Implementation of reinforcement learning in chemical reaction networks: application to phototaxis as curiosity-driven exploration
Pith reviewed 2026-06-26 01:59 UTC · model grok-4.3
The pith
A POMDP implemented in chemical reaction networks reproduces Chlamydomonas phototaxis by treating run-tumble motion as active sampling to resolve sensory ambiguity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding a POMDP inside chemical reaction network ordinary differential equations, the framework shows that run-tumble alternation in Chlamydomonas emerges naturally as an information-acquisition strategy: tumbling reorients the cell to sample new sensory configurations and resolve sensor ambiguity, while the inferred behavioral objective produces alignment statistics that match experimental trajectories.
What carries the argument
CRN-ODEs that realize memoryless Bayesian internal-state updates balancing light-oriented motion against exploratory reorientation, together with a biophysical photoreception process and a chemically computable polynomial bound on information gain.
If this is right
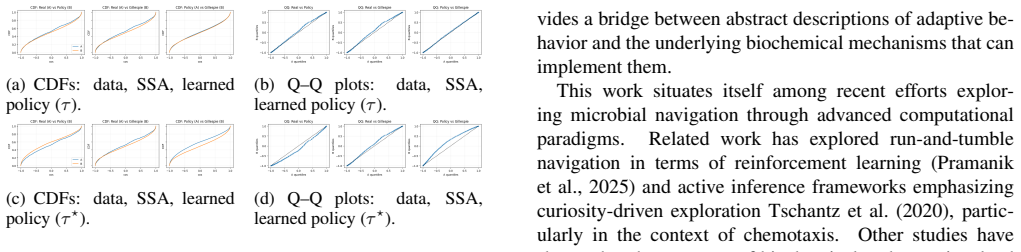
- The model reproduces the empirical alignment-to-light distribution at a level comparable to objective SSA baselines.
- Run-tumble alternation is shown to function as an information-acquisition strategy that resolves sensor ambiguity.
- Intracellular biochemical networks are shown to be capable of supporting adaptive information-seeking behavior during cellular navigation.
- Inverse reinforcement learning can recover a behavioral objective consistent with observed phototactic motion when applied to trajectory data.
Where Pith is reading between the lines
- The same CRN-POMDP construction could be applied to other unicellular navigation tasks where sensory ambiguity must be resolved by movement.
- Perturbations that alter the biochemical rates governing Bayesian updates should produce measurable changes in the frequency of tumbling events.
- The polynomial information-gain bound offers a concrete, chemically realizable objective that could be tested by comparing predicted versus observed exploration rates under varying light conditions.
Load-bearing premise
That the POMDP state updates and the tradeoff between orienting and exploratory reorientation can be faithfully realized as memoryless Bayesian steps inside ordinary differential equations of a chemical reaction network.
What would settle it
Generate trajectories from the CRN model using the IRL-inferred objective and check whether their alignment-to-light histogram deviates significantly from the histogram measured on the thirty experimental Chlamydomonas recordings while standard SSA baselines remain close.
