Context-Aware Distillation and Ablation for Text2DSL
Pith reviewed 2026-06-26 10:19 UTC · model grok-4.3
The pith
Structured context makes text-to-DSL generation robust where prompt-only baselines fail on harder data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
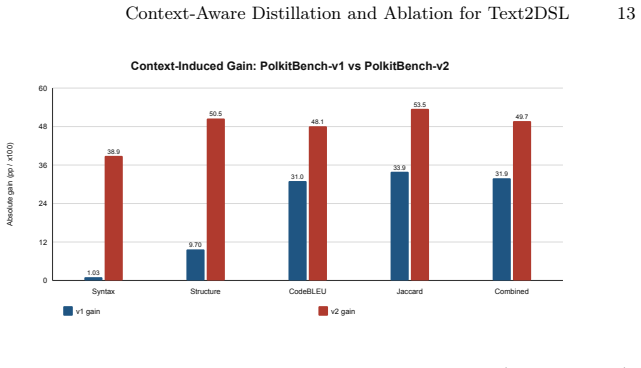
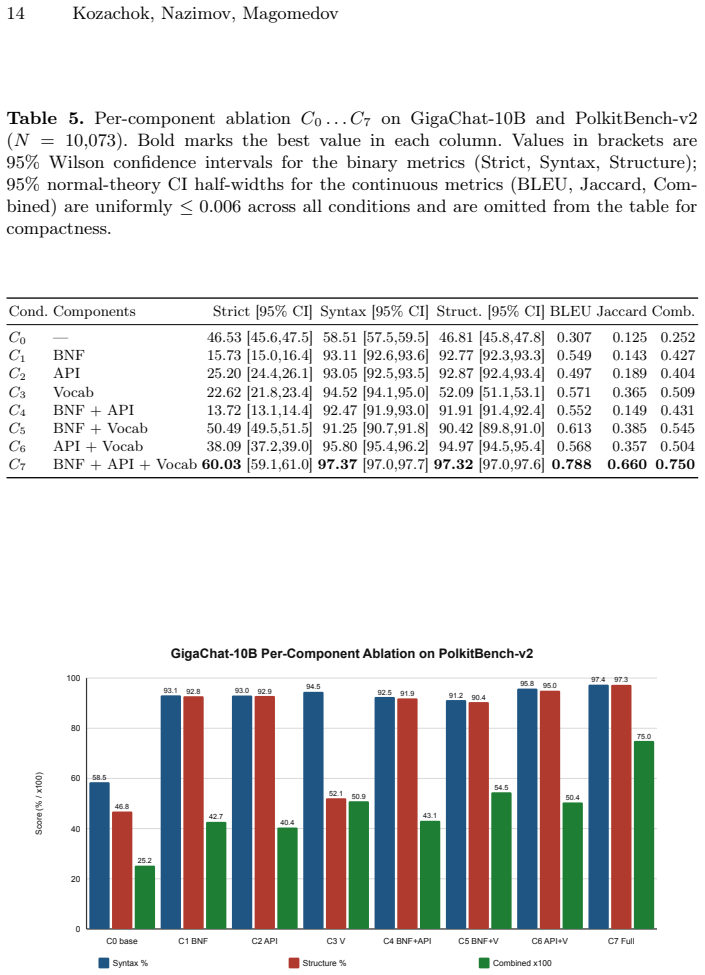
Context-aware distillation scales the PolkitBench corpus from 4,204 to 10,073 pairs at 100.0% AST validity and 99.7% runtime pass rate. Factorial ablation on the harder corpus shows baseline syntax validity falling from 97.6% to 58.5% while context mode falls only from 98.6% to 97.4%, with vocabulary giving the largest combined-score lift (+0.198) and API (+24.7 pp) plus BNF (+22.3 pp) giving the largest structural-validity lifts; the full context condition C7 is strongest on every metric.
What carries the argument
Structured context of BNF grammar, API specification, and closed identifier vocabulary supplied to the teacher LLM during distillation, followed by two-tier AST and runtime verification.
If this is right
- The full context condition C7 outperforms every partial context on all metrics.
- Vocabulary supplies the largest semantic-quality improvement (+0.198 combined score).
- API specification supplies the largest structural-validity gain (+24.7 percentage points).
