MPC-Injection: Biasing Off-Policy Locomotion RL Toward Controller-Induced Behavior Basins
Pith reviewed 2026-06-26 01:32 UTC · model grok-4.3
The pith
MPC-Injection steers off-policy RL locomotion policies into controller-preferred behavior basins by injecting MPC transitions into the replay buffer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
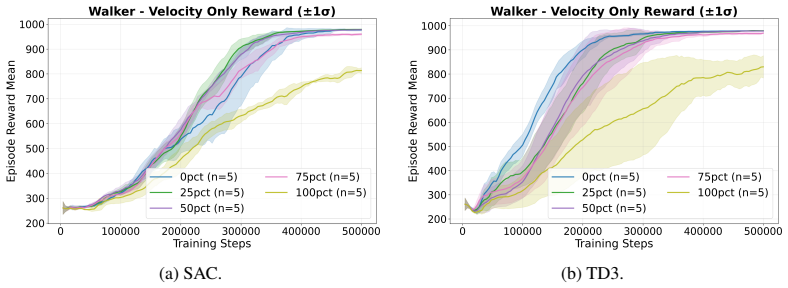
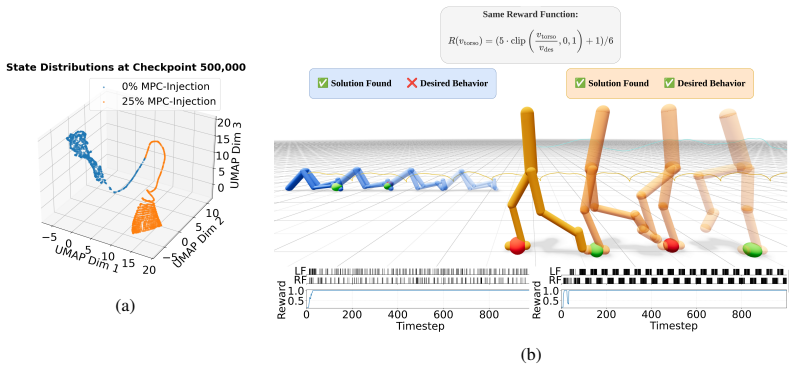
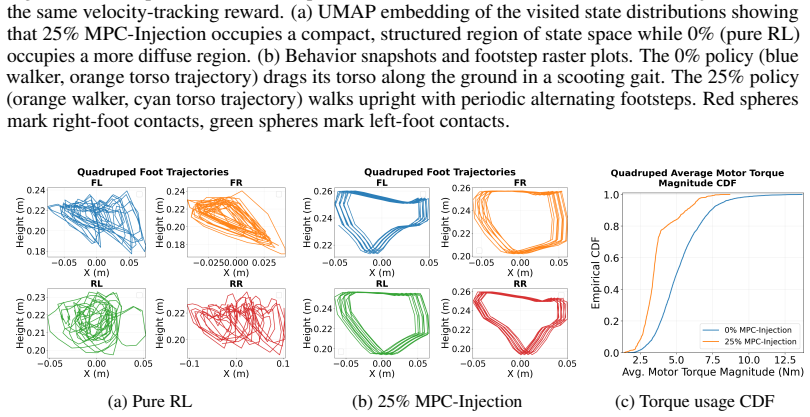
By inserting transitions from an MPC controller into the off-policy RL replay buffer, the method biases actor-critic updates toward states visited by the controller, allowing the policy to reach desirable gaits even under one- or two-term task rewards that would otherwise lead to degenerate behaviors.
What carries the argument
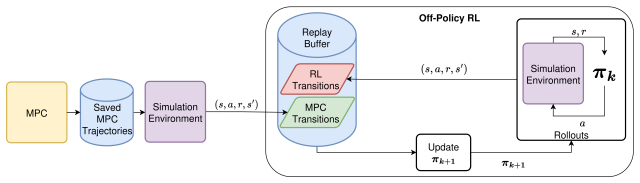
MPC-Injection, the direct insertion of MPC-generated transitions into the RL replay buffer to shift the replay state distribution toward the controller's behavior basin.
If this is right
- Policies reach usable gaits with rewards containing only one or two terms rather than twenty-one tuned terms.
- No discriminator, kinematic retargeting, or auxiliary objective is required, unlike adversarial motion priors.
- The bias works on a 2D walker in simulation and transfers to a real Go2 quadruped.
