Unified Dominance Graph for Interval-Predicate Approximate Nearest Neighbor Search
Pith reviewed 2026-06-25 22:17 UTC · model grok-4.3
The pith
The Unified Dominance Graph maps different interval predicates to one shared dominance space so the same graph construction and search code works for all of them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For any chosen interval predicate, the Unified Dominance Graph transforms object and query endpoints into coordinates in a normalized two-dimensional dominance space and constructs a dominance-labeled graph over those points. The same construction and search procedures therefore apply to containment, overlap, and the other supported predicates once the semantic mapping is performed. Query-state-specific proximity graphs are compressed into this single compact index, and validity-preserving patch edges are added to maintain routing options under restrictive interval filters.
What carries the argument
Unified Dominance Graph: a dominance-labeled graph built on endpoints after they are mapped into a predicate-specific two-dimensional dominance space, allowing reuse of the same algorithms across interval relations.
If this is right
- One index structure supports containment, overlap, and other two-bound conjunctive interval predicates after a predicate-specific mapping step.
- Query performance stays stable when the workload switches among different interval relations.
- Indexing overhead remains low while search outperforms hybrid range-filtering baselines.
- Validity-preserving patch edges keep search effective when the interval filter leaves only a small fraction of objects valid.
Where Pith is reading between the lines
- The same dominance-mapping idea could be tested on interval predicates that involve more than two endpoints or on predicates defined over multiple interval attributes.
- If the dominance labels preserve enough proximity information, the graph might be usable for exact nearest-neighbor search under the same interval constraints.
- Temporal or financial databases that already store interval attributes could adopt the mapping to avoid maintaining separate indexes for each predicate type.
Load-bearing premise
Mapping any supported interval predicate into the same dominance space lets the identical graph algorithms remain correct and efficient for every predicate.
What would settle it
A benchmark run in which the mapped graph returns a nearest neighbor that violates the original interval predicate or shows query latency that is markedly worse than a predicate-specific baseline on the same data.
Figures

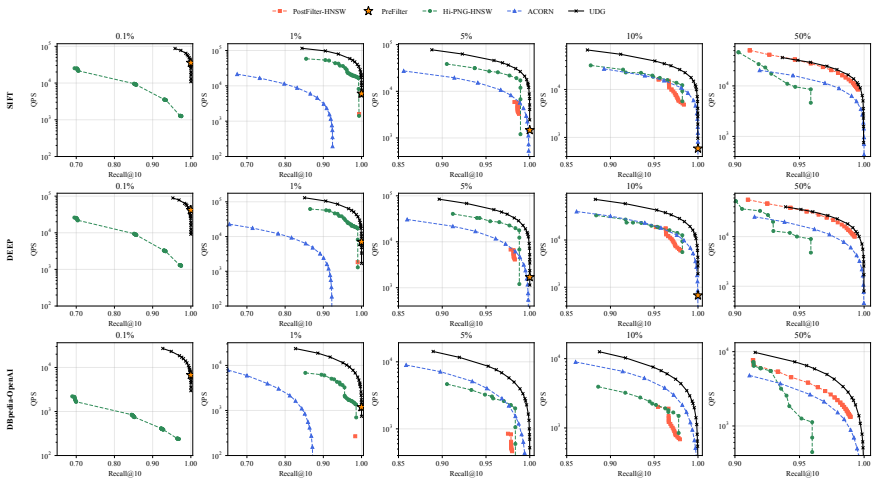
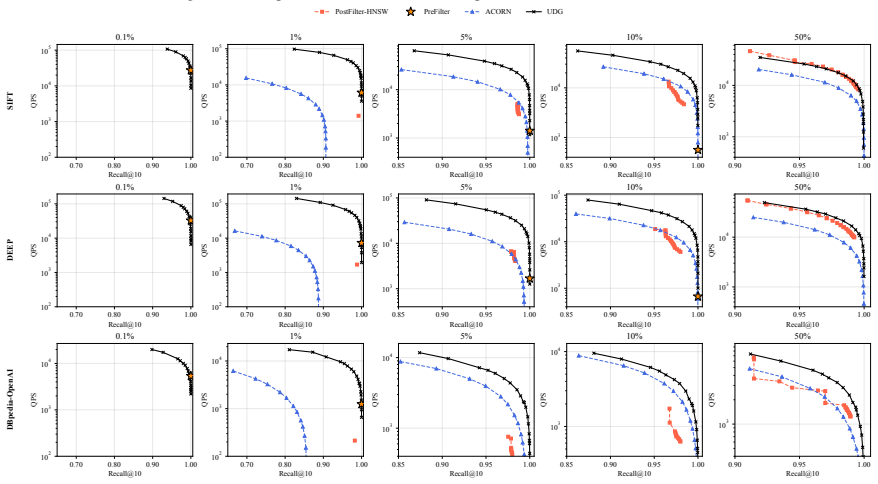



read the original abstract
Approximate Nearest Neighbor Search (ANNS) is a core primitive for unstructured data retrieval. Real-world applications--such as temporal databases, financial data analysis, and retrieval-augmented generation--often require hybrid queries whose valid objects are constrained by continuous interval attributes, such as lifespans or price ranges. We study Interval-Predicate ANNS (IPANNS), where validity is determined by a predicate between an object interval and a query interval. Existing range-filtering ANNS (RFANNS) methods are designed for single-dimensional scalar filters, but interval predicates such as containment and overlap rely on two coupled endpoint constraints. Treating endpoints as independent scalar attributes can