Scaling Laws for Task-Specific LLM Distillation
Pith reviewed 2026-06-25 23:27 UTC · model grok-4.3
The pith
Chain-of-thought supervision recovers general knowledge that pruning erases in task-specific LLM distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that empirical scaling laws for domain-specific LLM compression reveal supervision format as the key driver of the tradeoff between in-domain task performance and retention of general knowledge, with chain-of-thought supervision actively recovering general knowledge that pruning erases while a blended chain-of-thought loss stabilizes the distillation process.
What carries the argument
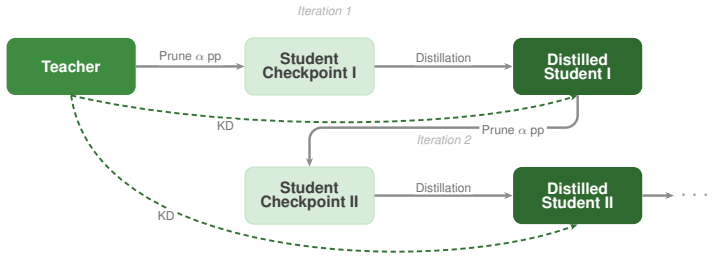
The blended chain-of-thought supervision loss that stabilizes KL-divergence distillation over reasoning traces during iterative structural pruning.
Load-bearing premise
The observed scaling behaviors and the stabilizing effect of the blended chain-of-thought loss on KL-divergence distillation are driven primarily by supervision format rather than unmeasured factors such as specific model architectures, dataset composition, or benchmark choices.
What would settle it
An experiment showing that the same scaling laws and recovery effect hold when supervision format is varied but model architecture, dataset composition, and benchmarks are changed would support the claim; finding that architecture or dataset shifts alter the tradeoff independently of supervision format would falsify it.
Figures










read the original abstract
Large Language Models (LLMs) achieve strong performance across a growing range of domains, yet their scale poses deployment challenges in applications where latency and cost constraints are critical. This paper derives empirical scaling laws for domain-specific LLM compression, quantifying how in-domain and general knowledge performance scale with dataset size, compression ratio, supervision format, and iterative pruning schedule. Using quantitative finance as our application domain, we compare logit-based and LoRA-based distillation under iterative structural pruning, introducing a blended chain-of-thought supervision loss that stabilizes KL-divergence distillation over reasoning traces. In-domain task quality degrades predictably under compression while general-knowledge benchmarks collapse well before the same point; supervision format is the key driver of this tradeoff, with chain-of-thought supervision actively recovering general knowledge that pruning erases. We release the headline dataset FinHeadlineMix, scaling law results, and practical recommendations to provide a reusable framework for domain-specific compression decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives empirical scaling laws for domain-specific LLM compression using quantitative finance as the application domain. It compares logit-based and LoRA-based distillation under iterative structural pruning, introduces a blended chain-of-thought supervision loss to stabilize KL-divergence distillation over reasoning traces, and claims that supervision format is the key driver of the in-domain vs. general-knowledge tradeoff, with CoT supervision recovering knowledge erased by pruning. The work releases the FinHeadlineMix dataset along with scaling-law results and practical recommendations.
Significance. If the scaling laws prove robust and the attribution to supervision format can be isolated from confounds, the work would supply a reusable empirical framework for compression decisions in specialized domains. The dataset release and emphasis on practical recommendations are strengths that support reproducibility and downstream use.
major comments (2)
- [Abstract] Abstract: the claim that 'supervision format is the key driver of this tradeoff' is load-bearing for the central contribution, yet the described experiments do not isolate it. No ablations are mentioned that hold architecture, pruning schedule, loss components, and dataset fixed while varying only supervision format (or that swap domain while holding format fixed). Without such controls, the observed in-domain stability and general-knowledge recovery could be driven by interactions with the quantitative-finance domain or FinHeadlineMix composition rather than format per se.
- [Abstract] Abstract (results paragraph): the stabilizing effect of the blended chain-of-thought loss on KL-divergence distillation is asserted without reference to concrete metrics (e.g., KL values, scaling exponents, or recovery deltas on general-knowledge benchmarks) that would allow verification that the effect is format-driven rather than an artifact of the chosen benchmarks or model sizes.
minor comments (1)
- [Abstract] Abstract: the phrase 'iterative pruning schedule' is introduced without any indication of the schedule parameters or how they enter the scaling laws.
Simulated Author's Rebuttal
We thank the referee for the constructive comments identifying gaps in experimental controls and metric reporting. We agree these points strengthen the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'supervision format is the key driver of this tradeoff' is load-bearing for the central contribution, yet the described experiments do not isolate it. No ablations are mentioned that hold architecture, pruning schedule, loss components, and dataset fixed while varying only supervision format (or that swap domain while holding format fixed). Without such controls, the observed in-domain stability and general-knowledge recovery could be driven by interactions with the quantitative-finance domain or FinHeadlineMix composition rather than format per se.
