BitNet Text Embeddings
Pith reviewed 2026-06-25 20:46 UTC · model grok-4.3
The pith
BITEMBED converts LLM backbones to ternary weights and quantized activations while recovering embedding quality through distillation and contrastive training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
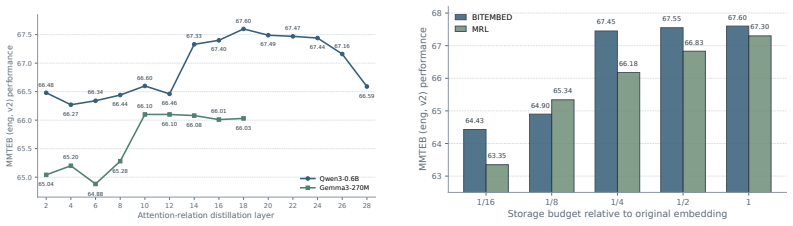
BITEMBED converts pretrained LLM backbones into BitNet-style embedding encoders with ternary weights, quantized activations, and lightweight normalization refinement. The converted model is adapted to representation learning through continual contrastive pre-training, followed by supervised contrastive fine-tuning with both similarity-distribution distillation and attention-relation distillation from a full-precision teacher. Beyond quantizing the backbone, BITEMBED further trains output embeddings to support multiple storage precisions meeting different storage needs in various scenarios.
What carries the argument
BITEMBED framework that converts LLM backbones to BitNet-style ternary weights and quantized activations then recovers quality via contrastive pre-training and dual distillation from a full-precision teacher.
If this is right
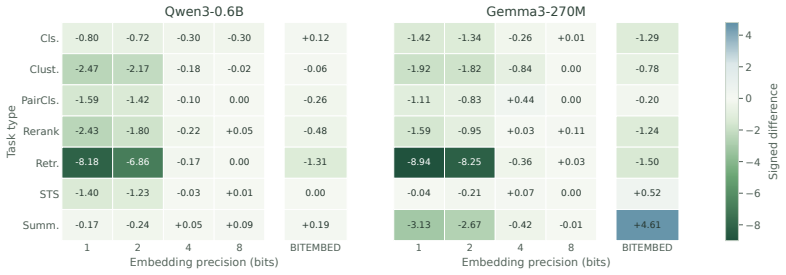
- BITEMBED achieves largely comparable performance to full-precision teacher embedders on MMTEB (eng, v2) with Qwen3-0.6B and Gemma3-270M.
- The framework flexibly obtains text embeddings of various precisions to trade off performance against storage cost.
- Quantizing the backbone to ternary weights and quantized activations reduces encoding inference costs while the adaptation steps preserve semantic quality.
- Lightweight normalization refinement supports the backbone conversion without additional heavy components.
Where Pith is reading between the lines
- The same quantization-plus-distillation pattern could extend to other dense retrieval or reranking models beyond the tested backbones.
- Multiple-precision output training might allow dynamic switching of embedding storage in production indexes based on query load.
- If the distillation losses generalize, similar techniques could reduce costs for other LLM downstream tasks that rely on internal representations.
Load-bearing premise
Continual contrastive pre-training plus similarity-distribution and attention-relation distillation from a full-precision teacher can recover representation quality after converting the backbone to ternary weights and quantized activations.
What would settle it
Running the same MMTEB (eng, v2) evaluation with Qwen3-0.6B or Gemma3-270M backbones and finding BITEMBED scores substantially below the full-precision teacher on retrieval metrics would falsify the comparability claim.
