Curiosity as Linguistic Intervention: Using LLM Tutoring Dialogues to Influence Exploratory Learning Behavior
Pith reviewed 2026-06-26 10:57 UTC · model grok-4.3
The pith
Curiosity-oriented linguistic interventions in LLM tutoring increase exploratory learner behaviors up to 2.4 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
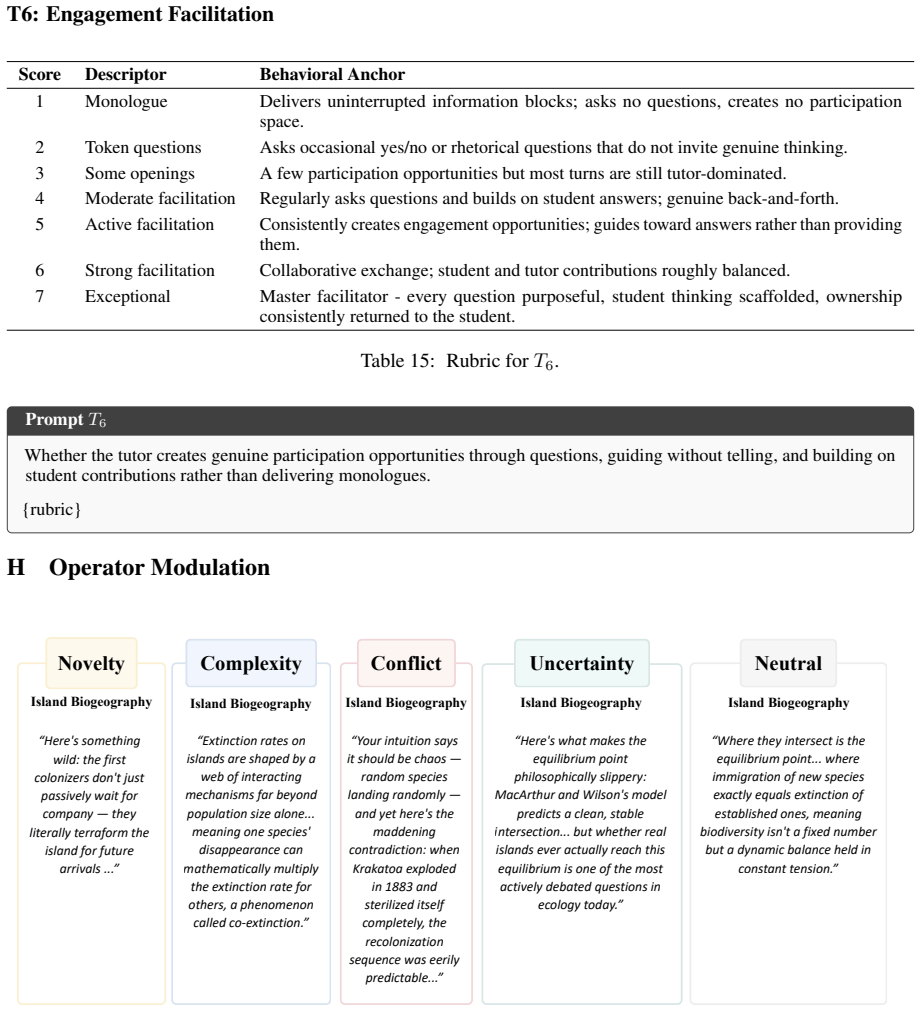
We introduce CURIOBOT, a framework that operationalizes Berlyne's collative variables, novelty, complexity, conflict, and uncertainty, as adaptive linguistic interventions for conversational tutoring. Across 270 tutoring conversations spanning multiple model families, domains, and topic complexity levels, curiosity-oriented interventions consistently increased exploratory learner behaviors, producing up to 2.4x more conversational turns under fixed time budgets. To measure these effects, we further introduce a learner-centered evaluation framework capturing exploratory questioning, conversational agency, productive struggle, and observable curiosity. Learner-side gains persisted even when tu
What carries the argument
CURIOBOT, the framework that turns Berlyne's collative variables into real-time linguistic interventions inside LLM tutor utterances.
If this is right
- Exploratory questioning, conversational agency, productive struggle, and observable curiosity all rise in the learner.
- The increase in learner activity occurs independently of any measured improvement in tutor instructional quality.
- LLM-mediated dialogue supplies a scalable, controllable setting for testing how specific language choices affect exploratory learning.
- The effects appear across different model families and domains, indicating the interventions are not tied to one particular LLM.
Where Pith is reading between the lines
- The same style of interventions might be tested outside tutoring, for example in open-ended question-answering or collaborative problem-solving sessions.
