Reference-Free Assessment of Physical Consistency in World Model-based Video Generation
Pith reviewed 2026-06-26 11:10 UTC · model grok-4.3
The pith
Reference-free measures using SLAM and optical flow assess physical consistency in generated videos and improve robotic task success by over 8%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
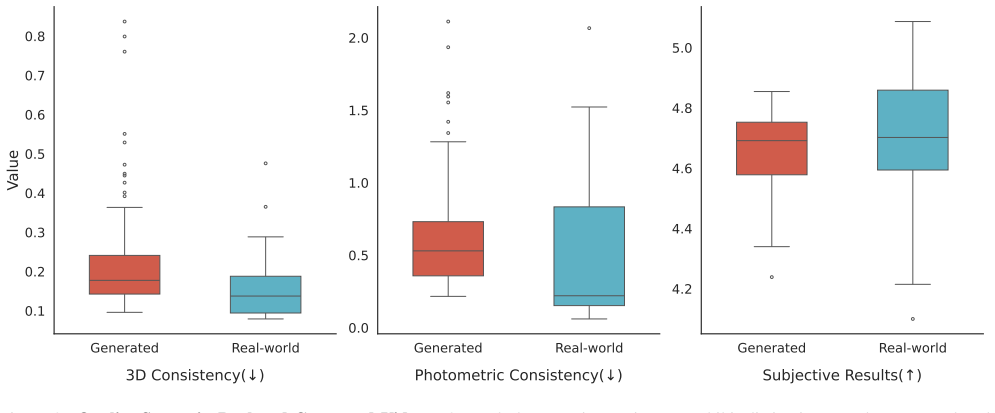
The central claim is that reference-free physical consistency assessment via DROID-SLAM and SEA-RAFT enables effective filtering of generated videos, resulting in over 8% improvement in task success rates for VLA models and providing spatio-temporal localization of inconsistencies.
What carries the argument
DROID-SLAM and SEA-RAFT used to quantify physical inconsistencies in generated videos through structure and flow analysis without references.
Load-bearing premise
DROID-SLAM and SEA-RAFT can be applied directly to generated videos to reliably quantify physical inconsistencies without ground-truth references or additional validation specific to synthetic data.
What would settle it
Observing that high-consistency videos according to the measures do not lead to higher task success rates in real-world robotic experiments, or that obvious physical errors like object interpenetration are not flagged by the measures.
Figures








read the original abstract
We introduce reference-free measures for evaluating the physical consistency of generated videos, combining relative and absolute approaches to assess fidelity. Although tools like WorldGym or WorldEval enable robotic simulation via video generation, physical fidelity gaps often prevent these environments from accurately reproducing real-world task success rates of VLA models. Unlike existing evaluation methods, which require costly human voting (Elo) or unavailable ground-truth references (FVD), our approach utilizes DROID-SLAM and SEA-RAFT to quantify physical inconsistencies, motivated by WorldScore. Videos filtered using our relative consistency assessment show an improvement in task success rates of over 8%, effectively narrowing the simulation-to-reality gap. Furthermore, our absolute assessment enables spatio-temporal localization, providing visualization of when and where physical artifacts occur.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces reference-free relative and absolute measures for physical consistency in world model-generated videos, leveraging DROID-SLAM and SEA-RAFT (motivated by WorldScore) to quantify inconsistencies without ground-truth references or human voting. It claims that filtering videos via the relative consistency assessment yields an over-8% improvement in downstream task success rates for VLA models, narrowing the sim-to-real gap, while the absolute assessment enables spatio-temporal localization of artifacts.
Significance. If the empirical result holds under proper validation, the work would offer a scalable, automated alternative to costly human evaluation or reference-dependent metrics for improving physical fidelity in video-based world models, with direct relevance to robotic simulation and VLA deployment.
major comments (2)
- [Abstract] Abstract and results sections: the headline claim of >8% task-success improvement from relative-consistency filtering is presented without experimental details (number of videos, task suite, baseline filters, statistical tests, or error bars), so the attribution of the lift specifically to physical consistency cannot be verified from the provided evidence.
- [Methodology] Methodology (DROID-SLAM/SEA-RAFT application): the central assumption that these estimators, developed and benchmarked on real-camera footage, produce scores that reliably track physical violations when applied to generated videos is unvalidated; generated videos can introduce photometric and geometric artifacts (texture flicker, inconsistent lighting, non-rigid motion) that violate the pipelines' assumptions, risking selection on an unrelated signal.
minor comments (2)
- [Methodology] Clarify the exact definitions of the relative and absolute consistency scores, including any thresholds or aggregation steps, to allow reproducibility.
- [Discussion] Add a limitations paragraph discussing failure modes of DROID-SLAM and SEA-RAFT on synthetic data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and commit to revisions that strengthen the presentation and evidence without misrepresenting the current manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: the headline claim of >8% task-success improvement from relative-consistency filtering is presented without experimental details (number of videos, task suite, baseline filters, statistical tests, or error bars), so the attribution of the lift specifically to physical consistency cannot be verified from the provided evidence.