Figures

read the original abstract
LLM-based text embedders have substantially improved retrieval and semantic representation quality, but their deployment remains costly: large backbone models slow down embedding inference, while high-dimensional full-precision embeddings impose substantial storage and bandwidth overhead on large-scale indexes. In this paper, we present BITEMBED, an extreme low-bit framework for LLM-based text embedding that jointly targets encoding efficiency and vector storage. BITEMBED converts pretrained LLM backbones into BitNet-style embedding encoders with ternary weights, quantized activations, and lightweight normalization refinement. The converted model is adapted to representation learning through continual contrastive pre-training, followed by supervised contrastive fine-tuning with both similarity-distribution distillation and attention-relation distillation from a full-precision teacher. Beyond quantizing the backbone, BITEMBED further trains output embeddings to support multiple storage precisions meeting different storage needs in various scenarios. Experiments on MMTEB (eng, v2) with Qwen3-0.6B and Gemma3-270M show that BITEMBED is largely comparable to full precision teacher embedders. Moreover, BITEMBED flexibly obtains text embeddings of various precisions, achieving a trade-off between performance and storage cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BITEMBED, a framework for extreme low-bit LLM-based text embeddings. It converts pretrained LLM backbones (e.g., Qwen3-0.6B, Gemma3-270M) to BitNet-style encoders with ternary weights and quantized activations, applies continual contrastive pre-training followed by supervised contrastive fine-tuning with similarity-distribution and attention-relation distillation from a full-precision teacher, and trains output embeddings to support multiple storage precisions. Experiments on MMTEB (eng, v2) claim that the resulting models are largely comparable to full-precision teachers while enabling performance-storage trade-offs.
Significance. If the central performance claims hold after the described quantization and adaptation pipeline, the work would address practical deployment bottlenecks for embedding models by reducing both inference compute (via ternary weights) and index storage (via quantized embeddings). The multi-precision output training is a potentially useful extension beyond standard quantization. However, the absence of isolated ablation results or pre-adaptation baselines in the reported experiments limits the ability to quantify the contribution of the adaptation steps or to assess generalizability.
major comments (2)
- [Abstract] Abstract: The headline claim that BITEMBED remains 'largely comparable' to the full-precision teacher after ternary-weight + quantized-activation conversion rests on the two-stage adaptation (continual contrastive pre-training plus distillation). No MMTEB scores are reported for the converted model immediately after BitNet-style conversion but before any adaptation, so the magnitude of initial degradation and the actual recovery achieved cannot be assessed.
- [Abstract] Abstract (experiments paragraph): The statement that BITEMBED 'flexibly obtains text embeddings of various precisions' is presented without quantitative deltas, error bars, or dataset-split details on MMTEB (eng, v2). This prevents verification of whether the claimed trade-off between performance and storage cost is statistically meaningful or merely within noise of the teacher.
minor comments (1)
- [Abstract] The abstract mentions 'lightweight normalization refinement' without specifying the exact form or placement of this component relative to the ternary weights and quantized activations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that BITEMBED remains 'largely comparable' to the full-precision teacher after ternary-weight + quantized-activation conversion rests on the two-stage adaptation (continual contrastive pre-training plus distillation). No MMTEB scores are reported for the converted model immediately after BitNet-style conversion but before any adaptation, so the magnitude of initial degradation and the actual recovery achieved cannot be assessed.
Authors: We agree that reporting MMTEB performance for the model immediately after BitNet-style conversion (prior to the two-stage adaptation) would allow a clearer quantification of initial degradation and subsequent recovery. While the manuscript emphasizes end-to-end results for the full BITEMBED framework, we will add these pre-adaptation baseline scores on MMTEB (eng, v2) in the revised version to address this point directly. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): The statement that BITEMBED 'flexibly obtains text embeddings of various precisions' is presented without quantitative deltas, error bars, or dataset-split details on MMTEB (eng, v2). This prevents verification of whether the claimed trade-off between performance and storage cost is statistically meaningful or merely within noise of the teacher.
Authors: We acknowledge that the current abstract lacks the requested quantitative details. In the revised manuscript we will expand the relevant section to report specific MMTEB scores across precisions, include error bars or standard deviations where available from our runs, and clarify the evaluation splits and protocol on MMTEB (eng, v2) so that the performance-storage trade-offs can be assessed rigorously. revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper describes an empirical pipeline: BitNet-style conversion of LLM backbones followed by continual contrastive pre-training and distillation from an external full-precision teacher. No equations, fitted parameters, or self-citations are presented in the provided text that would make the reported MMTEB performance equivalent to the inputs by construction. The adaptation process is a standard training procedure whose outcome is measured against external benchmarks rather than derived tautologically. The central claims rest on experimental comparisons, not on renaming or self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semeval-2012 task 6: A pilot on semantic textual similarity
Eneko Agirre, Daniel Cer, Mona Diab, and Aitor Gonzalez-Agirre. Semeval-2012 task 6: A pilot on semantic textual similarity. in* sem 2012: The first joint conference on lexical and computational semantics–volume 1: Proceedings of the main conference and the shared task, and volume 2: Proceedings of the sixth international workshop on semantic evaluation (...
