MMGist: A Comprehensive Multimodal Benchmark for 2027
Pith reviewed 2026-06-26 11:03 UTC · model grok-4.3
The pith
MMGist applies three filters to shrink a vision-language benchmark pool by 69 percent while keeping model rankings nearly identical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
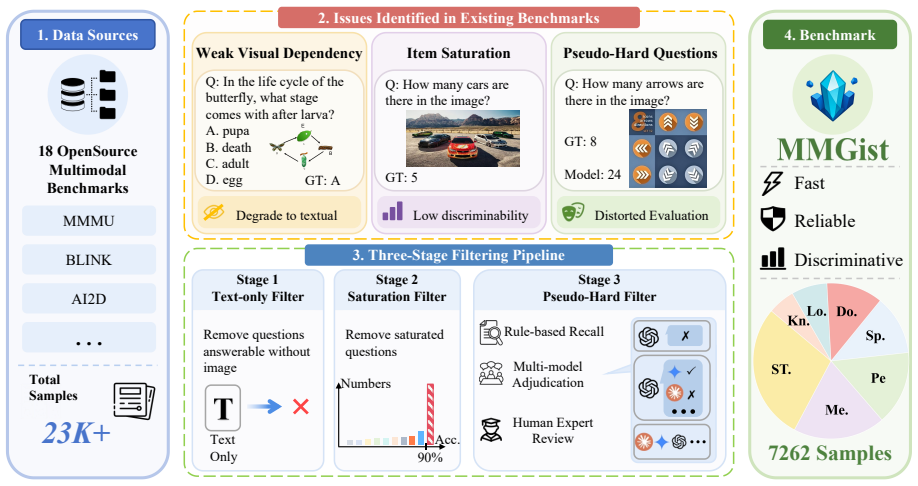
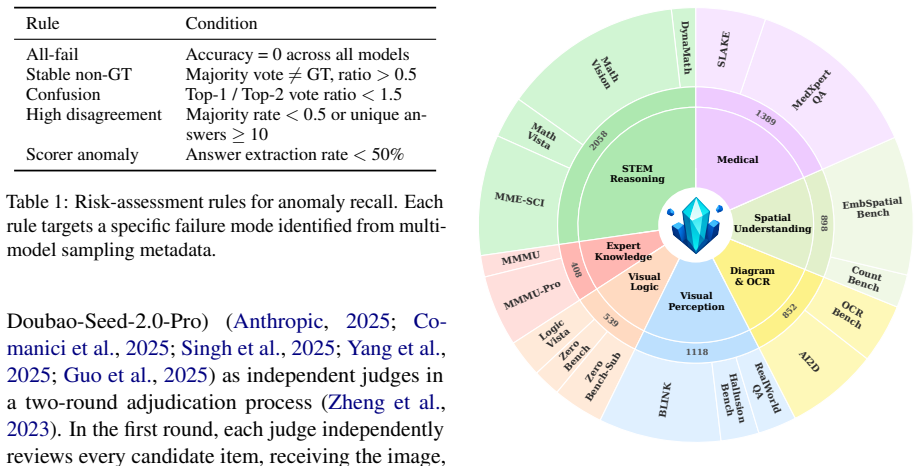
A three-stage pipeline of text-ablation filtering, cross-model saturation filtering, and anomaly detection filtering produces a 7,262-item benchmark that preserves original model rankings at Spearman ρ = 0.98, cuts the item count by 69 percent, and raises cross-model discrimination by 78 percent compared with the raw 23,250-item pool.
What carries the argument
The three-stage filtering pipeline that first removes items solvable from text alone, then drops items near saturation across many models, then removes anomalous items that produce unstable scores.
If this is right
- Visual Logic remains a consistent weak point across current large vision-language models.
- Knowledge-heavy dimensions continue to separate closed-source models from open-source ones.
- Benchmark designers should favor visual dependence, discrimination power, and reliability over simply increasing the number of items.
Where Pith is reading between the lines
- The same filtering logic could be applied to single-modality or non-English benchmarks to test whether similar size reductions preserve rankings.
- Model developers might adopt MMGist for faster iteration while still tracking relative capability ordering.
- Periodic re-application of the pipeline could keep future benchmarks from drifting back toward saturation as models improve.
Load-bearing premise
The three filtering steps remove non-visual, saturated, and anomalous items without changing the underlying capability order or favoring one model family over another.
What would settle it
Re-evaluating all 27 models on the unfiltered 23,250-item pool and obtaining model rankings or discrimination scores that differ substantially from the MMGist results.