- Actor-critic updates become directed toward controller-visited states that pure RL may not reach under simple rewards.
Where Pith is reading between the lines
- The injection technique could reduce reliance on reward engineering in other off-policy RL control tasks where an approximate solver exists.
- Varying the fraction or timing of injected transitions might allow tuning the strength of the bias versus exploration.
- The approach may combine with existing basin-escaping methods to handle cases where the MPC itself is imperfect.
Load-bearing premise
Transitions from the MPC controller can be inserted into the RL replay buffer without introducing harmful distribution shift or instability in the actor-critic updates.
What would settle it
A trial in which the policy trained with MPC-Injection under the one- or two-term reward produces gaits no better than pure RL or diverges due to the injected transitions.
Figures


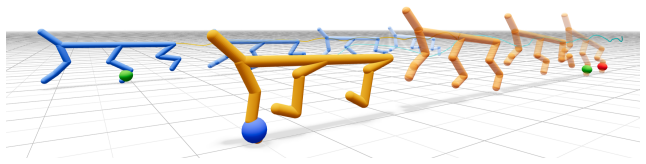

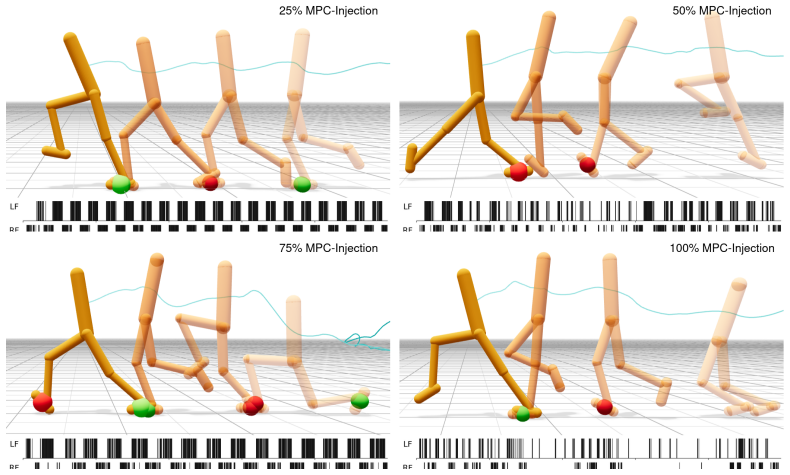
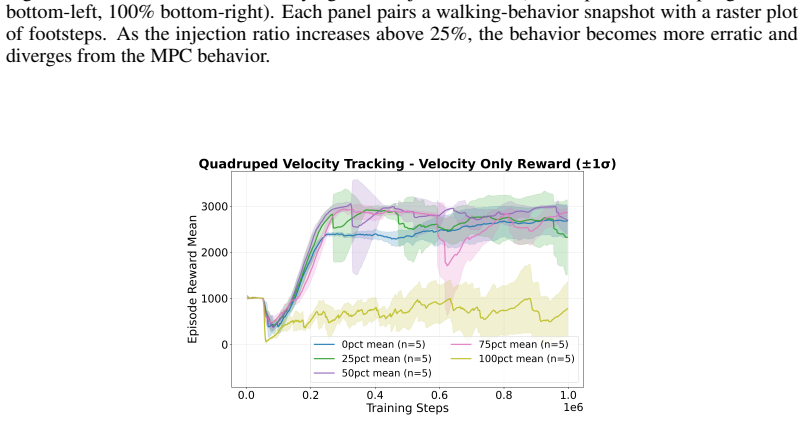
read the original abstract
Reinforcement learning (RL) for locomotion frequently converges to locally optimal but undeployable behaviors, such as vibrating limbs or scooting on the torso, that maximize return without producing a usable gait. We present MPC-Injection, a low-overhead method that steers RL toward a designer-preferred gait by inserting transitions into the replay buffer from a model predictive controller solving the same Markov decision process. Unlike reward shaping, MPC-Injection does not require redesigning the task reward, and unlike adversarial imitation learning, it adds no discriminator, no kinematic retargeting, and no auxiliary objective. Instead, the controller's preferred behavior is transferred to the policy purely through the replay state distribution. On a 2D walker in simulation and with sim-to-real evaluation on a Go2 quadruped, we show that MPC-Injection drives the policy into the controller's behavior basin using a one to two-term task reward, producing gaits qualitatively comparable to those of reward shaping with twenty-one tuned terms and of adversarial motion priors without their discriminator and retargeting overhead. We further analyze how the injected transitions bias actor-critic updates toward controller-visited states, allowing the policy to learn behaviors that pure RL may fail to reach under simple reward functions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MPC-Injection, a low-overhead technique that inserts transitions generated by an MPC controller (solving the same MDP) into the replay buffer of an off-policy actor-critic RL algorithm for locomotion. This biases the policy toward the controller-induced behavior basin, enabling usable gaits with only one- or two-term task rewards. Qualitative results are reported on a 2D walker in simulation and sim-to-real transfer on a Unitree Go2 quadruped, with an accompanying analysis of how the injected transitions affect actor-critic updates; the method is contrasted with reward shaping (21 terms) and adversarial motion priors (discriminator + retargeting).