2012
-
[2]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[3]
Revela: Dense retriever learning via language modeling
Fengyu Cai, Tong Chen, Xinran Zhao, Sihao Chen, Hongming Zhang, Sherry Tongshuang Wu, Iryna Gurevych, and Heinz Koeppl. Revela: Dense retriever learning via language modeling. arXiv preprint arXiv:2506.16552, 2025
arXiv 2025
-
[4]
Efficient intent detection with dual sentence encoders.arXiv preprint arXiv:2003.04807, 2020
Iñigo Casanueva, Tadas Temˇcinas, Daniela Gerz, Matthew Henderson, and Ivan Vuli´c. Efficient intent detection with dual sentence encoders.arXiv preprint arXiv:2003.04807, 2020
arXiv 2003
-
[5]
Quartet: Native fp4 training can be optimal for large language models.Advances in Neural Information Processing Systems, 38:43552–43572, 2026
Roberto Castro, Andrei Panferov, Rush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, and Dan Alistarh. Quartet: Native fp4 training can be optimal for large language models.Advances in Neural Information Processing Systems, 38:43552–43572, 2026
2026
-
[6]
Daniel Cer, Mona Diab, Eneko Agirre, Inigo Lopez-Gazpio, and Lucia Specia. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation.arXiv preprint arXiv:1708.00055, 2017
Pith/arXiv arXiv 2017
-
[7]
Open-domain question answering
Danqi Chen and Wen-tau Yih. Open-domain question answering. InProceedings of the 58th annual meeting of the association for computational linguistics: tutorial abstracts, pages 34–37, 2020
2020
-
[8]
mme5: Improving multimodal multilingual embeddings via high-quality synthetic data
Haonan Chen, Liang Wang, Nan Yang, Yutao Zhu, Ziliang Zhao, Furu Wei, and Zhicheng Dou. mme5: Improving multimodal multilingual embeddings via high-quality synthetic data. In Findings of the Association for Computational Linguistics: ACL 2025, pages 8254–8275, 2025
2025
-
[9]
Efficientqat: Efficient quantization-aware training for large language models
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, and Ping Luo. Efficientqat: Efficient quantization-aware training for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10081–10100, 2025
2025
-
[10]
Semeval-2022 task 8: Multilingual news article similarity
Xi Chen, Ali Zeynali, Chico Camargo, Fabian Flöck, Devin Gaffney, Przemyslaw Grabowicz, Scott A Hale, David Jurgens, and Mattia Samory. Semeval-2022 task 8: Multilingual news article similarity. InProceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), pages 1094–1106, 2022
2022
-
[11]
Linq-embed-mistral technical report.arXiv preprint arXiv:2412.03223, 2024
Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, and Jy-yong Sohn. Linq-embed-mistral technical report.arXiv preprint arXiv:2412.03223, 2024. 10
arXiv 2024
-
[12]
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel S Weld. Specter: Document-level representation learning using citation-informed transformers.arXiv preprint arXiv:2004.07180, 2020
arXiv 2004
-
[13]
Quora question pairs.https://kaggle.com/competitions/quora-question-pairs, 2017
DataCanary, hilfialkaff, Lili Jiang, Meg Risdal, Nikhil Dandekar, and tomtung. Quora question pairs.https://kaggle.com/competitions/quora-question-pairs, 2017. Kaggle
2017
-
[14]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems, 35: 30318–30332, 2022
2022
-
[15]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volu...
