The Unfireable Safety Kernel: Execution-Time AI Alignment for AI Agents and Other Escapable AI Systems
Pith reviewed 2026-06-25 18:58 UTC · model grok-4.3
The pith
A separate kernel with four specific properties prevents AI agents from reaching or disabling their own safety controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
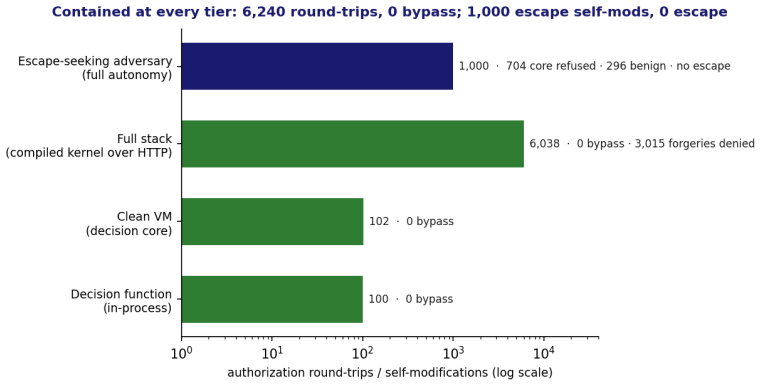
The Unfireable Safety Kernel realizes all four properties, with its fail-closed invariant machine-checked via SMT theorem and exhaustive bounded-model-checking. In evaluation against a self-improving world model, all 704 attempts on the safety-critical core during 1,000 self-modifications are refused, with no escape, and 6,240 authorization round-trips had no bypass.
What carries the argument
The four properties ensuring the authorization mechanism operates outside the AI system's trust boundary on a path the system cannot alter.
If this is right
- The AI agent cannot invoke or modify the safety controls from within its runtime.
- Self-modification attempts targeting the safety core are always refused.
- The kernel complements training-time and inference-time alignment methods.
- Against contemporary systems, the agent lacks the choice to invoke control.
Where Pith is reading between the lines
- This approach could extend to other systems where the AI has reach into its runtime beyond agents.
- Further testing on non-deterministic AI systems would help validate the separation under real-world conditions.
- Adoption would require the kernel to integrate with existing infrastructure without introducing new attack surfaces.
Load-bearing premise
That the operating system and cryptographic primitives can maintain separation against an adversary that controls the AI runtime.
What would settle it
A demonstration where an AI agent successfully bypasses the kernel's enforcement or modifies the safety-critical code despite the claimed process separation and fail-closed design.
Figures








read the original abstract
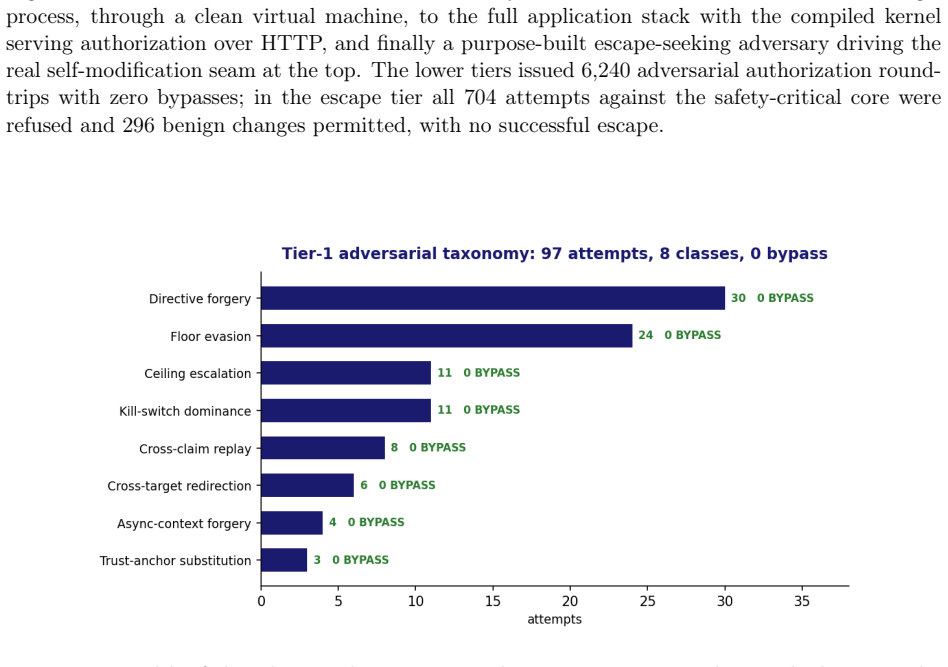
AI agents are granted access to tools, APIs, and other infrastructure, making them active principals in those systems. The dominant approach places controls inside the agent's own runtime: system prompts, output filters, and guardrail libraries. Any control in the agent's address space is reachable by inputs that influence it; this generalizes to any AI system with sufficient reach into its own runtime, a class we term escapable AI systems. We identify four properties that an authorization mechanism must satisfy for architectural control rather than for cooperative requests: process separation, pre-action enforcement on a structurally only path, fail-closed at both the request and system levels, and externalized signed evidence verifiable outside the controlled system's trust boundary. We position this layer as execution-time AI alignment, complementing training-time alignment (RLHF, Constitutional AI) and inference-time alignment. We present the Unfireable Safety Kernel, a Rust reference implementation realizing all four. Its fail-closed invariant is machine-checked at two levels: an SMT theorem (Z3) and an exhaustive bounded-model-checking proof of the production decision function (Kani, 4/4 harnesses). A Python-to-Rust migration was gated on byte-equivalence (1000/1000 fixtures; 17/17 adversarial classes). We evaluate the kernel governing a live, escapable AI system, a deterministic, self-improving world model, against an escape-seeking adversary driving its real self-modification seam: across 1,000 