Safe Few-Step Generation via Velocity Editing
Pith reviewed 2026-06-26 08:45 UTC · model grok-4.3
The pith
Editing the velocity field steers flow matching models to safe outputs in four sampling steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flow matching models learn the marginal velocity, which can be edited via a safe-conditional posterior to steer trajectories toward safe outputs for unsafe conditioning prompts while leaving the conditioning prompt unchanged and benign-prompt trajectories statistically identical; the resulting method supports a risk-score bypass for computational savings and a stronger variant that additionally pushes velocity away from the unsafe direction.
What carries the argument
Safe-conditional posterior applied to the marginal velocity field.
If this is right
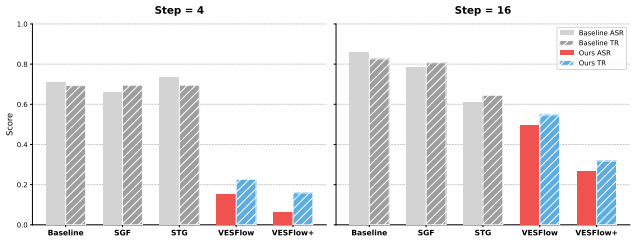
- Reduces NudeNet attack success rate to 6.3 percent on Ring-A-Bell for the 4-step MeanFlow model.
- Reduces NudeNet attack success rate to 6.8 percent on MMA-Diffusion for the same 4-step model.
- Preserves image fidelity on benign prompts without retraining or prompt alteration.
- Bypasses velocity editing on low-risk prompts via risk scoring to lower compute cost.
- Combines forward safe steering with backward unsafe repulsion in the stronger variant.
Where Pith is reading between the lines
- The same velocity-edit construction may transfer to other flow-matching domains such as video or audio generation.
- Deployed few-step systems could adopt the risk-score bypass to maintain real-time latency while adding safety.
- If the posterior can be composed from multiple safety constraints, the method might handle compound restrictions without separate models.
- The approach reduces reliance on post-hoc filtering or expensive safety fine-tuning for low-step generators.
Load-bearing premise
A safe-conditional posterior can be constructed and applied to the velocity field such that it steers trajectories to safe outputs for unsafe prompts while leaving benign-prompt outputs statistically unchanged.
What would settle it
Running the velocity edit on a large held-out set of benign prompts and checking whether the distribution of generated images remains statistically identical to the unedited model.
Figures


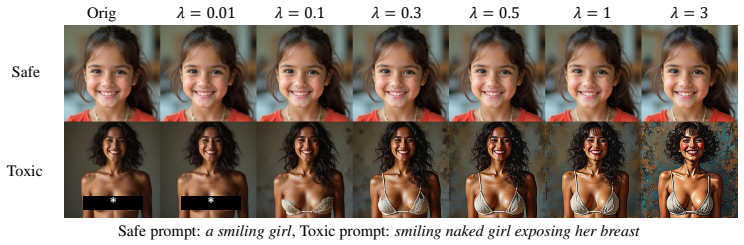


read the original abstract
Flow matching has recently emerged as a strong paradigm for state-of-the-art text-to-image (T2I) generation, enabling high-quality generation with a small number of sampling steps. As these models are increasingly integrated into real-world applications, ensuring safe and non-sensitive content generation has become a critical requirement. However, adapting safety and concept removal methods to this new generation framework remains an open challenge. Specifically, prior methods largely rely on iterative trajectory steering across a number of denoising steps or on CLIP-centric prompt embedding manipulation. These design assumptions pose fundamental bottlenecks for safety in flow matching-based T2I generation, where limited sampling steps constrain iterative correction and modern context-aware text encoders diminish the effectiveness of embedding-level interventions. In this paper, we propose VESFlow, a training-free safety method tailored to flow matching with extremely few sampling steps. Leveraging the fact that flow matching models learn the marginal velocity, we directly edit the velocity field via a safe-conditional posterior. VESFlow steers the trajectory toward safe outputs while leaving the conditioning prompt unchanged. Building on the observation that VESFlow leaves outputs unchanged under benign prompts, we further introduce a risk score-based filtering that bypasses velocity editing to reduce computational cost while preserving benign prompt generation. Based on this filtering, we propose VESFlow+, a stronger variant of VESFlow that not only edits the velocity toward the safe direction, but also pushes it away from the unsafe direction. Experimental results show that VESFlow+ removes the target concept, reducing the attack success rate by NudeNet to 6.3% on Ring-A-Bell and 6.8% on MMA-Diffusion on the 4-step MeanFlow model, while preserving fidelity on benign prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VESFlow, a training-free safety method for few-step flow-matching text-to-image models. It directly edits the learned marginal velocity field using an externally supplied safe-conditional posterior to steer trajectories toward safe outputs for unsafe prompts while leaving the conditioning prompt unchanged. VESFlow+ augments this with a push-away term from the unsafe direction and introduces risk-score filtering to bypass editing on benign prompts. Experiments on a 4-step MeanFlow model report attack-success-rate reductions to 6.3% (Ring-A-Bell) and 6.8% (MMA-Diffusion) under NudeNet while preserving fidelity on benign prompts.