Figures


read the original abstract
Living systems navigate environments using noisy and incomplete sensory signals. In unicellular algae, phototaxis is often modeled as a mechanistic run--tumble process driven by stimulus--response rules. However, such descriptions overlook how organisms actively sample their environment to reduce sensory ambiguity. From a minimal cognition perspective, we reframe this navigation as a subjective, information-driven sensorimotor process. To this end, we propose a framework linking a Partially Observable Markov Decision Process (POMDP) with biochemical reaction dynamics. Environmental variables are hidden, while the cell updates a minimal internal state from each observation through a memoryless Bayesian step. These internal dynamics balance orienting toward light with exploratory reorientation and can be implemented through Chemical-Reaction-Network Ordinary Differential Equations (CRN--ODEs). Our model includes a biophysical observation process for photoreception and a chemically computable polynomial bound on information gain. Using Inverse Reinforcement Learning (IRL) on 30 experimentally recorded Chlamydomonas trajectories, we infer the behavioral objective consistent with observed phototactic motion and benchmark the resulting dynamics with standard Stochastic Simulation Algorithm (SSA) baselines. Our model reproduces the empirical alignment-to-light distribution, comparable to objective SSA baselines on this dataset. Within this framework, run--tumble alternation emerges as an information-acquisition strategy: tumbling reorients the cell to sample new sensory configurations and resolve sensor ambiguity, demonstrating how intracellular biochemical networks can support adaptive information-seeking behavior in cellular navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework that links a Partially Observable Markov Decision Process (POMDP) for phototaxis in Chlamydomonas to Chemical Reaction Network Ordinary Differential Equations (CRN-ODEs). It incorporates a biophysical photoreception process and a polynomial bound on information gain, uses Inverse Reinforcement Learning (IRL) on 30 experimental trajectories to infer the behavioral objective, benchmarks against SSA baselines, reproduces the empirical alignment-to-light distribution, and interprets run-tumble alternation as an emergent information-acquisition strategy that resolves sensory ambiguity.
Significance. If the POMDP-to-CRN-ODE embedding and the IRL-based interpretation hold without circularity or approximation artifacts, the work would provide a concrete biochemical substrate for curiosity-driven exploration and minimal cognition in single cells, extending RL concepts into systems biology and offering a mechanistic account of adaptive sensorimotor behavior beyond simple stimulus-response models.
major comments (2)
- [CRN-ODE implementation of the POMDP (abstract and methods description)] The central modeling step—embedding memoryless Bayesian belief updates (balancing light-orienting and exploratory reorientation) into mass-action CRN-ODEs together with photoreception kinetics and a polynomial information-gain bound—is load-bearing for all subsequent claims, yet the manuscript provides no explicit rate laws or verification that normalization (a division) is realized without introducing bias or non-biophysical tuning; standard CRN-ODEs support only polynomial or rational kinetics unless auxiliary species are introduced.
- [IRL inference and benchmarking against SSA baselines] IRL is performed on the same 30 experimentally recorded trajectories that are later used to benchmark the model and claim emergence of run-tumble as information acquisition; by construction the fitted objective is consistent with the data, so the interpretation that tumbling resolves sensor ambiguity does not constitute an independent test of the framework.
minor comments (1)
- [Methods and parameter tables] The manuscript should report the full set of CRN rate constants, scaling parameters, polynomial coefficients for the information-gain bound, and data-exclusion criteria for the 30 trajectories to allow independent verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [CRN-ODE implementation of the POMDP (abstract and methods description)] The central modeling step—embedding memoryless Bayesian belief updates (balancing light-orienting and exploratory reorientation) into mass-action CRN-ODEs together with photoreception kinetics and a polynomial information-gain bound—is load-bearing for all subsequent claims, yet the manuscript provides no explicit rate laws or verification that normalization (a division) is realized without introducing bias or non-biophysical tuning; standard CRN-ODEs support only polynomial or rational kinetics unless auxiliary species are introduced.
Authors: We agree that the manuscript would be strengthened by explicit rate laws. In revision we will add the complete set of mass-action reactions and the resulting ODE system, including the auxiliary species used to implement the normalization step while preserving polynomial kinetics. The polynomial information-gain bound was selected precisely because it admits a direct chemical realization; we will include verification simulations comparing the CRN-ODE trajectories to the exact Bayesian update to confirm that no material bias is introduced. revision: yes
-
Referee: [IRL inference and benchmarking against SSA baselines] IRL is performed on the same 30 experimentally recorded trajectories that are later used to benchmark the model and claim emergence of run-tumble as information acquisition; by construction the fitted objective is consistent with the data, so the interpretation that tumbling resolves sensor ambiguity does not constitute an independent test of the framework.
