RocketPFN: Accurate Time Series Classification via In-Context Learning
Pith reviewed 2026-06-26 14:15 UTC · model grok-4.3
The pith
RocketPFN matches the strongest time series classifier on UCR benchmarks with no training on target data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
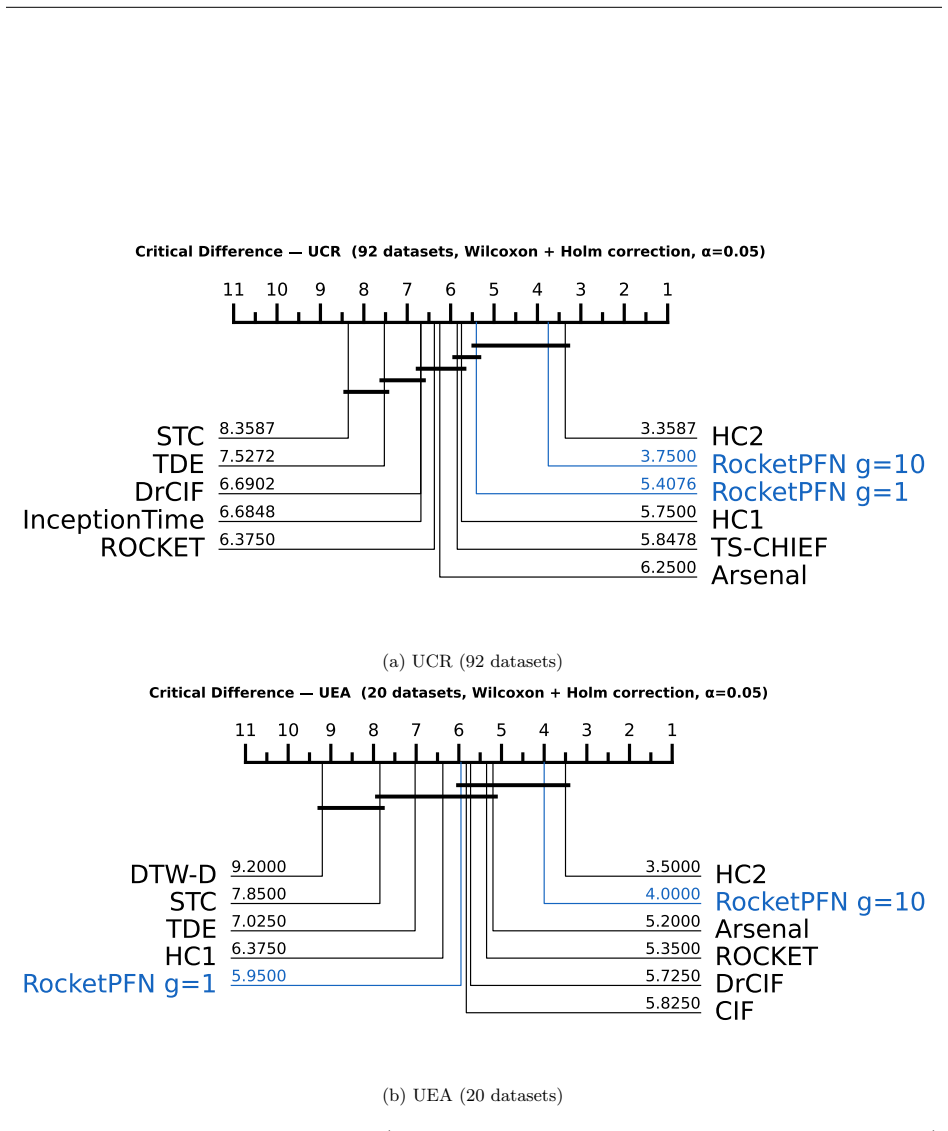
RocketPFN is a two-stage pipeline that applies Rocket random convolutional feature extraction to time series and then uses TabPFN v2.5 for in-context classification with no updates to any model parameters. On 92 UCR datasets under the 30-resample protocol it attains mean accuracy 0.900, identical to HC2, with Wilcoxon signed-rank p-value 0.50. It exceeds every single classifier inside the HC2 ensemble and also exceeds MOMENT, Mantis and MantisV2 when each is paired with the same downstream classifier, even when the compared encoders were pretrained on data containing UCR samples.
What carries the argument
The RocketPFN pipeline, which converts time series into fixed tabular features via Rocket and supplies them directly to TabPFN for in-context classification without adaptation.
If this is right
- RocketPFN significantly outperforms each individual classifier inside the HC2 ensemble.
- Performance difference versus HC2 is not statistically significant on the 20 UEA multivariate datasets.