Authors: We agree that the current experiments do not fully isolate supervision format from domain-specific factors. The revised manuscript will add ablation studies holding architecture, pruning schedule, loss components, and dataset fixed while varying only supervision format. We will also discuss limitations of domain-specific results and why full domain-swapping experiments are outside the current scope. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): the stabilizing effect of the blended chain-of-thought loss on KL-divergence distillation is asserted without reference to concrete metrics (e.g., KL values, scaling exponents, or recovery deltas on general-knowledge benchmarks) that would allow verification that the effect is format-driven rather than an artifact of the chosen benchmarks or model sizes.
Authors: We acknowledge that concrete metrics were not provided in the abstract or results summary. The revision will report explicit values including KL divergence before/after the blended loss, scaling exponents across formats, and recovery deltas on general-knowledge benchmarks, presented in tables and figures. revision: yes
Circularity Check
Empirical scaling laws from experiments exhibit no circularity
full rationale
The paper frames its contribution as deriving empirical scaling laws from controlled experiments on LLM distillation, pruning, and supervision formats in a quantitative-finance domain. Performance trends (in-domain vs. general-knowledge degradation, stabilization via blended CoT loss) are reported as observed outcomes across dataset sizes, compression ratios, and loss variants. No mathematical derivation chain, fitted-parameter-as-prediction step, self-definitional equations, or load-bearing self-citations appear in the provided abstract or described methodology. The central attribution to supervision format rests on comparative experimental results rather than any reduction to prior inputs by construction. This is a standard empirical study whose claims can be evaluated against the released dataset and benchmarks without internal circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- scaling law coefficients for performance versus compression ratio and dataset size
axioms (1)
- domain assumption In-domain task quality and general-knowledge benchmark scores are valid proxies for the underlying capabilities affected by compression and supervision.
Reference graph
Works this paper leans on
-
[1]
Nvidia, Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H. Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, Sirshak Das, Ayush Dattagupta, Olivier Delalleau, Leon Derczynski, Yi Dong, Daniel Egert, Ellie Evans, Aleksander Ficek, Denys Fridman, Shaona Ghosh, Boris Ginsburg, Igor Gitman, and Tomasz Grzegorz...
arXiv 2024
-
[2]
Optimal brain damage
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage. In D. Touret- zky, editor,Advances in Neural Information Processing Systems, volume 2. Morgan- Kaufmann, 1989. URL https://proceedings.neurips.cc/paper_files/paper/1989/ file/6c9882bbac1c7093bd25041881277658-Paper.pdf
1989
-
[3]
Compact language models via pruning and knowledge distillation
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, and Pavlo Molchanov. Compact language models via pruning and knowledge distillation. 07 2024. URL https: //arxiv.org/pdf/2407.14679.pdf
arXiv 2024
-
[4]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. 03 2015. URLhttps://arxiv.org/pdf/1503.02531.pdf
Pith/arXiv arXiv 2015
-
[5]
Llama-nemotron: Efficient reasoning models
Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, Ido Shahaf, Oren Tropp, Ehud Karpas, Ran Zilberstein, Jiaqi Zeng, Soumye Singhal, Alexander Bukharin, Yian Zhang, Tugrul Konuk, Gerald Shen, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Yoshi Suhara, Olivier Delalleau, and ...
arXiv 2025
-
[6]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, and Chengda Lu. Deepseek-r1: Incentivizing reasoning capability in llms via...