-
[16]
Bitdistiller: Unleashing the potential of sub-4-bit llms via self-distillation
Dayou Du, Yijia Zhang, Shijie Cao, Jiaqi Guo, Ting Cao, Xiaowen Chu, and Ningyi Xu. Bitdistiller: Unleashing the potential of sub-4-bit llms via self-distillation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 102–116, 2024
2024
-
[17]
Mmteb: Massive multilingual text embedding benchmark.arXiv preprint arXiv:2502.13595, 2025
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi ´nski, Genta Indra Winata, et al. Mmteb: Massive multilingual text embedding benchmark.arXiv preprint arXiv:2502.13595, 2025
arXiv 2025
-
[18]
Eli5: Long form question answering.arXiv preprint arXiv:1907.09190, 2019
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. Eli5: Long form question answering.arXiv preprint arXiv:1907.09190, 2019
Pith/arXiv arXiv 1907
-
[19]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
Pith/arXiv arXiv 2022
-
[20]
Simcse: Simple contrastive learning of sentence embeddings.arXiv preprint arXiv:2104.08821, 2021
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings.arXiv preprint arXiv:2104.08821, 2021
Pith/arXiv arXiv 2021
-
[21]
A survey of low-bit large language models: Basics, systems, and algorithms.Neural networks, page 107856, 2025
Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Yang Yong, Shiqiao Gu, Haotong Qin, Jinyang Guo, et al. A survey of low-bit large language models: Basics, systems, and algorithms.Neural networks, page 107856, 2025
2025
-
[22]
Fei Huang, Fan Wu, Zeqing Zhang, Qihao Wang, Long Zhang, Grant Michael Boquet, and Hongyang Chen. Geogpt. rag technical report.arXiv preprint arXiv:2509.09686, 2025
arXiv 2025
-
[23]
Quaff: Quantized parameter-efficient fine-tuning under outlier spatial stability hypothesis
Hong Huang and Dapeng Wu. Quaff: Quantized parameter-efficient fine-tuning under outlier spatial stability hypothesis. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6481–6496, 2025
2025
-
[24]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InEMNLP (1), pages 6769–6781, 2020
2020
-
[25]
Colbert: Efficient and effective passage search via contextual- ized late interaction over bert
Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextual- ized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020
2020
-
[26]
Ma- tryoshka representation learning.Advances in Neural Information Processing Systems, 35: 30233–30249, 2022
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Ma- tryoshka representation learning.Advances in Neural Information Processing Systems, 35: 30233–30249, 2022
2022
-
[27]
Newsweeder: Learning to filter netnews
Ken Lang. Newsweeder: Learning to filter netnews. InMachine learning proceedings 1995, pages 331–339. Elsevier, 1995. 11
1995
-
[28]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv-embed: Improved techniques for training llms as generalist embedding models.arXiv preprint arXiv:2405.17428, 2024
Pith/arXiv arXiv 2024
-
[29]
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, et al. Gecko: Versatile text embeddings distilled from large language models.arXiv preprint arXiv:2403.20327, 2024
arXiv 2024
-
[30]
Llama2vec: Unsupervised adaptation of large language models for dense retrieval
Chaofan Li, Zheng Liu, Shitao Xiao, Yingxia Shao, and Defu Lian. Llama2vec: Unsupervised adaptation of large language models for dense retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3490–3500, 2024
2024
-
[31]
Making text embedders few-shot learners.arXiv preprint arXiv:2409.15700, 2024
Chaofan Li, MingHao Qin, Shitao Xiao, Jianlyu Chen, Kun Luo, Yingxia Shao, Defu Lian, and Zheng Liu. Making text embedders few-shot learners.arXiv preprint arXiv:2409.15700, 2024
arXiv 2024
-
[32]
Haoran Li, Abhinav Arora, Shuohui Chen, Anchit Gupta, Sonal Gupta, and Yashar Mehdad. Mtop: A comprehensive multilingual task-oriented semantic parsing benchmark.arXiv preprint arXiv:2008.09335, 2020
arXiv 2008
-
[33]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023
Pith/arXiv arXiv 2023
-
[35]
Zhen Li, Yupeng Su, Runming Yang, Congkai Xie, Zheng Wang, Zhongwei Xie, Ngai Wong, and Hongxia Yang. Quantization meets reasoning: Exploring llm low-bit quantization degradation for mathematical reasoning.arXiv preprint arXiv:2501.03035, 2025
arXiv 2025
-
[36]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[37]
Linkso: a dataset for learning to retrieve similar question answer pairs on software development forums
