What Does It Mean to Break a Distillation Defense?
Pith reviewed 2026-06-25 22:49 UTC · model grok-4.3
The pith
The effectiveness of output perturbation defenses against LLM distillation depends on the attacker's threat model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that whether a defense such as antidistillation sampling counts as effective against distillation attacks on black-box LLMs is not an intrinsic property of the defense but instead depends on the concrete threat model used for evaluation. The authors formalize that threat model through three dimensions—query budget, data budget, and interface profile—and show that changing any of them can reverse the apparent success or failure of the defense. They further argue that without explicit specification and stress-testing along these dimensions, comparisons across defenses are unreliable, compositions with other attacks cannot be reasoned about, and deployments for intellectual
What carries the argument
Three-dimensional threat model (query budget, data budget, interface profile) that classifies attacker capabilities for evaluating output-perturbation defenses.
If this is right
- Any claim that a distillation defense is robust must be accompanied by results across multiple settings of query budget, data budget, and interface profile.
- Compositions of defenses or attacks can only be analyzed once both sides share the same three-dimensional threat model.
- Regulatory or governance frameworks that rely on these defenses must require explicit statements of the attacker capabilities they assume.
- New defense designs should include experiments that vary each dimension independently rather than reporting a single operating point.
Where Pith is reading between the lines
- The same three dimensions could be used to evaluate other API-based attacks such as model inversion or membership inference.
- Defenders might eventually build adaptive perturbations that respond differently depending on detected levels of the three attacker dimensions.
- Empirical work could test whether real-world distillation attempts cluster at particular combinations of the three axes rather than spanning them uniformly.
Load-bearing premise
The three dimensions of query budget, data budget, and interface profile are enough to capture all attacker capabilities that matter for breaking distillation defenses.
What would settle it
