VideoLatent: Video-Language Learning via Latent Self-Forcing
Pith reviewed 2026-06-26 09:23 UTC · model grok-4.3
The pith
VideoLatent learns video reasoning in latent space from standard QA triplets alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
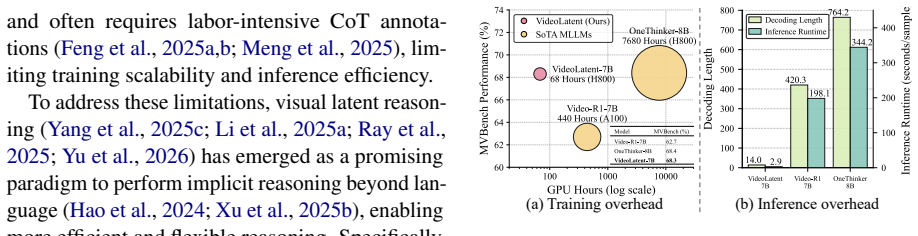
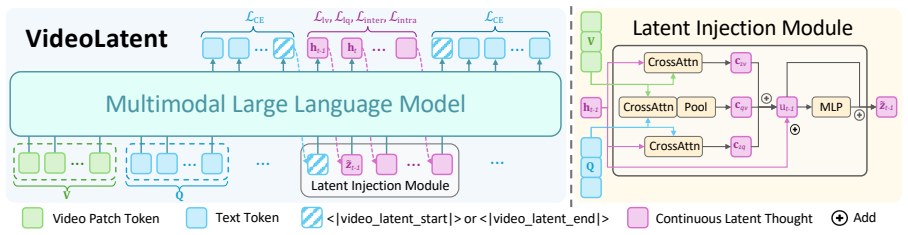
The authors claim that their VideoLatent model, equipped with a latent injection module, can perform visual latent reasoning for video tasks by training with a latent self-forcing paradigm that includes latent alignment and latent diversity objectives. These objectives are applied using only standard video-question-answer triplets, without reliance on CoT traces, auxiliary images, or fine-grained annotations. This results in consistent outperformance on general video understanding and complex reasoning across 14 benchmarks, along with major efficiency improvements.
What carries the argument
Latent self-forcing training paradigm consisting of latent alignment and latent diversity objectives that guide the generation of useful visual latents for reasoning.
If this is right
- Outperforms standard and latent MLLMs on 14 video benchmarks for understanding and reasoning.
- Reduces training overhead by approximately 6 times and inference overhead by approximately 68 times relative to Video-R1.
- Generalizes effectively across different MLLM backbones and model scales.
- Supports video-language learning without labor-intensive CoT annotations or auxiliary supervision.
Where Pith is reading between the lines
- The same objectives could potentially be applied to other video-related tasks such as captioning or action recognition.
- Efficiency improvements may enable training on much larger video datasets than previously feasible.
- Latent reasoning might transfer to real-time applications where CoT methods are too slow.
Load-bearing premise
The latent alignment and diversity objectives trained solely on standard video-QA triplets are enough to create visual latents that enable effective reasoning without additional supervision.
What would settle it
Demonstrating on a held-out video reasoning task that performance does not exceed that of a standard MLLM baseline when no CoT or extra annotations are used.
