Humans Disengage, Reasoning Models Persist: Separating Difficulty Registration from Deliberation Allocation
Pith reviewed 2026-06-26 05:33 UTC · model grok-4.3
The pith
Humans spend less time on problems they fail while large reasoning models spend more, even though both track difficulty across problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
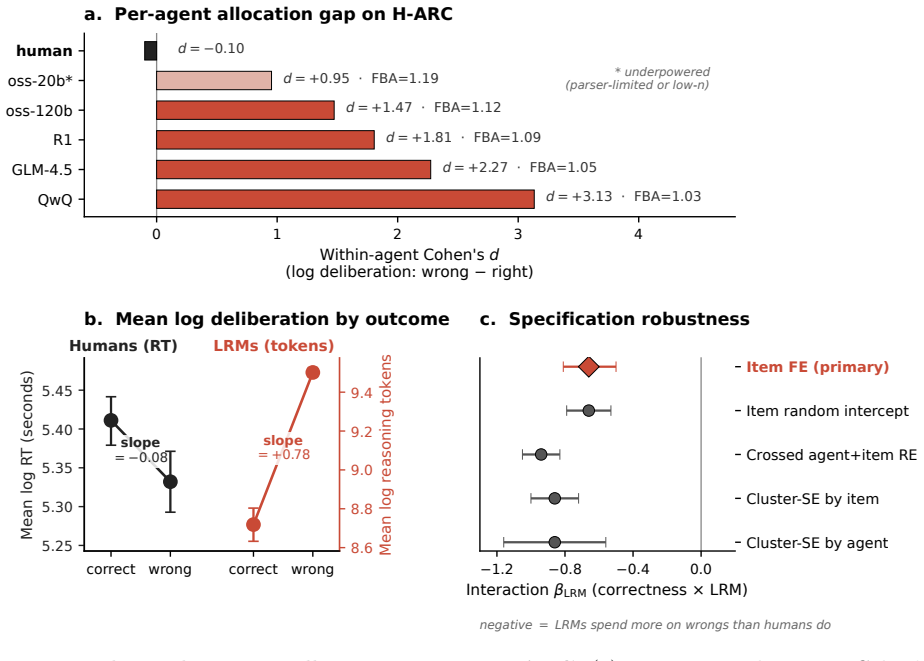
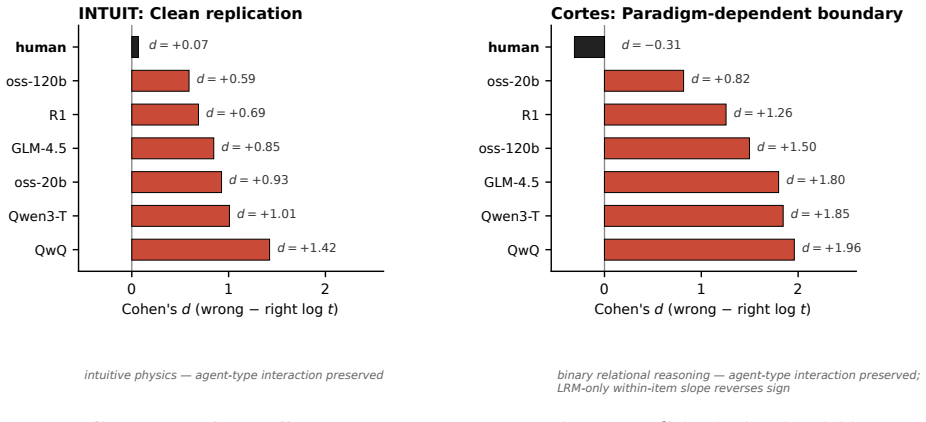
On a public matched human-LRM corpus, humans and all five thinking LRMs reproduce the known cross-item alignment between deliberation effort and difficulty but diverge within items: every LRM shows a large wrong-versus-right effect while humans show the opposite sign. The comparison stays inside each agent's own scale and holds under item fixed effects.
What carries the argument
Item fixed-effects analysis that isolates within-item allocation (wrong-vs-right difference) from between-item registration (cross-item correlation with difficulty).
If this is right
- The same cross-item correlation can arise from opposite within-item stopping policies.
- Trace length in LRMs tracks uncertainty but not the control decision to persist or abandon.
- Under resource-rational metareasoning the split is between two stopping policies that share a difficulty signal but implement opposite control.
- The dissociation is absent in non-thinking baselines and replicates across datasets.
