Learning Interpretable Text Signals for Structured Responses
Pith reviewed 2026-06-25 20:35 UTC · model grok-4.3
The pith
Joint non-negative matrix factorization and binomial regression learns document topics aligned with ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining non-negative matrix factorization for text reconstruction with binomial regression for rating prediction, the shared document-topic matrix recovers stable signals that are relevant to the external response variable while maintaining competitive predictive performance against separate regression baselines on both simulated and real review data.
What carries the argument
The joint non-negative matrix factorization and binomial regression model in which the document-topic representation is learned simultaneously from text reconstruction loss and rating prediction loss.
If this is right
- The learned topics can be read as response-relevant textual signals rather than purely descriptive factors.
- Prediction accuracy on bounded ratings remains competitive with linear and ridge regression that use bag-of-words or similar features.
- The same joint framework can be extended to other response types by replacing the binomial regression component.
- The model supplies an initial practical method for interpretable modelling of text-linked structured outcomes.
Where Pith is reading between the lines
- Changing the link function or loss could allow the same joint structure to handle count or continuous responses without redesigning the factorization step.
- Stability of the recovered signals across resamples may indicate robustness when text data contain high levels of irrelevant variation.
- The approach could be tested on paired text and outcome data from domains such as medical records or policy documents to check whether the aligned topics reveal domain-specific patterns.
Load-bearing premise
That jointly optimizing the topic representation for both reconstruction and prediction yields signals that are stably aligned with the response rather than merely fitting sample-specific noise.
What would settle it
In repeated simulations with known generating topics, the recovered topics either fail to match the planted response-relevant topics or show large variation in alignment with the ratings across independent draws from the same distribution.
Figures

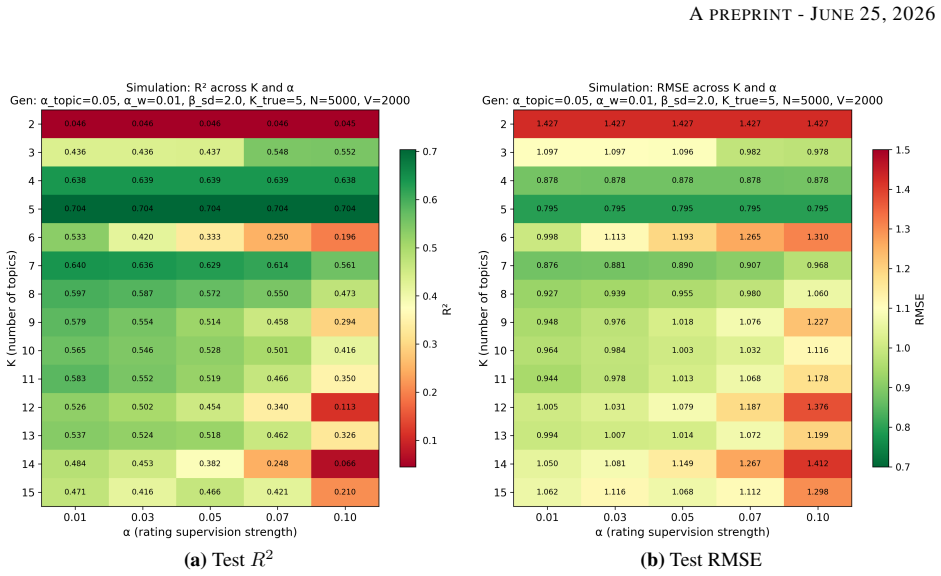
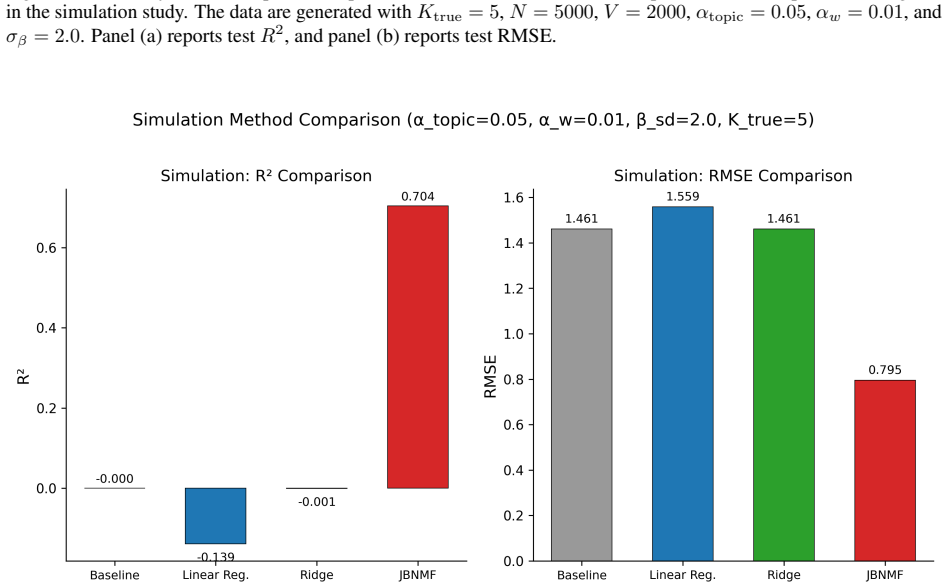



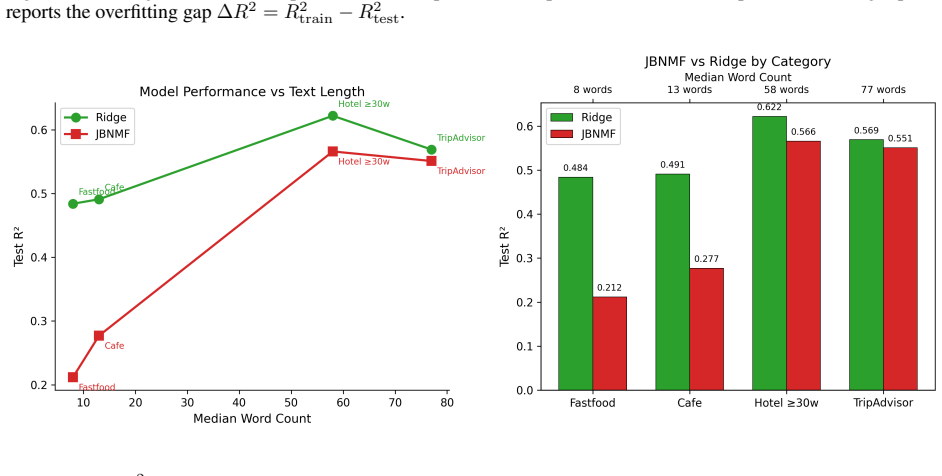
read the original abstract
Textual data are often collected alongside structured response variables, but prediction and interpretation are commonly treated as separate tasks. This paper studies rating prediction as an initial case of interpretable text-response modelling, where the aim is to learn textual representations that are both semantically meaningful and aligned with an external response. We propose a joint non-negative matrix factorisation and binomial regression model, in which the document-topic representation is learned from both text reconstruction and rating prediction. Simulation experiments and a real-world review dataset show that the model can recover stable response-relevant textual signals and achieve competitive performance against linear and ridge regression baselines. The framework provides a practical step towards interpretable modelling of text-linked outcomes, with potential extensions