Figures

read the original abstract
Recent advancements in chain-of-thought (CoT) reasoning have shown promise in enhancing video understanding and reasoning capabilities of multimodal large language models (MLLMs). However, existing CoT-based MLLMs require labor-intensive CoT annotations and incur substantial training and inference overhead. While visual latent reasoning has emerged as a more efficient alternative, existing methods primarily focus on image tasks and heavily rely on additional supervision signals for visual latent generation (e.g., CoT traces, auxiliary images, or fine-grained annotations), limiting their scalability and transferability to video tasks. To bridge this gap, we introduce VideoLatent, a novel MLLM equipped with a latent injection module tailored for video understanding and reasoning. Specifically, VideoLatent learns to perform visual latent reasoning using a new latent self-forcing training paradigm, which comprises latent alignment and latent diversity objectives, and relies solely on standard video-question-answer triplets. Extensive experiments across 14 benchmarks demonstrate that our model consistently outperforms existing standard and latent MLLMs on general video understanding and complex video reasoning. Compared with Video-R1, our VideoLatent achieves superior computational efficiency, reducing training/inference overhead by $\sim$6$\times$/$\sim$68$\times$. Moreover, experiments demonstrate that our method has strong generalizability to different MLLM backbones and different model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoLatent, an MLLM for video understanding and reasoning equipped with a latent injection module. It proposes a latent self-forcing training paradigm consisting of latent alignment and latent diversity objectives that are optimized solely on standard video-QA triplets (no CoT traces or auxiliary signals). The central claims are consistent outperformance versus standard and latent MLLMs on 14 benchmarks plus large efficiency gains versus Video-R1 (∼6× training, ∼68× inference) and generalizability across backbones and scales.
Significance. If the central sufficiency claim holds, the work would be significant: it offers a scalable route to visual latent reasoning for video without labor-intensive CoT annotations, directly addressing a scalability bottleneck in prior latent-reasoning methods. The reported efficiency numbers, if reproducible and fairly matched, would constitute a practical advance for deployment.
major comments (2)
- [Experiments / Method] The central claim that latent alignment + diversity objectives (trained only on video-QA triplets) suffice to induce visual latents supporting complex reasoning is load-bearing yet unsupported by visible evidence. No ablation isolates the contribution of these objectives versus the injection module or training recipe; gains on reasoning benchmarks could therefore be explained by other factors.
- [Experiments] Efficiency comparison to Video-R1 (∼6×/∼68×) is presented without explicit statement of how baselines were matched for model size, data, or optimization; this is required to substantiate the claim and is absent from the reported results.
minor comments (1)
- [Abstract] Notation for the efficiency ratios uses approximate symbols without defining the exact measurement protocol (wall-clock, FLOPs, or tokens).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below with clarifications and commitments to revisions that strengthen the experimental evidence without altering the core claims.
read point-by-point responses
-
Referee: [Experiments / Method] The central claim that latent alignment + diversity objectives (trained only on video-QA triplets) suffice to induce visual latents supporting complex reasoning is load-bearing yet unsupported by visible evidence. No ablation isolates the contribution of these objectives versus the injection module or training recipe; gains on reasoning benchmarks could therefore be explained by other factors.
Authors: We agree that isolating the objectives is important for substantiating the central claim. The manuscript reports overall gains from the full VideoLatent pipeline but does not include dedicated ablations separating latent alignment, latent diversity, and the injection module. In the revision we will add these ablations (full model vs. module-only vs. objectives-ablated variants) on the same video-QA triplets to demonstrate that the self-forcing objectives are responsible for the reasoning improvements beyond the injection module alone. revision: yes
-
Referee: [Experiments] Efficiency comparison to Video-R1 (∼6×/∼68×) is presented without explicit statement of how baselines were matched for model size, data, or optimization; this is required to substantiate the claim and is absent from the reported results.
Authors: We acknowledge that the efficiency section would benefit from explicit matching details. The reported ∼6× training and ∼68× inference gains versus Video-R1 were obtained using the same backbone scale and comparable volumes of standard video-QA triplets under matched optimization settings. In the revision we will expand the experimental protocol subsection to state the exact model sizes, data quantities, and hyperparameter matching used for the Video-R1 baseline, ensuring the comparison is fully reproducible and fair. revision: yes
Circularity Check
No circularity: new objectives presented as empirical additions without definitional reduction
full rationale
The provided abstract and description introduce VideoLatent via a latent self-forcing paradigm consisting of alignment and diversity objectives trained exclusively on standard video-QA triplets. No equations, parameter-fitting steps, or self-citations are shown that would make any claimed prediction or uniqueness result equivalent to its own inputs by construction. Performance and efficiency claims are framed as outcomes of experiments across benchmarks rather than derivations that loop back to fitted values or prior author work. The central sufficiency assumption is an empirical hypothesis, not a self-referential definition, so the derivation chain remains independent of the target results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CoRR , volume =
OpenAI , title =. CoRR , volume =
-
[2]
LLaMA: Open and Efficient Foundation Language Models , journal =
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. LLaMA: Open and Efficient Foundation Language Models , journal =
-
[3]
CoRR , volume =
Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan ...
