MSU-Bench: Towards Speaker-Centric Understanding in Conversational Multi-Speaker Scenarios
Pith reviewed 2026-06-26 07:34 UTC · model grok-4.3
The pith
MSU-Bench supplies 2300 QA pairs across 16 tasks to test speaker grounding and multi-speaker reasoning in conversational audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
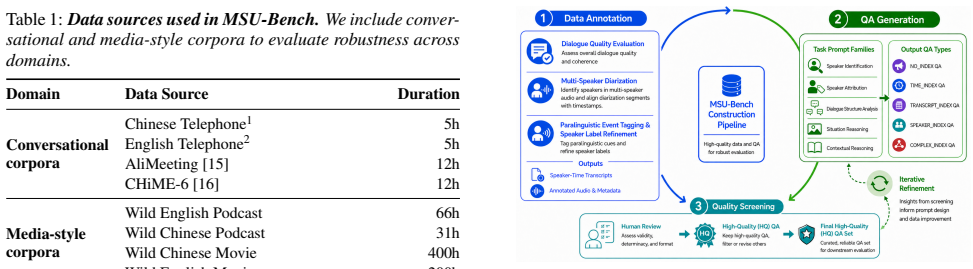
MSU-Bench introduces a benchmark of 16 speaker-centric tasks and 2300 QA instances built through a Gemini-assisted annotation pipeline with human verification, revealing that closed-source models currently lead overall performance while every tested model still encounters clear difficulties with complex speaker grounding and multi-speaker reasoning.
What carries the argument
The two-tier framework that progresses from speaker grounding tasks to dialogue reasoning tasks, together with the speaker-referencing scheme analysis and diagnostic error categorization.
If this is right
- Development of large audio language models must include explicit mechanisms for maintaining speaker identity across turns.
- Error patterns identified in the benchmark point to specific failure modes that training data and objectives should target.
- Closed-source models hold an advantage on current tasks, suggesting differences in scale, data, or alignment that open models need to close.
- The benchmark supplies a standardized way to measure progress on multi-speaker conversational understanding beyond isolated subtasks.
Where Pith is reading between the lines
- The same annotation approach could be applied to create comparable benchmarks in additional languages or acoustic conditions.
- Integration of MSU-Bench scores with single-speaker benchmarks would give a more complete picture of where multi-speaker capability diverges from general speech understanding.
- Persistent gaps on grounding tasks imply that current pretraining corpora under-represent overlapping speech and speaker changes typical of natural conversation.
Load-bearing premise
The Gemini-assisted annotation and human verification process produces QA labels that genuinely measure speaker-centric understanding rather than artifacts of how the questions were generated.
What would settle it
A large-scale re-annotation of the same audio clips by independent human labelers that produces systematically different answers on more than a small fraction of the 2300 instances, or a new model family that scores near ceiling on the hardest grounding and reasoning tasks without any change in speaker tracking architecture.
Figures

read the original abstract
Spoken Language Understanding (SLU) is moving from task-specific pipelines toward large audio language models (LALMs) that generate natural-language responses. However, existing speech benchmarks mainly focus on single-speaker settings or isolated subtasks, leaving speaker-centric understanding in realistic multi-speaker conversations insufficiently evaluated. We introduce MSU-Bench, a diagnostic benchmark for multi-speaker conversational understanding, covering 16 speaker-centric tasks and 2,300 QA instances in a two-tier framework from speaker grounding to dialogue reasoning. We build a Gemini-assisted annotation and QA generation pipeline with human-in-the-loop verification, achieving high QA validity and strong agreement between human answers and verified labels. We further analyze speaker-referencing schemes and diagnostic error types to reveal bottlenecks in speaker grounding and reasoning. Experiments reveal clear gaps across model families, with closed-source systems leading overall but all models still facing challenges in complex speaker grounding and multi-speaker reasoning. The benchmark annotations, metadata, and evaluation scripts will be available at the GitHub repository: https://github.com/ASLP-lab/MSU-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MSU-Bench, a diagnostic benchmark for multi-speaker conversational understanding in spoken language models. It defines 16 speaker-centric tasks and 2,300 QA instances organized in a two-tier framework (speaker grounding to dialogue reasoning), constructed via a Gemini-assisted annotation pipeline with human-in-the-loop verification that reportedly yields high QA validity and strong human-label agreement. Experiments demonstrate performance gaps across model families, with closed-source models leading but all struggling on complex grounding and reasoning; annotations and scripts are to be released.