Significance. If the central claim is supported, the approach provides a practical alternative for steering RL locomotion policies without reward redesign or auxiliary objectives, potentially lowering engineering overhead while leveraging existing MPC solutions. The replay-buffer biasing perspective and analysis of state-distribution effects on updates contribute a distinct angle on navigating behavior basins in off-policy RL.
major comments (2)
- Abstract: the central claim that MPC-Injection produces gaits 'qualitatively comparable' to reward shaping and AMP rests on qualitative descriptions alone; no quantitative metrics, ablation studies, success rates, or error bars are supplied, leaving the empirical support for the claim difficult to evaluate.
- Method description (MPC transition insertion): the load-bearing assumption that MPC-generated transitions can be inserted directly into the off-policy replay buffer without harmful distribution shift is not addressed; the paper provides no analysis or experiments quantifying alignment between the MPC (approximate model, receding horizon) and true simulator dynamics distributions or demonstrating stability of the resulting Q-targets under the minimal reward.
minor comments (1)
- Abstract: the phrasing 'one to two-term task reward' would benefit from an explicit example of the reward terms employed in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of MPC-Injection as a low-overhead alternative. We address each major comment below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the central claim that MPC-Injection produces gaits 'qualitatively comparable' to reward shaping and AMP rests on qualitative descriptions alone; no quantitative metrics, ablation studies, success rates, or error bars are supplied, leaving the empirical support for the claim difficult to evaluate.
Authors: We agree that the empirical support would be strengthened by quantitative evidence. In the revision we will add metrics including average episode return, forward velocity tracking error, and a gait stability score (e.g., torso height variance) computed over 5–10 random seeds with error bars. We will also include an ablation on the fraction of injected transitions and report success rates (fraction of runs that produce a stable forward gait) for all methods under the minimal reward. revision: yes
-
Referee: Method description (MPC transition insertion): the load-bearing assumption that MPC-generated transitions can be inserted directly into the off-policy replay buffer without harmful distribution shift is not addressed; the paper provides no analysis or experiments quantifying alignment between the MPC (approximate model, receding horizon) and true simulator dynamics distributions or demonstrating stability of the Q-targets under the minimal reward.
Authors: The manuscript already contains an analysis of how injected transitions bias the actor and critic updates toward controller-visited states. However, we acknowledge the need for explicit quantification of distribution shift and Q-target stability. In revision we will add (i) a comparison of state-visitation distributions (e.g., via Wasserstein distance or KL divergence on key state variables) between pure MPC rollouts and the mixed replay buffer, and (ii) plots of Q-target variance and temporal-difference error on held-out states when training with versus without injection under the one- or two-term reward. revision: yes
Circularity Check
No significant circularity; empirical method with external MPC input
full rationale