incur large intersection overhead, while containment-specific methods lack a generalized indexing abstraction. In this paper, we propose the Unified Dominance Graph (UDG), a graph-indexing framework for the closed two-bound conjunctive fragment of IPANNS. For a chosen interval predicate, UDG maps object and query endpoints into a normalized two-dimensional dominance space and builds a dominance-labeled graph over the transformed coordinates. Containment, overlap, and other supported endpoint-bound predicates therefore reuse the same construction and search algorithms after semantic mapping, while each UDG instance remains tied to its selected predicate. UDG compresses query-state-specific proximity graphs into one compact index. To improve graph search under restrictive interval filters, we add validity-preserving patch edges that provide routing choices when few objects remain valid. Extensive evaluations on standard benchmarks and real-world datasets show that UDG achieves stable query performance across multiple interval relations and workloads, significantly outperforming existing hybrid search baselines while maintaining low indexing overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Unified Dominance Graph (UDG) for Interval-Predicate Approximate Nearest Neighbor Search (IPANNS). For a chosen interval predicate, it maps object and query endpoints into a normalized 2D dominance space, constructs a dominance-labeled graph over the transformed coordinates, and reuses the same construction and search algorithms across predicates (containment, overlap, etc.) after the mapping. Validity-preserving patch edges are added to improve routing under restrictive filters. The central empirical claim is that UDG delivers stable query performance across multiple interval relations and workloads while significantly outperforming hybrid search baselines at low indexing cost.
Significance. If the empirical results hold, UDG supplies a reusable graph-indexing abstraction for the closed two-bound conjunctive fragment of IPANNS. This is relevant for temporal databases, financial analytics, and RAG workloads that combine vector similarity with interval constraints. The approach compresses predicate-specific proximity graphs into one compact index and avoids the intersection overhead of treating endpoints as independent scalars.
major comments (2)
- [Abstract] The abstract asserts that UDG 'significantly outperform[s] existing hybrid search baselines' and achieves 'stable query performance,' yet provides no quantitative results, error metrics, or dataset descriptions. The central claim therefore rests entirely on the (unseen in the provided abstract) experimental section; without those numbers the performance advantage cannot be assessed.
- [§3 (semantic mapping)] The weakest assumption is that predicate-specific semantic mappings into the same 2D dominance space allow the identical graph-construction and search procedures to be reused without correctness or performance degradation. The manuscript must demonstrate, for each supported predicate, that the mapping preserves validity and that the resulting dominance relations do not introduce false negatives or alter approximation guarantees.
minor comments (2)
- [§3] Notation for the normalized dominance coordinates and the patch-edge construction should be introduced with a small running example that shows both a containment and an overlap mapping side-by-side.