Significance. If the verification process demonstrably produces labels independent of Gemini artifacts, the benchmark would fill a clear gap in existing SLU evaluations (which are mostly single-speaker or isolated-task) and supply a reproducible diagnostic for LALM development in realistic multi-speaker dialogue. The planned public release of annotations, metadata, and scripts strengthens its potential utility.
major comments (1)
- [Benchmark construction / annotation pipeline] The section describing the annotation pipeline (Gemini-assisted QA generation with human verification) asserts 'high QA validity and strong agreement between human answers and verified labels' yet supplies no quantitative details—inter-annotator agreement statistics, fraction of labels revised, or explicit criteria (e.g., whether annotators saw only audio/transcript or also Gemini drafts). This information is load-bearing for the central claim that the 2,300 instances measure genuine speaker-centric phenomena rather than pipeline artifacts.
minor comments (2)
- [Abstract] The abstract states the benchmark covers '16 speaker-centric tasks and 2,300 QA instances' but does not preview any concrete agreement numbers or error-type statistics that are later claimed to be analyzed; adding one sentence with key figures would improve completeness.
- [Conclusion / data release statement] The GitHub link is given but no mention is made of whether the release will include the raw Gemini prompts or the exact verification guidelines used by annotators; this would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the annotation pipeline. This feedback directly strengthens the manuscript's central claims regarding benchmark validity. We will revise the relevant section to include the requested quantitative details and explicit criteria.
read point-by-point responses
-
Referee: [Benchmark construction / annotation pipeline] The section describing the annotation pipeline (Gemini-assisted QA generation with human verification) asserts 'high QA validity and strong agreement between human answers and verified labels' yet supplies no quantitative details—inter-annotator agreement statistics, fraction of labels revised, or explicit criteria (e.g., whether annotators saw only audio/transcript or also Gemini drafts). This information is load-bearing for the central claim that the 2,300 instances measure genuine speaker-centric phenomena rather than pipeline artifacts.
Authors: We agree that the absence of quantitative statistics and explicit procedural criteria weakens the evidential support for the pipeline's independence from Gemini artifacts. In the revised manuscript we will add: (1) inter-annotator agreement metrics (Cohen's κ and raw percentage agreement) computed on a held-out subset of instances; (2) the exact fraction of Gemini-generated labels that were revised or discarded during human verification; and (3) a clear description of annotator instructions, including whether they viewed only the audio/transcript or also the Gemini draft. These additions will be placed in a new subsection of the benchmark-construction section and will be accompanied by the corresponding numbers and criteria. revision: yes
Circularity Check
No circularity; benchmark construction is self-contained without derivations or fitted predictions
full rationale
The paper introduces a new benchmark (MSU-Bench) with 16 tasks and 2,300 QA instances via a Gemini-assisted pipeline plus human verification. No equations, predictive models, fitted parameters, or derivation chains exist that could reduce outputs to inputs by construction. Claims rest on the benchmark's creation and reported agreement statistics rather than any self-referential prediction or uniqueness theorem. This matches the default case of a non-circular benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Speaker-centric understanding in multi-speaker conversations can be meaningfully evaluated through a two-tier framework of grounding and reasoning tasks.
Reference graph
Works this paper leans on
-
[1]
Introduction Spoken language understanding (SLU) aims to interpret speech beyond verbatim transcription, requiring models to jointly cap- ture linguistic content as well as paralinguistic and pragmatic cues. With the emergence of large audio language models (LALMs) [1, 2, 3], SLU is shifting from task-specific pipelines, such as ASR and speaker analysis, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
The benchmark in- stances are constructed using a scalable annotation and QA gen- eration pipeline with human-in-the-loop verification
MSU-Bench: Hierarchical Design for Multi-Speaker Understanding MSU-Bench evaluates speaker-centric understanding in real- istic multi-speaker conversations through a two-tier task hier- archy and diagnostic multiple-choice QA. The benchmark in- stances are constructed using a scalable annotation and QA gen- eration pipeline with human-in-the-loop verifica...