- BNF grammar supplies the next largest structural-validity gain (+22.3 percentage points).
- Context-enhanced generation maintains high performance when test-corpus difficulty increases.
Where Pith is reading between the lines
- The same distillation pattern could generate verified rules for other policy or security DSLs that have formal grammars.
- Constraining the teacher with vocabulary and grammar may reduce hallucinated identifiers across broader LLM code-generation settings.
- Repeating the ablation on different model families would test whether vocabulary remains the dominant semantic contributor.
Load-bearing premise
The two-tier verification pipeline using esprima for AST and polkitd/pkcheck for runtime correctly identifies all valid and secure rules without systematic misses or false positives.
What would settle it
Finding a generated rule that passes both AST validation and runtime acceptance yet violates the intended security policy or introduces an undetected vulnerability when executed by the production daemon.
Figures

read the original abstract
We extend our prior work on Text2DSL automatic generation of domain-specific language (DSL) code from natural language descriptions along two complementary axes. First, we replace prompt-only synthetic generation with context-aware distillation, in which a teacher large language model (DeepSeek-V4-Flash) operates under an explicitly defined structured context comprising a BNF grammar, an API specification, and a closed identifier vocabulary; the resulting corpus is verified by a two-tier pipeline combining AST validation through esprima and runtime acceptance through the production polkitd daemon and the pkcheck client. This scales the verified PolkitBench corpus from 4,204 to 10,073 natural-language-to-Polkit-rule pairs at 100.0% AST validity and 99.7% runtime pass rate. Second, we conduct the per-component factorial ablation of structured context that was identified as future work in the precursor study: eight conditions C0-C7 are evaluated on GigaChat-10B-A1.8B with the new corpus. Three findings emerge. (i) The new harder corpus collapses the baseline mode (Syntax Valid 97.6% -> 58.5%, Combined Score 0.482 -> 0.252), whereas the context-enhanced mode degrades only marginally (Syntax 98.6% -> 97.4%, Combined 0.801 -> 0.750), confirming that structured context is not a cosmetic improvement but a load-bearing mechanism. (ii) The best absolute condition is the full context C7 across all metrics, while the strongest partial conditions (C5 = BNF + Vocabulary, C6 = API + Vocabulary) both contain the vocabulary. (iii) A Shapley-style decomposition assigns the largest semantic-quality effect to the vocabulary (Combined +0.198), the largest structural-validity effects to API (+24.7 pp) and BNF (+22.3 pp).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends prior Text2DSL work by introducing context-aware distillation, where a teacher LLM (DeepSeek-V4-Flash) generates Polkit rules under explicit structured context (BNF grammar, API specification, closed identifier vocabulary). This produces an expanded PolkitBench corpus of 10,073 NL-to-rule pairs at 100% AST validity (esprima) and 99.7% runtime pass rate (polkitd/pkcheck). A factorial ablation (C0-C7) on GigaChat-10B-A1.8B with the new corpus shows the baseline mode collapsing on the harder corpus (Syntax Valid 97.6%→58.5%, Combined 0.482→0.252) while context-enhanced modes degrade only marginally, with full context (C7) best and Shapley decomposition attributing largest effects to vocabulary (+0.198 Combined), API (+24.7 pp structural), and BNF (+22.3 pp structural).
Significance. If the two-tier verification pipeline is reliable, the work provides concrete evidence that structured context is load-bearing for DSL generation robustness rather than cosmetic, with quantitative per-component attribution via ablation and Shapley-style analysis on a scaled, verified corpus. The explicit scaling from 4,204 to 10,073 pairs and the differential degradation on the harder corpus are notable empirical contributions.
major comments (2)
- [Abstract] Abstract and methods: The central claim—that the new corpus exposes context as load-bearing because baseline syntax-valid rate collapses from 97.6% to 58.5% while context-enhanced drops only from 98.6% to 97.4%—depends entirely on the two-tier pipeline (esprima AST + polkitd/pkcheck runtime) correctly labeling semantic validity and security. No independent validation (human review of a sample, error analysis of false positives, or comparison against manual Polkit rules) is reported to confirm that the 99.7% runtime pass rate corresponds to human-judged correctness rather than undetected Polkit-specific semantic errors.
