BiPACE: Bisimulation-Guided Policy Optimization with Action Counterfactual Estimation for LLM Agents
Pith reviewed 2026-06-25 21:02 UTC · model grok-4.3
The pith
BiPACE fixes credit mismatch in group RL for LLM agents by clustering steps on hidden-state bisimulation and recentering with action counterfactual baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
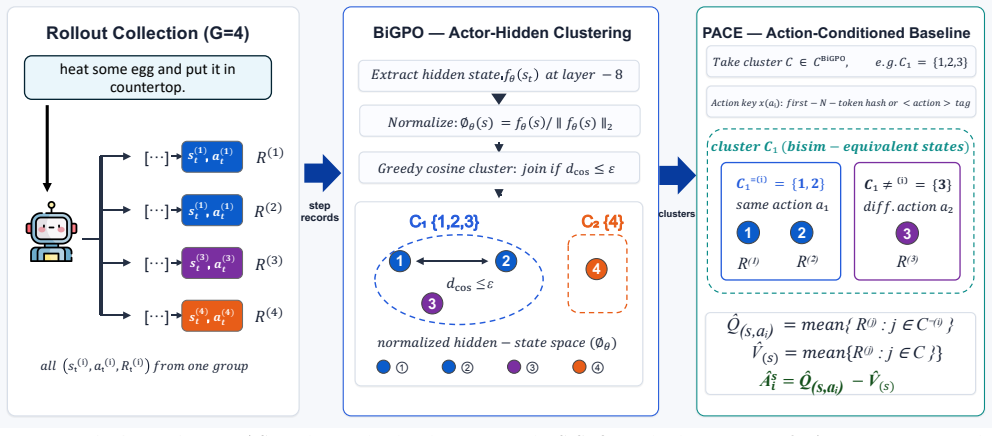
BiPACE is a drop-in advantage estimator that clusters steps by cosine distance in the actor's hidden-state geometry, an empirical policy-induced proxy for bisimulation that lowers singleton rates, then recenters returns within each behavioral cluster using action-conditioned peer baselines to estimate local Q(s,a)-V(s) nonparametrically, producing higher success rates than GiGPO on ALFWorld, WebShop, and TextCraft at two model scales.
What carries the argument
BiGPO clusters steps by cosine distance in the actor's own hidden-state geometry as an empirical policy-induced proxy for bisimulation; PACE recenters returns within each behavioral cluster using action-conditioned peer baselines to estimate local Q(s,a)-V(s).
If this is right
- On ALFWorld with Qwen2.5-7B, BiPACE_Q raises overall validation success from GiGPO's 90.8 to 97.1±0.9 and crosses the 95 percent threshold on every seed.
- On Qwen2.5-1.5B the same method reaches 93.5±1.2 versus GiGPO's 86.7.
- BiPACE improves over GRPO and GiGPO on WebShop and TextCraft at both model scales.
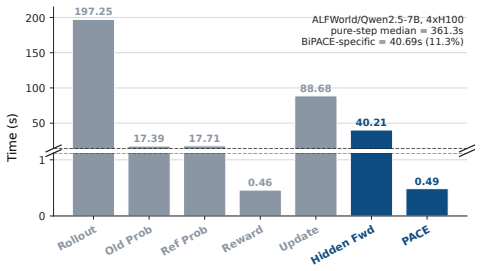
- The measured BiPACE-specific overhead is 11.3 percent of a single training-step wall time.
- The estimator's comparison unit shifts from surface identity to approximate behavioral equivalence plus action-side counterfactuals.
Where Pith is reading between the lines
- If hidden-state geometry reliably tracks behavioral equivalence, the same clustering could be tested in other partially observable RL domains where explicit state hashing is impractical.
- The nonparametric Q-V estimates inside clusters suggest that future work could combine BiPACE with learned critics without changing the rollout budget.
- Gains on both 7B and 1.5B models imply the method may improve data efficiency enough to make smaller base models competitive on long-horizon agent tasks.
- The 11.3 percent overhead figure provides a concrete budget for checking whether the clustering step can be approximated more cheaply while preserving the success-rate lift.
Load-bearing premise
Cosine distance between steps in the actor's own hidden-state geometry forms a reliable empirical proxy for bisimulation equivalence that produces behavioral clusters useful for credit assignment.
What would settle it
Re-running the ALFWorld/Qwen2.5-7B experiments and finding that BiPACE does not raise overall validation success above GiGPO's 90.8 or that the clusters fail to reduce the singleton rate left by observation hashing would falsify the central claim.
