Temporal Logic Guidance for Action-Only Diffusion Policies with World Models
Pith reviewed 2026-06-26 09:03 UTC · model grok-4.3
The pith
A learned world model enables differentiable STL guidance for action-only diffusion policies without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a learned world model supplies predicted states that make STL robustness scores differentiable for sequences of actions generated by a diffusion policy; the gradient of those scores can then be added to the denoising process to steer outputs toward constraint satisfaction at inference time while leaving the trained policy unchanged.
What carries the argument
World-model-enabled differentiable STL robustness evaluation whose gradient is injected into diffusion sampling.
If this is right
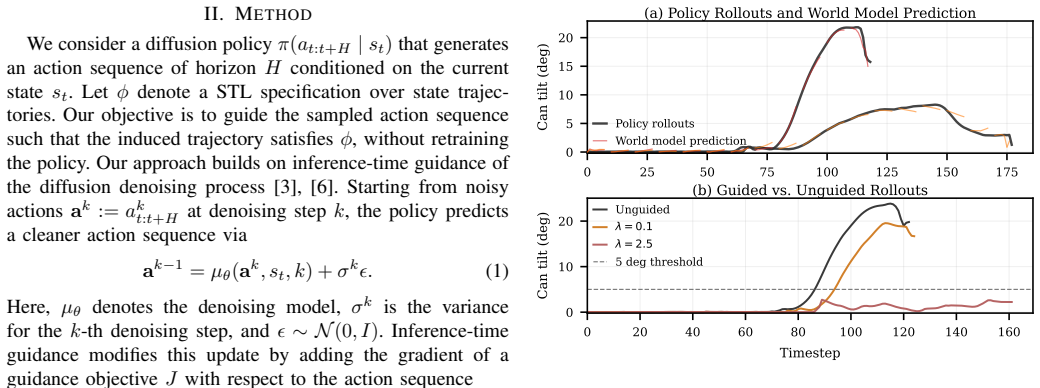
- Constraint violations drop from over 80 percent to 4 percent on the reported manipulation task while task success stays at 100 percent.
- Guidance works for policies that output only actions, avoiding the added complexity and runtime of joint state-action generation.
- No policy retraining is required; the same trained diffusion model can be guided by different STL specifications.
- The method extends in principle to more complex temporal constraints as noted in the discussion.
Where Pith is reading between the lines
- If the world model generalizes across tasks, the same guidance technique could apply to other action-only policy classes without modification.
- Runtime changes to the STL formula would let an operator adjust robot behavior on the fly to new preferences or safety rules.
- Pairing the method with uncertainty estimates from the world model could further reduce sensitivity to prediction mistakes.
Load-bearing premise
The learned world model must produce state predictions accurate enough that the STL robustness gradient improves constraint adherence without lowering task success or creating new errors.
What would settle it
An experiment in which the world model's state prediction error is increased until the fraction of constraint-satisfying trajectories falls to the level of the unguided baselines.
Figures

read the original abstract
Diffusion policies enable multimodal robot behavior but offer limited ability to choose among behavior modes at inference time, even though such control is desirable in human-robot settings. Prior solutions to this lack of control have utilized Signal Temporal Logic (STL) to express human intentions and provide corresponding guidance for diffusion policy inference. However, these approaches can only guide diffusion policies that jointly generate future actions and states, increasing both complexity and runtime. We propose a novel guidance method for action-only diffusion policies that uses a separate learned world model to enable differentiable evaluation of STL robustness, with its gradient then injected into the diffusion process. This steers behavior toward constraint satisfaction without retraining, improving constraint adherence while preserving task performance. On the Can Transport task from Robomimic, our method maintains 100% task success while reducing constraint violations from over 80% for baseline methods to 4%. We also discuss extensions toward improved robustness and more complex constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a guidance technique for action-only diffusion policies that uses a separate learned world model to compute differentiable Signal Temporal Logic (STL) robustness scores; the resulting gradients are injected into the diffusion sampling process to enforce temporal constraints at inference time without retraining the policy. On the Can Transport task from Robomimic, the method is reported to achieve 100% task success while reducing constraint violations from over 80% (baselines) to 4%.
