Improving Radio Source Count Estimation Using Kernel Density Estimation
Pith reviewed 2026-06-25 23:00 UTC · model grok-4.3
The pith
Kernel density estimation produces more accurate radio source counts than traditional binning, especially at high fluxes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KDE-based approaches yield more accurate and stable estimates of differential radio source counts than binned methods, particularly in the high-flux regime, and can incorporate continuous weights to address observational incompleteness.
What carries the argument
Kernel density estimation (KDE), which places a kernel function at each observed flux and sums the contributions to produce a continuous density estimate.
If this is right
- KDE removes the need to choose bin widths and reduces boundary effects at the bright end.
- Adaptive KDE automatically adjusts smoothing where source density changes rapidly.
- Weighted KDE applies incompleteness corrections continuously rather than in discrete bins.
- Some secondary features seen only in binned analyses of real data disappear under KDE, indicating they are artifacts.
Where Pith is reading between the lines
- The same KDE machinery could be tested on source-count problems at other wavelengths where flux-limited samples are also incomplete.
- If adopted, the approach would allow consistent re-analysis of legacy survey data without re-binning decisions.
- The stability at high fluxes suggests KDE estimates could tighten constraints on the bright-end slope of luminosity functions.
Load-bearing premise
The simulated flux-limited samples derived from an input luminosity function model faithfully represent the statistical properties and incompleteness of real observational data.
What would settle it
Comparison of KDE-derived counts against source counts measured in a deeper, more complete survey whose completeness function is independently known.
Figures

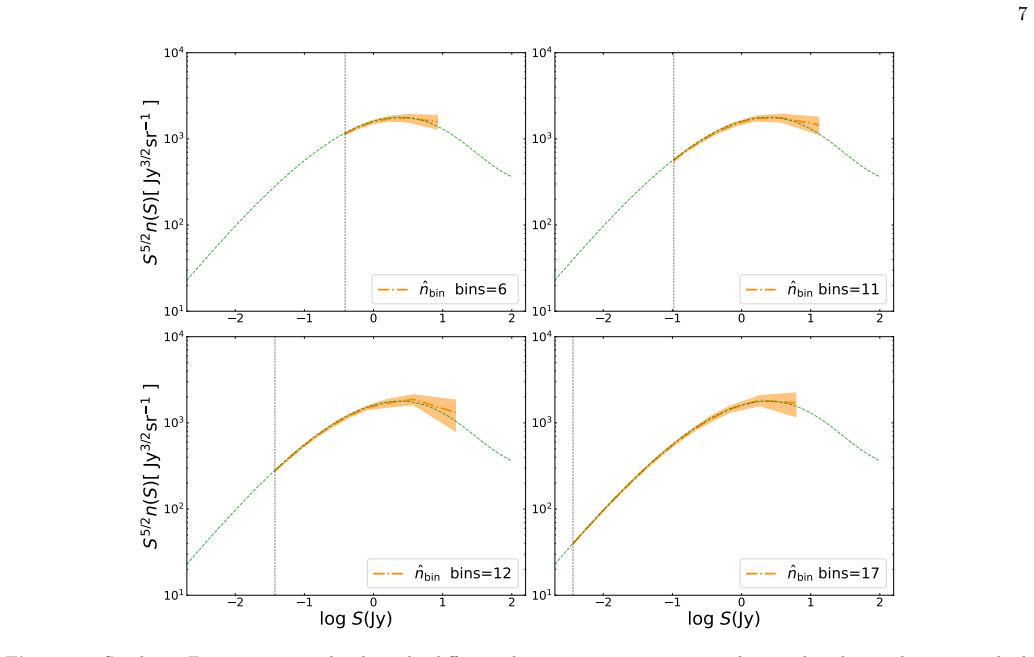




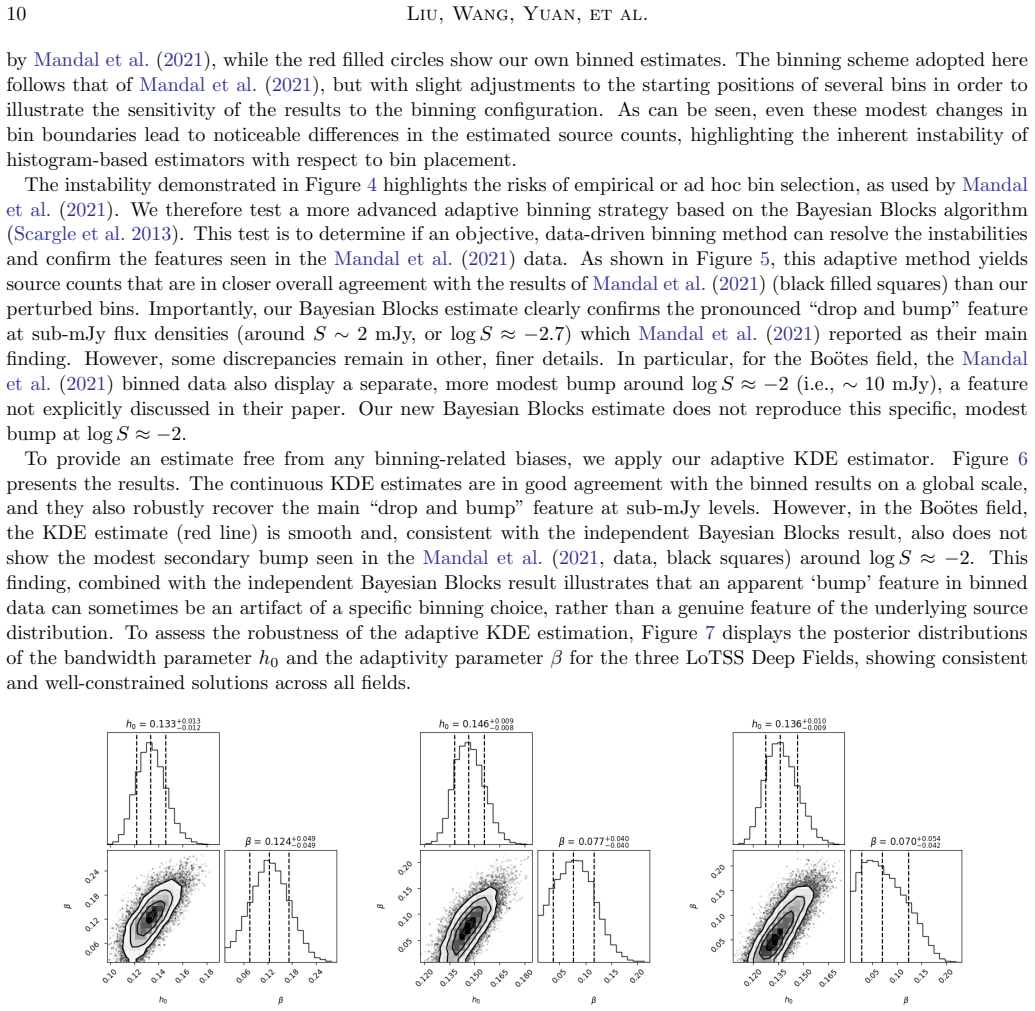
read the original abstract
