TokenMinds: Pretrained User Tokens and Embeddings for User Understanding in Large Recommender Systems
Pith reviewed 2026-06-25 21:58 UTC · model grok-4.3
The pith
TokenMinds generates both discrete SID-based user tokens and dense embeddings from behavior sequences using an LLM-adapted encoder-decoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TokenMinds extends the PLUM framework from item retrieval to user modeling, training an encoder-decoder on user behavior sequences to output both discrete SID-based user tokens and dense user embeddings. This dual-output design supplies complementary benefits of semantically grounded discrete representations and dense vector compatibility for downstream models. The shared SID vocabulary unifies long-form and short-form video behaviors in a single model, cutting training and serving costs. Results from extensive offline experiments and live launches on multiple YouTube surfaces confirm viability at industrial scale with full user traffic via asynchronous infrastructure.
What carries the argument
Dual-output encoder-decoder architecture adapted from pre-trained LLMs that produces both discrete SID user tokens and dense embeddings from behavior sequences, with a shared vocabulary for cross-scenario unification.
If this is right
- Discrete SID user tokens become available for integration into generative recommendation systems.
- Shared SID vocabulary enables single-model handling of long-form and short-form behaviors without separate training.
- Dense embeddings ensure direct compatibility with existing downstream scoring models.
- Asynchronous infrastructure supports scaling representation generation independently from ranking.
- Complementary gains appear across different production ranking systems.
Where Pith is reading between the lines
- The discrete tokens could support more interpretable user preference analysis by direct inspection of their semantic content.
- The unification approach might transfer to non-video domains such as product or music recommendation.
- Asynchronous decoupling of token generation could improve latency in other large-scale recommender pipelines.
- Semantic grounding of tokens may enable better cross-domain transfer of user representations.
Load-bearing premise
An encoder-decoder architecture adapted from pre-trained LLMs will produce discrete user tokens that are semantically grounded to item attributes when applied to user behavior sequences.
What would settle it
If live ranking experiments on YouTube show no performance gain from the SID tokens or no cost reduction from unifying long and short behaviors compared to separate models, the dual-output and unification claims would not hold.
Figures

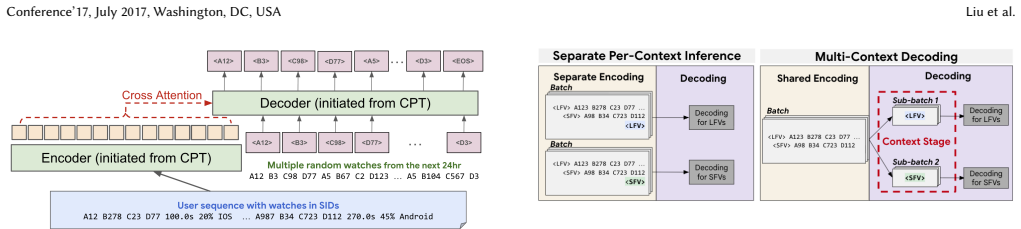