Significance. If the world-model accuracy precondition holds, the approach would allow runtime STL-based control of simpler action-only diffusion policies, which is practically relevant for human-robot interaction settings where constraints must be specified on the fly. The separation of the world model from the policy is a clean architectural choice that preserves the speed and simplicity of action-only models.
major comments (2)
- [Abstract / Experiments] The central empirical claim (100% success, 4% violations) is load-bearing on the assumption that the learned world model produces sufficiently accurate multi-step state predictions for reliable differentiable STL robustness gradients. No quantitative bound on world-model prediction error over the STL horizon, no ablation varying model accuracy, and no oracle-state-predictor comparison are supplied, leaving open the possibility that the injected gradients optimize an incorrect robustness landscape.
- [Method] The method description states that gradients from STL robustness on predicted states are injected into diffusion sampling, yet the manuscript supplies no details on world-model training procedure, loss scaling between task and constraint objectives, or how gradient magnitude is controlled to avoid degrading the original task performance.
minor comments (1)
- [Abstract] The abstract mentions 'extensions toward improved robustness' but does not indicate whether these are evaluated in the main experiments or left as future work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting important gaps in empirical validation and methodological detail. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central empirical claim (100% success, 4% violations) is load-bearing on the assumption that the learned world model produces sufficiently accurate multi-step state predictions for reliable differentiable STL robustness gradients. No quantitative bound on world-model prediction error over the STL horizon, no ablation varying model accuracy, and no oracle-state-predictor comparison are supplied, leaving open the possibility that the injected gradients optimize an incorrect robustness landscape.
Authors: We agree that the absence of quantitative error bounds, accuracy ablations, and oracle comparisons leaves the reliability of the STL gradients insufficiently substantiated. In the revised version we will add (i) measured multi-step prediction error statistics over the STL horizon, (ii) an ablation that varies world-model accuracy, and (iii) an oracle-state-predictor baseline to confirm that the observed constraint satisfaction is not an artifact of an incorrect robustness landscape. revision: yes
-
Referee: [Method] The method description states that gradients from STL robustness on predicted states are injected into diffusion sampling, yet the manuscript supplies no details on world-model training procedure, loss scaling between task and constraint objectives, or how gradient magnitude is controlled to avoid degrading the original task performance.
Authors: We acknowledge that these implementation details are missing from the current manuscript. The revised method section will explicitly describe the world-model training procedure, the loss scaling between task and constraint terms, and the gradient-magnitude control mechanisms used during sampling to preserve task performance. revision: yes
Circularity Check
No circularity; empirical performance claims rest on external task evaluation
full rationale
The paper describes an empirical method that trains a separate world model and injects STL robustness gradients into an action-only diffusion policy at inference time. No equations, derivations, or self-citations are presented that reduce the reported 100% success / 4% violation numbers on the Can Transport task to fitted parameters, renamed inputs, or self-referential definitions. The central result is obtained by running the guided policy on held-out Robomimic demonstrations and measuring task success plus constraint violations; these quantities are not forced by construction from the method's own training losses or prior author results. The world-model accuracy precondition is a correctness assumption rather than a circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Human-robot teaming: grand challenges,
M. Natarajan, E. Seraj, B. Altundas, R. Paleja, S. Ye, L. Chen, R. Jensen, K. C. Chang, and M. Gombolay, “Human-robot teaming: grand challenges,”Current Robotics Reports, vol. 4, no. 3, pp. 81–100, 2023
2023
-
[2]
Interpretable and per- sonalized apprenticeship scheduling: Learning interpretable scheduling policies from heterogeneous user demonstrations,
R. Paleja, A. Silva, L. Chen, and M. Gombolay, “Interpretable and per- sonalized apprenticeship scheduling: Learning interpretable scheduling policies from heterogeneous user demonstrations,”Advances in Neural Information Processing Systems, vol. 33, pp. 6417–6428, 2020
2020
-
[3]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[4]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[5]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Q. Nichol, “Diffusion models beat GANs on image synthesis,” inAdvances in Neural Information Processing Systems, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021. [Online]. Available: https://openreview.net/forum?id=AAWuCvzaVt