Radio source counts provide a fundamental census of cosmic radio emission, yet their estimation is usually based on coarse histograms that suffer from bin-choice bias, boundary effects, and survey incompleteness. We apply and rigorously evaluate kernel density estimation (KDE) as a anonparametric alternative to the conventional binned method for estimating differential radio source counts. Using simulated flux-limited samples derived from an input luminosity function model, we compare the performance of standard KDE, adaptive KDE, and traditional binning methods. Our results show that KDE-based approaches yield more accurate and stable estimates, particularly in the high-flux regime where data are sparse and conventional methods struggle. We also apply the adaptive KDE method to real observational data from the LOFAR Two-Metre Sky Survey Deep Fields. Our analysis robustly confirms the pronounced ``drop and bump" feature at sub-mJy flux densities, but also reveals that a secondary, modest bump seen in the binned data at ~ $\sim 10$ mJy is likely a binning artifact. We also demonstrate the flexibility of KDE in addressing observational incompleteness through weighted estimation, which applies weights continuously at the level of individual sources rather than averaging them in discrete bins. These strengths make KDE a powerful tool for source-count analyses in current and future radio surveys and, more broadly, in analogous studies at other wavelengths. All computations in this study are implemented with \texttt{AstroKDE}, a Python package we have developed for astronomical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that kernel density estimation (KDE), including adaptive and weighted variants, yields more accurate and stable estimates of differential radio source counts than conventional binned histograms, especially in the sparse high-flux regime. This is demonstrated by recovering known counts from flux-limited samples simulated from an input luminosity function model, with application to LOFAR Two-Metre Sky Survey Deep Fields data confirming the sub-mJy drop-and-bump feature while attributing a ~10 mJy secondary bump to binning artifacts. The work also shows KDE's flexibility for handling incompleteness via per-source weights and provides the AstroKDE Python package for implementation.