to other response types beyond bounded ratings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a joint non-negative matrix factorization (NMF) and binomial regression model in which the document-topic representation is learned simultaneously from text reconstruction and rating prediction objectives. Simulation experiments and a real-world review dataset are presented as evidence that the model recovers stable response-relevant textual signals while achieving competitive performance against linear and ridge regression baselines. The framework is positioned as a step toward interpretable modeling of text-linked structured outcomes with potential extensions to other response types.
Significance. If the empirical claims hold with adequate validation, the work would provide a practical joint-optimization approach that bridges the common separation between prediction and interpretation tasks in text analysis, offering a template for response-aligned textual representations that could generalize beyond bounded ratings.
major comments (2)
- [Abstract] Abstract: the claim that simulation experiments and a real-world review dataset support recovery of stable signals and competitive performance is made without any quantitative details, error bars, description of baselines, data splits, or hyperparameter choices. This absence prevents evaluation of the central claim.
- [Model] Model section (joint NMF-binomial objective): standard NMF admits permutation, scaling, and local-minima ambiguities; the added binomial regression term constrains factors only through the shared representation and response link but does not automatically eliminate these ambiguities without specified regularizers or initialization strategies. The abstract asserts stability yet supplies no indication of how stability is measured or enforced.
minor comments (1)
- [Abstract] Abstract: a brief statement of the specific metrics used to quantify stability and performance would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating where the manuscript will be revised for clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that simulation experiments and a real-world review dataset support recovery of stable signals and competitive performance is made without any quantitative details, error bars, description of baselines, data splits, or hyperparameter choices. This absence prevents evaluation of the central claim.
Authors: We agree that the abstract is written at a high level and does not include specific quantitative results. The full manuscript reports performance metrics, variability across runs, baseline comparisons, data partitioning, and hyperparameter settings in the simulation and real-data experiments. To address the concern, we will revise the abstract to incorporate concise quantitative highlights (e.g., key accuracy or correlation figures with variability measures) while preserving its brevity. revision: yes
-
Referee: [Model] Model section (joint NMF-binomial objective): standard NMF admits permutation, scaling, and local-minima ambiguities; the added binomial regression term constrains factors only through the shared representation and response link but does not automatically eliminate these ambiguities without specified regularizers or initialization strategies. The abstract asserts stability yet supplies no indication of how stability is measured or enforced.