-
[3]
Experimental Setup and Results We evaluate nine speech-language models on MSU-Bench, in- cluding six open-source models and three closed-source Gem- ini systems. The open-source models include Qwen2.5-Omni, Qwen3-Omni [22], AudioFlamingo-3 [23], Kimi-Audio [24], StepAudio2 [25], and MiMoAudio [26], covering both omni- style and audio-oriented architecture...
-
[4]
Analysis and Discussion We further analyze model behavior and benchmark quality from three diagnostic perspectives: speaker grounding under differ- ent speaker-referencing schemes, diagnostic error-type compo- sition under objective QA, and human verification of QA qual- ity. 4.1. Speaker-Referencing Scheme Analysis Table 4 reports model performance under...
-
[5]
Conclusion We presented MSU-Bench, a speaker-centric benchmark for re- alistic multi-speaker conversations with a two-tier hierarchy, 16 tasks, and 2,300 verified QA instances. Through evalua- tions of nine speech-language models, we show that speaker- referencing schemes and diagnostic error types reveal persistent bottlenecks: temporal grounding is espe...
-
[6]
62401377)
Acknowledgements This research is supported by National Natural Science Foun- dation of China (Grant No. 62401377)
-
[7]
Generative AI Use Disclosure Generative AI tools were used in two distinct capacities in this work. As part of the research methodology, Gemini was em- ployed in the MSU-Bench construction pipeline for dialogue quality assessment, paralinguistic annotation, and QA gener- ation (detailed in Section 2.2). All AI-generated annotations and QA items were subje...
-
[8]
A survey on speech large language models,
J. Peng, Y . Wang, Y . Fang, Y . Xi, X. Li, X. Zhang, and K. Yu, “A survey on speech large language models,”arXiv preprint arXiv:2410.18908, 2024
-
[9]
Audio-language models for audio-centric tasks: A survey,
Y . Su, J. Bai, Q. Xu, K. Xu, and Y . Dou, “Audio-language models for audio-centric tasks: A survey,”arXiv preprint arXiv:2501.15177, 2025
-
[10]
Audiobench: A universal benchmark for audio large language models,
B. Wang, X. Zou, G. Lin, S. Sun, Z. Liu, W. Zhang, Z. Liu, A. Aw, and N. Chen, “Audiobench: A universal benchmark for audio large language models,” inProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 4297–4316
2025
-
[11]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. MA, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=14rn7HpKVk
2024
-
[12]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Osum: Advancing open speech understand- ing models with limited resources in academia,
X. Geng, K. Wei, Q. Shao, S. Liu, Z. Lin, Z. Zhao, G. Li, W. Tian, P. Chen, Y . Liet al., “Osum: Advancing open speech understand- ing models with limited resources in academia,”arXiv preprint arXiv:2501.13306, 2025
-
[14]
H. Yin, Y . Chen, C. Deng, L. Cheng, H. Wang, C.-H. Tan, Q. Chen, W. Wang, and X. Li, “Speakerlm: End-to-end versa- tile speaker diarization and recognition with multimodal large lan- guage models,”arXiv preprint arXiv:2508.06372, 2025
-
[15]
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, infer long: Speech-llm enables zero-shot streamable joint asr and di- arization on long audio,”arXiv preprint arXiv:2511.16046, 2025
-
[16]
Tagspeech: End-to-end multi- speaker asr and diarization with fine-grained temporal grounding,
M. Huo, Y . Shao, and Y . Zhang, “Tagspeech: End-to-end multi- speaker asr and diarization with fine-grained temporal grounding,” arXiv preprint arXiv:2601.06896, 2026
-
[17]
Listening between the frames: Bridging temporal gaps in large audio-language mod- els,
H. Wang, Y . Li, S. Ma, H. Liu, and X. Wang, “Listening between the frames: Bridging temporal gaps in large audio-language mod- els,”arXiv preprint arXiv:2511.11039, 2025