-
[4]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , booktitle =
-
[5]
CoRR , volume =
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
-
[6]
CoRR , volume =
Jinze Bai and Shuai Bai and Shusheng Yang and Shijie Wang and Sinan Tan and Peng Wang and Junyang Lin and Chang Zhou and Jingren Zhou , title =. CoRR , volume =
-
[7]
Junnan Li and Dongxu Li and Silvio Savarese and Steven C. H. Hoi , title =
-
[8]
Yanwei Li and Yuechen Zhang and Chengyao Wang and Zhisheng Zhong and Yixin Chen and Ruihang Chu and Shaoteng Liu and Jiaya Jia , title =
-
[9]
CoRR , volume =
Feng Li and Renrui Zhang and Hao Zhang and Yuanhan Zhang and Bo Li and Wei Li and Zejun Ma and Chunyuan Li , title =. CoRR , volume =
-
[10]
Bin Lin and Yang Ye and Bin Zhu and Jiaxi Cui and Munan Ning and Peng Jin and Li Yuan , title =
-
[11]
NeurIPS , year =
Haotian Liu and Chunyuan Li and Qingyang Wu and Yong Jae Lee , title =. NeurIPS , year =
-
[12]
Beyond Embeddings: The Promise of Visual Table in Visual Reasoning , booktitle =
Yiwu Zhong and Zi. Beyond Embeddings: The Promise of Visual Table in Visual Reasoning , booktitle =
-
[13]
2024 , note =
OpenAI , title =. 2024 , note =
2024
-
[14]
2025 , note =
OpenAI , title =. 2025 , note =
2025
-
[15]
CoRR , volume =
Gemini Team , title =. CoRR , volume =
-
[16]
CoRR , volume =
ByteDance Seed , title =. CoRR , volume =
-
[17]
Lillicrap and Jean
Machel Reid and Nikolay Savinov and Denis Teplyashin and Dmitry Lepikhin and Timothy P. Lillicrap and Jean. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , journal =
-
[18]
Enhancing Temporal Modeling of Video LLMs via Time Gating , booktitle =
Zi. Enhancing Temporal Modeling of Video LLMs via Time Gating , booktitle =
-
[19]
Ji Lin and Hongxu Yin and Wei Ping and Pavlo Molchanov and Mohammad Shoeybi and Song Han , title =
-
[20]
Yuanhan Zhang and Jinming Wu and Wei Li and Bo Li and Zejun Ma and Ziwei Liu and Chunyuan Li , title =. Trans. Mach. Learn. Res. , volume =
-
[21]
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Peiyuan Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , title =. Trans. Mach. Learn. Res. , volume =
-
[22]
Jiabo Ye and Haiyang Xu and Haowei Liu and Anwen Hu and Ming Yan and Qi Qian and Ji Zhang and Fei Huang and Jingren Zhou , title =
-
[23]
Muhammad Maaz and Hanoona Abdul Rasheed and Salman Khan and Fahad Khan , title =
-
[24]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models , booktitle =
Matt Deitke and Christopher Clark and Sangho Lee and Rohun Tripathi and Yue Yang and Jae Sung Park and Mohammadreza Salehi and Niklas Muennighoff and Kyle Lo and Luca Soldaini and Jiasen Lu and Taira Anderson and Erin Bransom and Kiana Ehsani and Huong Ngo and Yen. Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models , b...