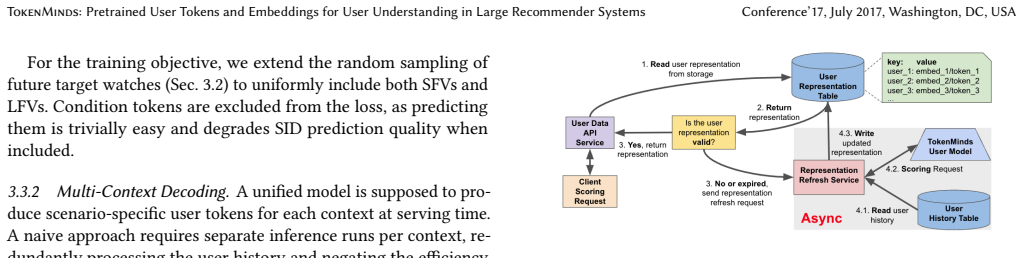
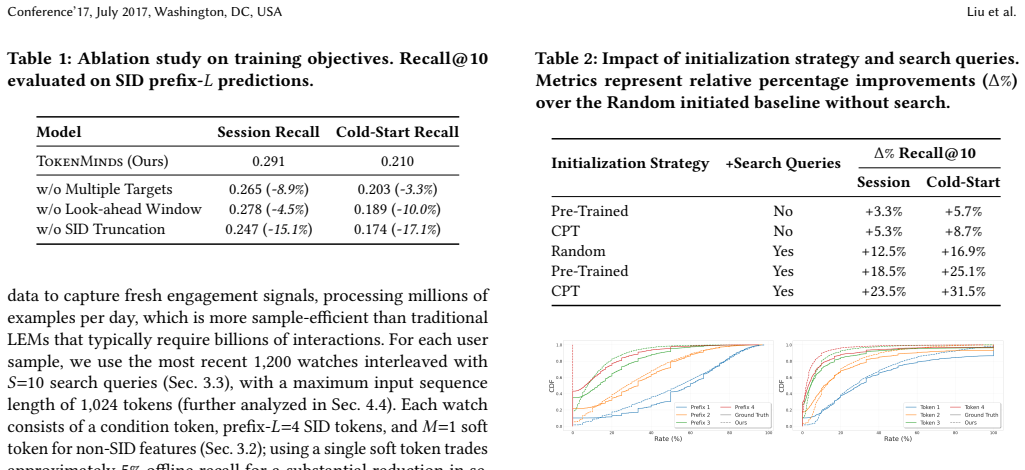

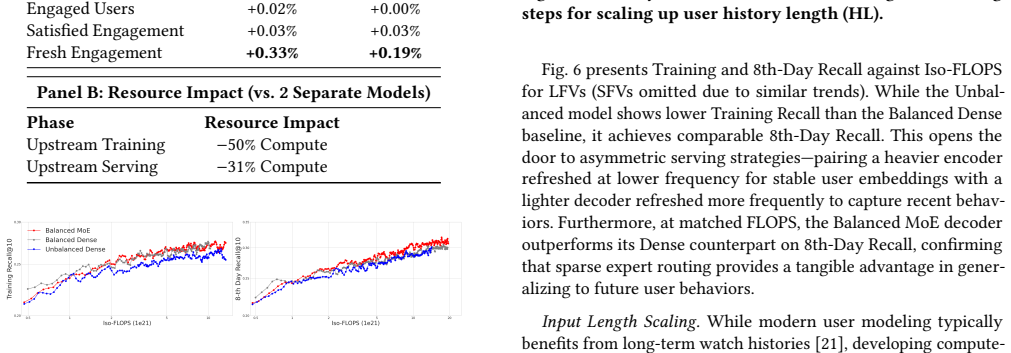
read the original abstract
User modeling in industrial recommender systems typically produces dense embeddings, which suffer from representational constraints inherent to fixed-dimensional vectors. An emerging alternative for discrete user representation -- using LLMs to generate text-based user tokens -- captures topical co-occurrences rather than deep sequential behavior dynamics and produces outputs that are difficult to ground to item attributes. Meanwhile, Semantic ID (SID) based item tokenization has proven effective for improving generalization in generative recommendation, yet discrete SID-based representations for users remain largely unexplored. We propose TokenMinds, an industrial-scale system that extends the PLUM framework from item retrieval to user modeling, generating both discrete SID-based user tokens and dense user embeddings via an encoder-decoder architecture adapted from pre-trained LLMs. This dual-output design provides the complementary benefits of discrete, semantically grounded user representations while maintaining compatibility with existing downstream models that rely on dense embeddings. Additionally, the shared SID vocabulary naturally extends to cross-scenario modeling: by unifying long-form and short-form video behaviors into a single model, we substantially reduce training and serving costs. We validate TokenMinds through extensive offline experiments and live launches on multiple YouTube surfaces, served on full user traffic (billions of users) via an asynchronous infrastructure that decouples representation generation from downstream scoring. Focusing on ranking as the primary downstream use case, our results confirm the practical viability of SID-based user tokens at industrial scale and demonstrate that tokens and dense embeddings provide complementary value across different production ranking systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TokenMinds, an industrial-scale system extending the PLUM framework to user modeling. It uses an encoder-decoder architecture adapted from pre-trained LLMs to generate both discrete SID-based user tokens and dense user embeddings from behavior sequences. The dual-output design is claimed to deliver complementary benefits of semantically grounded discrete representations while remaining compatible with existing dense-embedding downstream models; a shared SID vocabulary unifies long-form and short-form behaviors to cut training and serving costs. Validation is asserted via offline experiments and live launches on multiple YouTube surfaces serving full user traffic (billions of users), with ranking as the primary downstream task.