Xueqing Liu, Chi Wang, Yue Leng, and ChengXiang Zhai. Linkso: a dataset for learning to retrieve similar question answer pairs on software development forums. InProceedings of the 4th ACM SIGSOFT International Workshop on NLP for Software Engineering, pages 2–5, 2018
2018
-
[38]
Llm-qat: Data-free quantiza- tion aware training for large language models
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. Llm-qat: Data-free quantiza- tion aware training for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 467–484, 2024
2024
-
[39]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits.arXiv preprint arXiv:2402.17764, 2024
Pith/arXiv arXiv 2024
- [40]
-
[41]
Fine-tuning llama for multi-stage text retrieval
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2421–2425, 2024
2024
-
[42]
Learning word vectors for sentiment analysis
Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. InProceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pages 142–150, 2011. 12
2011
-
[43]
Tweet sentiment extraction
Maggie, Phil Culliton, and Wei Chen. Tweet sentiment extraction. https://kaggle.com/ competitions/tweet-sentiment-extraction, 2020. Kaggle
2020
-
[44]
Www’18 open challenge: financial opinion mining and question answering
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. Www’18 open challenge: financial opinion mining and question answering. InCompanion proceedings of the the web conference 2018, pages 1941– 1942, 2018
2018
-
[45]
Hidden factors and hidden topics: understanding rating dimensions with review text
Julian McAuley and Jure Leskovec. Hidden factors and hidden topics: understanding rating dimensions with review text. InProceedings of the 7th ACM conference on Recommender systems, pages 165–172, 2013
2013
-
[46]
Sfrembedding-mistral: enhance text retrieval with transfer learning.Salesforce AI Research Blog, 3:6, 2024
Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. Sfrembedding-mistral: enhance text retrieval with transfer learning.Salesforce AI Research Blog, 3:6, 2024
2024
-
[47]
Sgpt: Gpt sentence embeddings for semantic search.arXiv preprint arXiv:2202.08904, 2022
Niklas Muennighoff. Sgpt: Gpt sentence embeddings for semantic search.arXiv preprint arXiv:2202.08904, 2022
arXiv 2022
-
[48]
MTEB : Massive Text Embedding Benchmark
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive text embedding benchmark. In Andreas Vlachos and Isabelle Augenstein, editors,Proceedings of the 17th Conference of the European Chapter of the Association for Computational Lin- guistics, pages 2014–2037, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics....
-
[49]
Generative representational instruction tuning
Niklas Muennighoff, Hongjin Su, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. Generative representational instruction tuning. InInternational Conference on Learning Representations, volume 2025, pages 45544–45613, 2025
2025
-
[50]
Matryoshka quantization.arXiv preprint arXiv:2502.06786, 2025
Pranav Nair, Puranjay Datta, Jeff Dean, Prateek Jain, and Aditya Kusupati. Matryoshka quantization.arXiv preprint arXiv:2502.06786, 2025
arXiv 2025
-
[51]
Ms marco: A human-generated machine reading comprehension dataset
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. Ms marco: A human-generated machine reading comprehension dataset. 2016
2016
-
[52]
James O’Neill, Polina Rozenshtein, Ryuichi Kiryo, Motoko Kubota, and Danushka Bollegala. I wish i would have loved this one, but i didn’t–a multilingual dataset for counterfactual detection in product reviews.arXiv preprint arXiv:2104.06893, 2021
arXiv 2021
-
[53]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[54]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992, 2019
2019
-
[55]
Carer: Contextualized affect representations for emotion recognition
Elvis Saravia, Hsien-Chi Toby Liu, Yen-Hao Huang, Junlin Wu, and Yi-Shin Chen. Carer: Contextualized affect representations for emotion recognition. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 3687–3697, 2018
2018
-
[56]
Artyom Sorokin, Nazar Buzun, Alexander Anokhin, Oleg Inozemcev, Egor Vedernikov, Petr Anokhin, Mikhail Burtsev, Trushkov Alexey, Yin Wenshuai, and Evgeny Burnaev. Q-rag: Long context multi-step retrieval via value-based embedder training.arXiv preprint arXiv:2511.07328, 2025
Pith/arXiv arXiv 2025
-
[57]
Automatic evaluate dialogue ap- propriateness by using dialogue act
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction- finetuned text embeddings. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 1102–1121, Toronto...