Significance. If the performance gains hold under broader validation, the nonparametric KDE approach could meaningfully reduce bin-choice bias and boundary effects in radio source count analyses, benefiting studies of cosmic radio emission and analogous problems at other wavelengths. The provision of the AstroKDE package and emphasis on reproducible computations are strengths that support wider adoption.
major comments (3)
- [Simulation setup and results] Simulation and validation section: The accuracy claim rests on recovering the input luminosity function from samples generated under that same model (including its selection and incompleteness prescription). This tests internal consistency but does not directly establish superiority for real data whose true distribution may deviate; the manuscript should either test multiple independent input models or provide a quantitative sensitivity analysis to model choice.
- [Application to real data] LOFAR application and results: The assertion that the ~10 mJy bump is a binning artifact requires explicit uncertainty quantification (e.g., bootstrap or analytic KDE variance) on the adaptive KDE estimate to demonstrate that the feature is statistically insignificant, rather than relying on visual comparison alone.
- [Comparison methodology] Methods: The paper states KDE approaches are 'more accurate' but does not specify the exact error metric(s) (e.g., integrated squared error, Kolmogorov-Smirnov statistic, or binned χ2) or report numerical values/tables comparing KDE versus binning across flux regimes; without these, the quantitative support for the central performance claim cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: 'anonparametric' is a typographical error and should read 'a nonparametric'.
- [Methods] The manuscript should include a brief description of the kernel function and bandwidth selection method (e.g., cross-validation or rule-of-thumb) used in the AstroKDE implementation for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which has identified several areas where the manuscript can be strengthened. We address each major comment below and will incorporate the suggested revisions to improve the clarity and robustness of our claims.
read point-by-point responses
-
Referee: Simulation and validation section: The accuracy claim rests on recovering the input luminosity function from samples generated under that same model (including its selection and incompleteness prescription). This tests internal consistency but does not directly establish superiority for real data whose true distribution may deviate; the manuscript should either test multiple independent input models or provide a quantitative sensitivity analysis to model choice.
Authors: We agree that the current simulation setup demonstrates internal consistency for a single realistic input model but does not fully address sensitivity to model assumptions. In the revised manuscript, we will add a quantitative sensitivity analysis by perturbing key parameters of the luminosity function (e.g., faint-end slope and normalization) across a range of plausible values, recomputing the recovered source counts with both KDE and binned methods, and reporting the resulting variations in accuracy metrics. This will be presented in an expanded simulation section with additional figures and tables. revision: yes
-
Referee: LOFAR application and results: The assertion that the ~10 mJy bump is a binning artifact requires explicit uncertainty quantification (e.g., bootstrap or analytic KDE variance) on the adaptive KDE estimate to demonstrate that the feature is statistically insignificant, rather than relying on visual comparison alone.
