Robust Onion: Peeling Open Vocab Object Detectors Under Noise
Pith reviewed 2026-06-30 00:39 UTC · model grok-4.3
The pith
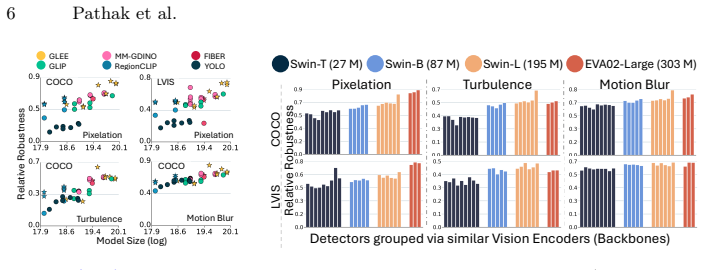
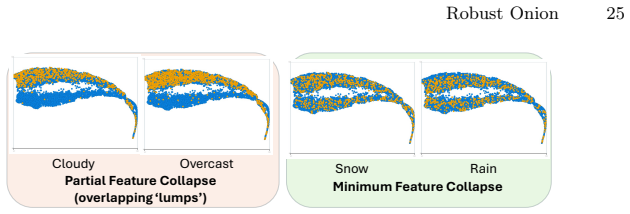
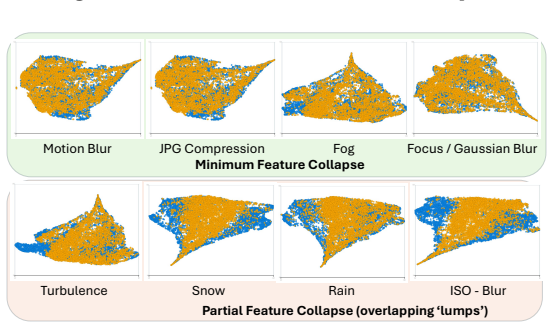
Open-vocabulary object detectors show comparable noise robustness when they share the same vision backbone because of feature collapse at matching layers.
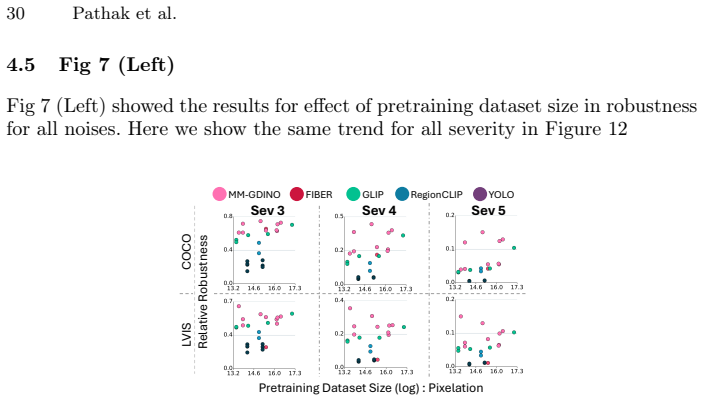
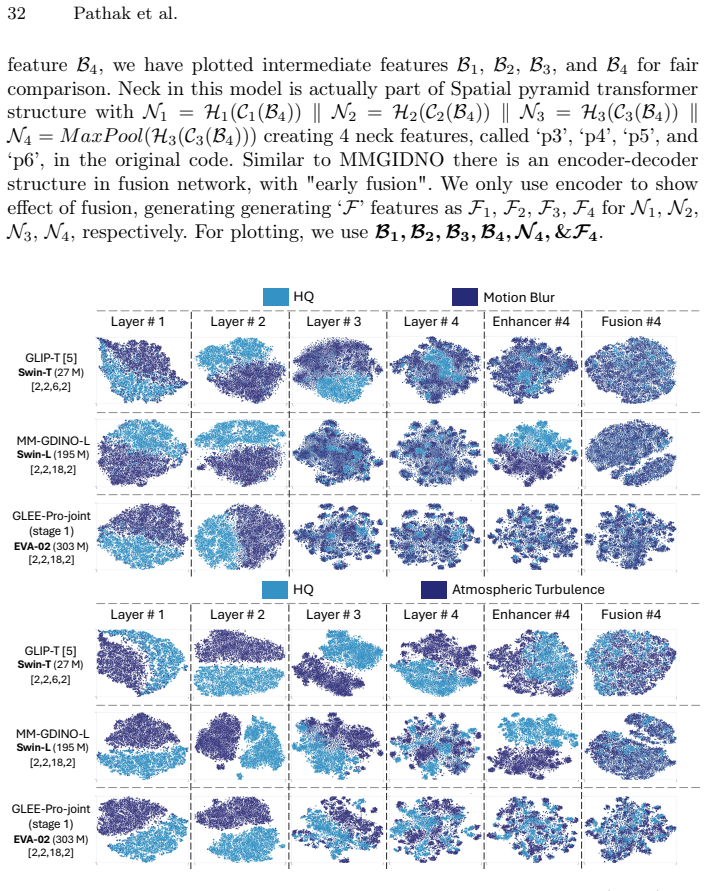
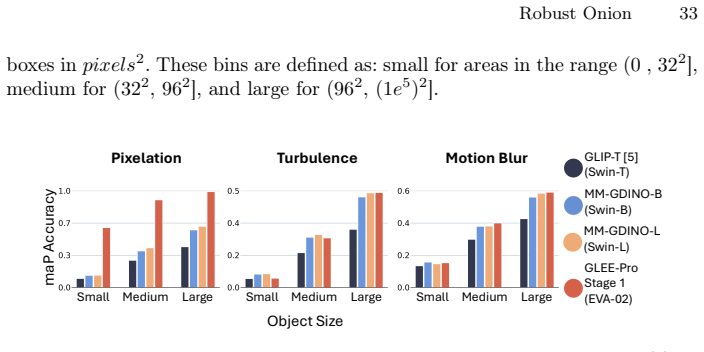
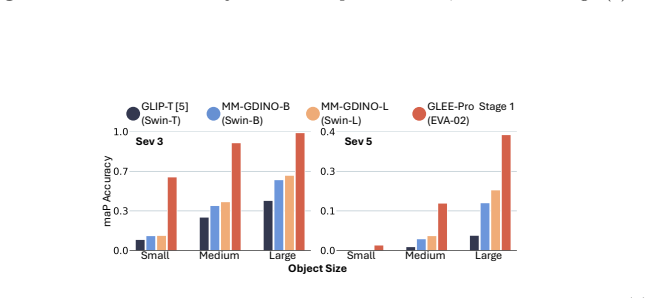
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
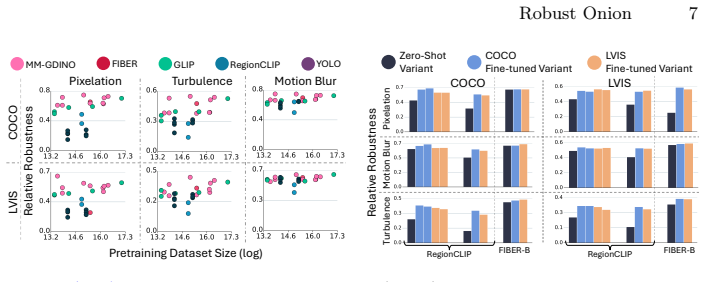
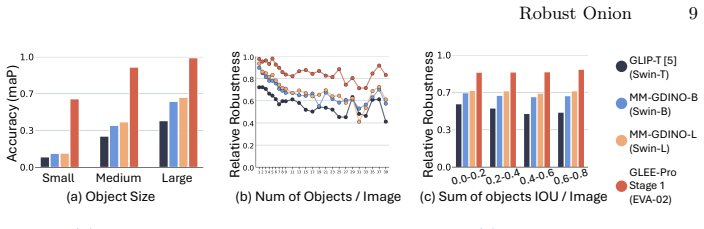
Models with similar vision backbones exhibit comparable robustness to visual noise, driven by similar feature collapse at similar layers, while robustness is primarily governed by the image domain rather than annotations or other training factors.
What carries the argument
Layer-by-layer peeling of OV-ODs under synthetic visual degradations to locate feature collapse points.
If this is right
- Models sharing a vision backbone will display matching robustness profiles and collapse layers under noise.
- Annotation differences contribute little to robustness gaps across detectors.
- Datasets containing large isolated objects produce an impression of higher robustness than datasets with varied object scales.
- A lightweight NN & TK0 plug-and-play module can raise real-world robustness using 96 times fewer trainable parameters than full retraining.
Where Pith is reading between the lines
- Efforts to strengthen vision backbones may improve noise robustness across many different open-vocabulary detectors at once.
- The synthetic degradation peeling technique could be reused to diagnose robustness in other vision tasks such as segmentation or captioning.
