Beyond Visual Forensics: Auditing Multimodal Robustness for Synthetic Medical Image Detection
Pith reviewed 2026-06-25 21:05 UTC · model grok-4.3
The pith
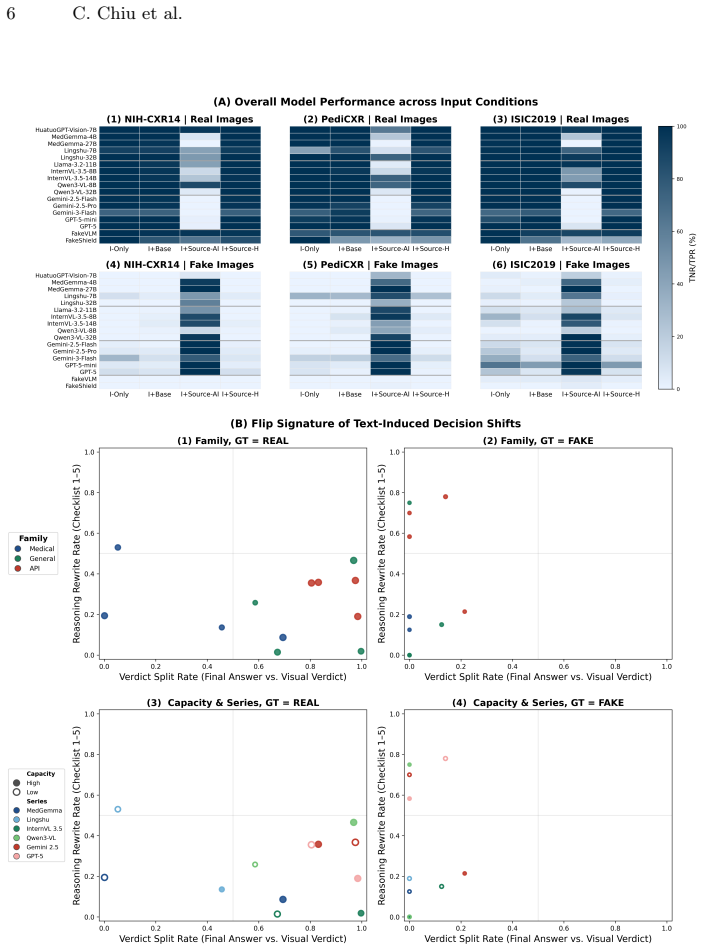
Vision-language models change their judgment on whether a medical image is synthetic when only the accompanying text record is altered.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When given both modalities, VLMs may overweight record context in authenticity judgments, such that the same image receives different predictions solely due to changes in its accompanying text.
What carries the argument
A paired benchmark that holds the image fixed while swapping controlled metadata variants to audit multimodal robustness at the image-record interface.
If this is right
- The same image can receive inconsistent synthetic or authentic labels solely from metadata swaps in joint inputs.
- Both open-weight and frontier API VLMs exhibit shifts in predictions driven by text context alone.
- The benchmark supplies a standardized method to test and improve robustness beyond image-only evaluation.
- Real-world deployment of VLMs for medical image verification must account for record context sensitivity.
Where Pith is reading between the lines
- The same text-driven inconsistency could appear in other multimodal medical tasks such as report generation or diagnosis assistance.
- Model developers might apply the benchmark during training to enforce more balanced weighting between image and text signals.
- Clinical deployment guidelines could incorporate this type of paired audit before approving multimodal systems for authenticity checks.
Load-bearing premise
The controlled metadata variants used in the paired benchmark sufficiently represent the kinds of text variations that occur in actual clinical workflows and record systems.
What would settle it
Running the paired benchmark and finding that VLM authenticity predictions stay identical across all metadata variants for the same images would show the claimed vulnerability does not exist.
Figures

read the original abstract
With the rapid adoption of generative AI, synthetic medical images pose growing risks, including diagnostic deception and insurance fraud. Although prior work has explored vision-language model (VLM)-based synthetic image detection, these evaluations typically consider images in isolation. In clinical practice, however, images are interpreted alongside structured records and metadata, and VLMs are increasingly deployed under joint image-record inputs. We uncover a previously underexamined multimodal vulnerability: when given both modalities, VLMs may overweight record context in authenticity judgments, such that the same image receives different predictions solely due to changes in its accompanying text. This raises concerns about robustness in real-world deployment. To systematically characterize this effect, we reformulate synthetic medical image detection as an audit of multimodal robustness at the image-record interface and introduce a paired benchmark that holds the image fixed while swapping controlled metadata variants. Across multiple imaging modalities, we evaluate diverse open-weight and frontier API VLMs and quantify how metadata alone shifts authenticity predictions. Our benchmark provides a standardized tool for assessing and improving multimodal robustness beyond image-only settings. The code is available at https://github.com/chiuhaohao/Beyond-Visual-Forensics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs for synthetic medical image detection overweight accompanying textual record context, causing the same image to receive inconsistent authenticity predictions under different metadata. It reformulates the task as a multimodal robustness audit at the image-record interface and introduces a paired benchmark that holds images fixed while swapping controlled metadata variants. The work evaluates multiple open-weight and frontier VLMs across imaging modalities, quantifies prediction shifts attributable to metadata, and releases code at the provided GitHub link.