Authors: We concur that visual comparison is insufficient to establish statistical insignificance. We will revise the LOFAR results section to include bootstrap resampling (with 1000 resamples) of the adaptive KDE estimates, providing uncertainty bands on the differential source counts. This will demonstrate quantitatively that the ~10 mJy feature lies within the 1-sigma uncertainty envelope while the sub-mJy drop-and-bump remains significant, with the new analysis added to the text and figures. revision: yes
-
Referee: Methods: The paper states KDE approaches are 'more accurate' but does not specify the exact error metric(s) (e.g., integrated squared error, Kolmogorov-Smirnov statistic, or binned χ2) or report numerical values/tables comparing KDE versus binning across flux regimes; without these, the quantitative support for the central performance claim cannot be evaluated.
Authors: The referee correctly notes the lack of explicit quantitative metrics. We will update the methods and results sections to define the error metrics used (integrated squared error for differential counts and Kolmogorov-Smirnov statistic for cumulative distributions), and add a new table summarizing numerical values of these metrics for KDE variants versus binning across low-, mid-, and high-flux regimes. This will provide the requested quantitative support for the performance claims. revision: yes
Circularity Check
No circularity: validation against known input model is independent benchmark
full rationale
The paper generates flux-limited samples from an explicit input luminosity function model, then measures how well KDE recovers the known differential counts versus binning. This is a standard external-truth test (the model supplies the ground truth), not a fit-then-predict or self-definition loop. Real-data application to LOFAR is presented separately without claiming quantitative accuracy from the simulations. No self-citations, uniqueness theorems, or ansatzes are invoked to force the result. The assumption that the simulation faithfully captures real incompleteness is a modeling limitation, not a circular reduction of the claimed derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Kernel density estimation accurately recovers the underlying density from samples under appropriate kernel and bandwidth choices.
Reference graph
Works this paper leans on
-
[1]
Abramson, I. 1982, Annals of Statistics, 10, 1217 Biggs, A. D., & Ivison, R. J. 2006, MNRAS, 371, 963, doi: 10.1111/j.1365-2966.2006.10730.x 13
-
[2]
2024, Kernel Density Estimators in Large Dimensions
Biroli, G., & M´ ezard, M. 2024, Kernel Density Estimators in Large Dimensions. https://arxiv.org/abs/2408.05807
arXiv 2024
-
[3]
2012, ApJS, 203, 15, doi: 10.1088/0067-0049/203/1/15
Bonzini, M., Mainieri, V., Padovani, P., et al. 2012, ApJS, 203, 15, doi: 10.1088/0067-0049/203/1/15
-
[4]
Borys, C., Scott, D., Chapman, S., et al. 2004, MNRAS, 355, 485, doi: 10.1111/j.1365-2966.2004.08335.x
-
[5]
Botev, Z. I., Grotowski, J. F., & Kroese, D. P. 2010, The Annals of Statistics, 38, doi: 10.1214/10-aos799
-
[6]
Breiman, L., Meisel, W. S., & Purcell, E. A. 1977, Technometrics, 19, 135, doi: 10.2307/1267744