Figures

read the original abstract
Stepwise group-based RL is an attractive way to train long-horizon LLM agents without a learned critic: it reuses multiple sampled rollouts to estimate local advantages. Its weakness is less visible but more fundamental: every group-relative estimator assumes that the steps it compares are equivalent for credit assignment. We show that current agentic variants violate this assumption through a state-action credit mismatch. The observation-hash partition is overly fine on the state side, creating singleton groups with zero step-level signal, while a single within-group mean is too coarse on the action side, mixing state-value estimation with action-specific credit. We introduce BiPACE (Bisimulation-Guided Policy Optimization with Action Counterfactual Estimation), a drop-in advantage estimator that fixes both sides without adding a critic, auxiliary loss, or extra rollouts. BiGPO clusters steps by cosine distance in the actor's own hidden-state geometry, an empirical policy-induced proxy for bisimulation that substantially lowers the singleton rate left by observation hashing. PACE then recenters returns within each behavioral cluster using action-conditioned peer baselines; its Q-style instance estimates a local Q(s,a)-V(s) nonparametrically. On ALFWorld/Qwen2.5-7B, BiPACE_Q raises overall validation success from GiGPO's 90.8 to $97.1\pm0.9$ over three seeds, and crosses the 95% threshold on every seed, which GiGPO never does within the same budget. On Qwen2.5-1.5B it reaches $93.5\pm1.2$ versus GiGPO's 86.7, and on WebShop and TextCraft it improves over GRPO and GiGPO at both model scales. The measured BiPACE-specific overhead is 11.3% of a single training-step wall time. Yet it changes the estimator's comparison unit from surface identity to approximate behavioral equivalence plus action-side counterfactuals. The code is available at https://github.com/TianxiangZhao/BiPACE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BiPACE, a drop-in advantage estimator for stepwise group-based RL in LLM agents. It replaces observation-hash partitioning with behavioral clusters formed by cosine distance on the actor's hidden states (treated as an empirical bisimulation proxy) and applies action-conditioned peer baselines to compute nonparametric Q(s,a)-V(s) estimates. On ALFWorld with Qwen2.5-7B, BiPACE_Q reports validation success of 97.1±0.9 versus GiGPO's 90.8 over three seeds; similar gains are claimed on Qwen2.5-1.5B, WebShop, and TextCraft. The method adds no critic, auxiliary loss, or extra rollouts, with measured overhead of 11.3% and public code release.
Significance. If the hidden-state cosine-distance clusters reliably approximate policy-induced behavioral equivalence, the approach would provide a practical, critic-free route to improved credit assignment for long-horizon LLM agents. The public code release supports direct reproducibility of the reported benchmark gains.
major comments (2)
- [§3.2] §3.2 (BiGPO clustering): the central claim that cosine distance on actor hidden states forms a reliable empirical proxy for bisimulation equivalence (enabling unbiased within-cluster advantage estimates) is load-bearing for the performance lift, yet the manuscript provides neither a derivation showing the proxy satisfies bisimulation metric properties nor an auxiliary experiment verifying that clusters group steps with similar future return distributions.
- [§5] §5 (ALFWorld and WebShop results): the reported success rates (e.g., 97.1±0.9 over three seeds crossing 95% on every seed) are presented without the full experimental protocol, data-exclusion rules, or statistical tests, preventing verification that the comparison unit change from surface identity to behavioral clusters is responsible for the observed gains rather than post-hoc choices.
minor comments (1)
- [§2] The distinction between BiPACE_Q and the baseline variants could be introduced with a short table in §2 to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (BiGPO clustering): the central claim that cosine distance on actor hidden states forms a reliable empirical proxy for bisimulation equivalence (enabling unbiased within-cluster advantage estimates) is load-bearing for the performance lift, yet the manuscript provides neither a derivation showing the proxy satisfies bisimulation metric properties nor an auxiliary experiment verifying that clusters group steps with similar future return distributions.