The paper describes MPC-Injection as an empirical technique that inserts transitions generated by an external MPC controller (solving the same MDP) directly into the off-policy replay buffer to bias actor-critic updates. No derivation chain, equations, or self-citations are present in the provided text that reduce any claim to a self-definition, fitted input renamed as prediction, or load-bearing self-citation. The central claim is framed as an experimental outcome validated on 2D walker simulation and Go2 hardware, relying on standard RL components rather than internal equivalence by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. M¨uller, E. Knoop, D. Mylonopoulos, A. Serifi, M. A. Hopkins, R. Grandia, and M. B¨acher. Olaf: Bringing an Animated Character to Life in the Physical World, Dec. 2025. URL http: //arxiv.org/abs/2512.16705. arXiv:2512.16705 [cs]
arXiv 2025
-
[2]
Y . Liang, Z. Peng, Y . Zhao, and W. Yan. Learning robust bipedal running via structured gait and trajectory guidance.Robotica, pages 1–19, Jan. 2026. ISSN 0263-5747, 1469-8668. doi:10.1017/S0263574725103007. URL https://www.cambridge.org/core/product/ identifier/S0263574725103007/type/journal_article
-
[3]
H. Xue, T. He, Z. Wang, Q. Ben, W. Xiao, Z. Luo, X. Da, F. Casta˜neda, G. Shi, S. Sastry, L. J. Fan, and Y . Zhu. Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer, Nov. 2025. URLhttp://arxiv.org/abs/2512.01061. arXiv:2512.01061 [cs]
arXiv 2025
-
[4]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control.ACM Transactions on Graphics, 40 (4):1–20, Aug. 2021. ISSN 0730-0301, 1557-7368. doi:10.1145/3450626.3459670. URL http://arxiv.org/abs/2104.02180. arXiv:2104.02180 [cs]
-
[5]
C. Li, M. Vlastelica, S. Blaes, J. Frey, F. Grimminger, and G. Martius. Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations, Nov. 2022. URL http: //arxiv.org/abs/2206.11693. arXiv:2206.11693 [cs]
arXiv 2022
-
[6]
S. Zhao, Y . Ze, Y . Wang, C. K. Liu, P. Abbeel, G. Shi, and R. Duan. ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning, Oct
- [7]
-
[8]
Y . Ze, Z. Chen, J. P. Ara´ujo, Z.-a. Cao, X. B. Peng, J. Wu, and C. K. Liu. TWIST: Teleoperated Whole-Body Imitation System, May 2025. URL http://arxiv.org/abs/2505.02833. arXiv:2505.02833 [cs]
arXiv 2025
-
[9]
Dawood, N
M. Dawood, N. Dengler, J. De Heuvel, and M. Bennewitz. Handling Sparse Rewards in Reinforcement Learning Using Model Predictive Control. In2023 IEEE International Con- ference on Robotics and Automation (ICRA), pages 879–885, London, United Kingdom, May
-
[10]
IEEE. ISBN 979-8-3503-2365-8. doi:10.1109/ICRA48891.2023.10161492. URL https://ieeexplore.ieee.org/document/10161492/
-
[11]
J. Shin, A. Hakobyan, M. Park, Y . Kim, G. Kim, and I. Yang. Infusing model predictive control into meta-reinforcement learning for mobile robots in dynamic environments.IEEE Robotics and Automation Letters, 7(4):10065–10072, Oct. 2022. ISSN 2377-3766, 2377-3774. doi:10. 1109/LRA.2022.3191234. URL http://arxiv.org/abs/2109.07120. arXiv:2109.07120 [cs]
arXiv 2022
-
[12]
J. Br¨udigam, A.-A. Abbas, M. Sorokin, K. Fang, B. Hung, M. Guru, S. Sosnowski, J. Wang, S. Hirche, and S. L. Cleac’h. Jacta: A Versatile Planner for Learning Dexterous and Whole-body Manipulation, Oct. 2024. URL http://arxiv.org/abs/2408.01258. arXiv:2408.01258 [cs]
arXiv 2024
-
[13]
A. D. Laud.Theory and application of reward shaping in reinforcement learning. PhD Thesis, University of Illinois at Urbana-Champaign, USA, 2004
2004
-
[14]
A. Y . Ng, D. Harada, and S. J. Russell. Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping. InProceedings of the Sixteenth International Conference on Machine Learning, ICML ’99, pages 278–287, San Francisco, CA, USA, 1999. Morgan Kaufmann Publishers Inc. ISBN 1-55860-612-2. 9