A concrete counter-example would be an output-perturbation defense whose reduction in student-model accuracy remains large and stable no matter how the three dimensions are varied from low to high.
Figures

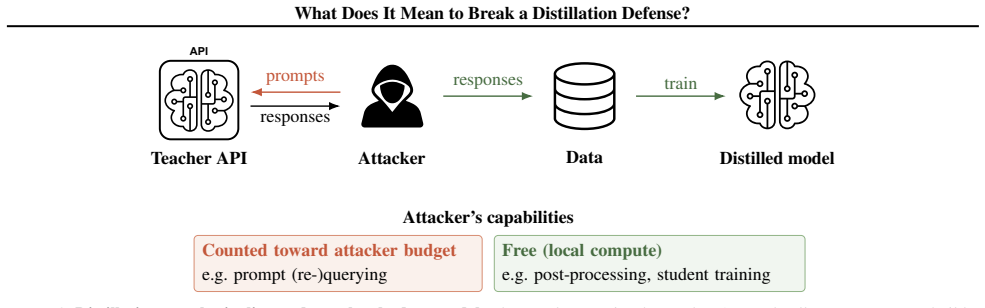
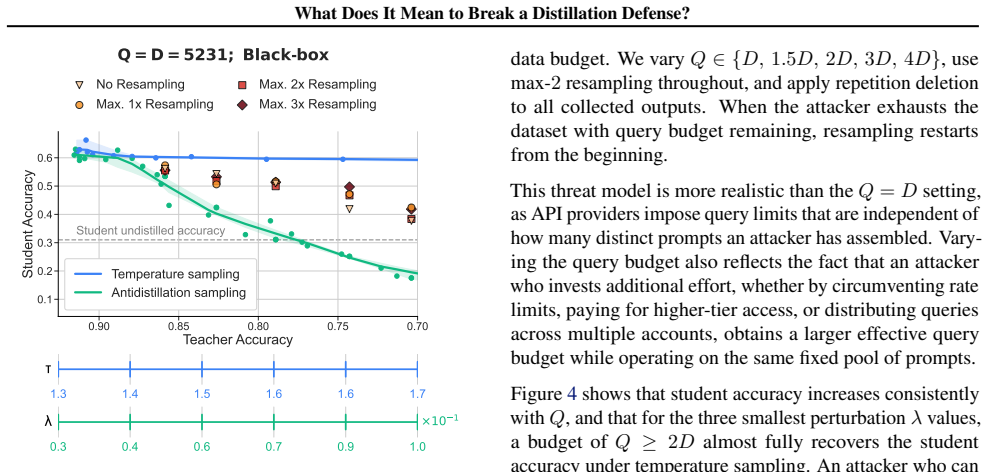
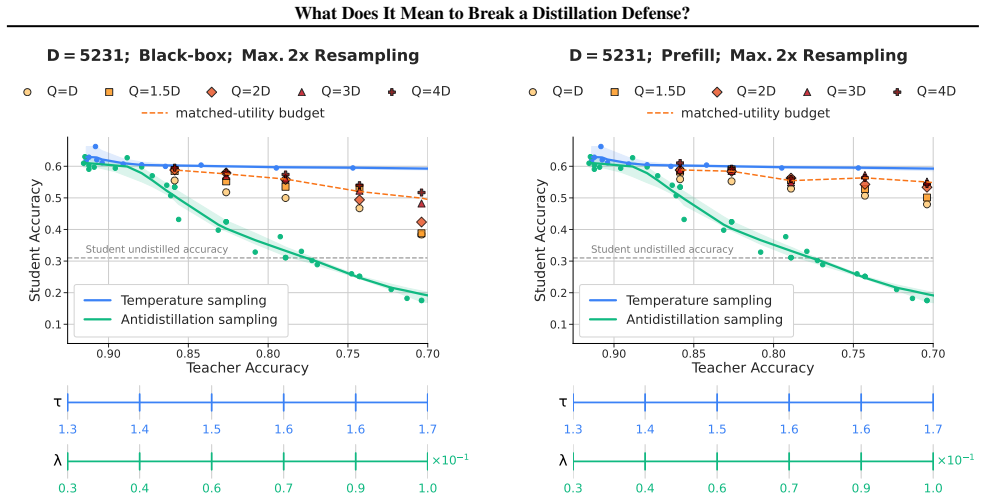

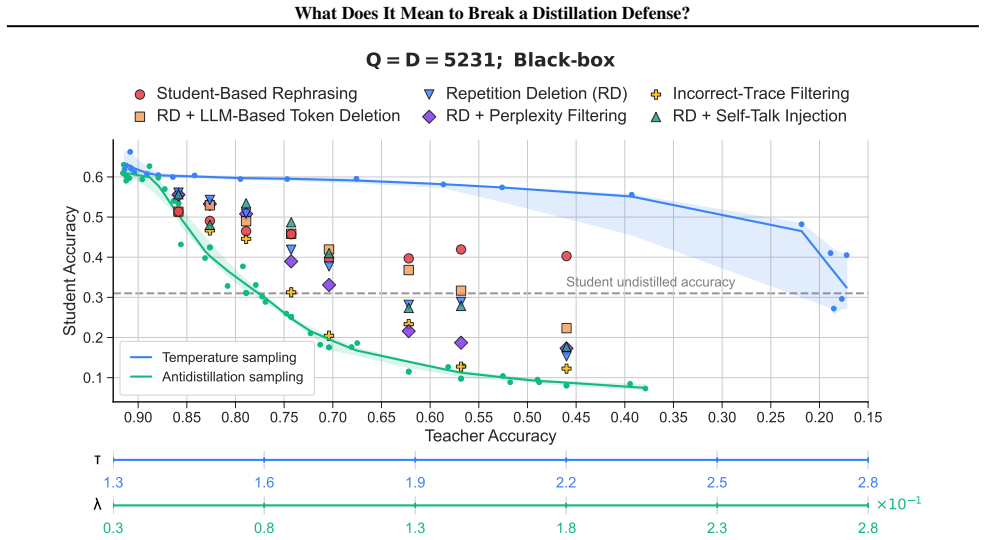











read the original abstract
Black-box LLMs (accessible only via API) are vulnerable to distillation attacks, in which an attacker queries the model and trains a student on its outputs. A recent line of work proposes output perturbation defenses that modify the teacher's output to reduce student performance while preserving utility for legitimate users. As a relatively new family of approaches, output perturbation defenses lack a shared threat model, making it difficult to compare them, reason about composing them with other attacks, or evaluate their robustness against realistic adversaries. This underspecification matters beyond technical evaluation: when defenses are deployed to protect intellectual property or justify regulatory compliance, an imprecise threat model can create a false sense of security. We propose a threat model framework that describes attackers along three dimensions: a query budget, a data budget, and an interface profile that captures how attackers interact with the API. Using antidistillation sampling as a case study, we show that whether the defense is considered effective depends on the assumed threat model. We argue that future work on distillation defenses, along with any governance or policy frameworks built around them, should explicitly specify and stress-test attacker capabilities along our three dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that output perturbation defenses against distillation attacks on black-box LLMs lack a shared threat model, which hinders comparison, composition with other attacks, and realistic robustness evaluation. It proposes a framework characterizing attackers along three dimensions (query budget, data budget, and interface profile) and uses antidistillation sampling as a case study to show that defense effectiveness is threat-model dependent. The authors conclude that future work, as well as any governance frameworks, should explicitly specify and stress-test attacker capabilities along these dimensions.
