DynaMOMA: Instantaneous Prediction of Grasp Poses for Mobile Manipulation of Dynamic Objects
Pith reviewed 2026-06-25 21:31 UTC · model grok-4.3
The pith
Coupling an anchor-based diffusion model for grasp prediction with a whole-body reinforcement learning policy enables mobile robots to handle dynamic objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
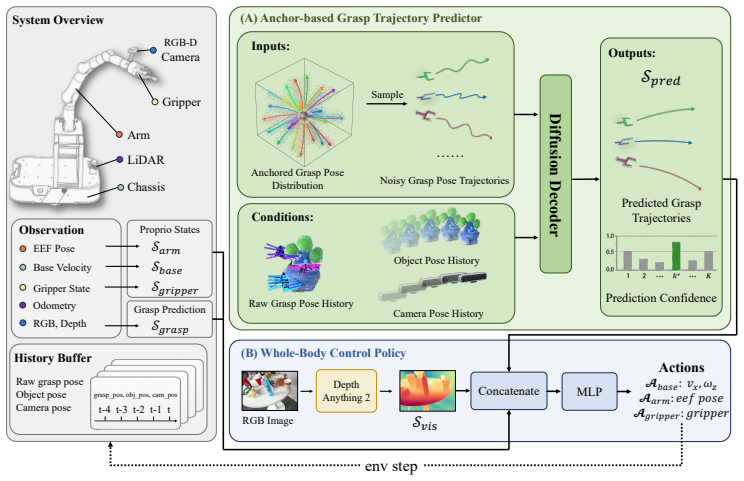
The paper claims that an anchor-based diffusion model conditioned only on historical observations can generate temporally consistent short-horizon grasp trajectories, which when encoded as compact features and supplied to a whole-body reinforcement learning policy equipped with an anticipation-guided reward, produce effective mobile manipulation of dynamic objects, with the approach showing strong results across simulation settings and generalizing to real-world trials.
What carries the argument
The anchor-based diffusion model that generates temporally consistent short-horizon grasp trajectories from historical observations, which are encoded and fed to the reinforcement learning policy.
If this is right
- The combined predictor and policy achieve strong performance across diverse simulation settings and grasping metrics.
- Both the predictor and the policy transfer with strong generalizability to physical robot hardware.
- The anticipation-guided reward gives the policy an explicit short-term horizon that improves coordination between base and arm.
- The framework handles the core difficulty of evolving target poses without requiring separate modules for navigation and reaching.
Where Pith is reading between the lines
- The same prediction-plus-policy structure could be tested on related dynamic tasks such as pushing or intercepting objects.
- Replacing the diffusion model with other generative predictors might reveal whether the anchor mechanism is essential or whether any temporally consistent forecaster would suffice.
- Extending the prediction horizon or adding multi-object handling would be a direct next measurement of the approach's limits.
- The encoding step that compresses trajectories into features for the policy could be inspected to see how much information is lost versus retained.
Load-bearing premise
That observations from the recent past are enough for the diffusion model to output grasp trajectories that stay useful once the object keeps moving.
What would settle it
Real-world trials in which objects accelerate or change direction faster than the training distribution, causing grasp success rates to fall well below the levels achieved when the predictor is used.
Figures



read the original abstract
Mobile manipulation is a fundamental robotics task and has advanced rapidly in recent years, enabling robots to navigate, reach, and interact with objects in complex environments. However, mobile manipulation of dynamic objects remains highly challenging, as robots must coordinate the mobile base and arm while adapting to continuously evolving target poses. A key challenge lies in predicting temporally consistent short-horizon grasp trajectories from dynamic observations. In this work, we propose \ours{}, a dynamic mobile manipulation framework that couples instantaneous grasp trajectory prediction with whole-body control policy. Our predictor uses an anchor-based diffusion model to generate temporally consistent short-horizon grasp trajectories conditioned on historical observations. The predicted trajectories are then encoded as compact features and fed to a whole-body reinforcement learning policy, which controls the mobile manipulator for dynamic grasping. We further introduce a anticipation-guided reward that equips the policy with an anticipatory grasping horizon by adaptively shifting the target from the current grasp observation to the instantaneously predicted grasp trajectory. Through extensive experiments in Isaac Gym simulation, we show that our method achieves strong performance in mobile manipulation of dynamic objects across diverse settings and grasping metrics. Furthermore, our predictor and policy demonstrate strong generalizability in real-world experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DynaMOMA, a framework for mobile manipulation of dynamic objects that couples an anchor-based diffusion model for instantaneous prediction of temporally consistent short-horizon grasp trajectories (conditioned on historical observations) with a whole-body reinforcement learning policy. Predicted trajectories are encoded as compact features for the policy, which is trained using an anticipation-guided reward that adaptively shifts the target grasp from current observations to the predicted trajectory. The manuscript claims strong performance across diverse settings and grasping metrics in Isaac Gym simulations, plus strong generalizability in real-world experiments.