Authors: The IRL step recovers the objective consistent with the observed trajectories under the POMDP formulation. The subsequent analysis shows that, once this objective is fixed, the belief-update dynamics implemented by the CRN-ODEs cause run-tumble alternation to emerge as the policy that maximizes expected information gain. This is an explanatory, not a predictive, claim: the model is not asserted to forecast held-out data but to supply a mechanistic account of how the inferred objective is realized biochemically. The SSA comparison establishes that the CRN-ODE implementation matches empirical statistics at least as closely as standard baselines. We will revise the text to make this distinction explicit and to note the absence of cross-validation as a limitation. revision: partial
Circularity Check
IRL fit to trajectories makes reproduction and 'emergence' of run-tumble as info-acquisition tautological by construction
specific steps
-
fitted input called prediction
[Abstract]
"Using Inverse Reinforcement Learning (IRL) on 30 experimentally recorded Chlamydomonas trajectories, we infer the behavioral objective consistent with observed phototactic motion and benchmark the resulting dynamics with standard Stochastic Simulation Algorithm (SSA) baselines. Our model reproduces the empirical alignment-to-light distribution, comparable to objective SSA baselines on this dataset. Within this framework, run--tumble alternation emerges as an information-acquisition strategy: tumbling reorients the cell to sample new sensory configurations and resolve sensor ambiguity."
The objective is obtained by fitting to the trajectories; the subsequent reproduction of their alignment distribution and the interpretation of run-tumble as an information-acquisition strategy are therefore forced by the IRL construction rather than constituting an independent prediction from the biochemical network model.
full rationale
The paper infers the behavioral objective via IRL directly from the 30 trajectories, then uses that objective to generate dynamics whose statistics are benchmarked against the same trajectories and interpreted as demonstrating information-seeking behavior. This matches the 'fitted_input_called_prediction' pattern: the reproduction and the emergence claim are properties of the fitted reward rather than independent outputs of the CRN-POMDP embedding. The POMDP-to-CRN mapping itself is a separate modeling step whose correctness is not addressed by circularity analysis. No self-citation load-bearing or self-definitional reductions are evident from the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- polynomial coefficients for information gain bound
- CRN rate constants and scaling parameters
axioms (2)
- domain assumption Environmental variables are hidden while the cell updates a minimal internal state from each observation through a memoryless Bayesian step
- domain assumption The internal dynamics balance orienting toward light with exploratory reorientation
invented entities (1)
-
CRN-ODE realization of the POMDP for phototaxis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Physical review fluids , volume=
Optimal trajectories for Bayesian olfactory search in turbulent flows: The low information limit and beyond , author=. Physical review fluids , volume=. 2025 , publisher=
2025
-
[2]
Europhysics letters , volume=
Gradient sensing in Bayesian chemotaxis , author=. Europhysics letters , volume=. 2022 , publisher=
2022
-
[3]
2017 , author =
Cell signaling as a probabilistic computer , journal =. 2017 , author =
2017
-
[4]
2018 , eprint=
Computing with Chemical Reaction Networks: A Tutorial , author=. 2018 , eprint=
