Discovering Latent Groups for Robust Classification
Pith reviewed 2026-06-26 08:35 UTC · model grok-4.3
The pith
Neural classification trees disentangle latent subgroups by routing samples to easy or hard nodes using prediction correctness as pseudo-labels, without needing subgroup labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
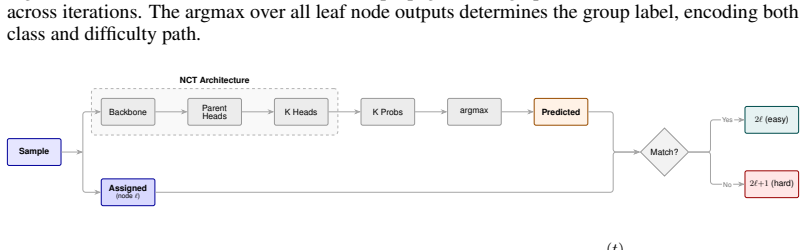
By building a tree-shaped network and routing each sample to an easy or hard node according to prediction correctness, then reusing the routes as pseudo-labels in subsequent iterations, neural classification trees disentangle conflicting subgroups in the absence of subgroup supervision, while producing both robust class predictions and an interpretable tree topology that isolates minority subgroups.
What carries the argument
Neural classification trees that route samples to easy or hard nodes based on prediction correctness and reuse those routes as pseudo-labels to separate latent subgroups.
If this is right
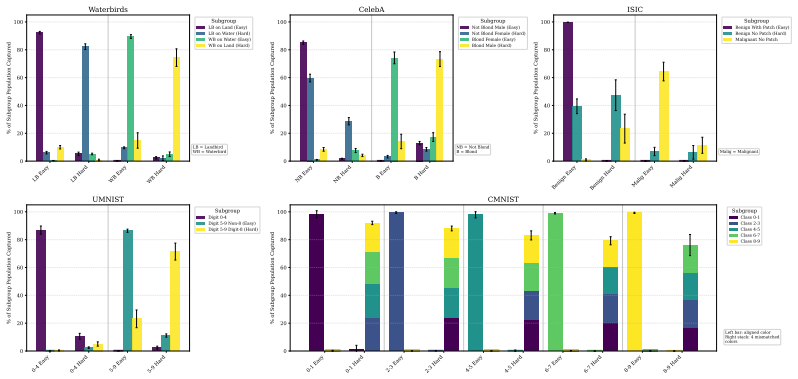
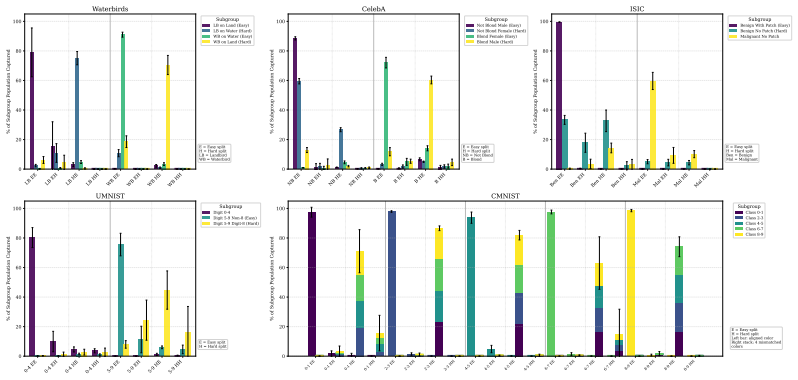
- The tree topology consistently isolates minority subgroups across the five evaluated benchmarks.
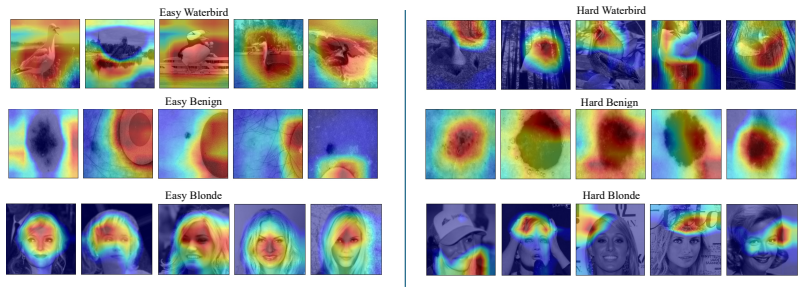
- The architecture supplies a transparent mapping between model structure and the data's latent group structure.