- The plug-and-play adaptation method points toward efficient ways to upgrade existing detectors without full retraining on new domains.
Load-bearing premise
Controlled synthetic visual degradations sufficiently represent the distribution and effects of real-world noise on detector performance and internal features.
What would settle it
Measure whether backbone similarity still predicts robustness levels when the same models are tested on uncontrolled real-world noisy images from BDD100K or VisDRONE instead of synthetic degradations.
Figures















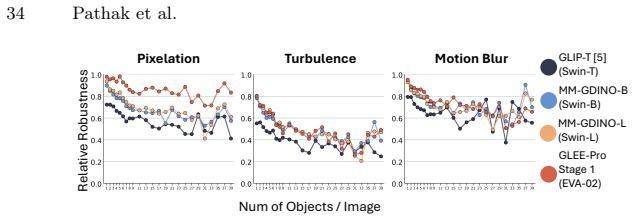
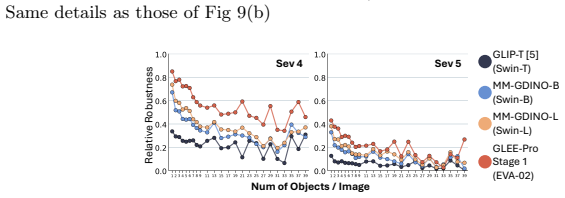
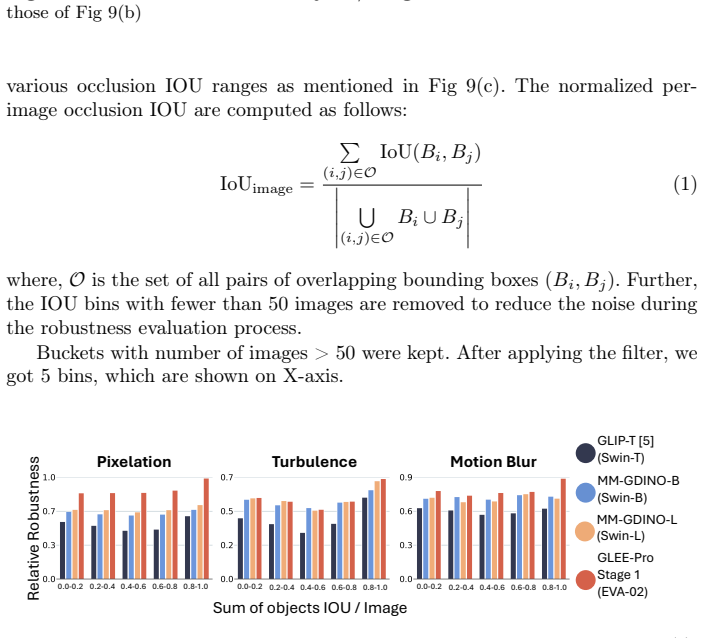







read the original abstract
The impact of real-world noise on Open Vocabulary Object Detectors (OV-ODs) remains poorly understood due to their architectural complexity. We present our comprehensive analysis Robust Onion, an empirical study that uses controlled synthetic visual degradations to peel OV-ODs layer-by-layer, revealing how, why, and where robustness degrades, systematically analyzing feature collapse. Our findings reveal that models with similar vision backbones exhibit comparable robustness, driven by similar feature collapse at similar layers, while factors such as pretraining strategy, architectural nuances, and caption supervision contribute little. Robustness is primarily governed by the image domain rather than annotations, explaining the similar robustness impact on COCO and LVIS, and why datasets like ODinW-13 can give an impression of inflated robustness due to large, isolated objects. Finally, we validate our insights by improving robustness on real-world BDD100K, WiderFace, and VisDRONE via our lightweight plug-and-play NN & TK0 approach, using 96x fewer trainable parameters than end-to-end training. We also explain the prior works' robustness observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Robust Onion, an empirical study of open-vocabulary object detectors (OV-ODs) under controlled synthetic visual degradations. By peeling models layer-by-layer, it identifies feature collapse locations and concludes that robustness is governed primarily by the image domain and vision backbone (similar backbones exhibit comparable collapse at similar layers) rather than annotations, pretraining strategy, or caption supervision. This explains comparable degradation on COCO and LVIS and inflated robustness impressions on ODinW-13. The authors validate the insights by transferring a lightweight plug-and-play NN & TK0 fix (96x fewer trainable parameters than end-to-end training) to improve performance on real-world datasets BDD100K, WiderFace, and VisDRONE, while also explaining prior robustness observations.