Where Pith is reading between the lines
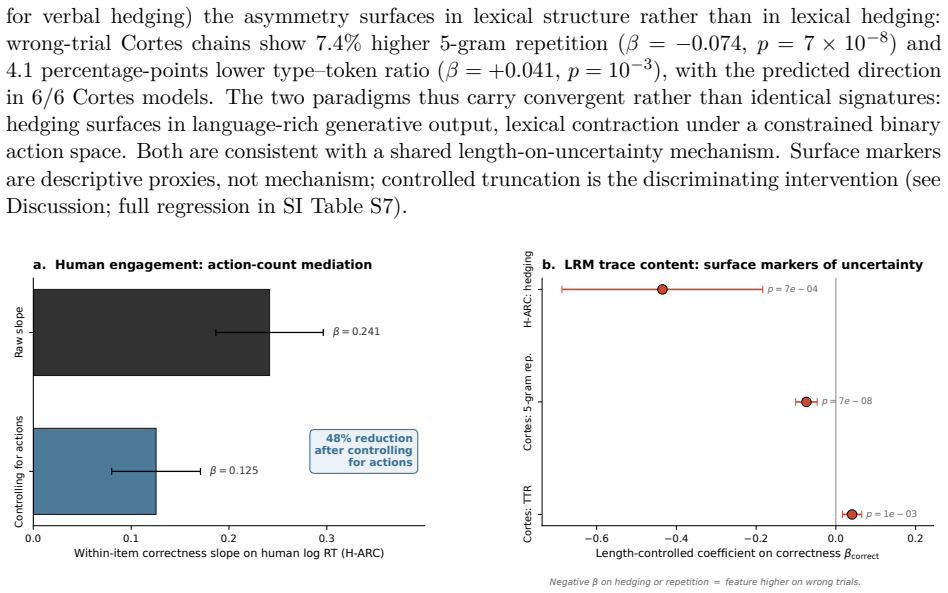
- Models may lack an explicit mechanism for abandoning items they expect to fail, leading to longer traces precisely on errors.
- Training objectives that reward human-like disengagement on low-success items could reduce unnecessary computation.
- The registration-allocation split offers a new diagnostic for comparing metacognitive policies across agents.
Load-bearing premise
The matched human-LRM corpus and item fixed-effects analysis successfully isolate within-item allocation from between-item difficulty differences without residual confounding from problem selection or measurement scale differences.
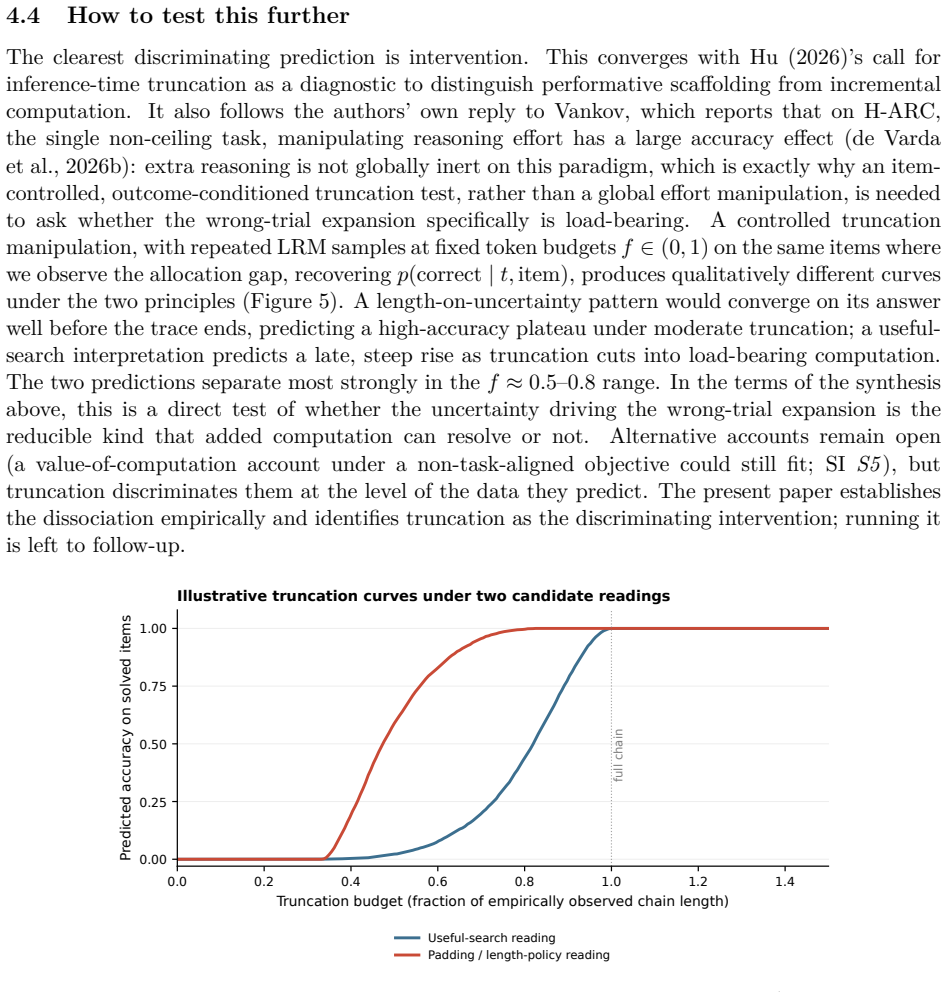
What would settle it
A replication on a new matched corpus or with an alternative matching procedure that eliminates the within-item wrong-versus-right reversal between humans and LRMs.