-
[25]
CoRR , volume =
Weiyun Wang and Zhangwei Gao and Lixin Gu and Hengjun Pu and Long Cui and Xingguang Wei and Zhaoyang Liu and Linglin Jing and Shenglong Ye and Jie Shao and Zhaokai Wang and Zhe Chen and Hongjie Zhang and Ganlin Yang and Haomin Wang and Qi Wei and Jinhui Yin and Wenhao Li and Erfei Cui and Guanzhou Chen and Zichen Ding and Changyao Tian and Zhenyu Wu and J...
-
[26]
Zhijian Liu and Ligeng Zhu and Baifeng Shi and Zhuoyang Zhang and Yuming Lou and Shang Yang and Haocheng Xi and Shiyi Cao and Yuxian Gu and Dacheng Li and Xiuyu Li and Haotian Tang and Yunhao Fang and Yukang Chen and Cheng
-
[27]
Wenliang Dai and Junnan Li and Dongxu Li and Anthony Meng Huat Tiong and Junqi Zhao and Weisheng Wang and Boyang Li and Pascale Fung and Steven C. H. Hoi , title =. NeurIPS , year =
-
[28]
CoRR , volume =
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Ming. CoRR , volume =
-
[29]
CoRR , volume =
Qwen Team , title =. CoRR , volume =
-
[30]
CoRR , volume =
Kaituo Feng and Kaixiong Gong and Bohao Li and Zonghao Guo and Yibing Wang and Tianshuo Peng and Benyou Wang and Xiangyu Yue , title =. CoRR , volume =
-
[31]
CoRR , volume =
Xingjian Zhang and Siwei Wen and Wenjun Wu and Lei Huang , title =. CoRR , volume =
-
[32]
CoRR , volume =
Qi Wang and Yanrui Yu and Ye Yuan and Rui Mao and Tianfei Zhou , title =. CoRR , volume =
-
[33]
CoRR , volume =
Kaituo Feng and Manyuan Zhang and Hongyu Li and Kaixuan Fan and Shuang Chen and Yilei Jiang and Dian Zheng and Peiwen Sun and Yiyuan Zhang and Haoze Sun and Yan Feng and Peng Pei and Xunliang Cai and Xiangyu Yue , title =. CoRR , volume =
-
[34]
CoRR , volume =
Shuming Liu and Mingchen Zhuge and Changsheng Zhao and Jun Chen and Lemeng Wu and Zechun Liu and Chenchen Zhu and Zhipeng Cai and Chong Zhou and Haozhe Liu and Ernie Chang and Saksham Suri and Hongyu Xu and Qi Qian and Wei Wen and Balakrishnan Varadarajan and Zhuang Liu and Hu Xu and Florian Bordes and Raghuraman Krishnamoorthi and Bernard Ghanem and Vika...
-
[35]
CoRR , volume =
Ziang Yan and Xinhao Li and Yinan He and Zhengrong Yue and Xiangyu Zeng and Yali Wang and Yu Qiao and Limin Wang and Yi Wang , title =. CoRR , volume =
-
[36]
CoRR , volume =
Zefeng He and Xiaoye Qu and Yafu Li and Siyuan Huang and Daizong Liu and Yu Cheng , title =. CoRR , volume =
-
[37]
Haotian Liu and Chunyuan Li and Yuheng Li and Yong Jae Lee , title =
-
[38]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[39]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[40]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[41]
Kunchang Li and Yali Wang and Yinan He and Yizhuo Li and Yi Wang and Yi Liu and Zun Wang and Jilan Xu and Guo Chen and Ping Lou and Limin Wang and Yu Qiao , title =
-
[42]
Yuanxin Liu and Shicheng Li and Yi Liu and Yuxiang Wang and Shuhuai Ren and Lei Li and Sishuo Chen and Xu Sun and Lu Hou , title =
-
[43]
Chaoyou Fu and Yuhan Dai and Yongdong Luo and Lei Li and Shuhuai Ren and Renrui Zhang and Zihan Wang and Chenyu Zhou and Yunhang Shen and Mengdan Zhang and Peixian Chen and Yanwei Li and Shaohui Lin and Sirui Zhao and Ke Li and Tong Xu and Xiawu Zheng and Enhong Chen and Caifeng Shan and Ran He and Xing Sun , title =