- The method achieves competitive robustness with existing state-of-the-art approaches that rely on pseudo-group labels.
- At inference the model returns both a class prediction and the subgroup path through the tree.
Where Pith is reading between the lines
- The routing mechanism could be adapted to other model families beyond trees to surface latent structure.
- The approach may help debug models by making the learned group separations explicit in the architecture.
- Prediction errors might serve as a general unsupervised signal for discovering hidden data partitions in other settings.
Load-bearing premise
Routing decisions based only on whether the current model predicts a sample correctly will reliably surface and separate the latent subgroup structure over iterations without any external supervision.
What would settle it
A controlled dataset with known spurious correlations where the learned tree routes fail to isolate the minority subgroup or where the routes do not align with the actual group structure after several iterations.
Figures

read the original abstract
Machine learning models exploit spurious correlations, achieving high average accuracy but failing disproportionately on underrepresented subgroups. Existing methods address this by adjusting network parameters, guided either by subgroup annotations or inferred pseudo-group labels. Yet at inference, these methods produce only a class prediction, with no insight into a sample's latent subgroup. We propose neural classification trees (NCT), a framework that achieves robustness by encoding subgroup structure in its tree-shaped architecture. By routing each sample to an "easy" or "hard" node of this tree -- based on prediction correctness -- and reusing these routes as pseudo-labels for the next iteration, NCT disentangles conflicting subgroups, without requiring subgroup supervision. We evaluate NCT on five benchmarks spanning binary and multi-class spurious correlations. Our experiments show that the learned tree topology provides strong interpretability by consistently isolating minority subgroups, which provides a transparent mapping between the model architecture and the data's latent group structure, while yielding competitive robustness with state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Neural Classification Trees (NCT), a tree-shaped neural architecture for robust classification under spurious correlations. Samples are routed to 'easy' or 'hard' nodes based on whether the current model predicts them correctly; these routes are then reused as pseudo-labels to train the next iteration of the tree. The method claims to disentangle latent subgroups without subgroup annotations, yielding both competitive robustness on five benchmarks and interpretability via a tree topology that isolates minority subgroups.
Significance. If the central claim holds, NCT would be notable for embedding subgroup structure directly in the model architecture rather than post-hoc adjustment, providing both robustness and a transparent mapping from architecture to latent groups. This is a strength relative to methods that output only class predictions. The iterative pseudo-labeling approach, if shown to progressively isolate groups rather than reinforce initial biases, could offer a new direction for unsupervised robust learning.
major comments (2)
- [Method description (abstract and §3)] The core mechanism (routing by prediction correctness and reusing routes as pseudo-labels) is load-bearing for the claim of disentangling subgroups without supervision. However, when the initial model is dominated by spurious correlations, early routing decisions are likely to group minority samples with majority samples that share the same spurious feature; this can lock in a non-separating partition rather than isolate latent groups. The manuscript provides no theoretical analysis or ablation demonstrating that the process escapes this fixed point.
- [Abstract and Experiments (§4)] The abstract states that NCT yields 'competitive robustness with state-of-the-art methods' on five benchmarks, yet the provided text contains no quantitative results, tables, error bars, or implementation details (e.g., tree depth, routing threshold, loss weighting). Without these, the empirical support for the central claim cannot be assessed.
minor comments (2)
- [Method] Notation for the 'easy' and 'hard' nodes and the precise definition of the routing function should be formalized with equations rather than prose description.
- [Method] The paper should clarify whether the tree topology is learned jointly or grown iteratively, and how the final inference uses the learned routes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The core mechanism (routing by prediction correctness and reusing routes as pseudo-labels) is load-bearing for the claim of disentangling subgroups without supervision. However, when the initial model is dominated by spurious correlations, early routing decisions are likely to group minority samples with majority samples that share the same spurious feature; this can lock in a non-separating partition rather than isolate latent groups. The manuscript provides no theoretical analysis or ablation demonstrating that the process escapes this fixed point.