- When the same downstream classifier is used, RocketPFN beats MOMENT, Mantis and MantisV2 while using fewer extracted features and zero learned parameters.
- The advantage over the other encoders persists even when those encoders saw UCR training samples during pretraining.
Where Pith is reading between the lines
- The result suggests that tabular in-context models can absorb time series structure through generic feature extraction alone.
- Similar two-stage pipelines could be tested on other sequence or multivariate tasks where labeled data are scarce.
- If the compatibility between feature extractor and in-context model is the key ingredient, swapping Rocket for alternative extractors offers a direct experimental test.
Load-bearing premise
Rocket features must be compatible with TabPFN's in-context learning so that the combination reaches competitive accuracy on time series tasks without any adaptation or training.
What would settle it
A fresh collection of time series classification datasets, evaluated under the same 30-resample protocol, on which RocketPFN mean accuracy falls significantly below HC2 would refute the matching-performance claim.
Figures
read the original abstract
We introduce RocketPFN, a training-free pipeline for time series classification that combines random convolutional feature extraction (Rocket) with in-context classification via a pretrained tabular foundation model (TabPFN v2.5). On 92 UCR datasets (30-resample protocol), RocketPFN matches HC2, the strongest published method on the archive, in mean accuracy (both 0.900, Wilcoxon p=0.50), with no training on the target data and a median inference time of 30 seconds per fold. It also significantly outperforms every individual classifier in the HC2 ensemble. On UEA (20 datasets) the difference is likewise not statistically significant. A separate comparison concerns TSC foundation models: when paired with the same downstream classifier, MOMENT, Mantis, and MantisV2 are all significantly outperformed by RocketPFN using fewer extracted features and no learned parameters (p<0.001 in each case). This holds even when the encoders were pretrained on corpora that include the UCR training samples. We propose this two-stage pipeline as a reference point for evaluating zero-shot TSC foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RocketPFN, a training-free pipeline for time series classification that extracts random convolutional features via Rocket and performs in-context classification with the pretrained tabular model TabPFN v2.5. On the UCR archive (92 datasets, 30-resample protocol) it reports mean accuracy 0.900, matching the HC2 ensemble (Wilcoxon p=0.50) with no target-data training and median 30 s inference per fold; it also outperforms every individual HC2 component and, when using the same downstream classifier, significantly outperforms MOMENT/Mantis/MantisV2 encoders (p<0.001) even when those encoders saw UCR data during pretraining. Parallel non-significant differences are reported on the UEA archive (20 datasets).
Significance. If reproducible, the result is significant: it supplies a simple, fast, fully zero-shot baseline that matches the strongest published TSC method on the standard UCR protocol while using no learned parameters and fewer features than the compared foundation-model encoders. The head-to-head design against both HC2 components and pretrained encoders (with explicit note on pretraining overlap) provides a useful reference point for future zero-shot TSC work and demonstrates that established feature extractors plus tabular in-context models can be competitive without domain-specific pretraining.
major comments (1)
- [§4] §4 (experimental protocol): the manuscript must explicitly state the precise Rocket kernel count, dilation parameters, and the exact feature-vector construction (including any scaling or padding) passed to TabPFN; without these the central claim of feature compatibility cannot be independently verified and is load-bearing for the reported accuracy parity.
minor comments (2)
- [Abstract] Abstract: the UEA mean accuracy value is omitted; reporting it alongside the UCR figure would improve completeness.
- [Methods] The paper should include a short table or appendix listing the exact TabPFN context length and any preprocessing steps applied to the Rocket features.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the experimental protocol. We address the point below and confirm that the requested details will be added to the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (experimental protocol): the manuscript must explicitly state the precise Rocket kernel count, dilation parameters, and the exact feature-vector construction (including any scaling or padding) passed to TabPFN; without these the central claim of feature compatibility cannot be independently verified and is load-bearing for the reported accuracy parity.
Authors: We agree that these implementation details are necessary for independent verification. In the revised Section 4 we will explicitly report: (i) the Rocket kernel count (10,000 kernels), (ii) the dilation schedule (standard Rocket dilations with maximum dilation equal to series length), and (iii) the precise feature-vector construction, including per-feature min-max scaling to [0,1], zero-padding of shorter series to the longest length in each fold, and the exact concatenation of the 20,000-dimensional Rocket feature vector (10,000 kernels × 2 features each) passed to TabPFN v2.5. We will also include a short pseudocode block or reference to the exact Rocket call used. revision: yes
Circularity Check
No significant circularity; empirical pipeline evaluated on public benchmarks
full rationale
The manuscript describes a training-free pipeline that feeds Rocket-extracted convolutional features into TabPFN v2.5 for in-context classification. All load-bearing claims are direct empirical comparisons (mean accuracy 0.900 matching HC2 on 92 UCR datasets under the 30-resample protocol, Wilcoxon p=0.50; outperformance versus MOMENT/Mantis encoders; similar results on UEA). No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the reported protocol. The compatibility of Rocket features with TabPFN is precisely the hypothesis tested by the head-to-head numbers on public data; the result is therefore falsifiable by reproduction rather than circular by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The Wilcoxon signed-rank test is appropriate for assessing statistical significance of differences in classifier performance across multiple datasets.