Significance. If the central claim holds, the work is significant for standardizing evaluations of a relatively new class of defenses, reducing the risk of false security claims in IP protection or regulatory settings. The framework is presented independently without circularity or fitted parameters, and the case study provides a concrete illustration of the dependency. This addresses a standard but important point in security research about threat-model underspecification.
minor comments (2)
- [Abstract] The abstract states that the three dimensions help address underspecification but does not include even a one-sentence gloss on 'interface profile'; adding this would improve self-contained readability without lengthening the abstract.
- [§3] §3 (framework presentation) would benefit from an explicit statement of whether the three dimensions are intended as a minimal sufficient set or as an initial proposal open to extension; the current wording leaves this implicit.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The report correctly summarizes our central claim regarding the underspecification of threat models in output perturbation defenses and the proposed three-dimensional framework. No specific major comments were raised.
Circularity Check
No significant circularity; framework is self-contained
full rationale
The paper proposes a conceptual three-dimensional threat model (query budget, data budget, interface profile) and illustrates its implications via a case study on antidistillation sampling. No equations, fitted parameters, or derivations appear in the provided text. The central claim—that defense effectiveness is threat-model dependent—is presented as a direct consequence of varying the dimensions, without reduction to self-definitions, self-citations, or renamed empirical patterns. No load-bearing steps match any enumerated circularity pattern, consistent with the reader's independent assessment.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attackers in distillation attacks can be meaningfully characterized along query budget, data budget, and interface profile.
invented entities (1)
-
Interface profile
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Trockman, Asher and Savani, Yash , year =
-
[2]
2026 , howpublished =
2026
-
[3]
2025 , howpublished =
2025
-
[4]
2025 , howpublished =
Logprobs deprecated for gpt-5 models? , author =. 2025 , howpublished =
2025
-
[5]
2025 , howpublished =
Get logprobs at output token level , author =. 2025 , howpublished =
2025
-
[6]
Finlayson, Matthew and Ren, Xiang and Swayamdipta, Swabha , booktitle =
-
[7]
2024 , howpublished =
2024
-
[8]
International Conference on Machine Learning (ICML) , year =
Stealing Part of a Production Language Model , author =. International Conference on Machine Learning (ICML) , year =
-
[9]
2026 , month = feb, howpublished =
2026
-
[10]
Large Language Models Are Reasoning Teachers
Ho, Namgyu and Schmid, Laura and Yun, Se-Young , booktitle =. 2023 , address =. doi:10.18653/v1/2023.acl-long.830 , url =
-
[11]
Hinton, Geoffrey and Vinyals, Oriol and Dean, Jeff , journal =
-
[12]
, journal =
Hartman, Max and Jayaraman, Vidhata and Choraria, Moulik and Savani, Yash and Varshney, Lav R. , journal =
-
[13]
Zhao, Kaixiang and Li, Lincan and Ding, Kaize and Gong, Neil Zhenqiang and Zhao, Yue and Dong, Yushun , booktitle =. 2025 , publisher =. doi:10.1145/3711896.3736573 , url =
-
[14]
2022 , address =
Xu, Qiongkai and He, Xuanli and Lyu, Lingjuan and Qu, Lizhen and Haffari, Gholamreza , booktitle =. 2022 , address =
2022
-
[15]
Birch, Lewis and Hackett, William and Trawicki, Stefan and Suri, Neeraj and Garraghan, Peter , journal =
-
[16]
Savani, Yash and Trockman, Asher and Feng, Zhili and Xu, Yixuan Even and Schwarzschild, Avi and Robey, Alexander and Finzi, Marc and Kolter, J Zico , booktitle =
-
[17]
Li, Pingzhi and Tan, Zhen and Zhang, Mohan and Qu, Huaizhi and Liu, Huan and Chen, Tianlong , journal =
-
[18]
Ma, Haoyu and Chen, Tianlong and Hu, Ting-Kuei and You, Chenyu and Xie, Xiaohui and Wang, Zhangyang , booktitle =
-
[19]
2025 , publisher =
Chen, Huajie and Zhu, Tianqing and Zhang, Lefeng and Liu, Bo and Wang, Derui and Zhou, Wanlei and Xue, Minhui , journal =. 2025 , publisher =
2025
-
[20]
