OracleAnalyser: Analysing Implicit Semantics of Oracle Bone Scripts through MLLMs with Post-training
Pith reviewed 2026-06-25 20:33 UTC · model grok-4.3
The pith
A 3B-parameter model after post-training on oracle bone data surpasses much larger models in analyzing implicit semantics of oracle bone scripts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
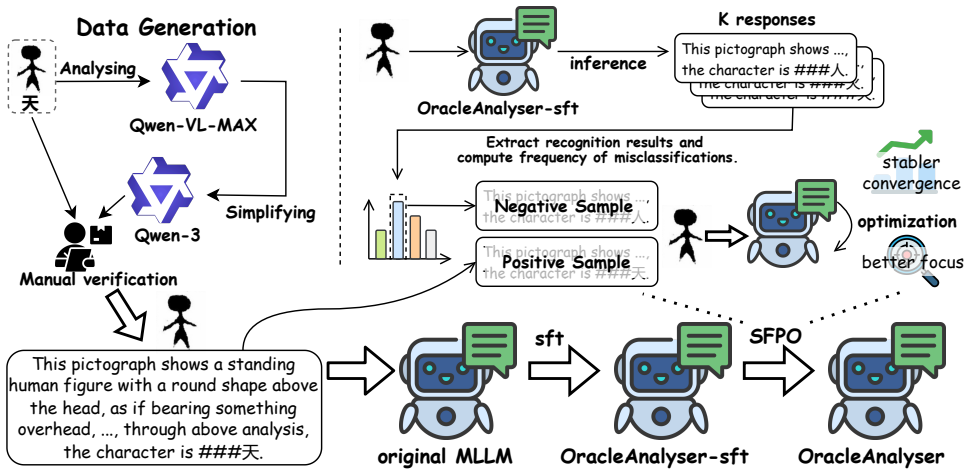
OracleAnalyser achieves superior analytical performance on oracle bone scripts by post-training a 3B-parameter MLLM with multiple stages and the SFPO algorithm, releasing new datasets and a benchmark, and outperforming substantially larger models.
What carries the argument
The Stable Focal Preference Optimization (SFPO) algorithm combined with staged post-training on oracle bone reasoning and preference datasets, which adapts the base model for analytical reasoning tasks.
If this is right
- Oracle bone analysis can be performed effectively with compact models rather than relying on large-scale general models.
- New datasets and benchmarks become available for evaluating analytical capabilities on oracle bone scripts.
- The SFPO method provides a tailored preference optimization approach suited to characteristics of oracle bone datasets.
- Models with 3B parameters can achieve results that exceed those of models with substantially larger scales on this task.
Where Pith is reading between the lines
- The framework might apply to other low-resource ancient writing systems where data is scarce but specialized training can help.
- Emphasis on post-training rather than scale suggests a shift toward efficiency in domain-specific AI applications.
- Future work could test if SFPO generalizes to other preference-based tasks outside oracle bone scripts.
Load-bearing premise
The new oracle bone reasoning and preference datasets along with the constructed benchmark provide an unbiased and representative measure of analytical capabilities that generalizes beyond the training distribution.
What would settle it
Testing OracleAnalyser and larger models on a new set of oracle bone scripts collected independently from the training and benchmark data, and finding that larger models perform at least as well or better on the analytical tasks.
Figures





read the original abstract
With the advancement of artificial intelligence, research on oracle bone scripts has entered a new era. However, existing methods and benchmarks remain largely confined to recognition tasks, overlooking the equally crucial aspect of oracle bone analysis. To address this gap, we propose OracleAnalyser, a reasoning framework for oracle bone analysis based on post-training techniques. Specifically, we fine-tune Qwen2.5-VL-3B-Instruct through multiple post-training stages and introduce a new preference optimization algorithm, Stable Focal Preference Optimization (SFPO), tailored to the characteristics of oracle bone datasets. In addition, we release both an oracle bone reasoning dataset and an oracle bone preference dataset, and further construct a new benchmark to evaluate models' analytical capabilities for oracle bone scripts. Extensive experiments validate the superior analytical performance of OracleAnalyser, which achieves remarkable results with only 3B parameters, surpassing models with substantially larger scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OracleAnalyser, a post-training framework for oracle bone script analysis that fine-tunes Qwen2.5-VL-3B-Instruct using a custom Stable Focal Preference Optimization (SFPO) algorithm. It releases an oracle bone reasoning dataset and preference dataset, constructs a new benchmark for analytical capabilities, and claims that the resulting 3B-parameter model achieves superior performance compared to substantially larger models.