Pith/arXiv arXiv 2025
-
[7]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. 06 2021. URLhttps://arxiv.org/pdf/2106.09685.pdf
Pith/arXiv arXiv 2021
-
[8]
Lora without regret.Thinking Machines Lab: Connectionism, 2025
John Schulman and Thinking Machines Lab. Lora without regret.Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20250929. https://thinkingmachines.ai/blog/lora/
-
[9]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. 01 2022. URLhttps://arxiv.org/pdf/2201.11903.pdf
Pith/arXiv arXiv 2022
-
[10]
Bucilua, R
C. Bucilua, R. Caruana, and A. Niculescu-Mizil. Model compression.Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’06: 535–541, 2006. 21
2006
-
[11]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. 05 2023. URL https://arxiv.org/pdf/2305.02301.pdf
Pith/arXiv arXiv 2023
-
[12]
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. 06 2016. URL https://arxiv.org/pdf/1606.07947.pdf
Pith/arXiv arXiv 2016
-
[13]
On the efficacy of knowledge distillation.ICCV 2019, 10 2019
Jang Hyun Cho and Bharath Hariharan. On the efficacy of knowledge distillation.ICCV 2019, 10 2019. URLhttps://arxiv.org/pdf/1910.01348.pdf
arXiv 2019
-
[14]
Knowledge distillation: Bad models can be good role models
Gal Kaplun, Eran Malach, Preetum Nakkiran, and Shai Shalev-Shwartz. Knowledge distillation: Bad models can be good role models. 03 2022. URLhttps://arxiv.org/pdf/2203.14649. pdf
arXiv 2022
-
[15]
Dan Busbridge, Amitis Shidani, Floris Weers, Jason Ramapuram, Etai Littwin, and Russ Webb. Distillation scaling laws. 02 2025. URLhttps://arxiv.org/pdf/2502.08606.pdf
arXiv 2025
-
[16]
Reddi, Seungyeon Kim, and Sanjiv Kumar
Aditya Krishna Menon, Ankit Singh Rawat, Sashank J. Reddi, Seungyeon Kim, and Sanjiv Kumar. Why distillation helps: a statistical perspective. 05 2020. URL https://arxiv.org/ pdf/2005.10419.pdf
arXiv 2020
-
[17]
Dahl, and Geof- frey E
Rohan Anil, Gabriel Pereyra, Alexandre Passos, Robert Ormandi, George E. Dahl, and Geof- frey E. Hinton. Large scale distributed neural network training through online distillation. 04
-
[18]
URLhttps://arxiv.org/pdf/1804.03235.pdf
-
[19]
Knowledge distillation: A good teacher is patient and consistent
Lucas Beyer, Xiaohua Zhai, Amélie Royer, Larisa Markeeva, Rohan Anil, and Alexander Kolesnikov. Knowledge distillation: A good teacher is patient and consistent. 06 2021. URL https://arxiv.org/pdf/2106.05237.pdf
arXiv 2021
-
[20]
On-policy distillation of language models: Learning from self- generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2306.13649
arXiv 2024
-
[21]
Hewett, Mojan Javaheripi, Piero Kauffmann, James R
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Xin Wang, Rachel Ward, Yue Wu, Dingli Yu,...
2024
-
[22]
Llama 3.2: Revolutionizing edge ai and vision with open, cus- tomizable models, September 2024
MetaAI. Llama 3.2: Revolutionizing edge ai and vision with open, cus- tomizable models, September 2024. URL https://ai.meta.com/blog/ llama-3-2-connect-2024-vision-edge-mobile-devices/
2024
-
[23]
Is deeper better only when shallow is good? InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
Eran Malach and Shai Shalev-Shwartz. Is deeper better only when shallow is good? InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/ 606555cf42a6719782a952aa33cfa2cb-Abstract.html
2019
-
[24]
Lu Yin, Ajay Jaiswal, Shiwei Liu, Souvik Kundu, and Zhangyang Wang. Junk DNA hypothesis: Pruning small pre-trained weights irreversibly and monotonically impairs “difficult” downstream tasks in LLMs. 2023. URLhttps://arxiv.org/abs/2310.02277
Pith/arXiv arXiv 2023
-
[25]
Large language model adaptation for financial sentiment analysis
Pau Rodriguez Inserte, Mariam Nakhlé, Raheel Qader, Gaetan Caillaut, and Jingshu Liu. Large language model adaptation for financial sentiment analysis. In Chung-Chi Chen, Hen- Hsen Huang, Hiroya Takamura, Hsin-Hsi Chen, Hiroki Sakaji, and Kiyoshi Izumi, editors, Proceedings of the Sixth Workshop on Financial Technology and Natural Language Processing, pag...
2023
-
[26]
Small models struggle to learn from strong reasoners,
Yuetai Li, Xiang Yue, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Bill Yuchen Lin, Bhaskar Ra- masubramanian, and Radha Poovendran. Small models struggle to learn from strong reasoners,
-
[27]
URLhttps://arxiv.org/abs/2502.12143
-
[28]
Bert vs gpt for financial engineering
Edward Sharkey and Philip Treleaven. Bert vs gpt for financial engineering. 05 2024. URL https://arxiv.org/pdf/2405.12990.pdf
arXiv 2024
-
[29]
Nemotron-3-Nano-30B-A3B: Model card, 2025
NVIDIA. Nemotron-3-Nano-30B-A3B: Model card, 2025. URL https://build.nvidia. com/nvidia/nemotron-3-nano-30b-a3b/modelcard. NVIDIA AI Foundation Model
2025
-
[30]
NeMo data designer
NVIDIA. NeMo data designer. https://nvidia-nemo.github.io/DataDesigner/ latest/, 2025. Accessed: 2025
2025
-
[31]
NeMo-Curator: a toolkit for data curation
Joseph Jennings, Mostofa Patwary, Sandeep Subramanian, Shrimai Prabhumoye, Ayush Dattagupta, Vibhu Jawa, Jiwei Liu, Ryan Wolf, Sarah Yurick, and Varun Singh. NeMo-Curator: a toolkit for data curation. URLhttps://github.com/NVIDIA/NeMo-Curator
-
[32]
Puzzle: Distillation-based nas for inference-optimized llms
Akhiad Bercovich, Tomer Ronen, Talor Abramovich, Nir Ailon, Nave Assaf, Mohammad Dabbah, Ido Galil, Amnon Geifman, Yonatan Geifman, Izhak Golan, Netanel Haber, Ehud Karpas, Roi Koren, Itay Levy, Pavlo Molchanov, Shahar Mor, Zach Moshe, Najeeb Nabwani, Omri Puny, Ran Rubin, Itamar Schen, Ido Shahaf, Oren Tropp, Omer Ullman Argov, and Ran Zilberstein. Puzzl...