-
[44]
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions , booktitle =
Junbin Xiao and Xindi Shang and Angela Yao and Tat. NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions , booktitle =
-
[45]
Junjie Zhou and Yan Shu and Bo Zhao and Boya Wu and Zhengyang Liang and Shitao Xiao and Minghao Qin and Xi Yang and Yongping Xiong and Bo Zhang and Tiejun Huang and Zheng Liu , title =
-
[46]
NeurIPS , year =
Haoning Wu and Dongxu Li and Bei Chen and Junnan Li , title =. NeurIPS , year =
-
[47]
Weihan Wang and Zehai He and Wenyi Hong and Yean Cheng and Xiaohan Zhang and Ji Qi and Ming Ding and Xiaotao Gu and Shiyu Huang and Bin Xu and Yuxiao Dong and Jie Tang , title =
-
[48]
CoRR , volume =
Yukun Qi and Yiming Zhao and Yu Zeng and Xikun Bao and Wenxuan Huang and Lin Chen and Zehui Chen and Jie Zhao and Zhongang Qi and Feng Zhao , title =. CoRR , volume =
-
[49]
Shaker and Anqi Tang and Muhammad Maaz and Ming
Hanoona Abdul Rasheed and Abdelrahman M. Shaker and Anqi Tang and Muhammad Maaz and Ming. VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos , journal =
-
[50]
CoRR , volume =
Kairui Hu and Penghao Wu and Fanyi Pu and Wang Xiao and Yuanhan Zhang and Xiang Yue and Bo Li and Ziwei Liu , title =. CoRR , volume =
-
[51]
Yuanhan Zhang and Yunice Chew and Yuhao Dong and Aria Leo and Bo Hu and Ziwei Liu , title =
-
[52]
Yilun Zhao and Haowei Zhang and Lujing Xie and Tongyan Hu and Guo Gan and Yitao Long and Zhiyuan Hu and Weiyuan Chen and Chuhan Li and Zhijian Xu and Chengye Wang and Ziyao Shangguan and Zhenwen Liang and Yixin Liu and Chen Zhao and Arman Cohan , title =
-
[53]
Benno Krojer and Mojtaba Komeili and Candace Ross and Quentin Garrido and Koustuv Sinha and Nicolas Ballas and Mido Assran , title =. Trans. Mach. Learn. Res. , volume =
-
[54]
Gupta and Rilyn Han and Li Fei
Jihan Yang and Shusheng Yang and Anjali W. Gupta and Rilyn Han and Li Fei. Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces , booktitle =
-
[55]
Cambrian-S: Towards Spatial Supersensing in Video , journal =
Shusheng Yang and Jihan Yang and Pinzhi Huang and Ellis Brown and Zihao Yang and Yue Yu and Shengbang Tong and Zihan Zheng and Yifan Xu and Muhan Wang and Daohan Lu and Rob Fergus and Yann LeCun and Li Fei. Cambrian-S: Towards Spatial Supersensing in Video , journal =
-
[56]
Perception Test:
Viorica Patraucean and Lucas Smaira and Ankush Gupta and Adri. Perception Test:. NeurIPS , year =
-
[57]
CoRR , volume =
Junhao Cheng and Yuying Ge and Teng Wang and Yixiao Ge and Jing Liao and Ying Shan , title =. CoRR , volume =
-
[58]
CoRR , volume =
Yukang Chen and Wei Huang and Baifeng Shi and Qinghao Hu and Hanrong Ye and Ligeng Zhu and Zhijian Liu and Pavlo Molchanov and Jan Kautz and Xiaojuan Qi and Sifei Liu and Hongxu Yin and Yao Lu and Song Han , title =. CoRR , volume =
-
[59]
CoRR , volume =
Zihui Xue and Mi Luo and Kristen Grauman , title =. CoRR , volume =