1999
-
[15]
S. H. Jeon, S. Heim, C. Khazoom, and S. Kim. Benchmarking Potential Based Rewards for Learning Humanoid Locomotion. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9204–9210, May 2023. doi:10.1109/ICRA48891.2023.10160885. URLhttp://arxiv.org/abs/2307.10142. arXiv:2307.10142 [cs]
-
[16]
A. Malysheva, D. Kudenko, and A. Shpilman. Learning to Run with Potential-Based Reward Shaping and Demonstrations from Video Data. In2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), pages 286–291, Nov. 2018. doi:10.1109/ ICARCV .2018.8581310. URL http://arxiv.org/abs/2012.08824. arXiv:2012.08824 [cs]
arXiv 2018
-
[17]
A. Harutyunyan, S. Devlin, P. Vrancx, and A. Nowe. Expressing Arbitrary Reward Functions as Potential-Based Advice.Proceedings of the AAAI Conference on Artificial Intelligence, 29(1), Feb. 2015. ISSN 2374-3468, 2159-5399. doi:10.1609/aaai.v29i1.9628. URL https: //ojs.aaai.org/index.php/AAAI/article/view/9628
-
[18]
T. Westenbroek, F. Castaneda, A. Agrawal, S. Sastry, and K. Sreenath. Lyapunov Design for Robust and Efficient Robotic Reinforcement Learning. In6th Conference on Robot Learning (CoRL 2022), Auckland, New Zealand, Nov. 2022. doi:10.48550/arXiv.2208.06721. URL http://arxiv.org/abs/2208.06721. arXiv:2208.06721 [cs]
-
[19]
G. Kim, Y .-H. Lee, and H.-W. Park. A Learning Framework for Diverse Legged Robot Locomotion Using Barrier-Based Style Rewards. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 10004–10010, Atlanta, GA, USA, May 2025. IEEE. ISBN 979-8-3315-4139-2. doi:10.1109/ICRA55743.2025.11128517. URL https: //ieeexplore.ieee.org/document/11128517/
-
[20]
Y . Kim, H. Oh, J. Lee, J. Choi, G. Ji, M. Jung, D. Youm, and J. Hwangbo. Not Only Rewards but Also Constraints: Applications on Legged Robot Locomotion.IEEE Transactions on Robotics, 40:2984–3003, 2024. ISSN 1552-3098, 1941-0468. doi:10.1109/TRO.2024.3400935. URL https://ieeexplore.ieee.org/document/10530429/
-
[21]
L. Yang, B. Werner, M. d. Sa, and A. D. Ames. CBF-RL: Safety Filtering Reinforcement Learning in Training with Control Barrier Functions, Oct. 2025. URL http://arxiv.org/ abs/2510.14959. arXiv:2510.14959 [cs]
Pith/arXiv arXiv 2025
-
[22]
G. Ji, J. Mun, H. Kim, and J. Hwangbo. Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion.IEEE Robotics and Automation Letters, 7(2):4630–4637, Apr. 2022. ISSN 2377-3766, 2377-3774. doi:10.1109/LRA.2022.3151396. URLhttp://arxiv.org/abs/2202.05481. arXiv:2202.05481 [cs]
-
[23]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning. InProceedings of the 5th Conference on Robot Learn- ing, pages 91–100. PMLR, Jan. 2022. URL https://proceedings.mlr.press/v164/ rudin22a.html. ISSN: 2640-3498
2022
-
[24]
J. Siekmann, Y . Godse, A. Fern, and J. Hurst. Sim-to-Real Learning of All Common Bipedal Gaits via Periodic Reward Composition. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 7309–7315, Xi’an, China, May 2021. IEEE. ISBN 978-1-7281- 9077-8. doi:10.1109/ICRA48506.2021.9561814. URL https://ieeexplore.ieee.org/ document/9561814/
-
[25]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning Quadrupedal Lo- comotion over Challenging Terrain.Science Robotics, 5(47):eabc5986, Oct. 2020. ISSN 2470-9476. doi:10.1126/scirobotics.abc5986. URL http://arxiv.org/abs/2010.11251. arXiv:2010.11251 [cs]. 10
-
[26]
A. Escontrela, X. B. Peng, W. Yu, T. Zhang, A. Iscen, K. Goldberg, and P. Abbeel. Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 25–32, Kyoto, Japan, Oct. 2022. IEEE. ISBN 978-1-6654-7927-1. doi:10.1109/IROS47612.2022.9981973. URL https:...