- If the mechanism is truly independent of content quality, it could be combined with other tutoring strategies without trade-offs.
- Longer-term studies could check whether the increased exploratory turns during a session lead to better retention or transfer on later tasks.
Load-bearing premise
The chosen linguistic patterns successfully isolate the four collative variables without being altered by the underlying model's own tendencies, the topic choices, or the way the new evaluation metrics are scored.
What would settle it
A controlled replication in which the same interventions produce no increase in learner conversational turns relative to baseline under identical time budgets and topic sets.
Figures









read the original abstract
Large Language Models (LLMs) provide a new opportunity to study how language shapes exploratory cognition because conversational strategies can be systematically manipulated at inference time. We introduce CURIOBOT, a framework that operationalizes Berlyne's collative variables, novelty, complexity, conflict, and uncertainty, as adaptive linguistic interventions for conversational tutoring. Across 270 tutoring conversations spanning multiple model families, domains, and topic complexity levels, curiosity-oriented interventions consistently increased exploratory learner behaviors, producing up to 2.4x more conversational turns under fixed time budgets. To measure these effects, we further introduce a learner-centered evaluation framework capturing exploratory questioning, conversational agency, productive struggle, and observable curiosity. Learner-side gains persisted even when tutor-side instructional quality remained unchanged, suggesting that curiosity functions as a partially independent interaction-level mechanism. More broadly, our results demonstrate that LLM-mediated dialogue can serve as a scalable experimental framework for studying how language shapes exploratory learning behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CURIOBOT, a framework operationalizing Berlyne's collative variables (novelty, complexity, conflict, uncertainty) as adaptive linguistic interventions in LLM-based tutoring dialogues. Across 270 conversations spanning model families, domains, and topic complexities, it reports that curiosity-oriented interventions consistently increase exploratory learner behaviors, yielding up to 2.4x more conversational turns under fixed time budgets. Learner gains persist even when tutor instructional quality is unchanged, and the work introduces a learner-centered evaluation framework measuring exploratory questioning, conversational agency, productive struggle, and observable curiosity. The results position LLM-mediated dialogue as a scalable experimental tool for studying language's role in exploratory learning.
Significance. If the central independence claim holds after verification of controls, the work offers a new experimental paradigm for isolating linguistic effects on exploratory cognition at scale. The CURIOBOT framework and learner-centered metrics could enable reproducible studies of interaction-level mechanisms in educational AI, extending beyond traditional tutoring research.
major comments (2)
- [Abstract] Abstract: The claim that 'learner-side gains persisted even when tutor-side instructional quality remained unchanged' is load-bearing for the independence conclusion, yet the abstract provides no evidence that interventions were checked for systematic effects on response length, coherence, or topic coverage that could mechanically increase turn counts.
- [Abstract] Abstract: The reported 2.4x increase in conversational turns requires statistical details, per-condition sample sizes, and validation that the learner-centered metrics are insensitive to generation artifacts; none of these are supplied, undermining assessment of whether the effect is robust to the noted confounds.
minor comments (1)
- [Abstract] The acronym CURIOBOT is used without an explicit expansion or definition on first use in the abstract.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on the abstract. They correctly identify that the abstract must better support its key claims about independence and effect robustness. We will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'learner-side gains persisted even when tutor-side instructional quality remained unchanged' is load-bearing for the independence conclusion, yet the abstract provides no evidence that interventions were checked for systematic effects on response length, coherence, or topic coverage that could mechanically increase turn counts.
Authors: The full manuscript reports post-hoc analyses confirming that curiosity interventions produced no significant differences in tutor response length, coherence scores, or topic coverage relative to control conditions. These checks are described in the experimental design and results sections. We agree the abstract should reference this verification to strengthen the independence claim and will add a concise clause to that effect in the revision. revision: yes
-
Referee: [Abstract] Abstract: The reported 2.4x increase in conversational turns requires statistical details, per-condition sample sizes, and validation that the learner-centered metrics are insensitive to generation artifacts; none of these are supplied, undermining assessment of whether the effect is robust to the noted confounds.