- [Ablation section] Ablation results: The Shapley-style decomposition reports specific attributions (vocabulary +0.198 Combined, API +24.7 pp, BNF +22.3 pp), but the exact computation method, base values, and whether it was performed on the new 10,073-pair corpus versus the prior one are not specified, making it impossible to verify if the attributions are robust to the verification pipeline.
minor comments (2)
- [Ablation section] The eight conditions C0-C7 are referenced but their exact definitions (which components are included in each) are not listed in the abstract; a table would improve clarity.
- [Results] No statistical significance tests or confidence intervals are mentioned for the reported deltas (e.g., 58.5% vs 97.4%).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the empirical contributions of the scaled corpus and ablation study. We address each major comment below and indicate planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods: The central claim—that the new corpus exposes context as load-bearing because baseline syntax-valid rate collapses from 97.6% to 58.5% while context-enhanced drops only from 98.6% to 97.4%—depends entirely on the two-tier pipeline (esprima AST + polkitd/pkcheck runtime) correctly labeling semantic validity and security. No independent validation (human review of a sample, error analysis of false positives, or comparison against manual Polkit rules) is reported to confirm that the 99.7% runtime pass rate corresponds to human-judged correctness rather than undetected Polkit-specific semantic errors.
Authors: We acknowledge that the manuscript does not report independent human validation of the two-tier pipeline beyond the automated checks. While runtime execution via the production polkitd daemon offers direct evidence of functional behavior, we agree that this leaves open the possibility of undetected semantic or security issues. In the revision we will add a human evaluation section: a random sample of 150 rules drawn from the 10,073-pair corpus will be reviewed by two domain experts (with inter-annotator agreement reported via Cohen’s kappa) against the original natural-language intent and Polkit security guidelines. This will be presented alongside the existing pipeline metrics. revision: yes
-
Referee: [Ablation section] Ablation results: The Shapley-style decomposition reports specific attributions (vocabulary +0.198 Combined, API +24.7 pp, BNF +22.3 pp), but the exact computation method, base values, and whether it was performed on the new 10,073-pair corpus versus the prior one are not specified, making it impossible to verify if the attributions are robust to the verification pipeline.
Authors: We agree the description of the Shapley-style decomposition is underspecified. The values were obtained on the new 10,073-pair corpus by treating the eight conditions (C0–C7) as a factorial design and applying the standard Shapley value formula for cooperative games, with C0 (no context) as the base value. We will insert a new subsection (and appendix with the full attribution matrix) that states the exact formula, confirms the corpus used, lists the base values for each metric, and notes that all attributions are computed after the two-tier verification filter. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper reports empirical ablation results (Syntax Valid rates, Combined Scores) measured on a new corpus of 10,073 pairs constructed via teacher-model distillation and verified by an external two-tier pipeline (esprima AST validation plus polkitd/pkcheck runtime acceptance at 99.7% pass rate). The sole reference to prior work notes only that the factorial ablation design was flagged as future work in the precursor study; this citation is not load-bearing for any metric or claim. No equations, self-definitions, fitted parameters renamed as predictions, or imported uniqueness results appear. All reported differentials are direct experimental outcomes on the verified corpus and GigaChat-10B model under the eight context conditions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The two-tier verification (esprima AST + polkitd/pkcheck runtime) accurately labels generated rules as correct or incorrect.
- domain assumption DeepSeek-V4-Flash can generate higher-quality DSL examples when supplied with explicit BNF, API, and vocabulary context than without.