2018
-
[5]
Proceedings of the National Academy of Sciences , volume =
A Goldbeter and D E Koshland , title =. Proceedings of the National Academy of Sciences , volume =. 1981 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.78.11.6840 , abstract =
-
[6]
Science , volume=
Chlamydomonas swims with two “gears” in a eukaryotic version of run-and-tumble locomotion , author=. Science , volume=. 2009 , publisher=
2009
-
[7]
Physical Review E , volume=
Run-and-tumble chemotaxis using reinforcement learning , author=. Physical Review E , volume=. 2025 , publisher=
2025
-
[8]
PLOS Computational Biology , volume=
Identification of the governing equation of stimulus-response data for run-and-tumble dynamics , author=. PLOS Computational Biology , volume=. 2025 , publisher=
2025
-
[9]
PLoS computational biology , volume=
Learning action-oriented models through active inference , author=. PLoS computational biology , volume=. 2020 , publisher=
2020
-
[10]
Natural computing , volume=
Deterministic function computation with chemical reaction networks , author=. Natural computing , volume=. 2014 , publisher=
2014
-
[11]
Natural computing , volume=
Programming discrete distributions with chemical reaction networks , author=. Natural computing , volume=. 2018 , publisher=
2018
-
[12]
Wiuf, Carsten and Behera, Abhishek and Singh, Abhinav and Gopalkrishnan, Manoj , title =. Journal of The Royal Society Interface , volume =. 2023 , doi =. https://royalsocietypublishing.org/doi/pdf/10.1098/rsif.2022.0877 , abstract =
-
[13]
PLOS Computational Biology , publisher =
The gradient of the reinforcement landscape influences sensorimotor learning , year =. PLOS Computational Biology , publisher =. doi:10.1371/journal.pcbi.1006839 , author =
-
[14]
and Daunizeau, Jean and Kiebel, Stefan J
Reinforcement Learning or Active Inference? , year =. PLOS ONE , publisher =. doi:10.1371/journal.pone.0006421 , author =
-
[15]
PLOS Computational Biology , publisher =
Predicting explorative motor learning using decision-making and motor noise , year =. PLOS Computational Biology , publisher =. doi:10.1371/journal.pcbi.1005503 , author =
-
[16]
PLOS Computational Biology , publisher =
Modeling sensory-motor decisions in natural behavior , year =. PLOS Computational Biology , publisher =. doi:10.1371/journal.pcbi.1006518 , author =
-
[17]
PLOS Computational Biology , publisher =
Decision making improves sperm chemotaxis in the presence of noise , year =. PLOS Computational Biology , publisher =. doi:10.1371/journal.pcbi.1006109 , author =
-
[18]
PLOS Computational Biology , publisher =
Motility Enhancement through Surface Modification Is Sufficient for Cyanobacterial Community Organization during Phototaxis , year =. PLOS Computational Biology , publisher =. doi:10.1371/journal.pcbi.1003205 , author =
-
[19]
Which States Matter? An Application of an Intelligent Discretization Method to Solve a Continuous POMDP in Conservation Biology , year =. PLOS ONE , publisher =. doi:10.1371/journal.pone.0028993 , author =
-
[20]
Optimal sensing and control of run-and-tumble chemotaxis , author =. Phys. Rev. Res. , volume =. 2022 , month =
2022
-
[21]
Choi, Jaedeug and Kim, Kee-Eung , title =. J. Mach. Learn. Res. , month = jul, pages =. 2011 , issue_date =
2011
-
[22]
2022 , eprint=
IRL with Partial Observations using the Principle of Uncertain Maximum Entropy , author=. 2022 , eprint=
2022
-
[23]
Winner-take-all (computing) --- Wikipedia , The Free Encyclopedia
Wikipedia contributors. Winner-take-all (computing) --- Wikipedia , The Free Encyclopedia. 2024
2024
-
[24]
G.G. Yen and W. Feng , keywords =. Winner take all experts network for sensor validation , journal =. 2001 , issn =. doi:https://doi.org/10.1016/S0019-0578(00)00047-1 , url =