Authors: The abstract summarizes the maximum observed effect size across the 270 conversations (balanced across conditions and models). The learner-centered metrics were validated via human annotation with reported inter-rater agreement to mitigate generation artifacts. Full per-condition sample sizes, confidence intervals, and statistical tests appear in the results section. Due to abstract length limits we cannot include all details, but we will revise to state the total sample size and note the artifact validation. We view this as a partial revision. revision: partial
Circularity Check
No significant circularity; empirical study is self-contained
full rationale
The paper reports results from an empirical user study across 270 tutoring conversations, measuring behavioral outcomes (conversational turns, exploratory questioning, agency) under curiosity-oriented interventions operationalized from Berlyne's variables. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist that reduce claims to inputs by construction. Central findings rest on observed data from multiple models and domains rather than definitional equivalence or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Berlyne's collative variables (novelty, complexity, conflict, uncertainty) influence curiosity and can be operationalized as adaptive linguistic interventions in dialogue.
invented entities (1)
-
CURIOBOT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neuron , volume=
States of curiosity modulate hippocampus-dependent learning via the dopaminergic circuit , author=. Neuron , volume=. 2014 , publisher=
2014
-
[2]
Nature communications , volume=
Humans monitor learning progress in curiosity-driven exploration , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[3]
, author=
Conflict, arousal, and curiosity. , author=. 1960 , publisher=
1960
-
[4]
, author=
Motivational problems raised by exploratory and epistemic behavior. , author=. 1962 , publisher=
1962
-
[5]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[6]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[7]
arXiv preprint arXiv:1904.09675 , year=
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
Pith/arXiv arXiv 1904
-
[8]
Unifying AI tutor evaluation: An evaluation taxonomy for pedagogical ability assessment of LLM-powered AI tutors , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[9]
Ceur Workshop Proceedings , volume=
Automating pedagogical evaluation of LLM-based conversational agents , author=. Ceur Workshop Proceedings , volume=. 2025 , organization=
2025
-
[10]
arXiv preprint arXiv:2205.07540 , year=
The AI teacher test: Measuring the pedagogical ability of blender and GPT-3 in educational dialogues , author=. arXiv preprint arXiv:2205.07540 , year=
-
[11]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Mathdial: A dialogue tutoring dataset with rich pedagogical properties grounded in math reasoning problems , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[12]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Stepwise verification and remediation of student reasoning errors with large language model tutors , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[13]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Bridging the novice-expert gap via models of decision-making: A case study on remediating math mistakes , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[14]
arXiv preprint arXiv:2507.10579 , year=
Findings of the bea 2025 shared task on pedagogical ability assessment of ai-powered tutors , author=. arXiv preprint arXiv:2507.10579 , year=
arXiv 2025
-
[15]
arXiv preprint arXiv:2508.05952 , year=
Dean of llm tutors: exploring comprehensive and automated evaluation of llm-generated educational feedback via llm feedback evaluators , author=. arXiv preprint arXiv:2508.05952 , year=
-
[16]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[17]
The Innovation , year=
A survey on llm-as-a-judge , author=. The Innovation , year=
-
[18]
arXiv preprint arXiv:2407.12687 , year=
Towards responsible development of generative AI for education: An evaluation-driven approach , author=. arXiv preprint arXiv:2407.12687 , year=
-
[19]
Proceedings of the Eleventh ACM Conference on Learning@ Scale , pages=
Autotutor meets large language models: A language model tutor with rich pedagogy and guardrails , author=. Proceedings of the Eleventh ACM Conference on Learning@ Scale , pages=
-
[20]
arXiv preprint arXiv:2306.10052 , year=
Assigning AI: Seven approaches for students, with prompts , author=. arXiv preprint arXiv:2306.10052 , year=
-
[21]
arXiv preprint arXiv:2407.05181 , year=
Instructors as innovators: A future-focused approach to new AI learning opportunities, with prompts , author=. arXiv preprint arXiv:2407.05181 , year=
-
[22]
Communications of the ACM , volume=
Computing education in the era of generative AI , author=. Communications of the ACM , volume=. 2024 , publisher=
2024
-
[23]
International workshop on AI in education and educational research , pages=
Enhancing critical thinking in education by means of a Socratic chatbot , author=. International workshop on AI in education and educational research , pages=. 2024 , organization=
2024
-
[24]
, author=
EULER: Fine-Tuning a Large Language Model for Socratic Interactions. , author=. AIxEDU@ AI* IA , volume=
-
[25]
Proceedings of the 23rd Koli calling international conference on computing education research , pages=
Codehelp: Using large language models with guardrails for scalable support in programming classes , author=. Proceedings of the 23rd Koli calling international conference on computing education research , pages=
-
[26]
Proceedings of the 54th ACM Technical Symposium on Computer Science Education V
Using large language models to enhance programming error messages , author=. Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1 , pages=