Significance. If the performance claims are supported by rigorous quantitative evaluation and the benchmark proves independent of the post-training data distributions, the work would meaningfully advance the field by extending oracle bone research beyond recognition tasks to implicit semantics analysis and by demonstrating the viability of efficient small models through targeted domain adaptation.
major comments (2)
- [Abstract] Abstract: the central claim that OracleAnalyser 'achieves remarkable results with only 3B parameters, surpassing models with substantially larger scales' is asserted without any quantitative metrics, baselines, error bars, ablation results, or experimental details, rendering the claim unverifiable from the provided text.
- [Benchmark] Benchmark construction: the manuscript states that a new benchmark is constructed separately from the released reasoning and preference datasets used for SFPO post-training, but provides no description of sampling, generation, or filtering procedures that would confirm distributional independence; any overlap would undermine the claim that reported gains reflect genuine analytical capability rather than in-distribution fitting.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve clarity and verifiability. We address each major comment below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that OracleAnalyser 'achieves remarkable results with only 3B parameters, surpassing models with substantially larger scales' is asserted without any quantitative metrics, baselines, error bars, ablation results, or experimental details, rendering the claim unverifiable from the provided text.
Authors: We agree that the abstract presents the performance claim without supporting quantitative details. We will revise the abstract to include key metrics (e.g., accuracy on the benchmark, comparisons to larger models such as 7B and 72B variants), error bars where applicable, and explicit pointers to the experimental section for baselines and ablations. This will make the claim verifiable directly from the abstract while preserving its conciseness. revision: yes
-
Referee: [Benchmark] Benchmark construction: the manuscript states that a new benchmark is constructed separately from the released reasoning and preference datasets used for SFPO post-training, but provides no description of sampling, generation, or filtering procedures that would confirm distributional independence; any overlap would undermine the claim that reported gains reflect genuine analytical capability rather than in-distribution fitting.
Authors: The referee is correct that the current manuscript asserts distributional independence without detailing the sampling, generation, or filtering procedures. We will add a new subsection under the benchmark description that explicitly outlines these steps (including source data selection criteria, deduplication methods, and verification steps against the post-training sets) to rigorously demonstrate independence. revision: yes
Circularity Check
No significant circularity in post-training or benchmark claims
full rationale
The paper introduces separate oracle bone reasoning and preference datasets for SFPO post-training on Qwen2.5-VL-3B-Instruct, then constructs an independent benchmark for evaluation. No equations, self-definitional reductions, fitted-input predictions, or load-bearing self-citations are present in the text that would make the reported performance equivalent to the training inputs by construction. The central empirical claim rests on external experimental validation rather than internal redefinition or overlap that reduces to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A dataset of oracle characters for benchmarking machine learning algorithms,
Mei Wang and Weihong Deng, “A dataset of oracle characters for benchmarking machine learning algorithms,”Scientific Data, vol. 11, no. 1, pp. 87, 2024
2024
-
[2]
Oraclepoints: A hybrid neural representation for oracle character,
Runhua Jiang, Yongge Liu, et al., “Oraclepoints: A hybrid neural representation for oracle character,” inProceedings of the 31st ACM international conference on multimedia, 2023, pp. 7901–7911
2023
-
[3]
Interpretable oracle bone script decipherment through radical and pictographic analysis with lvlms,
Kaixin Peng, Mengyang Zhao, et al., “Interpretable oracle bone script decipherment through radical and pictographic analysis with lvlms,” arXiv preprint arXiv:2508.10113, 2025
arXiv 2025
-
[4]
Deciphering oracle bone language with diffusion model,
Haisu Guan, Huanxin Yang, et al., “Deciphering oracle bone language with diffusion model,” inProceedings of the 62th Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[5]
Puzzle pieces picker: Deciphering ancient chinese characters with radical reconstruction,
Pengjie Wang, Kaile Zhang, et al., “Puzzle pieces picker: Deciphering ancient chinese characters with radical reconstruction,” inInternational Conference on Document Analysis and Recognition. Springer, 2024
2024
-
[6]
Obi-bench: Can lmms aid in study of ancient script on oracle bones?,