- [§5] The paper should cite the specific RFANNS baselines it compares against and state whether they were re-implemented or taken from public code.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that UDG 'significantly outperform[s] existing hybrid search baselines' and achieves 'stable query performance,' yet provides no quantitative results, error metrics, or dataset descriptions. The central claim therefore rests entirely on the (unseen in the provided abstract) experimental section; without those numbers the performance advantage cannot be assessed.
Authors: We agree that the abstract would be strengthened by concrete support. In the revised version we will insert the principal quantitative results (e.g., the observed query-time speed-ups and stability metrics on the reported benchmarks) while remaining within the length limit. revision: yes
-
Referee: [§3 (semantic mapping)] The weakest assumption is that predicate-specific semantic mappings into the same 2D dominance space allow the identical graph-construction and search procedures to be reused without correctness or performance degradation. The manuscript must demonstrate, for each supported predicate, that the mapping preserves validity and that the resulting dominance relations do not introduce false negatives or alter approximation guarantees.
Authors: We accept the need for explicit demonstration. Section 3 already supplies the mappings together with informal validity arguments. We will augment the section with formal lemmas proving, for each predicate, that the mapping preserves validity, introduces no false negatives, and leaves the underlying approximation guarantees unchanged. revision: yes
Circularity Check
No significant circularity; derivation is a new construction
full rationale
The paper presents UDG as an original graph-indexing framework that applies a semantic mapping of interval predicates into 2D dominance space, followed by standard dominance-graph construction, search, and optional patch edges. No step reduces a claimed result to a fitted parameter, self-definition, or self-citation chain; the central claims rest on the explicit construction and empirical benchmarks rather than tautological equivalence to inputs. The method reuses the same algorithms across predicates only after an explicit predicate-specific mapping, which is not circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Serf: Segment graph for range-filtering approximate nearest neighbor search,
C. Zuo, M. Qiao, W. Zhou, F. Li, and D. Deng, “Serf: Segment graph for range-filtering approximate nearest neighbor search,”Proc. ACM Manag. Data, vol. 2, no. 1, Mar. 2024. [Online]. Available: https://doi.org/10.1145/3639324
-
[2]
Dynamic range-filtering approximate nearest neighbor search,
Z. Peng, M. Qiao, W. Zhou, F. Li, and D. Deng, “Dynamic range-filtering approximate nearest neighbor search,”Proc. VLDB Endow., vol. 18, no. 10, p. 3256–3268, Jun. 2025. [Online]. Available: https://doi.org/10.14778/3748191.3748193
-
[3]
Approximate nearest neighbor search with window filters,
J. Engels, B. Landrum, S. Yu, L. Dhulipala, and J. Shun, “Approximate nearest neighbor search with window filters,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[4]
Digra: A dynamic graph indexing for approximate nearest neighbor search with range filter,
M. Jiang, Z. Yang, F. Zhang, G. Hou, J. Shi, W. Zhou, F. Li, and S. Wang, “Digra: A dynamic graph indexing for approximate nearest neighbor search with range filter,”Proc. ACM Manag. Data, vol. 3, no. 3, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3725399
-
[5]
Efficient dynamic indexing for range filtered approximate nearest neighbor search,
F. Zhang, M. Jiang, G. Hou, J. Shi, H. Fan, W. Zhou, F. Li, and S. Wang, “Efficient dynamic indexing for range filtered approximate nearest neighbor search,”Proc. ACM Manag. Data, vol. 3, no. 3, Jun
-
[6]
Available: https://doi.org/10.1145/3725401
[Online]. Available: https://doi.org/10.1145/3725401
-
[7]
irangegraph: Improvising range-dedicated graphs for range-filtering nearest neighbor search,
Y . Xu, J. Gao, Y . Gou, C. Long, and C. S. Jensen, “irangegraph: Improvising range-dedicated graphs for range-filtering nearest neighbor search,”Proc. ACM Manag. Data, vol. 2, no. 6, Dec. 2024. [Online]. Available: https://doi.org/10.1145/3698814
-
[8]
Hi-png: Efficient interval-filtering anns via hierarchical interval partition navigating graph,
M. Yang, Y . Cai, and W. Zheng, “Hi-png: Efficient interval-filtering anns via hierarchical interval partition navigating graph,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, ser. KDD ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 3518–3529. [Online]. Available: https://doi.org/10.114...