Significance. If the empirical claims hold, the work would be significant for large-scale recommender systems by demonstrating a practical route to discrete, attribute-grounded user tokens that complement rather than replace dense embeddings and that scale to cross-scenario unification at industrial cost.
major comments (2)
- [Abstract] Abstract: the claim that the encoder-decoder adaptation produces discrete SID tokens that are 'semantically grounded to item attributes' and capture 'deep sequential behavior dynamics' (rather than topical co-occurrences) is load-bearing for the central complementarity and unification arguments, yet the abstract supplies no description of the tokenization of user sequences, the decoder constraint to valid SIDs, or any grounding loss/regularizer.
- [Abstract] Abstract: validation is asserted through 'extensive offline experiments and live launches on full user traffic' with 'complementary value' and 'cost reductions,' but no metrics, baselines, ablations, or controls are reported, preventing assessment of whether the dual-output design actually delivers the stated benefits.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address the two major comments point-by-point below, clarifying that the abstract is intentionally concise while the full technical details and empirical results appear in the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the encoder-decoder adaptation produces discrete SID tokens that are 'semantically grounded to item attributes' and capture 'deep sequential behavior dynamics' (rather than topical co-occurrences) is load-bearing for the central complementarity and unification arguments, yet the abstract supplies no description of the tokenization of user sequences, the decoder constraint to valid SIDs, or any grounding loss/regularizer.
Authors: The abstract is a high-level summary limited to 200-250 words and therefore omits implementation specifics. The full manuscript (Section 3) details the user-sequence tokenization process, the encoder-decoder adaptation from pre-trained LLMs, the explicit constraint that the decoder only emits tokens from the shared SID vocabulary, and the auxiliary losses used to encourage semantic grounding to item attributes while modeling sequential dynamics. These mechanisms are what distinguish the approach from purely topical LLM tokenization. We believe the abstract's claims are therefore justified by the methods and results sections. revision: no
-
Referee: [Abstract] Abstract: validation is asserted through 'extensive offline experiments and live launches on full user traffic' with 'complementary value' and 'cost reductions,' but no metrics, baselines, ablations, or controls are reported, preventing assessment of whether the dual-output design actually delivers the stated benefits.
Authors: Abstracts conventionally avoid numerical results to remain readable. The manuscript reports the requested metrics, baselines, ablations, and controls in Sections 4 and 5 (offline experiments) and Section 6 (live A/B tests on multiple YouTube surfaces with full user traffic). These sections quantify the complementary gains of the dual token-plus-embedding output and the training/serving cost reductions from the shared SID vocabulary. The abstract's high-level statements are therefore backed by the concrete evidence presented later. revision: no
Circularity Check
No circularity; empirical system description with external validation
full rationale
The manuscript presents TokenMinds as an engineering extension of the PLUM framework to user sequences, producing dual SID tokens plus embeddings via an adapted encoder-decoder, with claims of complementary value and cross-scenario unification supported by offline experiments and live launches on full YouTube traffic. No equations, parameter-fitting steps, or derivations are referenced in the abstract or described architecture. The central assertions are framed as measured outcomes from production A/B tests rather than quantities obtained by construction from fitted inputs or self-citations. Self-reference to PLUM is noted but does not carry any load-bearing uniqueness theorem or ansatz that the present work then re-derives; the novelty and viability rest on scale validation outside the cited prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Suyog Joshi, Manjunath Kudlur, Brian Levenstein, Claire Lloyd, Xinyuan Liu, Hao Mao, et al
-
[2]
InProceedings of the 5th Conference on Machine Learning and Systems (MLSys)
Pathways: Asynchronous Distributed Dataflow for ML. InProceedings of the 5th Conference on Machine Learning and Systems (MLSys)