arXiv preprint arXiv:2503.20083 , year =
Minixhofer, Benjamin and Vuli. arXiv preprint arXiv:2503.20083 , year =
-
[21]
Cui, Xiao and Zhu, Mo and Qin, Yulei and Xie, Liang and Zhou, Wengang and Li, Houqiang , booktitle =
-
[22]
Polino, Antonio and Pascanu, Razvan and Alistarh, Dan , booktitle =
-
[23]
Cheng, Yu and Wang, Duo and Zhou, Pan and Zhang, Tao , journal =
-
[24]
Model compression , author =. Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year =. doi:10.1145/1150402.1150464 , url =
-
[25]
Li, Chong and Zhang, Jiajun and Zong, Chengqing , journal =
-
[26]
Reuters , year =
Deepa Seetharaman and Fabiola Ar. Reuters , year =
-
[27]
Ding, Jiayu and Cui, Lei and Dong, Li and Zheng, Nanning and Wei, Furu , journal =
-
[28]
2026 , howpublished =
Reasoning models: Reasoning summaries , author =. 2026 , howpublished =
2026
-
[29]
Zou, Andy and Wang, Zifan and Carlini, Nicholas and Nasr, Milad and Kolter, J Zico and Fredrikson, Matt , journal =
-
[30]
2019 , organization =
Juuti, Mika and Szyller, Sebastian and Marchal, Samuel and Asokan, N , booktitle =. 2019 , organization =
2019
-
[31]
Fang, Hao and Zhang, Tianyi and Zhuang, Tianqu and Kong, Jiawei and Gao, Kuofeng and Chen, Bin and Liang, Leqi and Xia, Shu-Tao and Xu, Ke , journal =
-
[32]
Ma, Xinhang and Yeoh, William and Zhang, Ning and Vorobeychik, Yevgeniy , journal =
-
[33]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , month = mar, year =
-
[34]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
H. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[35]
International Conference on Machine Learning (ICML) , pages =
Jovanovi. International Conference on Machine Learning (ICML) , pages =. 2024 , organization =
2024
-
[36]
Qi, Xiangyu and Wei, Boyi and Carlini, Nicholas and Huang, Yangsibo and Xie, Tinghao and He, Luxi and Jagielski, Matthew and Nasr, Milad and Mittal, Prateek and Henderson, Peter , booktitle =
-
[37]
Tamirisa, Rishub and Bharathi, Bhrugu and Phan, Long and Zhou, Andy and Gatti, Alice and Suresh, Tarun and Lin, Maxwell and Wang, Justin and Wang, Rowan and Arel, Ron and others , booktitle =
-
[38]
2024 , address =
Li, Xiang and He, Shizhu and Wu, Jiayu and Yang, Zhao and Xu, Yao and Jun, Yang and Liu, Haifeng and Liu, Kang and Zhao, Jun , booktitle =. 2024 , address =
2024
-
[39]
Shridhar, Kumar and Stolfo, Alessandro and Sachan, Mrinmaya , journal =
-
[40]
Xu, Yixuan Even and Kirchenbauer, John and Savani, Yash and Trockman, Asher and Robey, Alexander and Goldstein, Tom and Fang, Fei and Kolter, J Zico , journal =
-
[41]
2023 , organization =
Kirchenbauer, John and Geiping, Jonas and Wen, Yuxin and Katz, Jonathan and Miers, Ian and Goldstein, Tom , booktitle =. 2023 , organization =
2023
-
[42]
2026 , month = feb, note =
2026
-
[43]
and Meyer, Stuart P
Hulse, Robert and Newby, Tyler G. and Meyer, Stuart P. and Tsang, Fredrick , year =
-
[44]
Jiang, Bo , journal =
-
[45]
Krishna, Kalpesh and Tomar, Gaurav Singh and Parikh, Ankur P and Papernot, Nicolas and Iyyer, Mohit , booktitle =
-
[46]
, year =
Taori, Rohan and Gulrajani, Ishaan and Zhang, Tianyi and Dubois, Yann and Li, Xuechen and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , year =
-
[47]
Peng, Baolin and Li, Chunyuan and He, Pengcheng and Galley, Michel and Gao, Jianfeng , journal =
-
[48]
arXiv preprint arXiv:2501.12948 , year =
-
[49]
Carlini, Nicholas and Athalye, Anish and Papernot, Nicolas and Brendel, Wieland and Rauber, Jonas and Tsipras, Dimitris and Goodfellow, Ian and Madry, Aleksander and Kurakin, Alexey , journal =
-
[50]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[51]
Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=
Evaluations of machine learning privacy defenses are misleading , author=. Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=
2024
-
[52]
arXiv preprint arXiv:2510.09023 , year=
The attacker moves second: Stronger adaptive attacks bypass defenses against LLM jailbreaks and prompt injections , author=. arXiv preprint arXiv:2510.09023 , year=
-
[53]
International conference on machine learning , pages=
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[54]
Advances in neural information processing systems , volume=
On adaptive attacks to adversarial example defenses , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.