-
[60]
CoRR , volume =
Jianrui Zhang and Mu Cai and Yong Jae Lee , title =. CoRR , volume =
-
[61]
Guo Chen and Yicheng Liu and Yifei Huang and Baoqi Pei and Jilan Xu and Yuping He and Tong Lu and Yali Wang and Limin Wang , title =
-
[62]
Wenyi Hong and Yean Cheng and Zhuoyi Yang and Weihan Wang and Lefan Wang and Xiaotao Gu and Shiyu Huang and Yuxiao Dong and Jie Tang , title =
-
[63]
Ziyao Shangguan and Chuhan Li and Yuxuan Ding and Yanan Zheng and Yilun Zhao and Tesca Fitzgerald and Arman Cohan , title =
-
[64]
Daniel Cores and Michael Dorkenwald and Manuel Mucientes and Cees G. M. Snoek and Yuki M. Asano , title =. CoRR , volume =
-
[65]
CoRR , volume =
Mu Cai and Reuben Tan and Jianrui Zhang and Bocheng Zou and Kai Zhang and Feng Yao and Fangrui Zhu and Jing Gu and Yiwu Zhong and Yuzhang Shang and Yao Dou and Jaden Park and Jianfeng Gao and Yong Jae Lee and Jianwei Yang , title =. CoRR , volume =
-
[66]
CoRR , volume =
Kejian Zhu and Zhuoran Jin and Hongbang Yuan and Jiachun Li and Shangqing Tu and Pengfei Cao and Yubo Chen and Kang Liu and Jun Zhao , title =. CoRR , volume =
-
[67]
Jiashuo Yu and Yue Wu and Meng Chu and Zhifei Ren and Zizheng Huang and Pei Chu and Ruijie Zhang and Yinan He and Qirui Li and Songze Li and Zhenxiang Li and Zhongying Tu and Conghui He and Yu Qiao and Yali Wang and Yi Wang and Limin Wang , title =
-
[68]
Jeff Rasley and Samyam Rajbhandari and Olatunji Ruwase and Yuxiong He , title =
-
[69]
Girshick , title =
Kaiming He and Haoqi Fan and Yuxin Wu and Saining Xie and Ross B. Girshick , title =
-
[70]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , title =. NeurIPS , year =
-
[71]
Zhuosheng Zhang and Aston Zhang and Mu Li and Alex Smola , title =
-
[72]
Zhuosheng Zhang and Aston Zhang and Mu Li and Hai Zhao and George Karypis and Alex Smola , title =. Trans. Mach. Learn. Res. , volume =
-
[73]
Chancharik Mitra and Brandon Huang and Trevor Darrell and Roei Herzig , title =
-
[74]
DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models , booktitle =
Ge Zheng and Bin Yang and Jiajin Tang and Hong. DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models , booktitle =
-
[75]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =
-
[76]
CoRR , volume =
Shulin Tian and Ruiqi Wang and Hongming Guo and Penghao Wu and Yuhao Dong and Xiuying Wang and Jingkang Yang and Hao Zhang and Hongyuan Zhu and Ziwei Liu , title =. CoRR , volume =
-
[77]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =
-
[78]
CoRR , volume =
Jiahao Meng and Xiangtai Li and Haochen Wang and Yue Tan and Tao Zhang and Lingdong Kong and Yunhai Tong and Anran Wang and Zhiyang Teng and Yujing Wang and Zhuochen Wang , title =. CoRR , volume =
-
[79]
Ziyang Wang and Jaehong Yoon and Shoubin Yu and Md Mohaiminul Islam and Gedas Bertasius and Mohit Bansal , title =
-
[80]
arXiv preprint arXiv:2503.13377 , year=
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding , author=. arXiv preprint arXiv:2503.13377 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.