-
[10]
Ann-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms,
M. Aum ¨uller, E. Bernhardsson, and A. Faithfull, “Ann-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms,” Inf. Syst., vol. 87, no. C, Jan. 2020. [Online]. Available: https: //doi.org/10.1016/j.is.2019.02.006
-
[12]
Efficient indexing of billion-scale datasets of deep descriptors,
A. B. Yandex and V . Lempitsky, “Efficient indexing of billion-scale datasets of deep descriptors,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2055–2063
2016
-
[13]
dbpedia-entities-openai-1m,
Kumar Shivendu and Nirant Kasliwal, “dbpedia-entities-openai-1m,”
-
[14]
Available: https://huggingface.co/datasets/KShivendu/ dbpedia-entities-openai-1M
[Online]. Available: https://huggingface.co/datasets/KShivendu/ dbpedia-entities-openai-1M
-
[15]
Reading between the timelines: Rag for answering diachronic questions,
K. H. Lau, R. Zhang, W. Shi, X. Zhou, and X. Cheng, “Reading between the timelines: Rag for answering diachronic questions,” 2025. [Online]. Available: https://arxiv.org/abs/2507.22917
arXiv 2025
-
[16]
Fnspid: A comprehensive financial news dataset in time series,
Z. Dong, X. Fan, and Z. Peng, “Fnspid: A comprehensive financial news dataset in time series,” 2024
2024
-
[17]
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 4, p. 824–836, Apr. 2020. [Online]. Available: https://doi.org/10.1109/ TPAMI.2018.2889473
arXiv 2020
-
[18]
Acorn: Performant and predicate-agnostic search over vector embeddings and structured data,
L. Patel, P. Kraft, C. Guestrin, and M. Zaharia, “Acorn: Performant and predicate-agnostic search over vector embeddings and structured data,” Proc. ACM Manag. Data, vol. 2, no. 3, May 2024. [Online]. Available: https://doi.org/10.1145/3654923
-
[19]
Approximate nearest neighbors: towards removing the curse of dimensionality,
P. Indyk and R. Motwani, “Approximate nearest neighbors: towards removing the curse of dimensionality,” inProceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, ser. STOC ’98. New York, NY , USA: Association for Computing Machinery, 1998, p. 604–613. [Online]. Available: https://doi.org/10.1145/276698.276876
-
[20]
Similarity search in high dimen- sions via hashing,
A. Gionis, P. Indyk, and R. Motwani, “Similarity search in high dimen- sions via hashing,” inProceedings of the 25th International Conference on Very Large Data Bases, ser. VLDB ’99. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1999, p. 518–529
1999
-
[21]
Multi- probe lsh: efficient indexing for high-dimensional similarity search,
Q. Lv, W. Josephson, Z. Wang, M. Charikar, and K. Li, “Multi- probe lsh: efficient indexing for high-dimensional similarity search,” in Proceedings of the 33rd International Conference on Very Large Data Bases, ser. VLDB ’07. VLDB Endowment, 2007, p. 950–961
2007
-
[22]
Product quantization for nearest neighbor search,
H. J ´egou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117–128, 2011
2011
-
[23]
The inverted multi-index,
A. Babenko and V . Lempitsky, “The inverted multi-index,” in2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 3069–3076
2012
-
[24]
Optimized product quantization,
T. Ge, K. He, Q. Ke, and J. Sun, “Optimized product quantization,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 4, pp. 744–755, 2014
2014
-
[25]
Scalable nearest neighbor algorithms for high dimensional data,
M. Muja and D. G. Lowe, “Scalable nearest neighbor algorithms for high dimensional data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 11, pp. 2227–2240, 2014
2014
-
[26]
Billion-scale similarity search with gpus,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with gpus,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2021
2021
-
[27]
Fast approximate nearest neighbor search with the navigating spreading-out graph,
C. Fu, C. Xiang, C. Wang, and D. Cai, “Fast approximate nearest neighbor search with the navigating spreading-out graph,”Proc. VLDB Endow., vol. 12, no. 5, p. 461–474, Jan. 2019. [Online]. Available: https://doi.org/10.14778/3303753.3303754
-
[28]
S. J. Subramanya, Devvrit, R. Kadekodi, R. Krishaswamy, and H. V . Simhadri,DiskANN: fast accurate billion-point nearest neighbor search on a single node. Red Hook, NY , USA: Curran Associates Inc., 2019
2019
-
[29]
M. Wang, X. Xu, Q. Yue, and Y . Wang, “A comprehensive survey and experimental comparison of graph-based approximate nearest neighbor search,”Proc. VLDB Endow., vol. 14, no. 11, p. 1964–1978, Jul. 2021. [Online]. Available: https://doi.org/10.14778/3476249.3476255
-
[30]
VBASE: Unifying online vector similarity search and relational queries via relaxed monotonicity,
Q. Zhang, S. Xu, Q. Chen, G. Sui, J. Xie, Z. Cai, Y . Chen, Y . He, Y . Yang, F. Yang, M. Yang, and L. Zhou, “VBASE: Unifying online vector similarity search and relational queries via relaxed monotonicity,” in17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). Boston, MA: USENIX Association, Jul. 2023, pp. 377–395. [Online]. A...