-
[3]
2018.JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018.JAX: composable transformations of Python+NumPy programs. http://github.com/google/jax
2018
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[6]
Bo Chang, Alexandros Karatzoglou, Yuyan Wang, Can Xu, Ed H Chi, and Min- min Chen. 2023. Latent user intent modeling for sequential recommenders. In Companion Proceedings of the ACM Web Conference 2023. 427–431
2023
-
[7]
Benjamin Coleman, Wang-Cheng Kang, Matthew Fahrbach, Ruoxi Wang, Lichan Hong, Ed Chi, and Derek Cheng. 2023. Unified embedding: Battle-tested feature representations for web-scale ML systems.Advances in Neural Information Processing Systems36 (2023), 56234–56255
2023
-
[8]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
2016
-
[9]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
2022
-
[10]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al
-
[11]
Plum: Adapting pre-trained language models for industrial-scale generative recommendations.arXiv preprint arXiv:2510.07784(2025)
arXiv 2025
-
[12]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[13]
In International Conference on Learning Representations (ICLR)
Session-based Recommendations with Recurrent Neural Networks. In International Conference on Learning Representations (ICLR)
-
[14]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating long semantic ids in parallel for recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 956–966
2025
-
[15]
Yanhua Huang, Yuqi Chen, Xiong Cao, Rui Yang, Mingliang Qi, Yinghao Zhu, Qingchang Han, Yaowei Liu, Zhaoyu Liu, Xuefeng Yao, et al . 2025. Towards large-scale generative ranking.arXiv preprint arXiv:2505.04180(2025)
arXiv 2025
-
[16]
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. 2025. Generative Recommendation with Seman- tic IDs: A Practitioner’s Handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6420–6425
2025
-
[17]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Rec- ommendation. InIEEE International Conference on Data Mining (ICDM). IEEE, 197–206
2018
-
[18]
Sein Kim, Hongseok Kang, Kibum Kim, Jiwan Kim, Donghyun Kim, Minchul Yang, Kwangjin Oh, Julian McAuley, and Chanyoung Park. 2025. Lost in Sequence: Do Large Language Models Understand Sequential Recommendation?. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
2025
-
[19]
Taku Kudo. 2018. Subword regularization: Improving neural network translation models with multiple subword candidates. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 66–75
2018
-
[20]
Yuening Li, Diego Uribe, Chuan He, Jiaxi Tang, Qingyun Liu, Junjie Shan, Ben Most, Kaushik Kalyan, Shuchao Bi, Xinyang Yi, et al. 2024. Short-form Video Needs Long-term Interests: An Industrial Solution for Serving Large User Se- quence Models. InProceedings of the 18th ACM Conference on Recommender Systems. 832–834
2024
-
[21]
Qingyun Liu, Zhe Zhao, Liang Liu, Zhen Zhang, Junjie Shan, Yuening Li, Shuchao Bi, Lichan Hong, and Ed H Chi. 2023. Multitask Ranking System for Immersive Feed and No More Clicks: A Case Study of Short-Form Video Recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4709–4716
2023
-
[22]
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al
-
[23]
Onerec-think: In-text reasoning for generative recommendation.arXiv preprint arXiv:2510.11639(2025)
arXiv 2025
-
[24]
Ilya Loshchilov and Frank Hutter. 2016. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983(2016)
Pith/arXiv arXiv 2016
-
[25]
Wenhan Lyu, Devashish Tyagi, Yihang Yang, Ziwei Li, Ajay Somani, Karthikeyan Shanmugasundaram, Nikola Andrejevic, Ferdi Adeputra, Curtis Zeng, Arun K Singh, et al. 2025. DV365: Extremely Long User History Modeling at Instagram. arXiv preprint arXiv:2506.00450(2025)
arXiv 2025
-
[26]
Muyang Ma, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Lifan Zhao, Peiyu Liu, Jun Ma, and Maarten de Rijke. 2022. Mixed information flow for cross-domain sequential recommendations.ACM Transactions on Knowledge Discovery from Data (TKDD)16, 4 (2022), 1–32
2022
-
[27]
Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. 2022. Pinner- former: Sequence modeling for user representation at pinterest. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 3702–3712
2022
-
[28]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. 2023. Recommender systems with generative retrieval. InProceedings of the 37th International Conference on Neural Information Processing Systems (NIPS ’23). Curran ...
2023
-
[29]
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, Ed Chi, and Xinyang Yi. 2024. Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24). Association fo...