Figures

read the original abstract
Large reasoning models (LRMs) take longer on harder problems, just as humans do. This surface similarity hides an opposite pattern within items. When an LRM gets a problem wrong, it spends more tokens than when it gets the same problem right; humans do the reverse, spending less time on the trials they get wrong. We separate two levels of deliberation: how response time tracks difficulty across items (registration), and, with item identity held fixed, whether an agent spends more on its own failures or successes (allocation). On a public matched human-LRM corpus, humans and all five thinking LRMs reproduce the known cross-item alignment (registration) but diverge within items (allocation): every LRM shows a large wrong-vs-right effect (Cohen's d = 1.47-3.13 on H-ARC) while humans show the opposite sign. The comparison stays inside each agent's own scale; we never put seconds and tokens on one axis. The dissociation holds under item fixed effects, replicates across datasets, and is absent in a non-thinking baseline. We read the human pattern as engagement versus abandonment: people stay on items they expect to solve and give up on the rest. We read the LRM pattern as length driven by uncertainty: chains grow when the model is unsure, which is exactly when it tends to fail. Both policies produce the same cross-item correlation with difficulty, so they look aligned on the measure prior work has used; the divergence shows up only once item identity is fixed. Under resource-rational metareasoning, the split is between two stopping policies that share a difficulty signal but implement opposite control; trace length captures the signal and misses the control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that humans and large reasoning models (LRMs) both exhibit positive cross-item registration of deliberation effort with problem difficulty, but diverge sharply in within-item allocation: LRMs expend more tokens on items they answer incorrectly (Cohen's d = 1.47–3.13), while humans expend less time on items they get wrong. This dissociation is reported to survive item fixed-effects regression, replicate across datasets, and be absent in a non-thinking baseline; the authors interpret it as humans engaging on solvable items versus abandoning the rest, versus LRMs lengthening chains under uncertainty.
Significance. If the dissociation holds, the work usefully separates registration from allocation in metareasoning and shows that the same cross-item correlation can arise from opposite stopping policies. Credit is due for the public matched corpus, item fixed-effects controls, replication across datasets, and explicit non-thinking baseline, all of which address obvious confounds and keep comparisons within each agent's native scale.
minor comments (2)
- The abstract and methods should explicitly state the exact number of items per dataset, the precise matching procedure used to create the human-LRM corpus, and the full specification of the item fixed-effects regression (including any additional covariates) so that readers can directly verify isolation of within-item allocation.
- Figure or table reporting the per-LRM Cohen's d values and human effect size should include confidence intervals and exact sample sizes per cell to allow assessment of precision.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were listed in the report, so we have no points requiring point-by-point response or manuscript changes.
Circularity Check
No significant circularity: purely empirical comparison
full rationale
The paper reports an empirical dissociation between cross-item registration and within-item allocation using a public matched human-LRM corpus, item fixed-effects regression, and Cohen's d effect sizes computed separately within each agent's native scale. No equations, derivations, or model fits are present; the central claims rest on direct statistical contrasts that survive the stated controls and replicate across datasets. No self-citations are load-bearing for the dissociation result, and the analysis introduces no self-definitional, fitted-input, or ansatz-smuggling steps. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying Cohen's d effect size and linear fixed-effects models hold for the response-time and token-count data.