2023
-
[31]
Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters,
S. Gollapudi, N. Karia, V . Sivashankar, R. Krishnaswamy, N. Begwani, S. Raz, Y . Lin, Y . Zhang, N. Mahapatro, P. Srinivasan, A. Singh, and H. V . Simhadri, “Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters,” inProceedings of the ACM Web Conference 2023, ser. WWW ’23. New York, NY , USA: Association for Computing Ma...
-
[32]
W. Wu, J. He, Y . Qiao, G. Fu, L. Liu, and J. Yu, “Hqann: Efficient and robust similarity search for hybrid queries with structured and unstructured constraints,” inProceedings of the 31st ACM International Conference on Information & Knowledge Management, ser. CIKM ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 4580–4584. [Online]...
-
[33]
Navigating labels and vectors: A unified approach to filtered approximate nearest neighbor search,
Y . Cai, J. Shi, Y . Chen, and W. Zheng, “Navigating labels and vectors: A unified approach to filtered approximate nearest neighbor search,” Proc. ACM Manag. Data, vol. 2, no. 6, Dec. 2024. [Online]. Available: https://doi.org/10.1145/3698822
-
[34]
Arkgraph: All-range approximate k-nearest-neighbor graph,
C. Zuo and D. Deng, “Arkgraph: All-range approximate k-nearest-neighbor graph,”Proc. VLDB Endow., vol. 16, no. 10, p. 2645–2658, Jun. 2023. [Online]. Available: https://doi.org/10.14778/3603581.3603601
-
[35]
Unify: Unified index for range filtered approximate nearest neighbors search,
A. Liang, P. Zhang, B. Yao, Z. Chen, Y . Song, and G. Cheng, “Unify: Unified index for range filtered approximate nearest neighbors search,” Proc. VLDB Endow., vol. 18, no. 4, p. 1118–1130, Dec. 2024. [Online]. Available: https://doi.org/10.14778/3717755.3717770
-
[36]
Timestamp approx- imate nearest neighbor search over high-dimensional vector data,
Y . Wang, Z. He, Y . Tong, Z. Zhou, and Y . Zhong, “Timestamp approx- imate nearest neighbor search over high-dimensional vector data,” in 2025 IEEE 41st International Conference on Data Engineering (ICDE), 2025, pp. 3043–3055
2025
-
[37]
Y . Liu, T. Wu, J. Xie, Y . Zhao, J. X. Yu, and J. Cui, “Generalized range filtering approximate nearest neighbor search: Containment and overlap [technical report],” 2026. [Online]. Available: https://arxiv.org/abs/2605.26474
Pith/arXiv arXiv 2026
-
[38]
Managing intervals efficiently in object-relational databases,
H.-P. Kriegel, M. P ¨otke, and T. Seidl, “Managing intervals efficiently in object-relational databases,” inProceedings of the 26th International Conference on Very Large Data Bases, ser. VLDB ’00. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2000, p. 407–418
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.