Authors: The referee correctly notes the standard identifiability issues in NMF. The joint objective couples the topic loadings to the binomial response through the shared document representation, which empirically reduces arbitrary scaling and permutation effects relative to unsupervised NMF; stability is evaluated via repeated random initializations and consistency of recovered signals across simulation replicates, as shown in the experimental results. We will expand the model section to explicitly describe the initialization procedure, any regularization terms employed, and the quantitative criteria used to assess stability of the response-relevant factors. revision: yes
Circularity Check
No circularity: joint objective and external validation are independent of fitted inputs
full rationale
The paper defines a joint NMF-binomial regression model whose document-topic factors are optimized simultaneously for text reconstruction and rating prediction. Claims of recovering stable response-relevant signals rest on simulation experiments and a held-out review dataset rather than any reduction of the output to the model's own fitted parameters by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to load-bear the central result; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Non-negative matrix factorization yields semantically meaningful document-topic representations when jointly optimized with an external response.
- standard math Binomial regression is an appropriate link function for bounded rating responses.
Reference graph
Works this paper leans on
-
[1]
Surface impedance of superconductors with weak magnetic impurities
doi: 10.1287/mnsc.1110.1370. 14 APREPRINT- JUNE25, 2026 David M. Blei, Andrew Y . Ng, and Michael I. Jordan. Latent dirichlet allocation.Journal of Machine Learning Research, 3:993–1022,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1287/mnsc.1110.1370 2026
-
[2]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
doi: 10.1509/jmkr.43.3.345. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume 1, pages 4171–4186. Associat...
-
[3]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
doi: 10.18653/v1/N19-1423. URL https://doi.org/10. 18653/v1/N19-1423. Shoumik Dhar. Tripadvisor hotel reviews 20k dataset. https://www.kaggle.com/datasets/shoumikdhar/ tripadvisor-hotel-reviews-20k-dataset,
-
[4]
Thomas L
Accessed: 2026-05-28. Thomas L. Griffiths and Mark Steyvers. Finding scientific topics.Proceedings of the National Academy of Sci- ences, 101(suppl. 1):5228–5235,
2026
-
[5]
URL https://doi.org/10.1073/pnas
doi: 10.1073/pnas.0307752101. URL https://doi.org/10.1073/pnas. 0307752101. Trevor Hastie, Robert Tibshirani, and Jerome Friedman.The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, New York, 2 edition,
-
[6]
URL https://doi.org/ 10.1007/978-0-387-84858-7
doi: 10.1007/978-0-387-84858-7. URL https://doi.org/ 10.1007/978-0-387-84858-7. Arthur E. Hoerl and Robert W. Kennard. Ridge regression: Biased estimation for nonorthogonal problems.Technomet- rics, 12(1):55–67,
-
[7]
URL https://doi.org/10.1080/00401706
doi: 10.1080/00401706.1970.10488634. URL https://doi.org/10.1080/00401706. 1970.10488634. Nan Hu, Jie Zhang, and Paul A. Pavlou. Overcoming the J-shaped distribution of product reviews.Communications of the ACM, 52(10):144–147,
-
[8]
doi: 10.1145/1562764.1562800. C. J. Hutto and Eric Gilbert. V ADER: A parsimonious rule-based model for sentiment analysis of social media text. InProceedings of the International AAAI Conference on Web and Social Media, pages 216–225,
-
[9]
doi: 10.1609/icwsm.v8i1.14550. Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness? InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4198–4205. Association for Computational Linguistics,
-
[10]
URL https: //doi.org/10.18653/v1/2020.acl-main.386
doi: 10.18653/v1/2020.acl-main.386. URL https: //doi.org/10.18653/v1/2020.acl-main.386. Jingu Kim, Yunlong He, and Haesun Park. Algorithms for nonnegative matrix and tensor factorizations: A unified view based on block coordinate descent framework.Journal of Global Optimization, 58(2):285–319,
-
[11]
doi: 10.1007/s10898-013-0035-4. Daniel D. Lee and H. Sebastian Seung. Learning the parts of objects by non-negative matrix factorization.Nature, 401 (6755):788–791,
-
[12]
doi: 10.1038/44565. Daniel D. Lee and H. Sebastian Seung. Algorithms for non-negative matrix factorization. InAdvances in Neural Information Processing Systems 13, pages 556–562. MIT Press,
-
[13]
doi: 10.18653/v1/2022.acl-long.426