Figures


read the original abstract
We conduct a systematic study of 18 widely used vision-language benchmarks and identify three major issues: 1) many items do not rely on visual cues and therefore fail to effectively measure multimodal understanding; 2) many items are already close to performance saturation for current LVLMs, which limits their discriminative power; 3) a small number of anomalous items affect the reliability of evaluation results. To this end, we propose MMGist, a curated benchmark that covers seven capability dimensions and contains 7,262 items. MMGist is constructed through a three-stage pipeline, which sequentially combines text-ablation filtering, cross-model saturation filtering, and anomaly detection filtering. We conduct extensive experiments on 27 leading LVLMs and compare MMGist with the raw pool of 23,250 items. The results show that MMGist preserves model rankings with high fidelity, with Spearman $\rho = 0.98$, while reducing evaluation items by 69\% and improving cross-model discrimination by 78\%. Further results indicate that Visual Logic remains a systematic weakness of current LVLMs, while knowledge-intensive dimensions such as Expert Knowledge dimensions remain important factors for distinguishing closed-source models from open-source models. These findings suggest that high-quality evaluation should prioritize visual dependency, discriminative power, and reliability, rather than simply pursuing benchmark scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies three issues in 18 existing vision-language benchmarks (non-visual items, performance saturation, anomalous items) and proposes MMGist, a curated 7,262-item benchmark spanning seven capability dimensions. It is built via a three-stage pipeline of text-ablation filtering, cross-model saturation filtering, and anomaly detection filtering. Experiments on 27 LVLMs show that MMGist preserves model rankings (Spearman ρ=0.98), reduces items by 69%, improves cross-model discrimination by 78%, and reveals persistent weaknesses in Visual Logic while highlighting Expert Knowledge for distinguishing closed- vs. open-source models.
Significance. If the filtering pipeline is shown to be free of selection bias, MMGist would offer a substantially more efficient and reliable evaluation resource for LVLMs, with the high rank preservation and discrimination gains providing a concrete advance over raw benchmark pools. The systematic analysis of 18 source benchmarks and the empirical findings on capability dimensions add value for future benchmark design.
major comments (2)
- [Abstract / three-stage pipeline description] The three-stage pipeline (text-ablation filtering, cross-model saturation filtering, and anomaly detection filtering) computes saturation and anomaly decisions from performance statistics across the identical 27 LVLMs later used to compute Spearman ρ=0.98 and the 78% discrimination improvement. This risks circular selection: retained items are those on which these models already exhibit spread or consistency, rendering the fidelity claims partly tautological. No held-out model validation, per-architecture retention statistics, or ablation of the filter models is reported to rule out bias favoring particular architectures (e.g., closed- vs. open-source on Expert Knowledge).
- [Abstract / Experimental results] The abstract states that MMGist improves cross-model discrimination by 78% but provides no definition of the discrimination metric (e.g., variance of scores, number of pairwise inversions, or normalized gap), no comparison to a size-matched random subset, and no raw data or thresholds for the saturation/anomaly filters. Without these, it is impossible to verify that the reported gain is not an artifact of the selection process itself.
minor comments (1)
- [Abstract] The seven capability dimensions are referenced but not enumerated or defined in the abstract; a table or explicit list would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address the concerns about circularity in the filtering pipeline and the lack of metric definitions below, and we commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / three-stage pipeline description] The three-stage pipeline (text-ablation filtering, cross-model saturation filtering, and anomaly detection filtering) computes saturation and anomaly decisions from performance statistics across the identical 27 LVLMs later used to compute Spearman ρ=0.98 and the 78% discrimination improvement. This risks circular selection: retained items are those on which these models already exhibit spread or consistency, rendering the fidelity claims partly tautological. No held-out model validation, per-architecture retention statistics, or ablation of the filter models is reported to rule out bias favoring particular architectures (e.g., closed- vs. open-source on Expert Knowledge).
Authors: We acknowledge that the filtering decisions rely on the same 27 LVLMs used for the reported Spearman correlation and discrimination metrics, which could introduce selection effects favoring models with particular performance profiles. While the pipeline design prioritizes items that are visually dependent and non-saturated for the current model landscape, we agree this warrants further validation. In the revised manuscript we will add a held-out model experiment (filtering on a random 20-model subset and evaluating rank preservation on the remaining 7 models), report per-architecture retention rates, and include an ablation removing one filter stage at a time. These additions will directly test for architecture-specific bias. revision: yes
-
Referee: [Abstract / Experimental results] The abstract states that MMGist improves cross-model discrimination by 78% but provides no definition of the discrimination metric (e.g., variance of scores, number of pairwise inversions, or normalized gap), no comparison to a size-matched random subset, and no raw data or thresholds for the saturation/anomaly filters. Without these, it is impossible to verify that the reported gain is not an artifact of the selection process itself.