-
[7]
Cochrane, R. K., Kondapally, R., Best, P. N., et al. 2023, MNRAS, 523, 6082, doi: 10.1093/mnras/stad1602
-
[8]
Condon, J. J. 1974, ApJ, 188, 279, doi: 10.1086/152714
-
[9]
, archivePrefix = "arXiv", eprint =
Condon, J. J., Cotton, W. D., Fomalont, E. B., et al. 2012, ApJ, 758, 23, doi: 10.1088/0004-637X/758/1/23
-
[10]
1967, Nature, 216, 1076, doi: 10.1038/2161076a0
Davidson, W. 1967, Nature, 216, 1076, doi: 10.1038/2161076a0
-
[11]
M., Marshall, J
Davies, T. M., Marshall, J. C., & Hazelton, M. L. 2018, Statistics in Medicine, 37, 1191
2018
-
[12]
Eddington, Sir, A. S. 1940, MNRAS, 100, 354, doi: 10.1093/mnras/100.5.354
-
[13]
1998, A&AS, 127, 335, doi: 10.1051/aas:1998355
Fadda, D., Slezak, E., & Bijaoui, A. 1998, A&AS, 127, 335, doi: 10.1051/aas:1998355
-
[14]
J., Buddelmeijer, H., Trager, S
Ferdosi, B. J., Buddelmeijer, H., Trager, S. C., Wilkinson, M. H. F., & Roerdink, J. B. T. M. 2011, A&A, 531, A114, doi: 10.1051/0004-6361/201116878
-
[15]
Franzen, T. M. O., Jackson, C. A., Offringa, A. R., et al. 2016, Monthly Notices of the Royal Astronomical Society, 459, 3314–3325, doi: 10.1093/mnras/stw823
-
[16]
Garn, T., Green, D. A., Riley, J. M., & Alexander, P. 2008, MNRAS, 383, 75, doi: 10.1111/j.1365-2966.2007.12562.x
-
[17]
Gasser, T., & M¨ uller, H. G. 1979, in Lectures Notes in
1979
-
[18]
2018, Studies in Big Data, Vol
Gramacki, A. 2018, Studies in Big Data, Vol. 37, Nonparametric Kernel Density Estimation and Its Computational Aspects (Springer), doi: 10.1007/978-3-319-71688-6
-
[19]
Gully, H., Hatch, N., Ahad, S. L., et al. 2025, MNRAS, 539, 3058, doi: 10.1093/mnras/staf635
-
[20]
Hall, P., & Park, B. U. 2002, Annals of Statistics, 30, 1460
2002
-
[21]
Hatfield, P. W., Lindsay, S. N., Jarvis, M. J., et al. 2016, MNRAS, 459, 2618, doi: 10.1093/mnras/stw769
-
[22]
Huynh, M. T., Jackson, C. A., Norris, R. P., & Prandoni, I. 2005, AJ, 130, 1373, doi: 10.1086/432873
-
[23]
2016, in MeerKAT Science: On the Pathway to the SKA, 6, doi: 10.22323/1.277.0006
Jarvis, M., Taylor, R., Agudo, I., et al. 2016, in MeerKAT Science: On the Pathway to the SKA, 6, doi: 10.22323/1.277.0006
-
[24]
Jones, M. C. 1993, Statistics and Computing, 3, 135, doi: 10.1007/BF00147776
-
[25]
Kapinska, A. D. 2020, in American Astronomical Society Meeting Abstracts, Vol. 236, American Astronomical Society Meeting Abstracts #236, 322.06
2020
-
[26]
Kellermann, K. I., Condon, J. J., Kimball, A. E., Perley, R. A., & Ivezi´ c,ˇZ. 2016, ApJ, 831, 168, doi: 10.3847/0004-637X/831/2/168
-
[27]
Longair, M. S. 1966, MNRAS, 133, 421, doi: 10.1093/mnras/133.4.421 —. 2011, High Energy Astrophysics
-
[28]
2014, Computational Statistics & Data Analysis, 72, 57
Maleca, P., & Schienle, M. 2014, Computational Statistics & Data Analysis, 72, 57
2014
-
[29]
Mandal, S., Prandoni, I., Hardcastle, M. J., et al. 2021, A&A, 648, A5, doi: 10.1051/0004-6361/202039998
-
[30]
S., & Ruppert, D
Marron, J. S., & Ruppert, D. 1994, Journal of the Royal Statistical Society Series B, 56, 653
1994
-
[31]
Marshall, J. C., & Hazelton, M. L. 2010, Journal of Multivariate Analysis, 101, 949 Mart´ ın-Navarro, I., & Mezcua, M. 2018, The Astrophysical Journal Letters, 855, L20, doi: 10.3847/2041-8213/aab103