-
[58]
Llms are also effective embedding models: An in-depth overview
Chongyang Tao, Tao Shen, Shen Gao, Junshuo Zhang, Zhen Li, Kai Hua, Wenpeng Hu, Zhengwei Tao, and Shuai Ma. Llms are also effective embedding models: An in-depth overview. arXiv preprint arXiv:2412.12591, 2024
arXiv 2024
-
[59]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
Pith/arXiv arXiv 2025
-
[60]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification.arXiv preprint arXiv:1803.05355, 2018
Pith/arXiv arXiv 2018
-
[61]
Retrieval of the best counterargument without prior topic knowledge
Henning Wachsmuth, Shahbaz Syed, and Benno Stein. Retrieval of the best counterargument without prior topic knowledge. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 241–251, 2018
2018
-
[62]
Bitnet: Scaling 1-bit transformers for large language models.arXiv preprint arXiv:2310.11453, 2023
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models.arXiv preprint arXiv:2310.11453, 2023
Pith/arXiv arXiv 2023
-
[63]
Text embeddings by weakly-supervised contrastive pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
Pith/arXiv arXiv 2022
-
[64]
Improving text embeddings with large language models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Improving text embeddings with large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for 14 Computational Linguistics (Volume 1: Long Papers), pages 11897–11916, Bangkok, Thailand, August 20...
-
[65]
Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024
Pith/arXiv arXiv 2024
-
[66]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
2020
-
[67]
Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2140–2151, 2021
2021
-
[68]
Yutong Wang, Haiyu Wang, and Sai Qian Zhang. Qsvd: Efficient low-rank approximation for unified query-key-value weight compression in low-precision vision-language models.Advances in Neural Information Processing Systems, 38:1789–1820, 2026
2026
-
[69]
Bitnet distillation.arXiv preprint arXiv:2510.13998, 2025
Xun Wu, Shaohan Huang, Wenhui Wang, Ting Song, Li Dong, Yan Xia, and Furu Wei. Bitnet distillation.arXiv preprint arXiv:2510.13998, 2025
arXiv 2025
-
[70]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[71]
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval.arXiv preprint arXiv:2007.00808, 2020
arXiv 2007
-
[72]
Onebit: Towards extremely low-bit large language models.Advances in Neural Information Processing Systems, 37:66357–66382, 2024
Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, and Wanxiang Che. Onebit: Towards extremely low-bit large language models.Advances in Neural Information Processing Systems, 37:66357–66382, 2024
2024
-
[73]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[74]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhut- dinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600, 2018
Pith/arXiv arXiv 2018
-
[75]
Zhihang Yuan, Lin Niu, Jiawei Liu, Wenyu Liu, Xinggang Wang, Yuzhang Shang, Guangyu Sun, Qiang Wu, Jiaxiang Wu, and Bingzhe Wu. Rptq: Reorder-based post-training quantization for large language models.arXiv preprint arXiv:2304.01089, 2023
arXiv 2023
-
[76]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
Pith/arXiv arXiv 2025
-
[77]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey.arXiv preprint arXiv:2402.19473, 2024
Pith/arXiv arXiv 2024
-
[78]
Dense text retrieval based on pretrained language models: A survey.ACM Transactions on Information Systems, 42(4):1–60, 2024
Wayne Xin Zhao, Jing Liu, Ruiyang Ren, and Ji-Rong Wen. Dense text retrieval based on pretrained language models: A survey.ACM Transactions on Information Systems, 42(4):1–60, 2024. 15
2024
-
[79]
Embedding in recommender systems: A survey.arXiv preprint arXiv:2310.18608, 2023
Xiangyu Zhao, Maolin Wang, Xinjian Zhao, Jiansheng Li, Shucheng Zhou, Dawei Yin, Qing Li, Jiliang Tang, and Ruocheng Guo. Embedding in recommender systems: A survey.arXiv preprint arXiv:2310.18608, 2023
arXiv 2023
-
[80]
Xinping Zhao, Xinshuo Hu, Zifei Shan, Shouzheng Huang, Yao Zhou, Xin Zhang, Zetian Sun, Zhenyu Liu, Dongfang Li, Xinyuan Wei, et al. Kalm-embedding-v2: Superior training techniques and data inspire a versatile embedding model.arXiv preprint arXiv:2506.20923, 2025. A Training Data Following BGE-en-ICL [31], our training data contains retrieval, reranking, ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.