Authors: We agree that the discrimination metric, filter thresholds, and supporting comparisons must be defined and reported for the claims to be verifiable. In the revision we will (1) explicitly define the 78% figure as the relative increase in mean pairwise absolute score difference across the 27 models, (2) add a size-matched random-subset baseline experiment showing that random 7,262-item subsets yield substantially lower discrimination gains, and (3) move the exact saturation and anomaly thresholds plus summary statistics of the filtered items to a new appendix table. These changes will allow readers to reproduce and scrutinize the selection process. revision: yes
Circularity Check
No significant circularity; empirical claims are direct measurements
full rationale
The paper describes an empirical filtering pipeline applied to an existing pool of items and then reports observed Spearman correlation and discrimination metrics computed directly on the 27 LVLMs. No equations, fitted parameters renamed as predictions, self-citations, or derivations are present that reduce the reported ρ = 0.98 or discrimination gain to the inputs by construction. The central results are self-contained empirical observations on the filtered set versus the raw pool, with no load-bearing self-referential logic or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The pool of 23,250 items from 18 benchmarks is a suitable starting point for curation that preserves overall model ordering.
Reference graph
Works this paper leans on
-
[1]
Are we done with mmlu? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), pages 5069–5096. Gemma Team, Google DeepMind. 2026. Gemma 4 model card. Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wa...
Pith/arXiv arXiv 2025
-
[2]
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Min- joon Seo, Hannaneh Hajishirzi, and Ali Farhadi
Step3-vl-10b technical report.arXiv preprint arXiv:2601.09668. Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Min- joon Seo, Hannaneh Hajishirzi, and Ali Farhadi
-
[3]
InEuro- pean conference on computer vision, pages 235–251
A diagram is worth a dozen images. InEuro- pean conference on computer vision, pages 235–251. Springer. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gon- zalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serv- ing with pagedattention. InProceedings of the 29th symposium o...
arXiv 2023
-
[4]
IEEE. Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, and 1 others. 2024a. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer. Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin...
arXiv 2024
-
[5]
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, In- bar Mosseri, Michal Irani, and Tali Dekel
Pervasive label errors in test sets destabi- lize machine learning benchmarks.arXiv preprint arXiv:2103.14749. Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, In- bar Mosseri, Michal Irani, and Tali Dekel. 2023. Teaching clip to count to ten. InProceedings of the IEEE/CVF international conference on computer vision, pages 3170–3180. Long Phan, Alice Gatt...
arXiv 2023
-
[6]
Anka Reuel, Amelia Hardy, Chandler Smith, Max Lam- parth, Malcolm Hardy, and Mykel J Kochenderfer
tinybenchmarks: evaluating llms with fewer examples.arXiv preprint arXiv:2402.14992. Anka Reuel, Amelia Hardy, Chandler Smith, Max Lam- parth, Malcolm Hardy, and Mykel J Kochenderfer
-
[7]
Betterbench: Assessing ai benchmarks, un- covering issues, and establishing best practices.Ad- vances in Neural Information Processing Systems, 37:21763–21813. Jonathan Roberts, Mohammad Reza Taesiri, Ansh Sharma, Akash Gupta, Samuel Roberts, Ioana Croitoru, Simion-Vlad Bogolin, Jialu Tang, Flo- rian Langer, Vyas Raina, and 1 others. 2025. Ze- robench: An...
arXiv 2025
-
[8]
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li
-
[9]
Measuring multimodal mathematical reason- ing with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, and 1 others. 2025. In- ternvl3. 5: Advancing open-source multimodal mod- els in versatility,...
Pith/arXiv arXiv 2025
-
[10]
Livebench: A challenging, contamination-free llm benchmark.arXiv preprint arXiv:2406.19314, 4:2. xAI. 2024. Realworldqa. Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang
Pith/arXiv arXiv 2024
-
[11]
Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, and 1 others
Logicvista: Multimodal llm logical reason- ing benchmark in visual contexts.arXiv preprint arXiv:2407.04973. Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, and 1 others. 2024. Benchmark data contamination of large language models: A survey.arXiv preprint arXiv:2406.04244. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, C...
Pith/arXiv arXiv 2024
-
[12]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, and 1 others. 2024. Mmmu: A massive multi-discipline multimodal un- derstanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on com- puter ...
Pith/arXiv arXiv 2024
-
[13]
Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Gong, Diyi Yang, and Xing Xie
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Gong, Diyi Yang, and Xing Xie. 2024. Dyval: Dynamic evalu- ation of large language models for reasoning tasks. InInternational Conference on Learning Representa- tions, volume 2024, pages 18...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.