Significance. If the central empirical claims hold, the work supplies a useful diagnostic framework for locating robustness failures in OV-ODs via layer-wise feature collapse analysis and demonstrates a practical, parameter-efficient intervention that transfers across domains. Credit is due for the multi-dataset validation (synthetic peeling plus real-world transfer) and for attempting to unify prior observations under a backbone/domain-centric account. The study is purely empirical with no derivations or parameter fitting, which avoids circularity but places the full burden on the quality and representativeness of the synthetic degradations.
major comments (2)
- [§4 (synthetic peeling) and §5 (real-world validation)] The load-bearing claim that 'robustness is primarily governed by the image domain rather than annotations' (abstract and §5) rests on the synthetic peeling experiments showing backbone-similar collapse loci. However, the manuscript does not report a direct comparison of activation statistics (e.g., layer-wise variance, cosine similarity to clean features, or collapse thresholds) between the controlled synthetic degradations and the actual noise distributions in BDD100K/WiderFace/VisDRONE. Without this, the domain-governance conclusion does not necessarily follow from the layer-wise analysis.
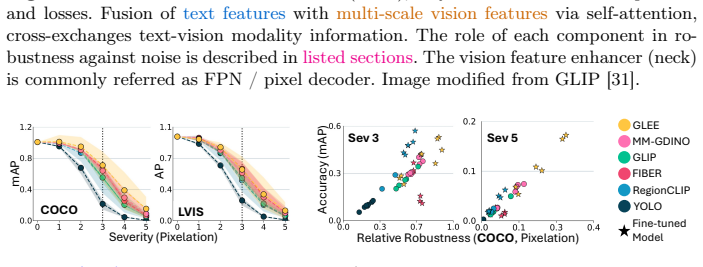
- [Table 2 and Figure 4] Table 2 / Figure 4 (layer-wise robustness curves): the reported similarity in collapse layers across backbones is central to the 'similar vision backbones exhibit comparable robustness' claim, yet no quantitative measure of collapse (e.g., the exact layer index where mean activation norm drops below a stated threshold, or statistical test across runs) is provided. This makes it impossible to evaluate whether the loci are truly 'similar' or merely qualitatively aligned.
minor comments (2)
- [Abstract] The abstract states conclusions without any quantitative results, error bars, dataset sizes, or ablation counts; moving at least one key quantitative finding (e.g., parameter count ratio or mAP delta on BDD100K) into the abstract would improve readability.
- [§3.3] Notation for the NN & TK0 components is introduced without an explicit equation or pseudocode block; a short definition of what 'TK0' modifies (e.g., which layers or tokens) would clarify the plug-and-play claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments, indicating where revisions will be made.
read point-by-point responses
-
Referee: [§4 (synthetic peeling) and §5 (real-world validation)] The load-bearing claim that 'robustness is primarily governed by the image domain rather than annotations' (abstract and §5) rests on the synthetic peeling experiments showing backbone-similar collapse loci. However, the manuscript does not report a direct comparison of activation statistics (e.g., layer-wise variance, cosine similarity to clean features, or collapse thresholds) between the controlled synthetic degradations and the actual noise distributions in BDD100K/WiderFace/VisDRONE. Without this, the domain-governance conclusion does not necessarily follow from the layer-wise analysis.
Authors: The domain-governance conclusion follows from two observations reported in the manuscript: (1) models sharing the same vision backbone exhibit nearly identical layer-wise collapse patterns under the controlled synthetic degradations, independent of annotation source or pretraining details, and (2) the lightweight NN & TK0 intervention derived from those patterns transfers to and improves performance on the real-world datasets BDD100K, WiderFace, and VisDRONE. While we did not include an explicit side-by-side comparison of activation statistics between synthetic and real noise distributions, the successful transfer provides empirical support that the synthetic regime captures the relevant robustness factors. We will add a short clarifying paragraph in §5 of the revision explaining this inference chain; this is a partial revision. revision: partial
-
Referee: [Table 2 and Figure 4] Table 2 / Figure 4 (layer-wise robustness curves): the reported similarity in collapse layers across backbones is central to the 'similar vision backbones exhibit comparable robustness' claim, yet no quantitative measure of collapse (e.g., the exact layer index where mean activation norm drops below a stated threshold, or statistical test across runs) is provided. This makes it impossible to evaluate whether the loci are truly 'similar' or merely qualitatively aligned.