-
[25]
and Darrell, Trevor , booktitle=
Pathak, Deepak and Agrawal, Pulkit and Efros, Alexei A. and Darrell, Trevor , booktitle=. Curiosity-Driven Exploration by Self-Supervised Prediction , year=
-
[26]
, booktitle=
Meyer, Jean-Arcady and Wilson, Stewart W. , booktitle=. A Possibility for Implementing Curiosity and Boredom in Model-Building Neural Controllers , year=
-
[27]
, title =
Gillespie, Daniel T. , title =. The Journal of Physical Chemistry , volume =. 1977 , doi =
1977
-
[28]
Overview of Mathematical Approaches Used to Model Bacterial Chemotaxis I: The Single Cell , volume =
Tindall, Marcus and Porter, Steven and Maini, Philip and Gaglia, Giorgio and Armitage, Judith , year =. Overview of Mathematical Approaches Used to Model Bacterial Chemotaxis I: The Single Cell , volume =. Bulletin of mathematical biology , doi =
-
[29]
Erban, Radek and Othmer, Hans G. , title =. SIAM Journal on Applied Mathematics , volume =. 2004 , doi =. https://doi.org/10.1137/S0036139903433232 , abstract =
-
[30]
Tailleur, J. and Cates, M. E. , year=. Statistical Mechanics of Interacting Run-and-Tumble Bacteria , volume=. Physical Review Letters , publisher=. doi:10.1103/physrevlett.100.218103 , number=
-
[31]
S. Muiños-Landin and A. Fischer and V. Holubec and F. Cichos , title =. Science Robotics , volume =. 2021 , doi =. https://www.science.org/doi/pdf/10.1126/scirobotics.abd9285 , abstract =
-
[32]
2018 , doi =
Gottlieb, Jacqueline and Oudeyer, Pierre-Yves , journal =. 2018 , doi =
2018
-
[33]
Proceedings of the international conference on automated planning and scheduling , volume=
Task-guided inverse reinforcement learning under partial information , author=. Proceedings of the international conference on automated planning and scheduling , volume=
-
[34]
Ziebart and Andrew Maas and J
Brian D. Ziebart and Andrew Maas and J. Andrew Bagnell and Anind K. Dey , title =. 2008 , booktitle =
2008
-
[35]
and Gopalkrishnan, Manoj , title =
Poole, William and Ouldridge, Thomas E. and Gopalkrishnan, Manoj , title =. Journal of The Royal Society Interface , volume =. 2025 , month =. doi:10.1098/rsif.2024.0373 , url =
-
[36]
PLOS Computational Biology , publisher =
Operant conditioning of stochastic chemical reaction networks , year =. PLOS Computational Biology , publisher =. doi:10.1371/journal.pcbi.1010676 , author =
-
[37]
Cognitive Neuroscience , volume =
Karl Friston and Francesco Rigoli and Dimitri Ognibene and Christoph Mathys and Thomas Fitzgerald and Giovanni Pezzulo , title =. Cognitive Neuroscience , volume =. 2015 , publisher =. doi:10.1080/17588928.2015.1020053 , note =
-
[38]
Generalized entropy-based criterion for consistent testing , author =. Phys. Rev. E , volume =. 1998 , month =. doi:10.1103/PhysRevE.58.1442 , url =
-
[39]
Entropy , VOLUME =
Vila, Màrius and Bardera, Anton and Feixas, Miquel and Sbert, Mateu , TITLE =. Entropy , VOLUME =. 2011 , NUMBER =
2011
-
[40]
and Lakin, M
Arredondo, D. and Lakin, M. R. (2022). Operant conditioning of stochastic chemical reaction networks. PLOS Computational Biology , 18(11):1--20
2022
-
[41]
Auconi, A., Novak, M., and Friedrich, B. M. (2022). Gradient sensing in bayesian chemotaxis. Europhysics letters , 138(1):12001
2022
-
[42]
Cardelli, L., Kwiatkowska, M., and Laurenti, L. (2018). Programming discrete distributions with chemical reaction networks. Natural computing , 17(1):131--145
2018
-
[43]
Chen, H.-L., Doty, D., and Soloveichik, D. (2014). Deterministic function computation with chemical reaction networks. Natural computing , 13(4):517--534
2014
-
[44]
and Kim, K.-E