Reference graph
Works this paper leans on
-
[1]
In: Proc
Kozachok, A.V., Nazimov, A.A., Magomedov, Sh.G.: Text2DSL: LLM-based code generation for domain-specific languages. In: Proc. 30th Int. Conf. Knowledge- Based and Intelligent Information & Engineering Systems (KES 2026). Procedia Computer Science (2026)
2026
-
[2]
https://www.freedesktop.org/software/ polkit/docs/latest/ (accessed 2026-05-12)
freedesktop.org: Polkit reference manual. https://www.freedesktop.org/software/ polkit/docs/latest/ (accessed 2026-05-12)
2026
-
[3]
NAI Labs Report 01-043, NAI Labs, Network Associates Inc
Smalley, S., Vance, C., Salamon, W.: Implementing SELinux as a Linux security module. NAI Labs Report 01-043, NAI Labs, Network Associates Inc. (2001)
2001
-
[4]
In: Proc
Loscocco, P., Smalley, S.: Integrating flexible support for security policies into the Linux operating system. In: Proc. FREENIX Track, USENIX Annual Technical Conf., pp. 29–42 (2001)
2001
-
[5]
https://www
The Open Policy Agent Authors: OPA documentation. https://www. openpolicyagent.org/docs/latest/ (accessed 2026-05-12)
2026
-
[6]
https://developer.hashicorp.com/ terraform/language (accessed 2026-05-12)
HashiCorp: Terraform language documentation. https://developer.hashicorp.com/ terraform/language (accessed 2026-05-12)
2026
-
[7]
In: 2019 24th International Conference on Engineering of Complex Computer Systems (ICECCS), pp
Rahman, A., Parnin, C., Williams, L.: The seven sins: security smells in infrastruc- ture as code scripts. In: Proc. 41st Int. Conf. on Software Engineering (ICSE), pp. 164–175 (2019). doi:10.1109/ICSE.2019.00033 20 Kozachok, Nazimov, Magomedov
-
[8]
Saavedra, N., Ferreira, J.F.: GLITCH: Automated polyglot security smell detection in infrastructure as code. In: Proc. 37th IEEE/ACM Int. Conf. on Automated Software Engineering (ASE), Art. No. 19, pp. 1–12 (2022). doi:10.1145/3551349. 3556945
-
[9]
ACM Computing Surveys 37(4), 316–344 (2005)
Mernik, M., Heering, J., Sloane, A.M.: When and how to develop domain-specific languages. ACM Computing Surveys 37(4), 316–344 (2005). doi:10.1145/1118890. 1118892
-
[10]
Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li, Z., Ma, J., Li, I., Yao, Q., Roman, S., Zhang, Z., Radev, D.: Spider: a large-scale human-labeled dataset for complex and cross-domain semantic parsing and Text-to-SQL task. In: Proc. 2018 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 3911–3921 (2018). doi:10.18653/v1/D18-1425
-
[11]
In: Advances in Neural Information Processing Systems 36 (NeurIPS 2023), pp
Pourreza, M., Rafiei, D.: DIN-SQL: decomposed in-context learning of Text-to- SQL with self-correction. In: Advances in Neural Information Processing Systems 36 (NeurIPS 2023), pp. 36339–36348 (2023)
2023
-
[12]
Li,H.,Zhang,J.,Li,C.,Chen,H.:RESDSQL:decouplingschemalinkingandskele- ton parsing for Text-to-SQL. In: Proc. 37th AAAI Conf. on Artificial Intelligence, pp. 13067–13075 (2023). doi:10.1609/aaai.v37i11.26535
-
[13]
Scholak, T., Schucher, N., Bahdanau, D.: PICARD: parsing incrementally for con- strained auto-regressive decoding from language models. In: Proc. 2021 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 9895–9901 (2021). doi:10.18653/v1/2021.emnlp-main.779
-
[14]
In: Proc
Poesia, G., Polozov, O., Le, V., Tiwari, A., Soares, G., Meek, C., Gulwani, S.: Synchromesh: reliable code generation from pre-trained language models. In: Proc. 10th Int. Conf. on Learning Representations (ICLR) (2022)
2022
-
[15]
In: Findings of the Association for Computational Linguistics: EMNLP 2023, pp
Geng, S., Josifoski, M., Peyrard, M., West, R.: Grammar-constrained decoding for structured NLP tasks without finetuning. In: Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 10932–10952 (2023). doi:10.18653/ v1/2023.findings-emnlp.733
2023
-
[16]
In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp
Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M., Shou, L., Qin, B., Liu, T., Jiang, D., Zhou, M.: CodeBERT: a pre-trained model for programming and natural languages. In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 1536–1547 (2020). doi:10.18653/v1/2020.findings-emnlp.139