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.426. URLhttps://aclanthology.org/2022.acl-long.426/. Zachary C. Lipton. The mythos of model interpretability.Communications of the ACM, 61(10):36–43,
-
[14]
doi: 10.1145/3233231. URLhttps://doi.org/10.1145/3233231. Bing Liu.Sentiment Analysis and Opinion Mining. Synthesis Lectures on Human Language Technologies. Morgan & Claypool Publishers, San Rafael, CA,
-
[15]
URL https: //doi.org/10.2200/S00416ED1V01Y201204HLT016
doi: 10.2200/S00416ED1V01Y201204HLT016. URL https: //doi.org/10.2200/S00416ED1V01Y201204HLT016. Bin Lu, Myle Ott, Claire Cardie, and Benjamin K. Tsou. Multi-aspect sentiment analysis with topic models. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, pages 81–88. IEEE,
-
[16]
doi: 10.1109/ICDMW.2011.125. Michael Luca. Reviews, reputation, and revenue: The case of Yelp.com. Working Paper 12-016, Harvard Business School,
-
[17]
Regression models for ordinal data.Journal of the Royal Statistical Society: Series B (Methodological), 42(2):109–142,
15 APREPRINT- JUNE25, 2026 Peter McCullagh. Regression models for ordinal data.Journal of the Royal Statistical Society: Series B (Methodological), 42(2):109–142,
2026
-
[18]
doi: 10.1111/j.2517-6161.1980.tb01109.x. Bo Pang and Lillian Lee. Opinion mining and sentiment analysis.F oundations and Trends in Information Retrieval, 2 (1–2):1–135,
-
[19]
doi: 10.1561/1500000011. James W. Pennebaker, Roger J. Booth, Ryan L. Boyd, and Martha E. Francis.Linguistic Inquiry and Word Count: LIWC2015. Pennebaker Conglomerates, Austin, TX,
-
[20]
Gerard Salton and Christopher Buckley
doi: 10.1111/ajps.12103. Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval.Information Processing & Management, 24(5):513–523,
-
[21]
URL https://doi.org/10.1016/ 0306-4573(88)90021-0
doi: 10.1016/0306-4573(88)90021-0. URL https://doi.org/10.1016/ 0306-4573(88)90021-0. Matt Taddy. Multinomial inverse regression for text analysis.Journal of the American Statistical Association, 108(503): 755–770,
-
[22]
Journal of the American Statistical Association , Year =
doi: 10.1080/01621459.2012.734168. Robert Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B, 58 (1):267–288,
-
[23]
URL https://doi.org/10.1111/j.2517-6161
doi: 10.1111/j.2517-6161.1996.tb02080.x. URL https://doi.org/10.1111/j.2517-6161. 1996.tb02080.x. Ivan Titov and Ryan T. McDonald. Modeling online reviews with multi-grain topic models. InProceedings of the 17th International Conference on World Wide Web, pages 111–120. Association for Computing Machinery,
-
[24]
URLhttps://doi.org/10.1145/1367497.1367513
doi: 10.1145/1367497.1367513. URLhttps://doi.org/10.1145/1367497.1367513. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, pages 5998–6008,
-
[25]
An Yan, Zhankui He, Jiacheng Li, Tianyang Zhang, and Julian McAuley
doi: 10.1145/860435.860485. An Yan, Zhankui He, Jiacheng Li, Tianyang Zhang, and Julian McAuley. Personalized showcases: Generating multi- modal explanations for recommendations. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2251–2255. Association for Computing Machinery,
-
[26]
URLhttps://doi.org/10.1145/3539618.3592036
doi: 10.1145/3539618.3592036. URLhttps://doi.org/10.1145/3539618.3592036. Xiaohui Yan, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. A biterm topic model for short texts. InProceedings of the 22nd International Conference on World Wide Web, pages 1445–1456. Association for Computing Machinery,
-
[27]
Tianyang Zhang and Jiacheng Li
doi: 10.1145/2488388.2488514. Tianyang Zhang and Jiacheng Li. Google local data (2021). https://mcauleylab.ucsd.edu/public_datasets/ gdrive/googlelocal/,
-
[28]
A Derivation of the optimisation updates This section provides the derivation of the update rules used in the Joint Binomial NMF algorithm
Accessed: 2026-05-28. A Derivation of the optimisation updates This section provides the derivation of the update rules used in the Joint Binomial NMF algorithm. The notation is consistent with the model formulation in the main text. The document-term matrix is denoted by X∈R M×N + , the document-topic matrix by W∈R M×K + , the topic-term matrix by H∈R K×...
2026
-
[29]
For a nonnegative parametera≥0 , the multiplicative updates can be motivated from the KKT complementary slackness condition
For Yi ∈ {0,1,2,3,4} , the binomial regression component is Lrating =− MX i=1 [Yi logp i + (4−Y i) log(1−p i)],(A.3) 16 APREPRINT- JUNE25, 2026 where pi =σ(W i·β), σ(z) = 1 1 + exp(−z). For a nonnegative parametera≥0 , the multiplicative updates can be motivated from the KKT complementary slackness condition. If the relevant objective is denoted by J(a) ,...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.