- domain assumption The 30-resample protocol provides a reliable estimate of classifier performance on UCR datasets.
Reference graph
Works this paper leans on
-
[1]
Engineering Structures , volume =
Arul, Monica and Kareem, Ahsan , title =. Engineering Structures , volume =
-
[2]
Data Mining and Knowledge Discovery , volume=
Bake off redux: a review and experimental evaluation of recent time series classification algorithms , author=. Data Mining and Knowledge Discovery , volume=. 2024 , publisher=
2024
-
[3]
and Labrador, Miguel A
Lara, Oscar D. and Labrador, Miguel A. , title =. IEEE Communications Surveys & Tutorials , volume =
-
[4]
, title =
Lei, Yaguo and Yang, Bin and Jiang, Xinwei and Jia, Feng and Li, Naipeng and Nandi, Asoke K. , title =. Mechanical Systems and Signal Processing , volume =
-
[6]
Art and Fan, Ya-Ju and Sachdeo, Rajesh C
Chaovalitwongse, W. Art and Fan, Ya-Ju and Sachdeo, Rajesh C. , title =. IEEE Transactions on Systems, Man, and Cybernetics---Part A: Systems and Humans , volume =
-
[7]
IEEE/CAA Journal of Automatica Sinica , volume =
Dau, Hoang Anh and Bagnall, Anthony and Kamgar, Kaveh and Yeh, Chin-Chia Michael and Zhu, Yan and Gharghabi, Shaghayegh and Ratanamahatana, Chotirat Ann and Keogh, Eamonn , title =. IEEE/CAA Journal of Automatica Sinica , volume =
-
[8]
Data Mining and Knowledge Discovery , volume =
Dempster, Angus and Petitjean, Fran. Data Mining and Knowledge Discovery , volume =
-
[9]
and Webb, Geoffrey I
Dempster, Angus and Schmidt, Daniel F. and Webb, Geoffrey I. , title =. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
-
[10]
, title =
Tan, Chang Wei and Dempster, Angus and Bergmeir, Christoph and Webb, Geoffrey I. , title =. Data Mining and Knowledge Discovery , volume =
-
[11]
and Bakiri, Ghulum , title =
Dietterich, Thomas G. and Bakiri, Ghulum , title =. Journal of Artificial Intelligence Research , volume =
-
[12]
Statistical comparisons of classifiers over multiple data sets , journal =
Dem. Statistical comparisons of classifiers over multiple data sets , journal =
-
[13]
2025 , eprint=
Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification , author=. 2025 , eprint=
2025
-
[15]
and Weber, Jonathan and Webb, Geoffrey I
Fawaz, Hassan Ismail and Lucas, Benjamin and Forestier, Germain and Pelletier, Charlotte and Schmidt, Daniel F. and Weber, Jonathan and Webb, Geoffrey I. and Idoumghar, Lhassane and Muller, Pierre-Alain and Petitjean, Fran. Data Mining and Knowledge Discovery , volume =
-
[16]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Goswami, Mononito and Szafer, Konrad and Choudhry, Arjun and Cai, Yifu and Li, Shuo and Dubrawski, Artur , title =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[17]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Hollmann, Noah and M\". Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[18]
Accurate predictions on small data with a tabular foundation model , journal =
Hollmann, Noah and M\". Accurate predictions on small data with a tabular foundation model , journal =
-
[20]
ACM Transactions on Knowledge Discovery from Data , volume =
Lines, Jason and Taylor, Sarah and Bagnall, Anthony , title =. ACM Transactions on Knowledge Discovery from Data , volume =
-
[21]
Machine Learning , volume =
Middlehurst, Matthew and Large, James and Flynn, Michael and Lines, Jason and Bostrom, Aaron and Bagnall, Anthony , title =. Machine Learning , volume =
-
[23]
Transformers can do
M\". Transformers can do. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[25]
2026 , eprint =
Grinsztajn, L. 2026 , eprint =
2026
-
[26]
Data Mining and Knowledge Discovery , volume =
Shifaz, Ahmed and Pelletier, Charlotte and Petitjean, Fran. Data Mining and Knowledge Discovery , volume =
-
[27]
International Conference on Learning Representations (ICLR) , year =
Xie, Shifeng and Feofanov, Vasilii and Odonnat, Ambroise and Zan, Lei and Alonso, Marius and Zhang, Jianfeng and Palpanas, Themis and Pan, Lujia and Zhang, Keli and Redko, Ievgen , title =. International Conference on Learning Representations (ICLR) , year =
-
[28]
Biometrics Bulletin , volume =