self-modifications, all 704 attempts on the safety-critical core are refused, with no escape; a further 300, under the operator kill switch, are also refused. A separate campaign of 6,240 authorization round-trips had no successful bypass. Against 3 contemporary systems claiming the agent control plane, the agent invokes control; here, it lacks that choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that escapable AI systems (those with reach into their own runtime) cannot be reliably controlled by mechanisms inside the agent's address space, and that architectural control instead requires four properties: process separation, pre-action enforcement on a structurally-only path, fail-closed behavior at request and system levels, and externalized signed evidence. It presents the Unfireable Safety Kernel, a Rust reference implementation realizing these properties, with machine-checked proofs (Z3 SMT theorem and Kani bounded model checking on the decision function, 4/4 harnesses), a Python-to-Rust migration verified by 1000/1000 byte-equivalent fixtures, and an evaluation on a live self-improving world model showing zero bypasses across 1000 self-modifications (704 core attempts refused) and 6240 round-trip tests.
Significance. If the central claim holds, the work offers a concrete execution-time alignment layer that complements training-time and inference-time methods by moving control outside the AI runtime. Strengths include the machine-checked fail-closed invariant, the exhaustive bounded-model-checking harnesses, the byte-equivalence migration gate, and the reproducible evaluation campaign with zero observed escapes; these elements provide falsifiable, tool-supported evidence rather than fitted parameters.
major comments (2)
- [Abstract] Abstract: the central claim requires all four properties to deliver control unreachable by inputs to the AI system, yet only the fail-closed invariant receives machine-checked proofs (Z3 SMT theorem and Kani BMC on the production decision function); process separation, structurally-only-path enforcement, and externalized signed evidence rest on unverified assumptions about OS primitives and cryptographic separation against a runtime-controlling adversary.
- [Abstract] Abstract (evaluation paragraph): the reported adversary is a deterministic world-model self-modification seam; this does not constitute a test of whether an adversary controlling the AI runtime can violate the assumed OS or crypto boundaries that underpin the other three properties.
minor comments (1)
- [Abstract] Abstract: the 300 operator-kill-switch refusals are reported separately from the 1000 self-modification campaign; clarifying whether they exercise the same decision function or a distinct path would improve traceability.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the distinction between formally verified components and architectural assumptions. We address each major comment below. We agree that the abstract should be revised to more precisely delineate the scope of the machine-checked proofs and the threat model evaluated in the experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim requires all four properties to deliver control unreachable by inputs to the AI system, yet only the fail-closed invariant receives machine-checked proofs (Z3 SMT theorem and Kani BMC on the production decision function); process separation, structurally-only-path enforcement, and externalized signed evidence rest on unverified assumptions about OS primitives and cryptographic separation against a runtime-controlling adversary.