Authors: We agree that an explicit quantitative definition would strengthen the claim. In the revised manuscript we will define collapse as the first layer where the mean activation norm (normalized to the clean-feature norm) falls below a fixed threshold of 0.5 and will tabulate the corresponding layer indices for each backbone alongside the existing curves. Where multiple random seeds were run we will also report the standard deviation of these indices. This constitutes a full revision of the presentation of Table 2 / Figure 4. revision: yes
Circularity Check
No circularity: purely empirical analysis with independent experimental validation
full rationale
This is a purely empirical study that applies controlled synthetic degradations to peel OV-OD layers and measures feature collapse across backbones. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains are load-bearing for the central claims. Robustness observations on COCO/LVIS are directly compared to real-world transfers on BDD100K/WiderFace/VisDRONE, and the backbone-dominance conclusion follows from layer-wise measurements rather than any definitional reduction or ansatz smuggled via prior work. The paper is self-contained against external benchmarks and exhibits no patterns from the enumerated circularity kinds.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[3]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=yJpBVE4vfo
Bao, W., Deng, R., He, J.: Mint: A simple test-time adaptation of vision-language models against common corruptions. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=yJpBVE4vfo
2025
-
[4]
Explaining object detection through difference map
Baranwal, A., Mueez, A., Voelker, J., Bhatia, G., Vyas, S.: Synspill: Improved industrial spill detection with synthetic data. In: 2025 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). p. 1425–1434. IEEE (Oct 2025).https://doi.org/10.1109/iccvw69036.2025.00152,http://dx.doi.org/ 10.1109/ICCVW69036.2025.00152
-
[5]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Bhojanapalli, S., Chakrabarti, A., Glasner, D., Li, D., Unterthiner, T., Veit, A.: Understanding robustness of transformers for image classification. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10231–10241 (October 2021)
2021
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bianchi, L., Carrara, F., Messina, N., Gennaro, C., Falchi, F.: The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22520–22529 (2024)
2024
-
[7]
Cabon, Y., Murray, N., Humenberger, M.: Virtual kitti 2. arXiv preprint arXiv:2001.10773 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chai, J.C.L., Ng, T.S., Low, C.Y., Park, J., Teoh, A.B.J.: Recognizability embed- ding enhancement for very low-resolution face recognition and quality estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9957–9967 (2023)
2023
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Guo, H., Yi, K., Li, B., Elhoseiny, M.: Visualgpt: Data-efficient adap- tation of pretrained language models for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18030– 18040 (2022)
2022
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, W.T., Vong, Y.J., Kuo, S.Y., Ma, S., Wang, J.: Robustsam: Segment any- thing robustly on degraded images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4081–4091 (June 2024)
2024
- [11]
-
[12]
In: Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part III 14
Cheng, Z., Zhu, X., Gong, S.: Low-resolution face recognition. In: Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part III 14. pp. 605–621. Springer (2019)
2018
-
[13]
In: European Confer- ence on Computer Vision
Chhipa, P.C., De, K., Chippa, M.S., Saini, R., Liwicki, M.: Open-vocabulary object detectors: Robustness challenges under distribution shifts. In: European Confer- ence on Computer Vision. pp. 62–79. Springer (2024) Robust Onion 17
2024
-
[14]
In: Proc
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
2016
-
[15]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Davila, D., Du, D., Lewis, B., Funk, C., Van Pelt, J., Collins, R., Corona, K., Brown, M., McCloskey, S., Hoogs, A., et al.: Mevid: Multi-view extended videos with identities for video person re-identification. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1634–1643 (2023)
2023
-
[16]
Deng, J., Zhang, H., Ding, K., Hu, J., Zhang, X., Wang, Y.: Zero-shot generalizable incremental learning for vision-language object detection (2024),https://arxiv. org/abs/2403.01680
-
[17]
In: NeurIPS (2022)
Dou, Z.Y., Kamath, A., Gan, Z., Zhang, P., Wang, J., Li, L., Liu, Z., Liu, C., LeCun, Y., Peng, N., Gao, J., Wang, L.: Coarse-to-fine vision-language pre-training with fusion in the backbone. In: NeurIPS (2022)