2021
-
[6]
Universal guidance for diffusion models,
A. Bansal, H.-M. Chu, A. Schwarzschild, S. Sengupta, M. Goldblum, J. Geiping, and T. Goldstein, “Universal guidance for diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 843–852
2023
-
[7]
Dynaguide: Steering diffusion polices with active dynamic guidance,
M. Du and S. Song, “Dynaguide: Steering diffusion polices with active dynamic guidance,”arXiv preprint arXiv:2506.13922, 2025
arXiv 2025
-
[8]
Guided conditional diffusion for controllable traffic simu- lation,
Z. Zhong, D. Rempe, D. Xu, Y . Chen, S. Veer, T. Che, B. Ray, and M. Pavone, “Guided conditional diffusion for controllable traffic simu- lation,” inIEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 3560–3566
2023
-
[9]
Diverse controllable diffusion policy with signal temporal logic,
Y . Meng and C. Fan, “Diverse controllable diffusion policy with signal temporal logic,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8354–8361, 2024
2024
-
[10]
Ltldog: Satisfying temporally- extended symbolic constraints for safe diffusion-based planning,
Z. Feng, H. Luan, P. Goyal, and H. Soh, “Ltldog: Satisfying temporally- extended symbolic constraints for safe diffusion-based planning,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8571–8578, 2024
2024
-
[11]
Monitoring temporal properties of con- tinuous signals,
O. Maler and D. Nickovic, “Monitoring temporal properties of con- tinuous signals,” inFormal Techniques, Modelling and Analysis of Timed and Fault-Tolerant Systems (FTRTFT), ser. Lecture Notes in Computer Science, Y . Lakhnech and S. Yovine, Eds., vol. 3253. Berlin, Heidelberg: Springer, 2004, pp. 152–166
2004
-
[12]
A. Manganaris, V . Giammarino, A. H. Qureshi, and S. Jagannathan, “Formal methods in robot policy learning and verification: A sur- vey on current techniques and future directions,”arXiv preprint arXiv:2602.06971, 2026
arXiv 2026
-
[13]
Stlcg++: A masking approach for differentiable signal temporal logic specification,
P. Kapoor, K. Mizuta, E. Kang, and K. Leung, “Stlcg++: A masking approach for differentiable signal temporal logic specification,”IEEE Robotics and Automation Letters, 2025
2025
-
[14]
Lang2ltl: Translating natural language commands to temporal specification with large language models,
J. X. Liu, Z. Yang, B. Schornstein, S. Liang, I. Idrees, S. Tellex, and A. Shah, “Lang2ltl: Translating natural language commands to temporal specification with large language models,” inWorkshop on Language and Robotics at CoRL 2022, 2022
2022
-
[15]
Lang2ltl-2: Grounding spatiotemporal navigation commands using large language and vision-language models,
J. X. Liu, A. Shah, G. Konidaris, S. Tellex, and D. Paulius, “Lang2ltl-2: Grounding spatiotemporal navigation commands using large language and vision-language models,” in2024 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 2325– 2332
2024
-
[16]
Deepstl: from english requirements to signal temporal logic,
J. He, E. Bartocci, D. Ni ˇckovi´c, H. Isakovic, and R. Grosu, “Deepstl: from english requirements to signal temporal logic,” inProceedings of the 44th International Conference on Software Engineering, 2022, pp. 610–622
2022
-
[17]
Systematic translation from natural language robot task descriptions to stl,
S. Mohammadinejad, S. Paul, Y . Xia, V . Kudalkar, J. Thomason, and J. V . Deshmukh, “Systematic translation from natural language robot task descriptions to stl,” inInternational Conference on Bridging the Gap between AI and Reality. Springer, 2024, pp. 259–276
2024
-
[18]
Stl: Still tricky logic (for system validation, even when showing your work),
I. Hurley, R. Paleja, A. Suh, J. D. Pe ˜na, and H. C. Siu, “Stl: Still tricky logic (for system validation, even when showing your work),”Advances in Neural Information Processing Systems, vol. 37, pp. 119 099–119 122, 2024
2024
-
[19]
Planning with diffu- sion for flexible behavior synthesis,
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffu- sion for flexible behavior synthesis,”arXiv preprint arXiv:2205.09991, 2022
Pith/arXiv arXiv 2022
-
[20]
What matters in learning from offline human demonstrations for robot manipulation,
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipulation,” in Proceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. ...
2022
-
[21]
Strengthening generative robot policies through predictive world modeling,
H. Qi, H. Yin, Y . Du, and H. Yang, “Strengthening generative robot policies through predictive world modeling,”arXiv e-prints, pp. arXiv– 2502, 2025
2025
-
[22]
Safedec: Constrained decoding for safe autoregressive generalist robot policies,
P. Kapoor, A. Ganlath, M. Clifford, C. Liu, S. Scherer, and E. Kang, “Safedec: Constrained decoding for safe autoregressive generalist robot policies,” 2026. [Online]. Available: https://openreview.net/forum?id=dLO7MhVbbB
2026
-
[23]
Baier, J.-P
C. Baier, J.-P. Katoen, and K. G. Larsen,Principles of Model Checking. MIT Press, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.