Authors: We acknowledge the referee's concern that early routing decisions based on an initial model biased by spurious correlations could potentially reinforce non-separating partitions. The manuscript does not contain a formal theoretical analysis of the iterative process or its fixed points. Our empirical evaluation across the five benchmarks shows that the resulting tree topologies consistently isolate minority subgroups, providing evidence that the process does not lock into non-separating partitions in the evaluated settings. We will add further ablations on routing threshold sensitivity and initial model variations in the revision. revision: partial
-
Referee: [Abstract and Experiments (§4)] The abstract states that NCT yields 'competitive robustness with state-of-the-art methods' on five benchmarks, yet the provided text contains no quantitative results, tables, error bars, or implementation details (e.g., tree depth, routing threshold, loss weighting). Without these, the empirical support for the central claim cannot be assessed.
Authors: We apologize for the omission of quantitative results, tables, error bars, and implementation details in the text provided for review. The full manuscript includes these elements in §4, with performance tables on the five benchmarks (including error bars from multiple runs) and hyperparameter details such as tree depth, routing threshold, and loss weighting. We will revise the manuscript to ensure all empirical results and implementation details are explicitly included and referenced. revision: yes
Circularity Check
No circularity: iterative routing is an algorithmic procedure, not a definitional reduction
full rationale
The paper describes an iterative training loop in which samples are routed to easy/hard nodes using the current model's prediction correctness and those routes are then treated as pseudo-labels for the next iteration. This is a standard self-training mechanism applied to a tree architecture; the abstract and method description contain no equations that define the final subgroup disentanglement or robustness metric as a direct function of the same fitted quantities by construction. No self-citation is invoked as a uniqueness theorem or load-bearing premise, and no ansatz or renaming of known results is presented as a derivation. The central claim therefore rests on the empirical behavior of the algorithm under its stated assumptions rather than on any self-referential identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural network training can produce useful predictors whose correctness signals subgroup structure
invented entities (1)
-
Neural Classification Tree (NCT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nature Machine Intelligence , author =
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard S Zemel, Wieland Brendel, Matthias Bethge, and Felix Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2:665–673, 2020. doi: 10.1038/s42256-020-00257-z
-
[2]
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. InInternational Conference on Learning Representations, 2020
2020
-
[3]
Maas, Ran Tao, and Tatsunori B
Shuxian Liu, Kai-Wei Chang, Andrew L. Maas, Ran Tao, and Tatsunori B. Hashimoto. Just train twice: Improving group robustness without training group information. InInternational Conference on Machine Learning, 2021
2021
-
[4]
Environment inference for invariant learning
Elliot Creager, Jörn-Henrik Jacobsen, and Richard Zemel. Environment inference for invariant learning. InInternational Conference on Machine Learning, 2021
2021
-
[5]
Last layer re-training is sufficient for robustness to spurious correlations
Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. Last layer re-training is sufficient for robustness to spurious correlations. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[6]
Sohoni, Jared A
Nimit S. Sohoni, Jared A. Dunnmon, Geoffrey Angus, Albert Gu, and Christopher Ré. No subclass left behind: Fine-grained robustness in coarse-grained classification problems. In Advances in Neural Information Processing Systems, volume 33, pages 19339–19352, 2020
2020
-
[7]
Exmap: Leveraging explainability heatmaps for unsupervised group robustness to spurious correlations
Rwiddhi Chakraborty, Adrian Sletten, and Michael C Kampffmeyer. Exmap: Leveraging explainability heatmaps for unsupervised group robustness to spurious correlations. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[8]
Correct-n-contrast: A contrastive approach for improving robustness to spurious correlations
Michael Zhang, Nimit S Sohoni, Hongyang R Zhang, Chelsea Finn, and Christopher Ré. Correct-n-contrast: A contrastive approach for improving robustness to spurious correlations. InInternational Conference on Machine Learning (ICML), pages 26484–26516. PMLR, 2022
2022
-
[9]
Discovering environments with xrm