Choi, J. and Kim, K.-E. (2011). Inverse reinforcement learning in partially observable environments. J. Mach. Learn. Res. , 12(null):691–730
2011
-
[45]
Colliaux, D., Bessière, P., and Droulez, J. (2017). Cell signaling as a probabilistic computer. International Journal of Approximate Reasoning , 83:385--399
2017
-
[46]
Djeumou, F., Cubuktepe, M., Lennon, C., and Topcu, U. (2022). Task-guided inverse reinforcement learning under partial information. In Proceedings of the international conference on automated planning and scheduling , volume 32, pages 53--61
2022
-
[47]
and Othmer, H
Erban, R. and Othmer, H. G. (2004). From individual to collective behavior in bacterial chemotaxis. SIAM Journal on Applied Mathematics , 65(2):361--391
2004
-
[48]
Friston, K., Rigoli, F., Ognibene, D., Mathys, C., Fitzgerald, T., and Pezzulo, G. (2015). Active inference and epistemic value. Cognitive Neuroscience , 6(4):187--214. PMID: 25689102
2015
-
[49]
Gillespie, D. T. (1977). Exact stochastic simulation of coupled chemical reactions. The Journal of Physical Chemistry , 81(25):2340--2361
1977
-
[50]
and Oudeyer, P.-Y
Gottlieb, J. and Oudeyer, P.-Y. (2018). Towards a neuroscience of active sampling and curiosity . Nature reviews. Neuroscience , 19(12):758--770
2018
-
[51]
A., Biferale, L., Celani, A., and Vergassola, M
Heinonen, R. A., Biferale, L., Celani, A., and Vergassola, M. (2025). Optimal trajectories for bayesian olfactory search in turbulent flows: The low information limit and beyond. Physical review fluids , 10(4):044601
2025
-
[52]
Lei, S., Li, Y., Ma, Z., Zhang, H., and Tang, M. (2025). Identification of the governing equation of stimulus-response data for run-and-tumble dynamics. PLOS Computational Biology , 21(8):e1013287
2025
-
[53]
A., and Darrell, T
Pathak, D., Agrawal, P., Efros, A. A., and Darrell, T. (2017). Curiosity-driven exploration by self-supervised prediction. In 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pages 488--489
2017
-
[54]
P., and Goldstein, R
Polin, M., Tuval, I., Drescher, K., Gollub, J. P., and Goldstein, R. E. (2009). Chlamydomonas swims with two “gears” in a eukaryotic version of run-and-tumble locomotion. Science , 325(5939):487--490
2009
-
[55]
E., and Gopalkrishnan, M
Poole, W., Ouldridge, T. E., and Gopalkrishnan, M. (2025). Autonomous learning of generative models with chemical reaction network ensembles. Journal of The Royal Society Interface , 22(222):20240373
2025
-
[56]
Pramanik, R., Mishra, S., and Chatterjee, S. (2025). Run-and-tumble chemotaxis using reinforcement learning. Physical Review E , 111(1):014106
2025
-
[57]
Tindall, M., Porter, S., Maini, P., Gaglia, G., and Armitage, J. (2008). Overview of mathematical approaches used to model bacterial chemotaxis i: The single cell. Bulletin of mathematical biology , 70:1525--69
2008
-
[58]
Tsallis, C. (1998). Generalized entropy-based criterion for consistent testing. Phys. Rev. E , 58:1442--1445
1998
-
[59]
K., and Buckley, C
Tschantz, A., Seth, A. K., and Buckley, C. L. (2020). Learning action-oriented models through active inference. PLoS computational biology , 16(4):e1007805
2020
-
[60]
Vila, M., Bardera, A., Feixas, M., and Sbert, M. (2011). Tsallis mutual information for document classification. Entropy , 13(9):1694--1707
2011
-
[61]
Wiuf, C., Behera, A., Singh, A., and Gopalkrishnan, M. (2023). A reaction network scheme for hidden markov model parameter learning. Journal of The Royal Society Interface , 20(203):20220877
2023
-
[62]
D., Maas, A., Bagnell, J
Ziebart, B. D., Maas, A., Bagnell, J. A., and Dey, A. K. (2008). Maximum entropy inverse reinforcement learning. In Proc. AAAI , pages 1433--1438
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.