Wilcoxon, Frank , title =. Biometrics Bulletin , volume =
-
[29]
Dietterich and Ghulum Bakiri
Thomas G. Dietterich and Ghulum Bakiri. Solving multiclass learning problems via error-correcting output codes. Journal of Artificial Intelligence Research, 2:263--286, 1994
1994
-
[30]
Schmidt, Jonathan Weber, Geoffrey I
Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F. Schmidt, Jonathan Weber, Geoffrey I. Webb, Lhassane Idoumghar, Pierre-Alain Muller, and Fran c ois Petitjean. InceptionTime : Finding A lex N et for time series classification. Data Mining and Knowledge Discovery, 34(6):1936--1962, 2020
1936
-
[31]
Applications of shapelet transform to time series classification of earthquake, wind and wave data
Monica Arul and Ahsan Kareem. Applications of shapelet transform to time series classification of earthquake, wind and wave data. Engineering Structures, 228: 0 111564, 2021
2021
-
[32]
The UEA multivariate time series classification archive, 2018
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. The UEA multivariate time series classification archive, 2018. arXiv preprint arXiv:1811.00075, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Art Chaovalitwongse, Ya-Ju Fan, and Rajesh C
W. Art Chaovalitwongse, Ya-Ju Fan, and Rajesh C. Sachdeo. On the time series k -nearest neighbor classification of abnormal brain activity. IEEE Transactions on Systems, Man, and Cybernetics---Part A: Systems and Humans, 37 0 (6): 0 1005--1016, 2007
2007
-
[34]
The UCR time series archive
Hoang Anh Dau, Anthony Bagnall, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, and Eamonn Keogh. The UCR time series archive. IEEE/CAA Journal of Automatica Sinica, 6 0 (6): 0 1293--1305, 2019
2019
-
[35]
Angus Dempster, Fran c ois Petitjean, and Geoffrey I. Webb. ROCKET : Exceptionally fast and accurate time series classification using random convolutional kernels. Data Mining and Knowledge Discovery, 34 0 (5): 0 1454--1495, 2020
2020
-
[36]
Schmidt, and Geoffrey I
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. MiniRocket : A very fast (almost) deterministic transform for time series classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 248--257, 2021
2021
-
[37]
Statistical comparisons of classifiers over multiple data sets
Janez Dem s ar. Statistical comparisons of classifiers over multiple data sets. Journal of Machine Learning Research, 7: 0 1--30, 2006
2006
-
[38]
Dietterich and Ghulum Bakiri
Thomas G. Dietterich and Ghulum Bakiri. Solving multiclass learning problems via error-correcting output codes. Journal of Artificial Intelligence Research, 2: 0 263--286, 1995
1995
-
[39]
Schmidt, Jonathan Weber, Geoffrey I
Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F. Schmidt, Jonathan Weber, Geoffrey I. Webb, Lhassane Idoumghar, Pierre-Alain Muller, and Fran c ois Petitjean. InceptionTime : Finding AlexNet for time series classification. Data Mining and Knowledge Discovery, 34 0 (6): 0 1936--1962, 2020
1936
-
[40]
Mantis: Lightweight Foundation Model for Time Series Classification
Vasilii Feofanov, Songkang Wen, Marius Alonso, Romain Ilbert, Hongbo Guo, Malik Tiomoko, Lujia Pan, Jianfeng Zhang, and Ievgen Redko. Mantis: Lightweight calibrated foundation model for user-friendly time series classification, 2025. URL https://arxiv.org/abs/2502.15637
work page internal anchor Pith review arXiv 2025
-
[41]
Vasilii Feofanov, Songkang Wen, Jianfeng Zhang, Lujia Pan, and Ievgen Redko. MantisV2 : Closing the zero-shot gap in time series classification with synthetic data and test-time strategies. arXiv preprint arXiv:2602.17868, 2026
-
[42]
MOMENT : A family of open time-series foundation models
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. MOMENT : A family of open time-series foundation models. In Proceedings of the International Conference on Machine Learning (ICML), 2024
2024
-
[43]
L \'e o Grinsztajn, Klemens Fl \"o ge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Mihir Manium, Shi Bin Hoo, Magnus B \"u hler, Anurag Garg, Dominik Safaric, Jake Robertson, Benjamin J \"a ger, Simone Alessi, Adrian Hayler, Vladyslav Moroshan, Lennart Purucker, Philipp Singer, Alan Arazi, Julien Siems, Jan Hendrik Metzen, Georg Grab, Nick Ericks...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