2022
-
[18]
Du, D., Qi, Y., Yu, H., Yang, Y., Duan, K., Li, G., Zhang, W., Huang, Q., Tian, Q.: Uavdt dataset (2018),https://sites.google.com/view/grli-uavdt/%E9% A6%96%E9%A1%B5
2018
-
[19]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Gu, X., Lin, T.Y., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2019)
Gupta, A., Dollar, P., Girshick, R.: LVIS: A dataset for large vocabulary instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2019)
2019
-
[22]
Customizing 360-degree panoramas through text-to-image diffusion models
Gupta, H., Kotlyar, O., Andreasson, H., Lilienthal, A.J.: Robust object detec- tion in challenging weather conditions. In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 7508–7517 (2024).https: //doi.org/10.1109/WACV57701.2024.00735
-
[23]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition (2015),https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
He, W., Deng, Y., Tang, S., Chen, Q., Xie, Q., Wang, Y., Bai, L., Zhu, F., Zhao, R., Ouyang, W., et al.: Instruct-reid: A multi-purpose person re-identification task with instructions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17521–17531 (2024)
2024
- [25]
-
[26]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kamath, A., Singh, M., LeCun, Y., Synnaeve, G., Misra, I., Carion, N.: Mdetr- modulated detection for end-to-end multi-modal understanding. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1780–1790 (2021)
2021
-
[27]
In: Conference on Empirical Methods in Natural Language Processing (2014),https://api.semanticscholar
Kazemzadeh, S., Ordonez, V., andre Matten, M., Berg, T.L.: Referitgame: Re- ferring to objects in photographs of natural scenes. In: Conference on Empirical Methods in Natural Language Processing (2014),https://api.semanticscholar. org/CorpusID:6308361
2014
-
[28]
Dawn: vehicle detection in adverse weather nature dataset.arXiv preprint arXiv:2008.05402, 2020
Kenk, M.A., Hassaballah, M.: Dawn: vehicle detection in adverse weather nature dataset. arXiv preprint arXiv:2008.05402 (2020) 18 Pathak et al
-
[29]
Dataset available from https://github
Krasin, I., Duerig, T., Alldrin, N., Ferrari, V., Abu-El-Haija, S., Kuznetsova, A., Rom, H., Uijlings, J., Popov, S., Veit, A., et al.: Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github. com/openimages2(3), 18 (2017)
2017
-
[30]
Li, C., Chen, X., Zhao, K., Zhu, J., Chen, J.: Zero-shot quantization for object detection (2025),https://openreview.net/forum?id=XNr6sexQGj
2025
-
[31]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., et al.: Grounded language-image pre-training. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10965–10975 (2022)
2022
-
[32]
Li, P., Prieto, L., Mery, D., Flynn, P.J.: On low-resolution face recognition in the wild: Comparisons and new techniques. IEEE Transactions on Information Forensics and Security14(8), 2000–2012 (2019).https://doi.org/10.1109/TIFS. 2018.2890812
-
[33]
Lin, T.Y., Maire, M., Belongie, S., Bourdev, L., Girshick, R., Hays, J., Perona, P., Ramanan, D., Zitnick, C.L., Dollár, P.: Microsoft coco: Common objects in context (2015)
2015
-
[34]
arXiv preprint arXiv:2302.05621 (2023)
Ling, X., Lu, Y., Xu, W., Deng, W., Zhang, Y., Cui, X., Shi, H., Wen, D.: Dive into the resolution augmentations and metrics in low resolution face recognition: A plain yet effective new baseline. arXiv preprint arXiv:2302.05621 (2023)
-
[35]
Liu, J., Wang, Z., Ma, L., Fang, C., Bai, T., Zhang, X., Liu, J., Chen, Z.: Bench- marking object detection robustness against real-world corruptions. Int. J. Com- put. Vision132(10), 4398–4416 (May 2024).https://doi.org/10.1007/s11263- 024-02096-6,https://doi.org/10.1007/s11263-024-02096-6
-
[36]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows (2021),https: //arxiv.org/abs/2103.14030
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 11–20 (2016)
2016
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Mao, X., Chen, Y., Zhu, Y., Chen, D., Su, H., Zhang, R., Xue, H.: Coco-o: A benchmark for object detectors under natural distribution shifts. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6339–6350 (2023)
2023
- [39]
-
[40]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) (October 2021)
Mao, Z., Chimitt, N., Chan, S.H.: Accelerating atmospheric turbulence simulation via learned phase-to-space transform. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) (October 2021)
2021
-