-
[27]
Proceedings of the 2023 ACM Conference on International Computing Education Research-Volume 1 , pages=
Exploring the responses of large language models to beginner programmers’ help requests , author=. Proceedings of the 2023 ACM Conference on International Computing Education Research-Volume 1 , pages=
2023
-
[28]
arXiv preprint arXiv:2302.04662 , year=
Generating high-precision feedback for programming syntax errors using large language models , author=. arXiv preprint arXiv:2302.04662 , year=
-
[29]
Proceedings of the 2023 ACM Conference on International Computing Education Research-Volume 2 , pages=
Generative AI for programming education: Benchmarking ChatGPT, GPT-4, and human tutors , author=. Proceedings of the 2023 ACM Conference on International Computing Education Research-Volume 2 , pages=
2023
-
[30]
arXiv preprint arXiv:2412.16429 , year=
Learnlm: Improving gemini for learning , author=. arXiv preprint arXiv:2412.16429 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
SocraticLM: Exploring socratic personalized teaching with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Khanmigo: AI-powered tutor , year =
-
[33]
Learning and individual differences , volume=
ChatGPT for good? On opportunities and challenges of large language models for education , author=. Learning and individual differences , volume=. 2023 , publisher=
2023
-
[34]
Medical education , volume=
Resolving the 50-year debate around using and misusing Likert scales , author=. Medical education , volume=. 2008 , publisher=
2008
-
[35]
Advances in health sciences education , volume=
Likert scales, levels of measurement and the “laws” of statistics , author=. Advances in health sciences education , volume=. 2010 , publisher=
2010
-
[36]
Neuron , volume=
The psychology and neuroscience of curiosity , author=. Neuron , volume=. 2015 , publisher=
2015
-
[37]
Annual Review of Psychology , volume=
Cognitive modeling using artificial intelligence , author=. Annual Review of Psychology , volume=. 2025 , publisher=
2025
-
[38]
Proceedings of the National Academy of Sciences , volume=
The neural architecture of language: Integrative modeling converges on predictive processing , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , publisher=
2021
-
[39]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Rarely a problem? Language models exhibit inverse scaling in their predictions following few-type quantifiers , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[40]
Proceedings of the National Academy of Sciences , volume=
Using cognitive psychology to understand GPT-3 , author=. Proceedings of the National Academy of Sciences , volume=. 2023 , publisher=
2023
-
[41]
Nature Computational Science, 3 (10), 833-838 , author=
Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science, 3 (10), 833-838 , author=
-
[42]
Political Analysis , volume=
Out of one, many: Using language models to simulate human samples , author=. Political Analysis , volume=. 2023 , publisher=
2023
-
[43]
Behavior Research Methods , volume=
Can large language models help augment English psycholinguistic datasets? , author=. Behavior Research Methods , volume=. 2024 , publisher=
2024
-
[44]
Advances in Neural Information Processing Systems , volume=
Enhancing personalized multi-turn dialogue with curiosity reward , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Conference on Human-Computer Interaction , pages=
Generating Neurolinguistic Stimuli Using LLM Prompting , author=. International Conference on Human-Computer Interaction , pages=. 2025 , organization=
2025
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mind the gap: The divergence between human and llm-generated tasks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Proceedings of the 18th workshop on innovative use of NLP for building educational applications (BEA 2023) , pages=
Generating better items for cognitive assessments using large language models , author=. Proceedings of the 18th workshop on innovative use of NLP for building educational applications (BEA 2023) , pages=
2023
-
[48]
Computers & Education , volume=
Do curious students learn more science in an immersive virtual reality environment? Exploring the impact of advance organizers and epistemic curiosity , author=. Computers & Education , volume=. 2022 , publisher=
2022
-
[49]
, author=
Examining the Relationship between Epistemic Curiosity and Achievement Goals. , author=. Eurasian Journal of Educational Research (EJER) , number=
-
[50]
Journal of Qualitative Research in Education , number=
Does E-learning Trigger Epistemic Curiosity? , author=. Journal of Qualitative Research in Education , number=
-
[51]
Cognition & Emotion , volume=
Epistemic curiosity, feeling-of-knowing, and exploratory behaviour , author=. Cognition & Emotion , volume=. 2005 , publisher=
2005
-
[52]
Current opinion in behavioral sciences , volume=
Epistemic curiosity and the region of proximal learning , author=. Current opinion in behavioral sciences , volume=. 2020 , publisher=
2020
-
[53]
Symbol Emergence Systems: An Interdisciplinary Discussion about Cognition, Language and Society , pages=
Curiosity and Exploration: Why Do We Want to Learn? , author=. Symbol Emergence Systems: An Interdisciplinary Discussion about Cognition, Language and Society , pages=. 2026 , publisher=
2026
-
[54]
Learning and Individual Differences , volume=
Achievement motivation and knowledge development during exploratory learning , author=. Learning and Individual Differences , volume=. 2015 , publisher=
2015
-
[55]
Cognition and instruction , volume=
Productive failure , author=. Cognition and instruction , volume=. 2008 , publisher=
2008
-
[56]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Towards human-centered proactive conversational agents , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.