Significance. If the empirical results hold with rigorous validation, the work could advance dynamic mobile manipulation by demonstrating a practical integration of diffusion-based trajectory prediction and whole-body RL control, particularly through the anticipation-guided reward mechanism. This addresses a key challenge in coordinating base and arm for evolving object poses. The approach builds on existing diffusion and RL techniques in a coherent architecture without introducing circular derivations.
major comments (2)
- [Abstract] Abstract: The central empirical claim of 'strong performance' and 'strong generalizability' is asserted without any quantitative metrics, baselines, error bars, ablation studies, or specific grasping metrics, which directly undermines the ability to evaluate whether the data support the claims as stated.
- [Abstract] Abstract (paragraph on predictor and policy coupling): The assumption that historical observations alone suffice to produce temporally consistent short-horizon grasp trajectories that remain useful when encoded for the RL policy under the anticipation-guided reward is presented without explicit testing or sensitivity analysis; this is load-bearing for the claimed coupling and requires verification in the experiments section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the claims require more concrete support to allow proper evaluation and will revise the abstract accordingly. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of 'strong performance' and 'strong generalizability' is asserted without any quantitative metrics, baselines, error bars, ablation studies, or specific grasping metrics, which directly undermines the ability to evaluate whether the data support the claims as stated.
Authors: We agree that the abstract's phrasing is too qualitative. In the revised version we will replace the generic claims with concise quantitative highlights drawn directly from the experiments (e.g., success rates, grasp-quality metrics, and baseline comparisons with standard deviations), while keeping the abstract within length limits. This change will be limited to the abstract and will not alter any experimental results. revision: yes
-
Referee: [Abstract] Abstract (paragraph on predictor and policy coupling): The assumption that historical observations alone suffice to produce temporally consistent short-horizon grasp trajectories that remain useful when encoded for the RL policy under the anticipation-guided reward is presented without explicit testing or sensitivity analysis; this is load-bearing for the claimed coupling and requires verification in the experiments section.
Authors: The experiments section already demonstrates end-to-end performance of the coupled system, but we acknowledge that an explicit sensitivity study isolating the role of historical observations would strengthen the manuscript. We will add a short ablation (varying the length of the observation history while keeping all other components fixed) and report the resulting changes in trajectory consistency and policy success rate. This addition will appear in the experiments section and will not require new data collection. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical robotics framework: an anchor-based diffusion predictor for grasp trajectories conditioned on history, encoded into a whole-body RL policy with an anticipation-guided reward. All performance claims are presented as outcomes of Isaac Gym simulation experiments and real-world tests rather than logical deductions or parameter fits that reduce to their own inputs by construction. No equations, self-definitional steps, or load-bearing self-citations appear in the provided description that would make the reported results circular; the method is framed as a proposed architecture validated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brock, J
O. Brock, J. Park, and M. Toussaint. Mobility and manipulation. InSpringer Handbook of Robotics, pages 1007–1036. Springer, 2016
2016
-
[2]
Hebert, M
P. Hebert, M. Bajracharya, J. Ma, N. Hudson, A. Aydemir, J. Reid, C. Bergh, J. Borders, M. Frost, M. Hagman, et al. Mobile manipulation and mobility as manipulation—design and algorithms of robosimian.Journal of Field Robotics, 32(2):255–274, 2015