-
[32]
Massardi, M., Bonaldi, A., Negrello, M., et al. 2010, MNRAS, 404, 532, doi: 10.1111/j.1365-2966.2010.16305.x
-
[33]
Mauch, T., & Sadler, E. M. 2007, MNRAS, 375, 931, doi: 10.1111/j.1365-2966.2006.11353.x
-
[34]
Mokkadem, A., Pelletier, M., & Thiam, B. 2006, Large and moderate deviations principles for recursive kernel estimators of a multivariate density and its partial derivatives. https://arxiv.org/abs/math/0601429
Pith/arXiv arXiv 2006
-
[35]
2016, A&A Rv, 24, 13, doi: 10.1007/s00159-016-0098-6
Padovani, P. 2016, A&A Rv, 24, 13, doi: 10.1007/s00159-016-0098-6
-
[36]
Padovani, P., Bonzini, M., Kellermann, K. I., et al. 2015, MNRAS, 452, 1263, doi: 10.1093/mnras/stv1375
-
[37]
A.Rahmati,J.Schaye,A.H.Pawlik,andM.Raičević.Mon
Prandoni, I., & Seymour, N. 2015, in Advancing Astrophysics with the Square Kilometre Array (AASKA14), 67, doi: 10.22323/1.215.0067
-
[38]
Sain, S. R. 2002, Computational Statistics & Data Analysis, 39, 165
2002
-
[39]
Scargle, J. D., Norris, J. J., Jackson, B., & Chiang, J. 2013, The Astrophysical Journal, 764, 167, doi: 10.1088/0004-637X/764/2/167
-
[40]
Scheuer, P. A. G. 1957, Proceedings of the Cambridge Philosophical Society, 53, 764, doi: 10.1017/S0305004100032825
-
[41]
Scott, D. W. 1979, Biometrika, 66, 605
1979
-
[42]
Scott, D. W. 2015, Multivariate Density Estimation:
2015
-
[43]
Shimwell, T. W., Tasse, C., Hardcastle, M. J., et al. 2019, A&A, 622, A1, doi: 10.1051/0004-6361/201833559
-
[44]
Shimwell, T. W., Hardcastle, M. J., Tasse, C., et al. 2022, A&A, 659, A1, doi: 10.1051/0004-6361/202142484 14Liu, W ang, Yuan, et al
-
[45]
Silverman, B. W. 1986, Density estimation for statistics and data analysis Smolˇ ci´ c, V., Zamorani, G., Schinnerer, E., Vla-Cosmos, & Cosmos Collaborations. 2009a, in Astronomical Society of the Pacific Conference Series, Vol. 408, The Starburst-AGN Connection, ed. W. Wang, Z. Yang, Z. Luo, & Z. Chen, 116 Smolˇ ci´ c, V., Schinnerer, E., Zamorani, G., e...
-
[46]
Vernstrom, T., Scott, D., Wall, J. V., et al. 2014, MNRAS, 440, 2791, doi: 10.1093/mnras/stu470
-
[47]
2024, A&A, 683, A174, doi: 10.1051/0004-6361/202347746
Wang, W., Yuan, Z., Yu, H., & Mao, J. 2024, A&A, 683, A174, doi: 10.1051/0004-6361/202347746
-
[48]
Eales, S. A. 2001, MNRAS, 322, 536, doi: 10.1046/j.1365-8711.2001.04101.x
-
[49]
Y., Delaigle, A., & Gustafson, P., eds
Yi, G. Y., Delaigle, A., & Gustafson, P., eds. 2021, Handbook of Measurement Error Models, 1st edn. (Chapman and Hall/CRC), doi: 10.1201/9781315101279
-
[50]
Yuan, Z., Jarvis, M. J., & Wang, J. 2020, ApJS, 248, 1, doi: 10.3847/1538-4365/ab855b
-
[51]
2013, Ap&SS, 345, 305, doi: 10.1007/s10509-013-1402-9
Yuan, Z., & Wang, J. 2013, Ap&SS, 345, 305, doi: 10.1007/s10509-013-1402-9
-
[52]
2017, ApJ, 846, 78, doi: 10.3847/1538-4357/aa8463
Yuan, Z., Wang, J., Zhou, M., Qin, L., & Mao, J. 2017, ApJ, 846, 78, doi: 10.3847/1538-4357/aa8463
-
[53]
2022, ApJS, 260, 10, doi: 10.3847/1538-4365/ac596a
Yuan, Z., Zhang, X., Wang, J., Cheng, X., & Wang, W. 2022, ApJS, 260, 10, doi: 10.3847/1538-4365/ac596a
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.