Mohammad Pezeshki, Diane Bouchacourt, Mark Ibrahim, Nicolas Ballas, Pascal Vincent, and David Lopez-Paz. Discovering environments with xrm. InInternational Conference on Machine Learning, 2024
2024
-
[10]
Learning from failure: Training debiased classifier from biased classifier
Junhyun Nam, Hyuntak Cha, Sungsoo Ahn, Jaeho Lee, and Jinwoo Shin. Learning from failure: Training debiased classifier from biased classifier. InAdvances in Neural Information Processing Systems, 2020
2020
-
[11]
Selecmix: Debiased learning by contradicting-pair sampling
Inwoo Hwang, Sangjun Lee, Yunhyeok Kwak, Seong Joon Oh, Damien Teney, Jin-Hwa Kim, and Byoung-Tak Zhang. Selecmix: Debiased learning by contradicting-pair sampling. In Advances in Neural Information Processing Systems, 2022
2022
-
[12]
Improving group robustness on spurious correlation requires preciser group inference
Yujin Han and Difan Zou. Improving group robustness on spurious correlation requires preciser group inference. InInternational Conference on Machine Learning (ICML), pages 17480– 17504, 2024
2024
-
[13]
Masktune: Mitigating spurious correlations by forcing to explore
Saeid Asgari Taghanaki, Kumar Abhishek, Kenji Kawaguchi, and Amir Azimi. Masktune: Mitigating spurious correlations by forcing to explore. InAdvances in Neural Information Processing Systems, 2022
2022
-
[14]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational Conference on Machine Learning (ICML), pages 5338–5348. PMLR, 2020
2020
-
[15]
Hacihadibadi
Md Rifat Arefin, Yan Zhang, Elnaz Barshan, Xiang Yue, Kenji Kawaguchi, and H. Hacihadibadi. Unsupervised concept discovery mitigates spurious correlations. InInternational Conference on Machine Learning (ICML). PMLR, 2024
2024
-
[16]
Neural prototype trees for interpretable fine-grained image recognition
Meike Nauta, Ron van Bree, and Christin Seifert. Neural prototype trees for interpretable fine-grained image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14933–14943, 2021. 10
2021
-
[17]
Gonzalez
Alvin Wan, Lisa Dunlap, Daniel Ho, Jihan Yin, Scott Lee, Henry Jin, Suzanne Petryk, Sarah Adel Bargal, and Joseph E. Gonzalez. NBDT: Neural-backed decision tree. InIn- ternational Conference on Learning Representations (ICLR), 2021
2021
-
[18]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeffrey Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[19]
Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
1991
-
[20]
Adaptive neural trees
Ryutaro Tanno, Kai Arulkumaran, Daniel Alexander, Antonio Criminisi, and Aditya Nori. Adaptive neural trees. InInternational Conference on Machine Learning (ICML), pages 6166–6175. PMLR, 2019
2019
-
[21]
Catastrophic interference in connectionist networks: The sequential learning problem.Psychology of learning and motivation, 24:109–165, 1989
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem.Psychology of learning and motivation, 24:109–165, 1989
1989
-
[22]
The pitfalls of simplicity bias in neural networks
Harshay Shah, Kaustav Tamuly, Aditi Raghunathan, Prateek Jain, and Praneeth Netrapalli. The pitfalls of simplicity bias in neural networks. InAdvances in Neural Information Processing Systems, volume 33, pages 9573–9585, 2020
2020
-
[23]
The origins and prevalence of texture bias in convolutional neural networks
Katherine Hermann, Ting Chen, and Simon Kornblith. The origins and prevalence of texture bias in convolutional neural networks. InAdvances in Neural Information Processing Systems, volume 33, pages 19000–19015, 2020
2020
-
[24]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), 2015
2015
-
[25]
Noel C. F. Codella, David Gutman, M. Emre Celebi, Brian Helba, Michael A. Marchetti, Stephen W. Dusza, Aadi Kalloo, Konstantinos Liopyris, Nabin Mishra, Harald Kittler, and Allan Halpern. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging co...
2017
-
[26]
The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5(1): 1–9, 2018
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5(1): 1–9, 2018
2018
-
[27]
Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
Pith/arXiv arXiv 1907
-
[28]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009
2009
-
[29]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[30]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[31]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[32]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2623–2631, 2019. 11
2019
-
[33]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[34]
The caltech- ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech- ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011
2011
-
[35]
RRC” = RandomResizedCrop; “RC(s, p)
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1452–1464, 2018. 12 Appendix Contents A Extended Experimental Setup 14 A.1 Dataset Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.