TabPFN : A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel M\" u ller, Katharina Eggensperger, and Frank Hutter. TabPFN : A transformer that solves small tabular classification problems in a second. In Proceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[45]
u ller, Lennart Purucker, Arjun Krishnakumar, Max K\
Noah Hollmann, Samuel M\" u ller, Lennart Purucker, Arjun Krishnakumar, Max K\" o rfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model. Nature, 637: 0 319--326, 2025
2025
-
[46]
From tables to time: Extending TabPFN -v2 to time series forecasting
Shi Bin Hoo, Samuel M\" u ller, David Salinas, and Frank Hutter. From tables to time: Extending TabPFN -v2 to time series forecasting. arXiv preprint arXiv:2501.02945, 2025
-
[47]
Lara and Miguel A
Oscar D. Lara and Miguel A. Labrador. A survey on human activity recognition using wearable sensors. IEEE Communications Surveys & Tutorials, 15 0 (3): 0 1192--1209, 2013
2013
-
[48]
Yaguo Lei, Bin Yang, Xinwei Jiang, Feng Jia, Naipeng Li, and Asoke K. Nandi. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mechanical Systems and Signal Processing, 138: 0 106587, 2020
2020
-
[49]
Time series classification with HIVE-COTE : The hierarchical vote collective of transformation-based ensembles
Jason Lines, Sarah Taylor, and Anthony Bagnall. Time series classification with HIVE-COTE : The hierarchical vote collective of transformation-based ensembles. ACM Transactions on Knowledge Discovery from Data, 12 0 (5): 0 1--35, 2018
2018
-
[50]
HIVE-COTE 2.0: a new meta ensemble for time series classification
Matthew Middlehurst, James Large, Michael Flynn, Jason Lines, Aaron Bostrom, and Anthony Bagnall. HIVE-COTE 2.0: a new meta ensemble for time series classification. Machine Learning, 110: 0 3211--3243, 2021
2021
-
[51]
aeon: a Python toolkit for learning from time series
Matthew Middlehurst, Ali Ismail-Fawaz, Antoine Guillaume, Christopher Holder, David Guijo-Rubio, Guzal Bulatova, Leonidas Tsaprounis, Lukasz Mentel, Martin Walter, Patrick Sch\" a fer, and Anthony Bagnall. aeon: a Python toolkit for learning from time series. arXiv preprint arXiv:2406.14231, 2024 a
-
[52]
Matthew Middlehurst, Patrick Sch \"a fer, and Anthony Bagnall. Bake off redux: a review and experimental evaluation of recent time series classification algorithms. Data Mining and Knowledge Discovery, 38 0 (4): 0 1958--2031, 2024 b . doi:10.1007/s10618-024-01022-1
-
[53]
Transformers can do Bayesian inference
Samuel M\" u ller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers can do Bayesian inference. In Proceedings of the International Conference on Learning Representations (ICLR), 2022
2022
-
[54]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Prior Labs Team . TabPFN -2.5: Advancing the state of the art in tabular foundation models. arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Ahmed Shifaz, Charlotte Pelletier, Fran c ois Petitjean, and Geoffrey I. Webb. TS-CHIEF : A scalable and accurate forest algorithm for time series classification. Data Mining and Knowledge Discovery, 34 0 (3): 0 742--775, 2020
2020
-
[56]
Chang Wei Tan, Angus Dempster, Christoph Bergmeir, and Geoffrey I. Webb. MultiRocket : Multiple pooling operators and transformations for fast and effective time series classification. Data Mining and Knowledge Discovery, 36 0 (5): 0 1623--1646, 2022
2022
-
[57]
Individual comparisons by ranking methods
Frank Wilcoxon. Individual comparisons by ranking methods. Biometrics Bulletin, 1 0 (6): 0 80--83, 1945
1945
-
[58]
CauKer : Classification time series foundation models can be pretrained on synthetic data
Shifeng Xie, Vasilii Feofanov, Ambroise Odonnat, Lei Zan, Marius Alonso, Jianfeng Zhang, Themis Palpanas, Lujia Pan, Keli Zhang, and Ievgen Redko. CauKer : Classification time series foundation models can be pretrained on synthetic data. In International Conference on Learning Representations (ICLR), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.