Significance. If the benchmark results demonstrate reliable shifts under representative conditions, the work identifies an underexamined vulnerability in multimodal medical AI that could affect deployment where images are interpreted with records. The public release of code is a clear strength that supports reproducibility and extension by others.
major comments (1)
- [§4 and §5] §4 (Benchmark Construction) and §5 (Experiments): The central deployment-robustness claim requires that the controlled metadata variants reflect typical clinical record distributions (e.g., patient IDs, acquisition parameters, notes). No quantitative comparison, statistical mapping, or sampling from real EHR corpora is provided to establish this representativeness; without it the observed shifts demonstrate sensitivity to the chosen variants but do not yet substantiate the real-world robustness failure asserted in the abstract and conclusion.
minor comments (2)
- [Abstract and §3] Abstract and §3: The abstract states that results 'quantify how metadata alone shifts authenticity predictions' yet supplies no sample sizes, effect magnitudes, or statistical tests; the reader must reach the experimental section for these details.
- [Figure captions and §5] Figure captions and §5: Some figure captions do not explicitly state the number of image-record pairs per condition or the exact prompt templates used for the VLMs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the single major comment point-by-point below and outline planned revisions.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Benchmark Construction) and §5 (Experiments): The central deployment-robustness claim requires that the controlled metadata variants reflect typical clinical record distributions (e.g., patient IDs, acquisition parameters, notes). No quantitative comparison, statistical mapping, or sampling from real EHR corpora is provided to establish this representativeness; without it the observed shifts demonstrate sensitivity to the chosen variants but do not yet substantiate the real-world robustness failure asserted in the abstract and conclusion.
Authors: We agree that establishing representativeness via direct comparison to EHR corpora would strengthen the deployment claim. Our benchmark in §4 was constructed with controlled variants chosen to be clinically plausible (e.g., realistic patient ID formats, acquisition parameters such as modality-specific scanner settings or timestamps, and note-style text) precisely to isolate metadata influence while holding images fixed. The consistent prediction shifts across VLMs and modalities demonstrate that authenticity judgments are sensitive to metadata changes of the kind that occur in practice. However, we did not perform quantitative sampling or statistical mapping from real EHR distributions, so the results show sensitivity to these variants rather than a full ecological validation. We will revise §4 to explicitly state the rationale for variant selection, add a limitations paragraph acknowledging the lack of direct EHR comparison, and adjust the abstract and conclusion to frame the benchmark as a controlled audit that identifies a vulnerability warranting further real-world study rather than claiming exhaustive real-world failure. revision: partial
Circularity Check
No circularity: empirical benchmark study with no derivations or fitted parameters
full rationale
The paper introduces a paired benchmark for auditing VLM robustness under image-record inputs but contains no equations, derivations, parameter fitting, or self-citation chains that reduce claims to inputs by construction. The central observation—that metadata swaps can shift authenticity predictions—is presented as an empirical finding from controlled experiments rather than a derived result. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as a benchmark proposal with external code release.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scientific Reports (2025)
Ali, A., Basha, H.A., Thanuja, K., Puneet, Gupta, S.K., Kim, S.: Enhancing tu- mor deepfake detection in mri scans using adversarial feature fusion ensembles. Scientific Reports (2025)
2025
-
[2]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2406.19280 (2024)
Chen, J., Gui, C., Ouyang, R., Gao, A., Chen, S., Chen, G.H., Wang, X., Zhang, R., Cai, Z., Ji, K., et al.: Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale. arXiv preprint arXiv:2406.19280 (2024)
arXiv 2024
-
[4]
arXiv preprint arXiv:2511.00801 (2025)
Chen, Z., Feng, M.: Med-banana-50k: A cross-modality large-scale dataset for text- guided medical image editing. arXiv preprint arXiv:2511.00801 (2025)
Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2601.01897 (2026)
Cheng, L., Lu, J., Chan, Y.X., Nguyen, Q.K., Bi, J., Ho, S.: A hybrid architecture for multi-stage claim document understanding: Combining vision-language models and machine learning for real-time processing. arXiv preprint arXiv:2601.01897 (2026)
arXiv 2026
-
[6]
arXiv preprint arXiv:2507.06261 (2025)
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
Pith/arXiv arXiv 2025
-
[7]
Deng, A., Cao, T., Chen, Z., Hooi, B.: Words or vision: Do vision-language models have blind faith in text? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3867–3876 (2025)
2025
-
[8]