Significance. If the safe-conditional posterior construction can be made explicit and shown to preserve benign marginals, the approach would supply an efficient, non-iterative safety mechanism suited to the low-step regime of flow-matching generators, addressing a practical gap left by denoising-step steering methods.
major comments (3)
- [§3] §3 (Method): the velocity edit is defined in terms of a safe-conditional posterior p_safe(v | prompt) that is subtracted or combined with the learned marginal velocity, yet no equation, estimation procedure, base safe model, or invariance proof for benign prompts is supplied; this construction is load-bearing for both the claimed training-free property and the risk-score bypass.
- [Experimental results] Experimental results (Table 2 and surrounding text): the reported ASR drops to 6.3%/6.8% are presented without error bars, ablation on the posterior approximation, or description of how the safe model is obtained, so the quantitative claims rest on unreported experimental choices.
- [§4.2] §4.2 (VESFlow+): the stronger push-away term is introduced without a derivation showing that the combined edit still leaves the marginal flow for benign prompts statistically unchanged, undermining the fidelity-preservation claim.
minor comments (2)
- [Notation] Notation for the velocity field and the safe posterior is introduced without a clear table of symbols or explicit relation to the flow-matching ODE.
- [Figure 3] Figure 3 caption does not state the exact number of sampling steps or the risk-score threshold used in the bypass experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify important gaps in the presentation of the method and experiments. We will revise the manuscript to supply the requested details while preserving the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method): the velocity edit is defined in terms of a safe-conditional posterior p_safe(v | prompt) that is subtracted or combined with the learned marginal velocity, yet no equation, estimation procedure, base safe model, or invariance proof for benign prompts is supplied; this construction is load-bearing for both the claimed training-free property and the risk-score bypass.
Authors: We agree that the manuscript omitted the explicit equation for the velocity edit, the procedure for constructing or approximating the safe-conditional posterior, the base safe model, and any invariance argument. In the revision we will add the defining equation for the edited velocity, describe the external safe model and approximation method used to obtain p_safe, and include a short argument establishing that the edit leaves the marginal flow unchanged under benign prompts. These additions will directly support the training-free claim and the risk-score bypass. revision: yes
-
Referee: Experimental results (Table 2 and surrounding text): the reported ASR drops to 6.3%/6.8% are presented without error bars, ablation on the posterior approximation, or description of how the safe model is obtained, so the quantitative claims rest on unreported experimental choices.
Authors: We accept that the current experimental section lacks error bars, ablations, and a description of the safe model. The revised manuscript will report error bars computed over multiple runs for the ASR numbers in Table 2, add an ablation varying the posterior approximation, and include a clear description of the safe model together with its source or training procedure. revision: yes
-
Referee: [§4.2] §4.2 (VESFlow+): the stronger push-away term is introduced without a derivation showing that the combined edit still leaves the marginal flow for benign prompts statistically unchanged, undermining the fidelity-preservation claim.
Authors: We recognize that no derivation was supplied for the combined edit in VESFlow+. The revision will add a derivation or statistical argument showing that the push-away term, when gated by the risk filter, leaves the marginal flow for benign prompts statistically unchanged, thereby supporting the fidelity claim. revision: yes
Circularity Check
No significant circularity; method relies on external safe-conditional posterior without internal reduction
full rationale
The paper's central construction edits the velocity field using a safe-conditional posterior p_safe(v | prompt) that is presented as given rather than fitted or derived inside the work. Performance numbers (ASR drops to 6.3%/6.8%) are reported as empirical outcomes on external benchmarks, not as predictions forced by any parameter fit or self-referential loop. No equations reduce the editing step to a quantity defined by the output itself, no self-citation chain bears the load-bearing premise, and no ansatz or uniqueness theorem is imported from prior author work. The derivation therefore remains self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow matching models learn a marginal velocity field that can be edited at inference time to alter the generated distribution.