arXiv 2024
-
[33]
Qwen Team. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388. Model:https://huggingface.co/Qwen/Qwen3-32B
Pith/arXiv arXiv 2025
-
[34]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245, 2023. URL https://arxiv.org/abs/2305. 13245
Pith/arXiv arXiv 2023
-
[35]
Llama 3 model card
AI@Meta. Llama 3 model card. 2024. URL https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md
2024
-
[36]
Introducing GPT-oss
OpenAI. Introducing GPT-oss. https://openai.com/index/introducing-gpt-oss/,
-
[37]
Defeating nondeterminism in LLM inference.Think- ing Machines Lab: Connectionism, 2025
Horace He and Thinking Machines Lab. Defeating nondeterminism in LLM inference.Think- ing Machines Lab: Connectionism, 2025. URL https://thinkingmachines.ai/blog/ defeating-nondeterminism-in-llm-inference/. Blog post
2025
-
[38]
Shortgpt: Layers in large language models are more redundant than you expect
Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect. 03 2024. URLhttps://arxiv.org/pdf/2403.03853.pdf
arXiv 2024
-
[39]
The Annals of Mathematical Statistics , author =
S. Kullback and R. A. Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, 1951. doi: 10.1214/aoms/1177729694. URL http://dx.doi.org/ 10.1214/aoms/1177729694
-
[40]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. 06 2023. URLhttps://arxiv.org/pdf/2306.08543.pdf
Pith/arXiv arXiv 2023
-
[41]
Patient knowledge distillation for bert model compression
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for bert model compression. 08 2019. URLhttps://arxiv.org/pdf/1908.09355.pdf
arXiv 2019
-
[42]
NeMo: a toolkit for Conversational AI and Large Language Models
Eric Harper, Somshubra Majumdar, Oleksii Kuchaiev, Li Jason, Yang Zhang, Evelina Bakh- turina, Vahid Noroozi, Sandeep Subramanian, Koluguri Nithin, Huang Jocelyn, Fei Jia, Jagadeesh Balam, Xuesong Yang, Micha Livne, Yi Dong, Sean Naren, and Boris Gins- burg. NeMo: a toolkit for Conversational AI and Large Language Models. URL https: //github.com/NVIDIA/NeMo
-
[43]
Tensorrt model optimizer (modelopt)
NVIDIA. Tensorrt model optimizer (modelopt). https://github.com/NVIDIA/ TensorRT-Model-Optimizer, 2025. Version 0.33.0. 23
2025
-
[44]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019. URL https://arxiv.org/abs/ 1711.05101
Pith/arXiv arXiv 2019
-
[45]
SGDR: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations (ICLR), 2017. URL https://arxiv. org/abs/1608.03983
Pith/arXiv arXiv 2017
-
[46]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021. URL https://arxiv. org/abs/2009.03300
Pith/arXiv arXiv 2021
-
[47]
MMLU- Pro: A more robust and challenging multi-task language understanding benchmark, 2024
Xiaotian Zhang, Yintao Du, Gen Luo, Yunshan Zhong, Shuo Zhang, and Rongrong Ji. MMLU- Pro: A more robust and challenging multi-task language understanding benchmark, 2024. URL https://arxiv.org/abs/2402.13383
arXiv 2024
-
[48]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13): 35...
arXiv 2017
-
[49]
Better fine-tuning by reducing representational collapse
Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta. Better fine-tuning by reducing representational collapse. InInternational Conference on Learning Representations (ICLR), 2021. URL https://arxiv.org/abs/ 2008.03156
arXiv 2021
-
[50]
GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020. URLhttps://arxiv.org/abs/2002.05202
Pith/arXiv arXiv 2002
-
[51]
Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019. URLhttps://arxiv.org/abs/1911.02150
Pith/arXiv arXiv 1911
-
[52]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into self-improving pipelines. InInternational Conference on Learning Representations (ICLR),
-
[53]
URLhttps://arxiv.org/abs/2310.03714
-
[54]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023. URLhttps://arxiv.org/abs/2309.06180. 24
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.