[41]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., Melville, J.: Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Minderer, M., Gritsenko, A., Stone, A., Neumann, M., Weissenborn, D., Doso- vitskiy, A., Mahendran, A., Arnab, A., Dehghani, M., Shen, Z., Wang, X., Zhai, X., Kipf, T., Houlsby, N.: Simple open-vocabulary object detection with vision transformers (2022),https://arxiv.org/abs/2205.06230
-
[43]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023),https://openreview.net/forum?id=mQPNcBWjGc Robust Onion 19
Minderer, M., Gritsenko, A.A., Houlsby, N.: Scaling open-vocabulary object de- tection. In: Thirty-seventh Conference on Neural Information Processing Systems (2023),https://openreview.net/forum?id=mQPNcBWjGc Robust Onion 19
2023
-
[44]
arXiv preprint arXiv:2405.04324 (2024)
Mishra, M., Stallone, M., Zhang, G., Shen, Y., Prasad, A., Soria, A.M., Merler, M., Selvam, P., Surendran, S., Singh, S., et al.: Granite code models: A family of open foundation models for code intelligence. arXiv preprint arXiv:2405.04324 (2024)
-
[45]
In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=AsFxRSLtqR
Pathak, P., Marjit, S., Vyas, S., Rawat, Y.S.: LR0.FM: Low-Res Benchmark and Improving robustness for Zero-Shot Classification in Foundation Models. In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=AsFxRSLtqR
2025
-
[46]
In: 36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025
Pathak, P., Rawat, Y.S.: Coarse attribute prediction with task agnostic distillation for real world clothes changing reid. In: 36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025. BMVA Press (2025)
2025
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Pathak, P., Rawat, Y.S.: Colors see colors ignore: Clothes changing reid with color disentanglement. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 16797–16807 (October 2025)
2025
-
[48]
In: 2017 2nd IEEE Interna- tional Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT)
Patil, J.S., Pawase, R.S., Dandawate, Y.H.: Classification of low resolution astro- nomical images using convolutional neural networks. In: 2017 2nd IEEE Interna- tional Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT). pp. 1168–1172. IEEE (2017)
2017
-
[49]
In: 2015 IEEE International Conference on Computer Vision (ICCV)
Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazeb- nik, S.: Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: 2015 IEEE International Conference on Computer Vision (ICCV). pp. 2641–2649 (2015).https://doi.org/10.1109/ICCV.2015.303
-
[50]
In: Proceedings of the Asian Conference on Computer Vision
Qin, Q., Chang, K., Huang, M., Li, G.: Denet: Detection-driven enhancement net- work for object detection under adverse weather conditions. In: Proceedings of the Asian Conference on Computer Vision. pp. 2813–2829 (2022)
2022
-
[51]
Learning Transferable Visual Models From Natural Language Supervision
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [52]
-
[53]
Sakaridis, C., Dai, D., Van Gool, L.: Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision126(9), 973–992 (Sep 2018),https://doi.org/10.1007/s11263-018-1072-8
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Schiappa, M.C., Azad, S., Vs, S., Ge, Y., Miksik, O., Rawat, Y.S., Vineet, V.: Robustness analysis on foundational segmentation models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1786– 1796 (2024)
2024
-
[55]
In: Proceedings of the IEEE/CVF international conference on computer vision
Shao, S., Li, Z., Zhang, T., Peng, C., Yu, G., Zhang, X., Li, J., Sun, J.: Objects365: A large-scale, high-quality dataset for object detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8430–8439 (2019)
2019
-
[56]
In: Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2556–2565 (2018)
2018
-
[57]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Shen, H., Zhao, T., Zhu, M., Yin, J.: Groundvlp: Harnessing zero-shot visual grounding from vision-language pre-training and open-vocabulary object detec- tion. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4766–4775 (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (June 2019) 20 Pathak et al
Shermeyer, J., Van Etten, A.: The effects of super-resolution on object detection performance in satellite imagery. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (June 2019) 20 Pathak et al
2019
-
[59]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Tian,X.,Gu,J.,Li,B.,Liu,Y.,Hu,C.,Wang,Y.,Zhan,K.,Jia,P.,Lang,X.,Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision-language models. ArXivabs/2402.12289(2024),https://api.semanticscholar.org/ CorpusID:267750682
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Advances in Neural Infor- mation Processing Systems34, 200–212 (2021)