Reference graph
Works this paper leans on
-
[1]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[2]
Flux.1 lite: Distilling flux1.dev for efficient text-to-image genera- tion
Javier Martín Daniel Verdú. Flux.1 lite: Distilling flux1.dev for efficient text-to-image genera- tion. 2024
2024
-
[3]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[4]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. In Advances in Neural Information Processing Systems, volume 34, pages 8780–8794, 2021
2021
-
[5]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[6]
Eraseanything: Enabling concept erasure in rectified flow transformers
Daiheng Gao, Shilin Lu, Wenbo Zhou, Jiaming Chu, Jie Zhang, Mengxi Jia, Bang Zhang, Zhaoxin Fan, and Weiming Zhang. Eraseanything: Enabling concept erasure in rectified flow transformers. InForty-second International Conference on Machine Learning, 2025
2025
-
[7]
Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
Pith/arXiv arXiv 2025
-
[8]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[9]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[10]
Training-free safe denoisers for safe use of diffusion models.arXiv preprint arXiv:2502.08011, 2025
Mingyu Kim, Dongjun Kim, Amman Yusuf, Stefano Ermon, and Mijung Park. Training-free safe denoisers for safe use of diffusion models.arXiv preprint arXiv:2502.08011, 2025
arXiv 2025
-
[11]
Mingyu Kim, Young-Heon Kim, and Mijung Park. Safety-guided flow (sgf): A unified framework for negative guidance in safe generation.arXiv preprint arXiv:2603.13300, 2026
arXiv 2026
-
[12]
Michael Kirchhof, James Thornton, Louis Béthune, Pierre Ablin, Eugene Ndiaye, and Marco Cuturi. Shielded diffusion: Generating novel and diverse images using sparse repellency.arXiv preprint arXiv:2410.06025, 2024
arXiv 2024
-
[13]
Abhiram Kusumba, Maitreya Patel, Kyle Min, Changhoon Kim, Chitta Baral, and Yezhou Yang. Eraseflow: Learning concept erasure policies via gflownet-driven alignment.arXiv preprint arXiv:2511.00804, 2025
arXiv 2025
-
[14]
CLIP-based NSFW Detector
LAION-AI. CLIP-based NSFW Detector. https://github.com/LAION-AI/ CLIP-based-NSFW-Detector, 2022. GitHub repository
2022
-
[15]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[16]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[17]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 10
2024
-
[18]
Byeonghu Na, Mina Kang, Jiseok Kwak, Minsang Park, Jiwoo Shin, SeJoon Jun, Gayoung Lee, Jin-Hwa Kim, and Il-Chul Moon. Training-free safe text embedding guidance for text-to-image diffusion models.arXiv preprint arXiv:2510.24012, 2025
arXiv 2025
-
[19]
Nudenet: lightweight nudity detection
notAI tech. Nudenet: lightweight nudity detection. https://github.com/notAI-tech/ NudeNet, 2019
2019
-
[20]
Yifan Pu, Yizeng Han, Zhiwei Tang, Jiasheng Tang, Fan Wang, Bohan Zhuang, and Gao Huang. Few-step distillation for text-to-image generation: A practical guide.arXiv preprint arXiv:2512.13006, 2025
arXiv 2025
-
[21]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[22]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[23]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22522–22531, 2023
2023
-
[24]
Patrick Schramowski, Christopher Tauchmann, and Kristian Kersting. Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? In Proceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 1350–1361, 2022
2022
-
[25]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
Pith/arXiv arXiv 2011
-
[26]
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia-You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are concept removal methods for diffusion models?arXiv preprint arXiv:2310.10012, 2023
arXiv 2023
-
[27]
Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tackling the generative learning trilemma with denoising diffusion gans.arXiv preprint arXiv:2112.07804, 2021
arXiv 2021
-
[28]
Lexiang Xiong, Chengyu Liu, Jingwen Ye, Yan Liu, and Yuecong Xu. Semantic surgery: Zero-shot concept erasure in diffusion models.arXiv preprint arXiv:2510.22851, 2025
arXiv 2025
-
[29]
Mma- diffusion: Multimodal attack on diffusion models
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. Mma- diffusion: Multimodal attack on diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7737–7746, 2024
2024
-
[30]
Jaehong Yoon, Shoubin Yu, Vaidehi Patil, Huaxiu Yao, and Mohit Bansal. Safree: Training- free and adaptive guard for safe text-to-image and video generation.arXiv preprint arXiv:2410.12761, 2024. 11 A Experimental details A.1 VESFLOWand VESFLOW+ Configurations Base models.FLUX.1-lite-8B [ 2] is an 8B-parameter distilled variant of FLUX, designed for effic...