Reference graph
Works this paper leans on
-
[1]
, title =
Lieder, Falk and Griffiths, Thomas L. , title =. Behavioral and Brain Sciences , volume =. 2020 , doi =
2020
-
[2]
Artificial Intelligence , volume =
Russell, Stuart and Wefald, Eric , title =. Artificial Intelligence , volume =. 1991 , doi =
1991
-
[3]
, title =
Bogacz, Rafal and Brown, Eric and Moehlis, Jeff and Holmes, Philip and Cohen, Jonathan D. , title =. Psychological Review , volume =. 2006 , doi =
2006
-
[4]
Proceedings of the National Academy of Sciences , volume =
de Varda, Andrea Gregor and D'Elia, Ferdinando Pio and Kean, Hope and Lampinen, Andrew and Fedorenko, Evelina , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =
2025
-
[5]
Proceedings of the National Academy of Sciences , volume =
de Varda, Andrea Gregor and D'Elia, Ferdinando Pio and Kean, Hope and Lampinen, Andrew and Fedorenko, Evelina , title =. Proceedings of the National Academy of Sciences , volume =. 2026 , doi =
2026
-
[6]
and Adolfi, Federico and Heaton, Rachel F
Vankov, Ivan I. and Adolfi, Federico and Heaton, Rachel F. and Puebla, Guillermo and Bowers, Jeffrey S. , title =. Proceedings of the National Academy of Sciences , volume =. 2026 , doi =
2026
-
[7]
Proceedings of the National Academy of Sciences , volume =
No deep insights into the alignment between human and deep learning reasoning processes:. Proceedings of the National Academy of Sciences , volume =. 2026 , doi =
2026
-
[8]
Proceedings of the National Academy of Sciences , volume =
Hu, Yueqing , title =. Proceedings of the National Academy of Sciences , volume =. 2026 , doi =
2026
-
[9]
and Gureckis, Todd M
LeGris, Solim and Vong, Wai Keen and Lake, Brenden M. and Gureckis, Todd M. , title =. Scientific Data , volume =. 2025 , doi =
2025
-
[10]
and O'Flynn, A
Prunty, J. and O'Flynn, A. and Quinn, P. and Cheke, L. G. , title =. 2025 , url =
2025
-
[11]
2021 , doi =
What Makes Mental Modeling Difficult? Normative Data for the Multidimensional Relational Reasoning Task , journal =. 2021 , doi =
2021
-
[12]
arXiv preprint arXiv:2412.19437 , year =
-
[13]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and others and Zhang, Zhen , title =. Nature , volume =. 2025 , doi =
2025
-
[14]
2025 , howpublished =
2025
-
[15]
arXiv preprint arXiv:2510.18176 , year =
Samineni, Soumya Rani and Kalwar, Durgesh and Gangal, Vardaan and Bhambri, Siddhant and Kambhampati, Subbarao , title =. arXiv preprint arXiv:2510.18176 , year =
-
[16]
2025 , doi =
Valmeekam, Karthik and Stechly, Kaya and Palod, Vardhan and Gundawar, Atharva and Kambhampati, Subbarao , title =. 2025 , doi =
2025
-
[17]
arXiv preprint arXiv:2504.09762 , year =
Kambhampati, Subbarao and Valmeekam, Karthik and Bhambri, Siddhant and Palod, Vardhan and Saldyt, Lucas Paul and Stechly, Kaya and Samineni, Soumya Rani and Kalwar, Durgesh and Biswas, Upasana , title =. arXiv preprint arXiv:2504.09762 , year =
-
[18]
Neural Computation , volume =
Ratcliff, Roger and McKoon, Gail , title =. Neural Computation , volume =. 2008 , doi =
2008
-
[19]
, title =
Heitz, Richard P. , title =. Frontiers in Neuroscience , volume =. 2014 , doi =
2014
-
[20]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. 2022 , doi =
2022
-
[21]
2022 , doi =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. 2022 , doi =
2022
-
[22]
2025 , doi =
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , title =. 2025 , doi =
2025
-
[23]
On the measure of intelligence , journal =
Chollet, Fran. On the measure of intelligence , journal =. 2019 , doi =
2019
-
[24]
and Narens, Louis , title =
Nelson, Thomas O. and Narens, Louis , title =. Psychology of Learning and Motivation , editor =. 1990 , doi =
1990
-
[25]
Philosophical Transactions of the Royal Society
Yeung, Nick and Summerfield, Christopher , title =. Philosophical Transactions of the Royal Society. 2012 , doi =
2012
-
[26]
, title =
Simon, Herbert A. , title =. Psychological Review , volume =. 1956 , doi =
1956
-
[27]
and Horvitz, Eric J
Gershman, Samuel J. and Horvitz, Eric J. and Tenenbaum, Joshua B. , title =. Science , volume =. 2015 , doi =
2015
-
[28]
, title =
Efron, Bradley and Tibshirani, Robert J. , title =. 1993 , isbn =
1993
-
[29]
Econometrica , volume =
Mundlak, Yair , title =. Econometrica , volume =. 1978 , doi =
1978
-
[30]
Rational use of cognitive resources in human planning , journal =
Callaway, Frederick and. Rational use of cognitive resources in human planning , journal =. 2022 , doi =
2022
-
[31]
Proceedings of the National Academy of Sciences , volume =
Binz, Marcel and Schulz, Eric , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , doi =
2023
-
[32]
and Leonesio, R
Nelson, Thomas O. and Leonesio, R. Jacob , title =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 1988 , doi =
1988
-
[33]
, title =
Zhu, Jian-Qiao and Griffiths, Thomas L. , title =. Psychological Review , year =
-
[34]
Structural Safety , volume =
Der Kiureghian, Armen and Ditlevsen, Ove , title =. Structural Safety , volume =. 2009 , doi =
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.