-
[17]
In: Proc
Guo, D., Ren, S., Lu, S., Feng, Z., Tang, D., Liu, S., Zhou, L., Duan, N., Svy- atkovskiy, A., Fu, S., Tufano, M., Deng, S.K., Clement, C., Drain, D., Sundaresan, N., Yin, J., Jiang, D., Zhou, M.: GraphCodeBERT: pre-training code representa- tions with data flow. In: Proc. 9th Int. Conf. on Learning Representations (ICLR) (2021)
2021
-
[18]
Wang, Y., Wang, W., Joty, S., Hoi, S.C.H.: CodeT5: identifier-aware unified pre- trained encoder-decoder models for code understanding and generation. In: Proc. 2021 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 8696–8708 (2021). doi:10.18653/v1/2021.emnlp-main.685
-
[19]
Li, R., Allal, L.B., Zi, Y., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., et al.: StarCoder: may the source be with you! Transactions on Machine Learning Research (TMLR), 2023 (2023)
2023
-
[20]
In: Proc
Nijkamp,E.,Pang,B.,Hayashi,H.,Tu,L.,Wang,H.,Zhou,Y.,Savarese,S.,Xiong, C.: CodeGen: an open large language model for code with multi-turn program synthesis. In: Proc. 11th Int. Conf. on Learning Representations (ICLR) (2023)
2023
-
[21]
Jain, N., Vaidyanath, S., Iyer, S., Natarajan, N., Parthasarathy, S., Rajamani, S., Sharma, R.: Jigsaw: large language models meet program synthesis. In: Proc. 44th Context-Aware Distillation and Ablation for Text2DSL 21 Int. Conf. on Software Engineering (ICSE), pp. 1219–1231 (2022). doi:10.1145/ 3510003.3510203
arXiv 2022
-
[22]
In: NeurIPS Deep Learning and Representation Learning Workshop (2014)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In: NeurIPS Deep Learning and Representation Learning Workshop (2014)
2014
-
[23]
In- ternational Journal of Computer Vision 129(6), 1789–1819 (2021)
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: a survey. In- ternational Journal of Computer Vision 129(6), 1789–1819 (2021). doi:10.1007/ s11263-021-01453-z
2021
-
[24]
In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp
Jiao, X., Yin, Y., Shang, L., Jiang, X., Chen, X., Li, L., Wang, F., Liu, Q.: Tiny- BERT: distilling BERT for natural language understanding. In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 4163–4174 (2020). doi:10.18653/v1/2020.findings-emnlp.372
-
[25]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N.A., Khashabi, D., Hajishirzi, H.: Self-Instruct: aligning language models with self-generated instructions. In: Proc. 61st Annual Meeting of the Association for Computational Linguistics (ACL), Vol. 1: Long Papers, pp. 13484–13508 (2023). doi:10.18653/v1/2023.acl-long.754
-
[26]
In: Proc
Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., Lin, Q., Jiang, D.: WizardLM: empowering large pre-trained language models to follow complex instructions. In: Proc. 12th Int. Conf. on Learning Representations (ICLR) (2024)
2024
-
[27]
In: Proc
Luo,Z.,Xu,C.,Zhao,P.,Sun,Q.,Geng,X.,Hu,W.,Tao,C.,Ma,J.,Lin,Q.,Jiang, D.: WizardCoder: empowering code large language models with Evol-Instruct. In: Proc. 12th Int. Conf. on Learning Representations (ICLR) (2024)
2024
-
[28]
In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-T., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive NLP tasks. In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp. 9459–9474 (2020)
2020
-
[29]
24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models.In:AdvancesinNeuralInformationProcessingSystems35(NeurIPS2022), pp. 24824–24837 (2022)
2022
-
[30]
Bleu: a method for automatic evaluation of machine translation
Papineni, K., Roukos, S., Ward, T., Zhu, W.-J.: BLEU: a method for automatic evaluationofmachinetranslation.In:Proc.40thAnnualMeetingoftheAssociation for Computational Linguistics (ACL), pp. 311–318 (2002). doi:10.3115/1073083. 1073135
-
[31]
Eghbali, A., Pradel, M.: CrystalBLEU: precisely and efficiently measuring the sim- ilarity of code. In: Proc. 37th IEEE/ACM Int. Conf. on Automated Software En- gineering (ASE), Art. No. 28, pp. 1–12 (2022). doi:10.1145/3551349.3556903
-
[32]
In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few- shot learners. In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp. 1877–1901 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.