2024
-
[30]
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, and Yongfeng Zhang. 2024. Idgenrec: Llm-recsys alignment with textual id learning. InProceed- ings of the 47th international ACM SIGIR conference on research and development in information retrieval. 355–364
2024
-
[31]
Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining (WSDM). ACM, 565– 573
2018
-
[32]
Yuhao Wang, Yichao Wang, Zichuan Fu, Xiangyang Li, Wanyu Wang, Yuyang Ye, Xiangyu Zhao, Huifeng Guo, and Ruiming Tang. 2024. Llm4msr: An llm- enhanced paradigm for multi-scenario recommendation. InACM International Conference on Information and Knowledge Management
2024
-
[33]
Orion Weller, Michael Boratko, Iftekhar Naim, and Jinhyuk Lee. 2025. On the theoretical limitations of embedding-based retrieval, 2025.URL https://arxiv. org/abs/2508.21038(2025)
arXiv 2025
-
[34]
Manjie Xu, Cheng Chen, Xin Jia, Jingyi Zhou, Yongji Wu, Zejian Wang, Chi Zhang, Kai Zuo, Yibo Chen, Xu Tang, et al. 2025. Cross-Scenario Unified Modeling of User Interests at Billion Scale.arXiv preprint arXiv:2510.14788(2025)
arXiv 2025
-
[35]
Bei Yang, Jie Gu, Ke Liu, Xiaoxiao Xu, Renjun Xu, Qinghui Sun, and Hong Liu. 2023. Empowering General-purpose User Representation with Full-life Cycle Behavior Modeling. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM, 5364–5374
2023
-
[36]
Fan Yang, Zheng Chen, Ziyan Jiang, Eunah Cho, Xiaojiang Huang, and Yanbin Lu. 2023. Palr: Personalization aware llms for recommendation.arXiv preprint arXiv:2305.07622(2023)
arXiv 2023
-
[37]
Liu Yang, Fabian Paischer, Kaveh Hassani, Jiacheng Li, Shuai Shao, Zhang Gabriel Li, Yun He, Xue Feng, Nima Noorshams, Sem Park, et al . 2024. Unifying gen- erative and dense retrieval for sequential recommendation.arXiv preprint arXiv:2411.18814(2024)
arXiv 2024
-
[38]
Yuhao Yang, Zhi Ji, Zhaopeng Li, Yi Li, Zhonglin Mo, Yue Ding, Kai Chen, Zijian Zhang, Jie Li, LIU LIN, et al . 2026. Sparse meets dense: Unified generative recommendations with cascaded sparse-dense representations.Advances in Neural Information Processing Systems38 (2026), 93746–93770
2026
-
[39]
Zhiming Yang, Haining Gao, Dehong Gao, Luwei Yang, Libin Yang, Xiaoyan Cai, Wei Ning, and Guannan Zhang. 2024. Mlora: Multi-domain low-rank adaptive network for ctr prediction. InACM Conference on Recommender Systems
2024
-
[40]
Tianzi Zang, Yanmin Zhu, Haobing Liu, Ruohan Zhang, and Jiadi Yu. 2022. A survey on cross-domain recommendation: taxonomies, methods, and future directions.ACM Transactions on Information Systems41, 2 (2022), 1–39
2022
-
[41]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. In International Conference on Machine Learning (ICML)
2024
-
[42]
Jun Zhang, Yi Li, Yue Liu, Changping Wang, Yuan Wang, Yuling Xiong, Xun Liu, Haiyang Wu, Qian Li, Enming Zhang, et al. 2025. GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation. arXiv preprint arXiv:2511.10138(2025)
arXiv 2025
-
[43]
Zhe Zhao, Lichan Hong, Li Wei, Jilin Chen, Aniruddh Nath, Shawn Andrews, Aditee Kumthekar, Maheswaran Sathiamoorthy, Xinyang Yi, and Ed Chi. 2019. Recommending what video to watch next: a multitask ranking system. InPro- ceedings of the 13th ACM conference on recommender systems. 43–51
2019
-
[44]
Guorui Zhou, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Qiang Luo, Qian- qian Wang, Qigen Hu, Rui Huang, Shiyao Wang, et al. 2025. OneRec Technical Report.arXiv preprint arXiv:2506.13695(2025). 9 Conference’17, July 2017, Washington, DC, USA Liu et al
arXiv 2025
-
[45]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900(2025)
Pith/arXiv arXiv 2025
-
[46]
Jingyi Zhou, Cheng Chen, Kai Zuo, Manjie Xu, Zhendong Fu, Yibo Chen, Xu Tang, and Yao Hu. 2025. HyMiRec: A Hybrid Multi-interest Learning Framework for LLM-based Sequential Recommendation.arXiv preprint arXiv:2510.13738 (2025). 10
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.