Authors: We agree the abstract and results presentation lack sufficient experimental details to allow full verification of the claim. The current manuscript reports the >8% improvement but does not embed the supporting parameters in the abstract. In revision we will expand the abstract to include the number of videos evaluated, the VLA task suite, baseline filter comparisons, and references to statistical tests with error bars, while retaining the core claim. This directly addresses the verifiability concern. revision: yes
-
Referee: [Methodology] Methodology (DROID-SLAM/SEA-RAFT application): the central assumption that these estimators, developed and benchmarked on real-camera footage, produce scores that reliably track physical violations when applied to generated videos is unvalidated; generated videos can introduce photometric and geometric artifacts (texture flicker, inconsistent lighting, non-rigid motion) that violate the pipelines' assumptions, risking selection on an unrelated signal.
Authors: The manuscript motivates the estimators via WorldScore but does not include explicit validation against generation-specific artifacts. We acknowledge this gap. In the revised version we will add a targeted analysis subsection showing correlation between the consistency scores and human-labeled physical violations on a generated-video subset, plus discussion of robustness to common artifacts. The observed downstream VLA success-rate lift provides supporting (though indirect) evidence that the signal is relevant to physical consistency rather than unrelated factors. revision: partial
Circularity Check
No significant circularity; empirical result independent of inputs
full rationale
The paper applies existing external tools (DROID-SLAM, SEA-RAFT) to generated videos to produce consistency scores, then reports an observed empirical lift (>8% task success) from filtering on those scores. No equations, definitions, or claims in the provided text reduce the metrics or the reported improvement to self-defined quantities, fitted parameters renamed as predictions, or load-bearing self-citations. The central claim remains an externally measurable outcome rather than a constructed equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kevin Black, Noah Brown, et al.π 0: A vision-language- action flow model for general robot control, 2026. 1
2026
-
[2]
Worldscore: A unified evaluation benchmark for world generation, 2025
Haoyi Duan, Hong-Xing Yu, et al. Worldscore: A unified evaluation benchmark for world generation, 2025. 1, 2
2025
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, et al. Scaling rectified flow transformers for high-resolution image synthesis, 2024. 5
2024
-
[4]
Robocerebra: A large- scale benchmark for long-horizon robotic manipulation eval- uation, 2025
Songhao Han, Boxiang Qiu, et al. Robocerebra: A large- scale benchmark for long-horizon robotic manipulation eval- uation, 2025. 1
2025
-
[5]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, et al. Openvla: An open-source vision-language-action model, 2024. 3, 4, 5
2024
-
[6]
Fine-tuning vision-language-action models: Optimizing speed and suc- cess, 2025
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and suc- cess, 2025. 1
2025
-
[7]
Cosmos policy: Fine-tuning video models for visuomotor control and planning, 2026
Moo Jin Kim, Yihuai Gao, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning, 2026. 1
2026
-
[8]
Worldmodelbench: Judging video generation models as world models, 2025
Dacheng Li, Yunhao Fang, et al. Worldmodelbench: Judging video generation models as world models, 2025. 1
2025
-
[9]
Worldeval: World model as real-world robot policies evaluator, 2025
Yaxuan Li, Yichen Zhu, et al. Worldeval: World model as real-world robot policies evaluator, 2025. 1
2025
-
[10]
Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023
Bo Liu, Yifeng Zhu, et al. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. 1
2023
-
[11]
Sora: Creating video from text.https:// openai.com/index/sora/, 2024
OpenAI. Sora: Creating video from text.https:// openai.com/index/sora/, 2024. Accessed: 2026- 04-18. 5
2024
-
[12]
Gpt-4o system card, 2024
OpenAI, :, et al. Gpt-4o system card, 2024. 3
2024
-
[13]
Worldgym: World model as an environment for policy evaluation, 2025
Julian Quevedo, Ansh Kumar Sharma, et al. Worldgym: World model as an environment for policy evaluation, 2025. 1, 3, 4
2025
-
[14]
Lucy edit: Open-weight text-guided video editing, 2025
DecartAI Team. Lucy edit: Open-weight text-guided video editing, 2025. 5
2025
-
[15]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras, 2022
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras, 2022. 1, 2, 3
2022
-
[16]
Towards accurate generative models of video: A new metric & chal- lenges, 2019
Thomas Unterthiner, Sjoerd van Steenkiste, et al. Towards accurate generative models of video: A new metric & chal- lenges, 2019. 1
2019
-
[17]
Bridgedata v2: A dataset for robot learning at scale, 2024
Homer Walke, Kevin Black, et al. Bridgedata v2: A dataset for robot learning at scale, 2024. 3
2024
-
[18]
Sea-raft: Simple, efficient, accurate raft for optical flow, 2024
Yihan Wang, Lahav Lipson, and Jia Deng. Sea-raft: Simple, efficient, accurate raft for optical flow, 2024. 1, 2
2024
-
[19]
Grok imagine.https://x.ai/news/grok- imagine-api, 2026
xAI. Grok imagine.https://x.ai/news/grok- imagine-api, 2026. Accessed: 2026-04-18. 5
2026
-
[20]
Vlabench: A large-scale bench- mark for language-conditioned robotics manipulation with long-horizon reasoning tasks, 2024
Shiduo Zhang, Zhe Xu, et al. Vlabench: A large-scale bench- mark for language-conditioned robotics manipulation with long-horizon reasoning tasks, 2024. 1
2024
-
[21]
X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language- action model, 2025
Jinliang Zheng, Jianxiong Li, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language- action model, 2025. 1
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.