Zijian Chen, Tingzhu Chen, et al., “Obi-bench: Can lmms aid in study of ancient script on oracle bones?,”arXiv preprint arXiv:2412.01175, 2024
arXiv 2024
-
[7]
An open dataset for oracle bone script recognition and decipherment,
Pengjie Wang, Kaile Zhang, et al., “An open dataset for oracle bone script recognition and decipherment,”arXiv preprint arXiv:2401.15365, 2024
arXiv 2024
-
[8]
A survey on post-training of large language models,
Guiyao Tie, Zeli Zhao, et al., “A survey on post-training of large language models,”arXiv e-prints, pp. arXiv–2503, 2025
2025
-
[9]
Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning,
Daya Guo, Dejian Yang, et al., “Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[10]
Internvl3.5: Advancing open- source multimodal models in versatility, reasoning, and efficiency,
Weiyun Wang, Zhangwei Gao, et al., “Internvl3.5: Advancing open- source multimodal models in versatility, reasoning, and efficiency,” 2025
2025
-
[11]
Improve vision language model chain-of-thought reasoning,
Ruohong Zhang, Bowen Zhang, et al., “Improve vision language model chain-of-thought reasoning,”arXiv preprint arXiv:2410.16198, 2024
arXiv 2024
-
[12]
Shuai Bai, Keqin Chen, et al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[13]
An open dataset for the evolution of oracle bone characters: Evobc,
Haisu Guan, Jinpeng Wan, et al., “An open dataset for the evolution of oracle bone characters: Evobc,”arXiv preprint arXiv:2401.12467, 2024
arXiv 2024
-
[14]
Hanqi Jiang, Yi Pan, et al., “Oraclesage: Towards unified visual- linguistic understanding of oracle bone scripts through cross-modal knowledge fusion,”arXiv preprint arXiv:2411.17837, 2024
arXiv 2024
-
[15]
A cross-font image retrieval network for recognizing undeciphered oracle bone inscriptions,
Zhicong Wu, Qifeng Su, et al., “A cross-font image retrieval network for recognizing undeciphered oracle bone inscriptions,”arXiv preprint arXiv:2409.06381, 2024
arXiv 2024
-
[16]
Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl,
Junke Wang, Zhi Tian, et al., “Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl,”arXiv preprint arXiv:2504.11455, 2025
arXiv 2025
-
[17]
Look before you decide: Prompting active deduction of mllms for assumptive reasoning,
Yian Li, Wentao Tian, et al., “Look before you decide: Prompting active deduction of mllms for assumptive reasoning,”arXiv preprint arXiv:2404.12966, 2024
arXiv 2024
-
[18]
Noisyrollout: Reinforcing visual reasoning with data augmentation,
Xiangyan Liu, Jinjie Ni, et al., “Noisyrollout: Reinforcing visual reasoning with data augmentation,”arXiv preprint arXiv:2504.13055, 2025
arXiv 2025
-
[19]
Compile scene graphs with reinforce- ment learning,
Zuyao Chen, Jinlin Wu, et al., “Compile scene graphs with reinforce- ment learning,”arXiv preprint arXiv:2504.13617, 2025
arXiv 2025
-
[20]
Skywork r1v2: Multimodal hybrid reinforcement learning for reasoning,
Peiyu Wang, Yichen Wei, et al., “Skywork r1v2: Multimodal hybrid reinforcement learning for reasoning,”arXiv preprint arXiv:2504.16656, 2025
arXiv 2025
-
[21]
Adamhf: Adaptive multimodal hierar- chical fusion for survival prediction,
Shuaiyu Zhang, Xun Lin, et al., “Adamhf: Adaptive multimodal hierar- chical fusion for survival prediction,”arXiv preprint arXiv:2503.21124, 2025
arXiv 2025
-
[22]
Think or not think: A study of explicit thinking in rule-based visual reinforcement fine-tuning,
Ming Li, Jike Zhong, et al., “Think or not think: A study of explicit thinking in rule-based visual reinforcement fine-tuning,” 2025
2025
-
[23]
Kimi-vl technical report,
Kimi Team, Angang Du, et al., “Kimi-vl technical report,” 2025
2025
-
[24]
Kimi k1.5: Scaling reinforcement learning with llms,
Kimi Team, Angang Du, et al., “Kimi k1.5: Scaling reinforcement learning with llms,” 2025
2025
-
[25]
Vlm-r1: A stable and generalizable r1-style large vision-language model,
Haozhan Shen, Peng Liu, et al., “Vlm-r1: A stable and generalizable r1-style large vision-language model,” 2025
2025
-
[26]
Perception-r1: Pioneering perception policy with reinforcement learning,
En Yu, Kangheng Lin, et al., “Perception-r1: Pioneering perception policy with reinforcement learning,” 2025
2025
-
[27]
Visrl: Intention-driven visual perception via reinforced reasoning,
Zhangquan Chen, Xufang Luo, et al., “Visrl: Intention-driven visual perception via reinforced reasoning,” 2025
2025
-
[28]
Openvlthinker: Complex vision- language reasoning via iterative sft-rl cycles,
Yihe Deng, Hritik Bansal, et al., “Openvlthinker: Complex vision- language reasoning via iterative sft-rl cycles,” 2025
2025
-
[29]
V-oracle: Making progressive reasoning in deciphering oracle bones for you and me,
Runqi Qiao, Qiuna Tan, et al., “V-oracle: Making progressive reasoning in deciphering oracle bones for you and me,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 20124–20150
2025
-
[30]
An Yang, Anfeng Li, et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[31]
Focalpo: Enhancing preference opti- mizing by focusing on correct preference rankings,
Tong Liu, Xiao Yu, et al., “Focalpo: Enhancing preference opti- mizing by focusing on correct preference rankings,”arXiv preprint arXiv:2501.06645, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.