Authors: We agree that a formal derivation establishing that cosine distance on actor hidden states satisfies bisimulation metric properties is absent from the manuscript; the approach is presented as an empirical proxy motivated by the observation that transformer hidden states encode policy-relevant behavioral features. No such derivation is provided because exact bisimulation requires knowledge of the full transition and reward structure, which is unavailable in the LLM-agent setting. We will add an auxiliary analysis in the revision (new subsection or appendix) that reports within-cluster versus between-cluster variance of Monte-Carlo returns on held-out rollouts to empirically support that clusters group steps with similar future return distributions. This addresses the referee’s concern without altering the core method. revision: yes
-
Referee: [§5] §5 (ALFWorld and WebShop results): the reported success rates (e.g., 97.1±0.9 over three seeds crossing 95% on every seed) are presented without the full experimental protocol, data-exclusion rules, or statistical tests, preventing verification that the comparison unit change from surface identity to behavioral clusters is responsible for the observed gains rather than post-hoc choices.
Authors: The manuscript reports means and standard deviations over three independent seeds and releases the full training and evaluation code. However, we acknowledge that the main text and appendix do not explicitly list data-exclusion criteria (none were applied beyond standard timeout and format filters) or include formal statistical tests comparing BiPACE against baselines. In the revision we will expand §5 and the experimental appendix to document the complete protocol, any filtering rules, and add paired t-test p-values (or bootstrap confidence intervals) across seeds to quantify the significance of the observed gains. This will allow readers to verify that the behavioral clustering and action-counterfactual components drive the improvements. revision: yes
Circularity Check
Derivation self-contained against external benchmarks; no circular reductions
full rationale
The paper defines BiPACE as a drop-in advantage estimator that forms behavioral clusters via cosine distance on the actor LLM's hidden states (treated as an empirical bisimulation proxy) and then applies within-cluster action-conditioned peer baselines to estimate local Q(s,a)-V(s) nonparametrically. All reported performance numbers are external benchmark success rates (e.g., ALFWorld validation success 97.1 vs. 90.8) measured on held-out environments, not quantities defined in terms of fitted parameters, self-referential predictions, or internal fits. No self-citations appear as load-bearing premises for the core claims, no uniqueness theorems are imported from prior author work, and no ansatz or known result is renamed or smuggled via citation. The method therefore remains self-contained against independent external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cosine distance in the actor's hidden-state geometry serves as an empirical proxy for bisimulation equivalence
Reference graph
Works this paper leans on
-
[1]
3spo: State-score- supervised policy optimization for llm agents.arXiv preprint arXiv:2606.09961,
Yu Han, Kailing Li, Yang Jiao, Yulin Dai, Yuqian Fu, Linhai Zhuo, and Tianwen Qian. 3spo: State-score- supervised policy optimization for llm agents.arXiv preprint arXiv:2606.09961,
-
[2]
Shuo He, Lang Feng, Qi Wei, Xin Cheng, Lei Feng, and Bo An. Hierarchy-of-groups policy optimiza- tion for long-horizon agentic tasks.arXiv preprint arXiv:2602.22817,
-
[3]
Salt: Step-level advantage assignment for long- horizon agents via trajectory graph
Jiazheng Li, Yawei Wang, Qiaojing Yan, Yijun Tian, Zhichao Xu, Huan Song, Panpan Xu, and Lin Lee Cheong. Salt: Step-level advantage assignment for long- horizon agents via trajectory graph. InFindings of the Association for Computational Linguistics: EACL 2026, pages 4709–4725, 2026a. Zhongyi Li, Wan Tian, Yikun Ban, Jinju Chen, Huiming Zhang, Yang Liu, a...
Pith/arXiv arXiv 2026
-
[4]
Chengjun Pan, Shichun Liu, Jiahang Lin, Dingwei Zhu, Jiazheng Zhang, Shihan Dou, Songyang Gao, Zhen- hua Han, Binghai Wang, Rui Zheng, et al. EVPO: Explained variance policy optimization for adaptive critic utilization in LLM post-training.arXiv preprint arXiv:2604.19485,
-
[5]
ADaPT: As-needed decomposition and planning with language models
Archiki Prasad, Alexander Koller, Mareike Hartmann, Peter Clark, Ashish Sabharwal, Mohit Bansal, and Tushar Khot. ADaPT: As-needed decomposition and planning with language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 4226–4252,
2024
-
[6]
Proximal policy opti- mization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy opti- mization algorithms.arXiv preprint arXiv:1707.06347,
-
[7]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[8]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cˆ ot´ e, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768,
Pith/arXiv arXiv 2010
-
[9]
Hindsight credit assign- ment for long-horizon LLM agents.arXiv preprint arXiv:2603.08754,
Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan- Zhe Guo, and Yu-Feng Li. Hindsight credit assign- ment for long-horizon LLM agents.arXiv preprint arXiv:2603.08754,
-
[10]
Text2grad: Reinforcement learn- ing from natural language feedback.arXiv preprint arXiv:2505.22338,
Hanyang Wang, Lu Wang, Chaoyun Zhang, Tianjun Mao, Si Qin, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. Text2grad: Reinforcement learn- ing from natural language feedback.arXiv preprint arXiv:2505.22338,
-
[11]
Quan Wei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, Wei Deng, Anderson Schneider, Yuriy Nevmyvaka, Yang Katie Zhao, Alfredo Garcia, et al. Re- inforcing multi-turn reasoning in LLM agents via turn- level reward design.arXiv preprint arXiv:2505.11821,
-
[12]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115,
-
[13]
Learning invariant representa- tions for reinforcement learning without reconstruction
Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representa- tions for reinforcement learning without reconstruction. arXiv preprint arXiv:2006.10742,
arXiv 2006
-
[14]
A. Extended Related Work Group-relative RL for LLM agents.GRPO [Shao et al., 2024] drops the critic by baselining against in- group sampled returns.GiGPO[Feng et al., 2025] adds a step-level term keyed on exact observation hashes, and HGPO[He et al., 2026] augments that key with history length. DAPO [Yu et al., 2025] and related work tune optimization or ...