-
[27]
N. Pollard, J. Hodgins, M. Riley, and C. Atkeson. Adapting human motion for the control of a humanoid robot. InProceedings 2002 IEEE International Conference on Robotics and Automation (Cat. No.02CH37292), volume 2, pages 1390–1397 vol.2, May 2002. doi:10.1109/ ROBOT.2002.1014737. URLhttps://ieeexplore.ieee.org/document/1014737/
arXiv 2002
-
[28]
D. Grimes, R. Chalodhorn, and R. Rao. Dynamic Imitation in a Humanoid Robot through Nonparametric Probabilistic Inference. InRobotics: Science and Systems II. Robotics: Science and Systems Foundation, Aug. 2006. ISBN 978-0-262-69348-6. doi:10.15607/RSS.2006.II.026. URLhttp://www.roboticsproceedings.org/rss02/p26.pdf
-
[29]
V . Kurtz and J. W. Burdick. Generative Predictive Control: Flow Matching Policies for Dynamic and Difficult-to-Demonstrate Tasks, May 2025. URL http://arxiv.org/abs/2502.13406. arXiv:2502.13406 [cs]
arXiv 2025
-
[30]
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang. GMT: General Motion Tracking for Humanoid Whole-Body Control, Sept. 2025. URLhttp://arxiv.org/abs/2506.14770. arXiv:2506.14770 [cs]
arXiv 2025
-
[31]
Y . Fuchioka, Z. Xie, and M. Van De Panne. OPT-Mimic: Imitation of Optimized Trajectories for Dynamic Quadruped Behaviors. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5092–5098, London, United Kingdom, May 2023. IEEE. ISBN 979-8-3503-2365-8. doi:10.1109/ICRA48891.2023.10160562. URL https://ieeexplore. ieee.org/document/10160562/
-
[32]
Code as policies: Language model programs for embodied control
A. George, A. Bartsch, and A. B. Farimani. Minimizing Human Assistance: Augmenting a Sin- gle Demonstration for Deep Reinforcement Learning. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5027–5033, May 2023. doi:10.1109/ICRA48891. 2023.10161119. URLhttps://ieeexplore.ieee.org/document/10161119/
-
[33]
M. Vecerik, T. Hester, J. Scholz, F. Wang, O. Pietquin, B. Piot, N. Heess, T. Roth¨orl, T. Lampe, and M. Riedmiller. Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards, Oct. 2018. URL http://arxiv.org/abs/1707.08817. arXiv:1707.08817 [cs]
Pith/arXiv arXiv 2018
-
[34]
A. Nair, B. McGrew, M. Andrychowicz, W. Zaremba, and P. Abbeel. Overcoming Exploration in Reinforcement Learning with Demonstrations. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6292–6299, May 2018. doi:10.1109/ICRA.2018. 8463162. URL https://ieeexplore.ieee.org/document/8463162/. ISSN: 2577-087X
-
[35]
H. Zhou, X. Zhang, and V . Tzoumas. Adaptive Legged Locomotion via Online Learning for Model Predictive Control.IEEE Robotics and Automation Letters, 11(2):1778–1785, Feb. 2026. ISSN 2377-3766. doi:10.1109/LRA.2025.3644161. URL https://ieeexplore.ieee.org/ document/11299577/
-
[36]
J. Cheng, D. Kang, G. Fadini, G. Shi, and S. Coros. Rambo: RL-Augmented Model-Based Whole-Body Control for Loco-Manipulation.IEEE Robotics and Automation Letters, 10(9): 9462–9469, Sept. 2025. ISSN 2377-3766, 2377-3774. doi:10.1109/LRA.2025.3594984. URL https://ieeexplore.ieee.org/document/11106746/
-
[37]
S. H. Jeon, H. J. Lee, S. Hong, and S. Kim. Residual MPC: Blending Reinforcement Learning with GPU-Parallelized Model Predictive Control, Oct. 2025. URL http://arxiv.org/abs/ 2510.12717. arXiv:2510.12717 [cs]. 11
arXiv 2025
-
[38]
M. Bogdanovic, M. Khadiv, and L. Righetti. Model-free reinforcement learning for robust locomotion using demonstrations from trajectory optimization.Frontiers in Robotics and AI, 9:854212, Aug. 2022. ISSN 2296-9144. doi:10.3389/frobt.2022.854212. URL https: //www.frontiersin.org/articles/10.3389/frobt.2022.854212/full
-
[39]
J. Carius, F. Farshidian, and M. Hutter. MPC-Net: A First Principles Guided Policy Search. IEEE Robotics and Automation Letters, 5(2):2897–2904, Apr. 2020. ISSN 2377-3766, 2377-3774. doi:10.1109/LRA.2020.2974653. URL http://arxiv.org/abs/1909.05197. arXiv:1909.05197 [cs]
-
[40]
Levine and V
S. Levine and V . Koltun. Guided policy search. In S. Dasgupta and D. McAllester, editors,Pro- ceedings of the 30th International Conference on Machine Learning, volume 28 ofProceedings of Machine Learning Research, pages 1–9, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR. URLhttps://proceedings.mlr.press/v28/levine13.html
2013
-
[41]
B. Amos, I. D. J. Rodriguez, J. Sacks, B. Boots, and J. Z. Kolter. Differentiable MPC for End-to-end Planning and Control, Oct. 2019. URL http://arxiv.org/abs/1810.13400. arXiv:1810.13400 [cs]
arXiv 2019
- [42]
-
[43]
R. Reiter, J. Hoffmann, D. Reinhardt, F. Messerer, K. Baumg¨artner, S. Sawant, J. B ¨odecker, M. Diehl, and S. Gros. Synthesis of model predictive control and reinforcement learning: Survey and classification.Annual Reviews in Control, 61:101045, 2026. ISSN 13675788. doi: 10.1016/j.arcontrol.2026.101045. URL https://linkinghub.elsevier.com/retrieve/ pii/S...