Tsimpoukelli, M., Menick, J.L., Cabi, S., Eslami, S., Vinyals, O., Hill, F.: Multi- modal few-shot learning with frozen language models. Advances in Neural Infor- mation Processing Systems34, 200–212 (2021)
2021
-
[61]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 7794–7803 (2018)
2018
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wu, J., Jiang, Y., Liu, Q., Yuan, Z., Bai, X., Bai, S.: General object foundation model for images and videos at scale. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3783–3795 (June 2024)
2024
-
[63]
arXiv preprint arXiv:2412.16583 (2024)
Xue, X., Wei, G., Chen, H., Zhang, H., Lin, F., Shen, C., Zhu, X.X.: Reo- vlm: Transforming vlm to meet regression challenges in earth observation. arXiv preprint arXiv:2412.16583 (2024)
-
[64]
Yamada, Y., Otani, M.: Does robustness on imagenet transfer to downstream tasks? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9215–9224 (June 2022)
2022
-
[65]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Yang, S., Luo, P., Loy, C.C., Tang, X.: Wider face: A face detection benchmark. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
2016
-
[66]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Yao, L., Pi, R., Han, J., Liang, X., Xu, H., Zhang, W., Li, Z., Xu, D.: Detclipv3: Towards versatile generative open-vocabulary object detection. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 5610–5619 (2024),https://api.semanticscholar.org/CorpusID:269148793
2024
-
[67]
Yoo, J., Lee, D., Chung, I., Kim, D., Kwak, N.: What how and when should object detectors update in continually changing test domains? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23354– 23363 (2024)
2024
-
[68]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[69]
arXiv preprint arXiv:2503.15892 (2025)
Yu, H., Yi, S., Niu, K., Zhuo, M., Li, B.: Umit: Unifying medical imaging tasks via vision-language models. arXiv preprint arXiv:2503.15892 (2025)
-
[70]
In: Computer Vision–ECCV 2016: 14th European Conference, Ams- terdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14
Yu, L., Poirson, P., Yang, S., Berg, A.C., Berg, T.L.: Modeling context in referring expressions. In: Computer Vision–ECCV 2016: 14th European Conference, Ams- terdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14. pp. 69–85. Springer (2016)
2016
-
[71]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zareian, A., Rosa, K.D., Hu, D.H., Chang, S.F.: Open-vocabulary object detection using captions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14393–14402 (2021)
2021
- [72]
-
[73]
In: Proceedings of the Asian Conference on Computer Vision
Zhang, Z., Gong, H., Feng, Y., Chu, Z., Liu, H.: Enhancing object detection in adverse weather conditions through entropy and guided multimodal fusion. In: Proceedings of the Asian Conference on Computer Vision. pp. 2922–2938 (2024)
2024
-
[74]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhao,S.,Schulter,S.,Zhao,L.,Zhang,Z.,Suh,Y.,Chandraker,M.,Metaxas,D.N., et al.: Taming self-training for open-vocabulary object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13938–13947 (2024) Robust Onion 21
2024
-
[75]
arXiv preprint arXiv:2401.02361 (2024)
Zhao, X., Chen, Y., Xu, S., Li, X., Wang, X., Li, Y., Huang, H.: An open and comprehensive pipeline for unified object grounding and detection. arXiv preprint arXiv:2401.02361 (2024)
-
[76]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L.H., Zhou, L., Dai, X., Yuan, L., Li, Y., et al.: Regionclip: Region-based language-image pretraining. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 16793–16803 (2022)
2022
-
[77]
In: International conference on machine learning
Zhou, D., Yu, Z., Xie, E., Xiao, C., Anandkumar, A., Feng, J., Alvarez, J.M.: Understanding the robustness in vision transformers. In: International conference on machine learning. pp. 27378–27394. PMLR (2022)
2022
-
[78]
Zhu, P., Wen, L., Du, D., Bian, X., Fan, H., Hu, Q., Ling, H.: Detection and track- ing meet drones challenge. IEEE Transactions on Pattern Analysis and Machine Intelligence44(11), 7380–7399 (2021) Robust Onion: Peeling Open Vocab Object Detectors Under Noise Supplementary Priyank Pathak*, Mukilan Karuppasamy*, Aaditya Baranwal, Shruti Vyas, and Yogesh S ...
2021
-
[79]
Section 1 highlights some RGB examples, and predictions on various syn- thetic and real-world noise examples
-
[80]
Section 2, and Section 3 has details for various datasets and models used in our analysis,
-
[81]
Section 4 have variants of various analysis shown in the main submission, but generalized for all severities, noises, and the LVIS dataset
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.