2024
-
[15]
For each promptp we sample G trajectories τ (1),
in a step-independentinput formulation: each step’s prompt is constructed from the current observation and a (possibly summarized) history, enabling horizons of 50+ steps. For each promptp we sample G trajectories τ (1), . . . , τ(G) of (possibly varying) lengths T (g). In the terminal-only reward setting we focus on, the trajectory return is R(τ) = rT−1 ...
2003
-
[16]
see Table I.1
runs per prompt-group in O(NpKp) time ( Np step records, Kp clusters), a handful of D- dimensional dot products per record dominated in prac- tice by the actor forward pass (measured grouping and advantage-estimation cost: 0 .49s, 0 .14% of a training step; Sec. 4.6). When Actor-Hidden features are used, the worker hook runs a vanilla actor forward with h...
2026
-
[17]
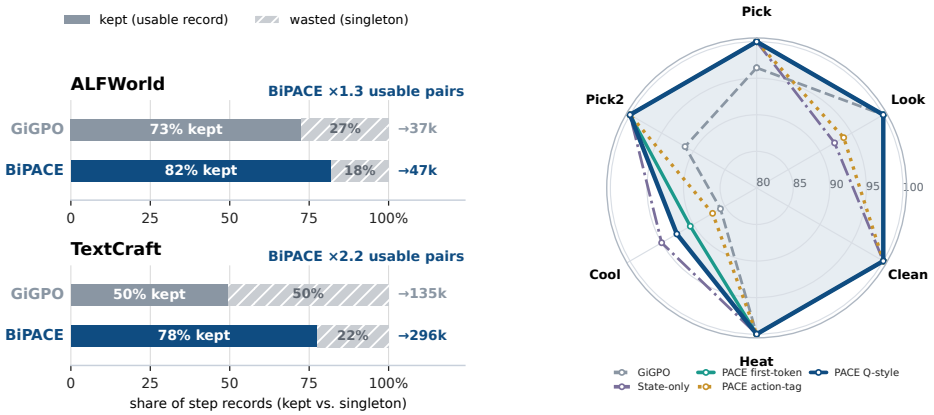
OnALFWorld,BiPACElowers the single- ton cluster fraction by 9 .3pp and increases mean group size by 1.6×
The diagnostic asks specifically whether the actor-hidden policy-state clustering creates larger non-singleton reuse pools than exact observation hashing under the same rollout bud- get (a question distinct from historical-context oracle grouping). OnALFWorld,BiPACElowers the single- ton cluster fraction by 9 .3pp and increases mean group size by 1.6×. On...
2018
-
[18]
Val/success-rate (binary aggregate, |V|=128) across three seeds: 93 .8%, 92 .2%, 94 .5%; mean ±std = 93.5±1.2% (reported as 93.5 in theAllcolumn of Table 2)
Q-style on Qwen2.5-1.5B (ALFWorld,ε=0.05, layer −12).The smaller backbone converges more slowly than 7B, so val @max is taken over the full 200-step training window. Val/success-rate (binary aggregate, |V|=128) across three seeds: 93 .8%, 92 .2%, 94 .5%; mean ±std = 93.5±1.2% (reported as 93.5 in theAllcolumn of Table 2). Versus the citedGiGPOresult of 86...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.