-
[44]
T. Howell, N. Gileadi, S. Tunyasuvunakool, K. Zakka, T. Erez, and Y . Tassa. Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo. Dec 2022. doi:10.48550/arXiv.2212. 00541. URLhttps://arxiv.org/abs/2212.00541
-
[45]
L. Amatucci, J. Sousa-Pinto, G. Turrisi, D. Orban, V . Barasuol, and C. Semini. Primal-Dual iLQR for GPU-Accelerated Learning and Control in Legged Robots.IEEE Robotics and Automation Letters, 11(1):1010–1017, Jan. 2026. ISSN 2377-3766, 2377-3774. doi:10.1109/ LRA.2025.3632610. URLhttps://ieeexplore.ieee.org/document/11248841/
arXiv 2026
-
[46]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In J. Dy and A. Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1861–1870. PMLR, 2018. URL https://proceedings. ...
2018
-
[47]
Fujimoto, H
S. Fujimoto, H. van Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. In J. Dy and A. Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1587–1596. PMLR, 2018. URLhttps://proceedings.mlr.press/v80/fujimoto18a.html
2018
-
[48]
Y . Tassa, Y . Doron, A. Muldal, T. Erez, Y . Li, D. de Las Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, T. Lillicrap, and M. Riedmiller. Deepmind control suite, 2018. URL https://arxiv.org/abs/1801.00690
Pith/arXiv arXiv 2018
-
[49]
Unitree Go2
Unitree Robotics. Unitree Go2. https://www.unitree.com/go2/. Product page. Accessed: 2026-05-17
2026
-
[50]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE,
-
[51]
doi:10.1109/IROS.2012.6386109. 12
-
[52]
Unitree RL mjlab
Unitree Robotics. Unitree RL mjlab. https://github.com/unitreerobotics/unitree_ rl_mjlab, 2026. GitHub repository. Accessed: 2026-05-15
2026
-
[53]
G. Kim, D. Kang, J.-H. Kim, S. Hong, and H.-W. Park. Contact-implicit model predictive control: Controlling diverse quadruped motions without pre-planned contact modes or trajectories. The International Journal of Robotics Research, 44(3):486–510, Mar. 2025. doi:10.1177/ 02783649241273645. URLhttps://doi.org/10.1177/02783649241273645
-
[54]
A. Du, E. Adabag, G. Bravo Palacios, and B. Plancher. Gato: Gpu-accelerated and batched trajectory optimization for scalable edge model predictive control. In2026 IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[55]
ConceptGraphs: Open-vocabulary 3d scene graphs for perception and planning,
K. Nguyen, S. Schoedel, A. Alavilli, B. Plancher, and Z. Manchester. Tinympc: Model- predictive control on resource-constrained microcontrollers. In2024 IEEE International Con- ference on Robotics and Automation (ICRA), 2024. doi:10.1109/ICRA57147.2024.10610987. URLhttps://doi.org/10.1109/ICRA57147.2024.10610987
-
[56]
F. Schramm, P. Fabre, N. Perrin-Gilbert, and J. Carpentier. Reference-Free Sampling- Based Model Predictive Control, Nov. 2025. URL http://arxiv.org/abs/2511.19204. arXiv:2511.19204 [cs]
Pith/arXiv arXiv 2025
-
[57]
∞X k=0 γkl(Sk, Ak)|S 0 =s # (4) and the action-value function Qπ(s, a) :=E
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann. Stable-baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research, 22 (268):1–8, 2021. URLhttp://jmlr.org/papers/v22/20-1364.html. A Problem Statement This section introduces the two main theoretical components of MPC-Injection, the MPC control...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.