-
[18]
Superb: Speech processing universal performance benchmark,
S.-w. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakho- tia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Linet al., “Superb: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021
-
[19]
Dynamic- superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,
C.-y. Huang, K.-H. Lu, S.-H. Wang, C.-Y . Hsiao, C.-Y . Kuan, H. Wu, S. Arora, K.-W. Chang, J. Shi, Y . Penget al., “Dynamic- superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 136–12 140
2024
-
[20]
S. Cornell, T. Park, S. Huang, C. Boeddeker, X. Chang, M. Ma- ciejewski, M. Wiesner, P. Garcia, and S. Watanabe, “The chime- 8 dasr challenge for generalizable and array agnostic distant automatic speech recognition and diarization,”arXiv preprint arXiv:2407.16447, 2024
-
[21]
A review of speaker diarization: Recent advances with deep learning,
T. J. Park, N. Kanda, D. Dimitriadis, K. J. Han, S. Watanabe, and S. Narayanan, “A review of speaker diarization: Recent advances with deep learning,”Computer Speech & Language, vol. 72, p. 101317, 2022
2022
-
[22]
M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,
F. Yu, S. Zhang, Y . Fu, L. Xie, S. Zheng, Z. Du, W. Huang, P. Guo, Z. Yan, B. Ma, X. Xu, and H. Bu, “M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,” inProc. ICASSP. IEEE, 2022
2022
-
[23]
CHiME-6 Challenge: Tackling Multispeaker Speech Recogni- tion for Unsegmented Recordings,
S. Watanabe, M. Mandel, J. Barker, E. Vincent, A. Arora, X. Chang, S. Khudanpur, V . Manohar, D. Povey, D. Raj, D. Sny- der, A. S. Subramanian, J. Trmal, B. B. Yair, C. Boeddeker, Z. Ni, Y . Fujita, S. Horiguchi, N. Kanda, T. Yoshioka, and N. Ryant, “CHiME-6 Challenge: Tackling Multispeaker Speech Recogni- tion for Unsegmented Recordings,” in6th Internati...
2020
-
[24]
An overview of speaker identifica- tion: Accuracy and robustness issues,
R. Togneri and D. Pullella, “An overview of speaker identifica- tion: Accuracy and robustness issues,”IEEE circuits and systems magazine, vol. 11, no. 2, pp. 23–61, 2011
2011
-
[25]
Accent classi- fication in speech,
S. Deshpande, S. Chikkerur, and V . Govindaraju, “Accent classi- fication in speech,” inFourth IEEE Workshop on Automatic Iden- tification Advanced Technologies (AutoID’05). IEEE, 2005, pp. 139–143
2005
-
[26]
Emotion, age, and gender classification in children’s speech by humans and machines,
H. Kaya, A. A. Salah, A. Karpov, O. Frolova, A. Grigorev, and E. Lyakso, “Emotion, age, and gender classification in children’s speech by humans and machines,”Computer Speech & Language, vol. 46, pp. 268–283, 2017
2017
-
[27]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE inter- national conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780
2017
-
[28]
V ocalsound: A dataset for improv- ing human vocal sounds recognition,
Y . Gong, J. Yu, and J. Glass, “V ocalsound: A dataset for improv- ing human vocal sounds recognition,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2022, pp. 151–155
2022
-
[29]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.- H. H. Yang, R. Duraiswami, D. Manocha, R. Valleet al., “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,”arXiv preprint arXiv:2507.08128, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Mimo-audio: Audio language models are few-shot learners.arXiv preprint arXiv:2512.23808,
D. Zhang, G. Wang, J. Xue, K. Fang, L. Zhao, R. Ma, S. Ren, S. Liu, T. Guo, W. Zhuanget al., “Mimo-audio: Audio language models are few-shot learners,”arXiv preprint arXiv:2512.23808, 2025
-
[34]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.