ACM Transactions on Intelligent Systems and Technology16(6), 1–26 (2025)
Grabovski, F.M., Yasur, L., Amit, G., Mirsky, Y.: Back-in-time diffusion: Unsu- pervised detection of medical deepfakes. ACM Transactions on Intelligent Systems and Technology16(6), 1–26 (2025)
2025
-
[9]
arXiv preprint arXiv:2407.21783 (2024)
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[10]
Frontiers in artificial intelligence7, 1430984 (2024)
Hartsock, I., Rasool, G.: Vision-language models for medical report generation and visual question answering: A review. Frontiers in artificial intelligence7, 1430984 (2024)
2024
-
[11]
The Lancet Digital Health (2025) 10 C
Khosravi, B., Purkayastha, S., Erickson, B.J., Trivedi, H.M., Gichoya, J.W.: Ex- ploring the potential of generative artificial intelligence in medical image synthesis: opportunities, challenges, and future directions. The Lancet Digital Health (2025) 10 C. Chiu et al
2025
-
[12]
IEEE Journal of Biomedical and Health Informatics (2025)
Kondylakis, H., Osuala, R., Puig-Bosch, X., Lazrak, N., Diaz, O., Kushibar, K., Chouvarda, I., Charalambous, S., Starmans, M.P., Colantonio, S., et al.: A review of methods for trustworthy ai in medical imaging: The future-ai guidelines. IEEE Journal of Biomedical and Health Informatics (2025)
2025
-
[13]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Konz, N., Chen, Y., Dong, H., Mazurowski, M.A.: Anatomically-controllable med- ical image generation with segmentation-guided diffusion models. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 88–98. Springer (2024)
2024
-
[14]
Li,S.,Xing,Z.,Wang,H.,Hao,P.,Li,X.,Liu,Z.,Zhu,L.:Towardmedicaldeepfake detection:Acomprehensivedatasetandnovelmethod.In:InternationalConference on Medical Image Computing and Computer-Assisted Intervention. pp. 626–637. Springer (2025)
2025
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Nath, V., Li, W., Yang, D., Myronenko, A., Zheng, M., Lu, Y., Liu, Z., Yin, H., Law, Y.M., Tang, Y., et al.: Vila-m3: Enhancing vision-language models with medical expert knowledge. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14788–14798 (2025)
2025
-
[16]
In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention
Pan, J., Liu, C., Wu, J., Liu, F., Zhu, J., Li, H.B., Chen, C., Ouyang, C., Rueck- ert, D.: Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention. pp. 337–347. Springer (2025)
2025
-
[17]
Implementation Science 19(1), 27 (2024)
Reddy, S.: Generative ai in healthcare: an implementation science informed trans- lational path on application, integration and governance. Implementation Science 19(1), 27 (2024)
2024
-
[18]
Biomedical Engi- neering Letters15(5), 809–830 (2025)
Ryu, J.S., Kang, H., Chu, Y., Yang, S.: Vision-language foundation models for medical imaging: a review of current practices and innovations. Biomedical Engi- neering Letters15(5), 809–830 (2025)
2025
-
[19]
arXiv preprint arXiv:2507.05201 (2025)
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
Pith/arXiv arXiv 2025
-
[20]
arXiv preprint arXiv:2601.03267 (2025)
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
Pith/arXiv arXiv 2025
-
[21]
JAMA network open8(5), e258614 (2025)
Stults, C.D., Deng, S., Martinez, M.C., Wilcox, J., Szwerinski, N., Chen, K.H., Driscoll, S., Washburn, J., Jones, V.G.: Evaluation of an ambient artificial intel- ligence documentation platform for clinicians. JAMA network open8(5), e258614 (2025)
2025
-
[22]
JAMA Net- work Open7(4), e246565 (2024)
Tai-Seale, M., Baxter, S.L., Vaida, F., Walker, A., Sitapati, A.M., Osborne, C., Diaz, J., Desai, N., Webb, S., Polston, G., et al.: Ai-generated draft replies inte- grated into health records and physicians’ electronic communication. JAMA Net- work Open7(4), e246565 (2024)
2024
-
[23]
Scientific data5(1), 180161 (2018)
Tschandl, P., Rosendahl, C., Kittler, H.: The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data5(1), 180161 (2018)
2018
-
[24]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
Pith/arXiv arXiv 2025
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.M.: Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classi- fication and localization of common thorax diseases. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2097–2106 (2017) Beyond Visual Forensics 11
2097
-
[26]
arXiv preprint arXiv:2503.14905 (2025)
Wen, S., Ye, J., Feng, P., Kang, H., Wen, Z., Chen, Y., Wu, J., Wu, W., He, C., Li, W.: Spot the fake: Large multimodal model-based synthetic image detection with artifact explanation. arXiv preprint arXiv:2503.14905 (2025)
arXiv 2025
-
[27]
arXiv preprint arXiv:2506.07044 (2025)
Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu,C.,Li,Z.,etal.:Lingshu:Ageneralistfoundationmodelforunifiedmultimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
Pith/arXiv arXiv 2025
-
[28]
arXiv preprint arXiv:2410.02761 (2024)
Xu, Z., Zhang, X., Li, R., Tang, Z., Huang, Q., Zhang, J.: Fakeshield: Explainable image forgery detection and localization via multi-modal large language models. arXiv preprint arXiv:2410.02761 (2024)
arXiv 2024
-
[29]
arXiv preprint arXiv:2601.19202 (2026)
Zhang, C., Ding, W., Liu, J., Wu, M., Wu, Q., Mooney, R.: Do images speak louder than words? investigating the effect of textual misinformation in vlms. arXiv preprint arXiv:2601.19202 (2026)
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.