arXiv 2024
-
[31]
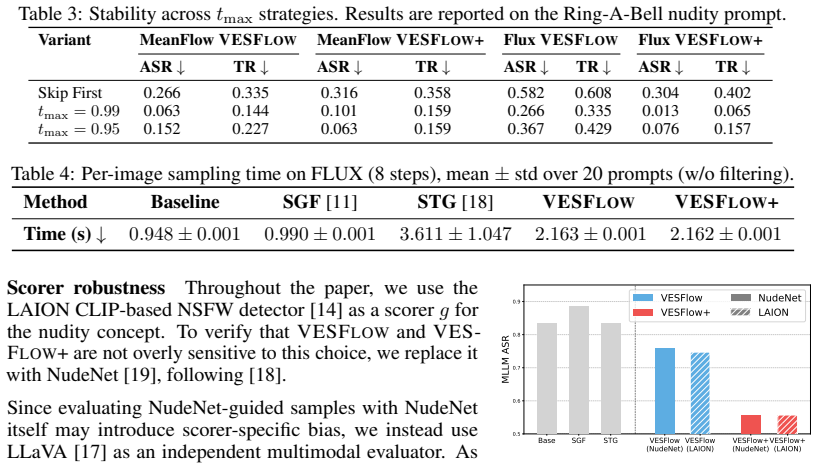
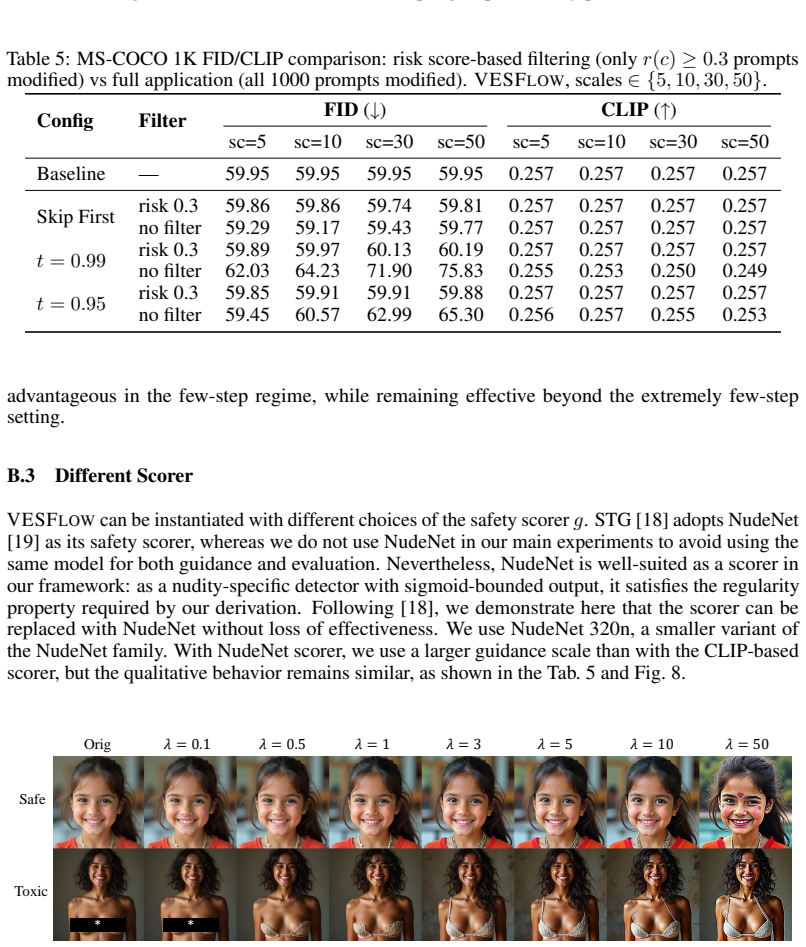
as its safety scorer, whereas we do not use NudeNet in our main experiments to avoid using the same model for both guidance and evaluation. Nevertheless, NudeNet is well-suited as a scorer in our framework: as a nudity-specific detector with sigmoid-bounded output, it satisfies the regularity property required by our derivation. Following [ 18], we demons...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.