2015
-
[3]
S. Wang, J. Zhang, M. Li, J. Liu, A. Li, K. Wu, F. Zhong, J. Yu, Z. Zhang, and H. Wang. Trackvla: Embodied visual tracking in the wild. InConference on Robot Learning, pages 4139–4164. PMLR, 2025
2025
-
[4]
Watkins-Valls, P
D. Watkins-Valls, P. K. Allen, H. Maia, M. Seshadri, J. Sanabria, N. Waytowich, and J. Varley. Mobile manipulation leveraging multiple views. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4585–4592. IEEE, 2022
2022
-
[5]
Kalashnikov, A
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on robot learning, pages 651–673. PMLR, 2018
2018
-
[6]
Mahler, M
J. Mahler, M. Matl, V . Satish, M. Danielczuk, B. DeRose, S. McKinley, and K. Goldberg. Learning ambidextrous robot grasping policies.Science robotics, 4(26):eaau4984, 2019
2019
-
[7]
W. Li, S. Zou, Z. Yu, Z. Zhou, W. Li, C. Zhu, R. Hu, and K. Xu. Llm-enhanced scene graph learning for household rearrangement.ACM Transactions on Graphics, 45(3):1–18, 2026
2026
-
[8]
F. Sun, Y . Chen, Y . Wu, L. Li, and X. Ren. Motion planning and cooperative manipulation for mobile robots with dual arms.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(6):1345–1356, 2022
2022
-
[9]
H. Chen, X. Zang, Y . Liu, X. Zhang, and J. Zhao. A hierarchical motion planning method for mobile manipulator.Sensors, 23(15):6952, 2023
2023
-
[10]
Patki, E
S. Patki, E. Fahnestock, T. M. Howard, and M. R. Walter. Language-guided semantic map- ping and mobile manipulation in partially observable environments. InConference on robot learning, pages 1201–1210. PMLR, 2020
2020
-
[11]
Burgess-Limerick, J
B. Burgess-Limerick, J. Haviland, C. Lehnert, and P. Corke. Reactive base control for on-the- move mobile manipulation in dynamic environments.IEEE Robotics and Automation Letters, 9(3):2048–2055, 2024
2048
-
[12]
C. Wu, R. Wang, M. Song, F. Gao, J. Mei, and B. Zhou. Real-time whole-body motion planning for mobile manipulators using environment-adaptive search and spatial-temporal optimization. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 1369–
-
[13]
Yokoyama, A
N. Yokoyama, A. Clegg, J. Truong, E. Undersander, T.-Y . Yang, S. Arnaud, S. Ha, D. Batra, and A. Rai. Asc: Adaptive skill coordination for robotic mobile manipulation.IEEE Robotics and Automation Letters, 9(1):779–786, 2023
2023
-
[14]
Jauhri, J
S. Jauhri, J. Peters, and G. Chalvatzaki. Robot learning of mobile manipulation with reacha- bility behavior priors.IEEE Robotics and Automation Letters, 7(3):8399–8406, 2022
2022
-
[15]
C. Wang, Q. Zhang, Q. Tian, S. Li, X. Wang, D. Lane, Y . Petillot, and S. Wang. Learning mobile manipulation through deep reinforcement learning.Sensors, 20(3):939, 2020
2020
-
[16]
C. Sun, J. Orbik, C. M. Devin, B. H. Yang, A. Gupta, G. Berseth, and S. Levine. Fully autonomous real-world reinforcement learning with applications to mobile manipulation. In Conference on Robot Learning, pages 308–319. PMLR, 2022. 9
2022
-
[17]
Zhang, N
J. Zhang, N. Gireesh, J. Wang, X. Fang, C. Xu, W. Chen, L. Dai, and H. Wang. Gamma: Graspability-aware mobile manipulation policy learning based on online grasping pose fusion. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 1399–
-
[18]
J. Wang, J. Rajabov, C. Xu, Y . Zheng, and H. Wang. Quadwbg: Generalizable quadrupedal whole-body grasping. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11675–11682. IEEE, 2025
2025
-
[19]
M ¨ulling, J
K. M ¨ulling, J. Kober, O. Kroemer, and J. Peters. Learning to select and generalize striking movements in robot table tennis.International Journal of Robotics Research, 32(3):263–279, 2013
2013
-
[20]
S. Kim, A. Shukla, and A. Billard. Catching objects in flight.IEEE Transactions on Robotics, 30(5):1049–1065, 2014
2014
-
[21]
D. B. D’Ambrosio, S. Abeyruwan, L. Graesser, A. Iscen, H. Ben Amor, A. Bewley, B. J. Reed, K. Reymann, L. Takayama, Y . Tassa, et al. Achieving human level competitive robot table tennis.arXiv preprint arXiv:2408.03906, 2024
arXiv 2024
-
[22]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[23]
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[24]
Calli, A