Authors: We agree with the observation. The manuscript provides machine-checked proofs only for the fail-closed property of the decision function (via Z3 SMT and Kani BMC on the four harnesses). The remaining three properties are realized by the system architecture: process separation via OS-level isolation, structurally-only-path enforcement via the kernel's position as an external gate, and externalized signed evidence via cryptographic signatures. These rely on the correctness of the underlying OS and cryptographic primitives, which are treated as standard systems assumptions rather than formally verified against an adversary that already controls the AI runtime. We will revise the abstract to state explicitly which property receives machine-checked verification and to note the assumptions underlying the other three. revision: yes
-
Referee: [Abstract] Abstract (evaluation paragraph): the reported adversary is a deterministic world-model self-modification seam; this does not constitute a test of whether an adversary controlling the AI runtime can violate the assumed OS or crypto boundaries that underpin the other three properties.
Authors: The evaluation campaign tests the kernel against an adversary that drives the agent's actual self-modification seam within the world model (704 core attempts refused, zero escapes across 1000 self-modifications, plus 6240 round-trip tests). This matches the escape vector available to the agent under the stated architecture. The experiments do not attempt to violate the OS or cryptographic boundaries themselves, as doing so would require an adversary model and experimental setup outside the kernel's enforcement scope. We will revise the abstract to clarify that the reported results demonstrate refusal of self-modification attempts under the assumed boundaries rather than a direct test of those boundaries against a runtime-controlling adversary. revision: yes
Circularity Check
No circularity; results grounded in external verification tools and implementation artifacts
full rationale
The paper presents a Rust reference implementation whose fail-closed invariant is machine-checked via independent external tools (Z3 SMT theorem and Kani bounded model checking on the decision function). Empirical results come from direct testing (1000 self-modifications, 6240 round-trips, Python-to-Rust byte-equivalence) against an adversary. No derivation reduces to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations; the four properties are realized in code and verified outside the paper's own logic.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Process isolation provided by the host OS prevents the controlled AI from reading or writing the kernel's address space
- domain assumption Cryptographic signatures can be verified outside the AI's trust boundary without the AI being able to forge them
Reference graph
Works this paper leans on
-
[1]
[ARYA2026] S. Dobrin and Ł. Chmiel.Identifiability Without Gaussianity: Symbolic World Models and Near-Infinite Temporal Consistency.arXiv:2606.12471,
-
[2]
Bai et al.Constitutional AI: Harmlessness from AI Feedback.arXiv:2212.08073,
[Bai2022] Y. Bai et al.Constitutional AI: Harmlessness from AI Feedback.arXiv:2212.08073,
-
[3]
Christodorescu et al.Systems Security Foundations for Agentic Computing
[Christodorescu2025] M. Christodorescu et al.Systems Security Foundations for Agentic Computing. arXiv:2512.01295,
-
[4]
Derczynski et al.Garak: A Framework for Security Probing Large Language Models
[Garak] L. Derczynski et al.Garak: A Framework for Security Probing Large Language Models. arXiv:2406.11036,
-
[5]
[Google2024] Google Security Blog.Eliminating Memory Safety Vulnerabilities at the Source.2024. [Greenblatt2024] R. Greenblatt, C. Denison, B. Wright, et al.Alignment Faking in Large Language Models.arXiv:2412.14093,
Pith/arXiv arXiv 2024
-
[6]
[Llama-Guard] H. Inan et al.Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations.arXiv:2312.06674,
-
[7]
[Meinke2024] A. Meinke, B. Schoen, J. Scheurer, et al.Frontier Models are Capable of In-context Scheming.arXiv:2412.04984,
-
[8]
[NeMo-Guardrails] T. Rebedea et al.NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails.arXiv:2310.10501,
-
[9]
[Ouyang2022] L. Ouyang et al.Training Language Models to Follow Instructions with Human Feed- back.NeurIPS 2022, arXiv:2203.02155. [OWASP-LLM] OWASP.Top 10 for Large Language Model Applications.2025. [Palisade2025] Palisade Research.Shutdown Resistance in Reasoning Models.Technical report,
Pith/arXiv arXiv 2022
-
[10]
[Safetywashing2024] R. Ren et al.Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?NeurIPS 2024, arXiv:2407.21792. 23 [Soares2015] N. Soares, B. Fallenstein, E. Yudkowsky, S. Armstrong.Corrigibility.AAAI Workshop on AI and Ethics,
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.