B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar. Benchmarking in manipulation research: Using the Yale-CMU-Berkeley object and model set.IEEE Robotics & Automation Magazine, 22(3):36–52, 2015
2015
-
[25]
Y .-W. Chao, W. Yang, Y . Xiang, P. Molchanov, A. Handa, J. Tremblay, Y . S. Narang, K. Van Wyk, U. Iqbal, S. Birchfield, J. Kautz, and D. Fox. DexYCB: A benchmark for captur- ing hand grasping of objects. InIEEE Conf. Comput. Vis. Pattern Recog., 2021
2021
-
[26]
M. V . Minniti, F. Farshidian, R. Grandia, and M. Hutter. Whole-body mpc for a dynamically stable mobile manipulator.IEEE Robotics and Automation Letters, 4(4):3687–3694, 2019
2019
-
[27]
Sleiman, F
J.-P. Sleiman, F. Farshidian, M. V . Minniti, and M. Hutter. A unified mpc framework for whole-body dynamic locomotion and manipulation.IEEE Robotics and Automation Letters, 6 (3):4688–4695, 2021
2021
-
[28]
Z. Jiao, Z. Zhang, X. Jiang, D. Han, S.-C. Zhu, Y . Zhu, and H. Liu. Consolidating kinematic models to promote coordinated mobile manipulations. In2021 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), pages 979–985. IEEE, 2021
2021
-
[29]
J. Hu, P. Stone, and R. Mart´ın-Mart´ın. Causal policy gradient for whole-body mobile manipu- lation.arXiv preprint arXiv:2305.04866, 2023
arXiv 2023
-
[30]
Z. Fu, X. Cheng, and D. Pathak. Deep whole-body control: learning a unified policy for manipulation and locomotion. InConference on Robot Learning, pages 138–149. PMLR, 2023
2023
-
[31]
M. Liu, Z. Chen, X. Cheng, Y . Ji, R.-Z. Qiu, R. Yang, and X. Wang. Visual whole-body control for legged loco-manipulation. InConf. Robot Learn., 2024
2024
-
[32]
M ¨ulling, J
K. M ¨ulling, J. Kober, O. Kroemer, and J. Peters. Learning to select and generalize striking movements in robot table tennis.The International Journal of Robotics Research, 32(3):263– 279, 2013. 10
2013
-
[33]
D. B. DAmbrosio, S. Abeyruwan, L. Graesser, A. Iscen, H. B. Amor, A. Bewley, B. J. Reed, K. Reymann, L. Takayama, Y . Tassa, et al. Achieving human level competitive robot table tennis. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 74–82. IEEE, 2025
2025
-
[34]
Y .-B. Jia, M. Gardner, and X. Mu. Batting an in-flight object to the target.International Journal of Robotics Research, 38(4):451–485, 2019
2019
-
[35]
Akinola, J
I. Akinola, J. Xu, S. Song, and P. K. Allen. Dynamic grasping with reachability and motion awareness. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9422–9429. IEEE, 2021
2021
-
[36]
W. Yang, C. Paxton, A. Mousavian, Y .-W. Chao, M. Cakmak, and D. Fox. Reactive human-to- robot handovers of arbitrary objects. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 3118–3124. IEEE, 2021
2021
-
[37]
Zhang, H.-S
G. Zhang, H.-S. Fang, H. Fang, and C. Lu. Flexible handover with real-time robust dynamic grasp trajectory generation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3192–3199. IEEE, 2023
2023
-
[38]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[39]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
- [40]
-
[41]
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
Pith/arXiv arXiv 2022
- [42]
-
[43]
S. H. Høeg, Y . Du, and O. Egeland. Streaming diffusion policy: Fast policy synthesis with variable noise diffusion models.arXiv preprint arXiv:2406.04806, 2024
arXiv 2024
-
[44]
H.-S. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), pages 11444–11453, 2020
2020
-
[45]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Pith/arXiv arXiv 2010
-
[46]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao. Depth anything v2. Advances in Neural Information Processing Systems, 37:21875–21911, 2024
2024
-
[47]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[48]
Accessed: 2026-05-28
Realman rm65-6f.https://www.realman-robotics.com/en/products/rm65.html. Accessed: 2026-05-28. 11
2026
-
[49]
D. He, W. Xu, N. Chen, F. Kong, C. Yuan, and F. Zhang. Point-lio: robust high-bandwidth light detection and ranging inertial odometry.Advanced Intelligent Systems, 5(7):2200459, 2023
2023
-
[50]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos. InInternational Confer- ence on Learning Representations, volume 2025, pages 28085–28128, 2025. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.