Human--LLM Collaboration Is Transforming Complexity Metrics in Scientific Texts
Pith reviewed 2026-06-26 01:45 UTC · model grok-4.3
The pith
LLM use after 2023 increases word turnover and flattens style-complexity ties in scientific abstracts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
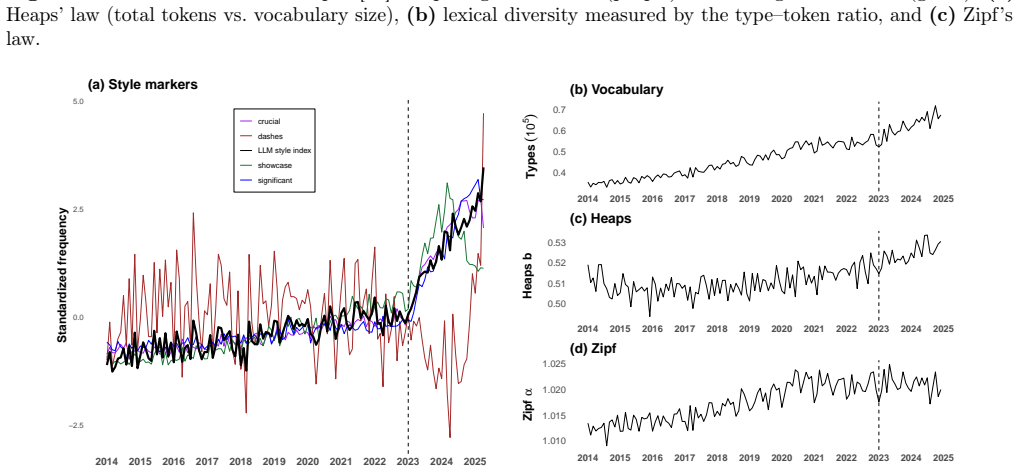
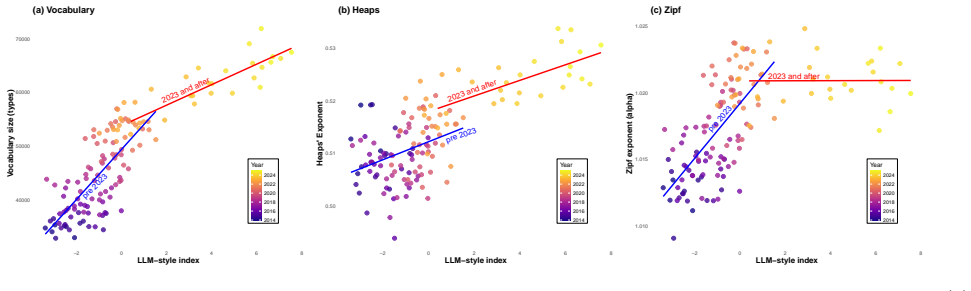
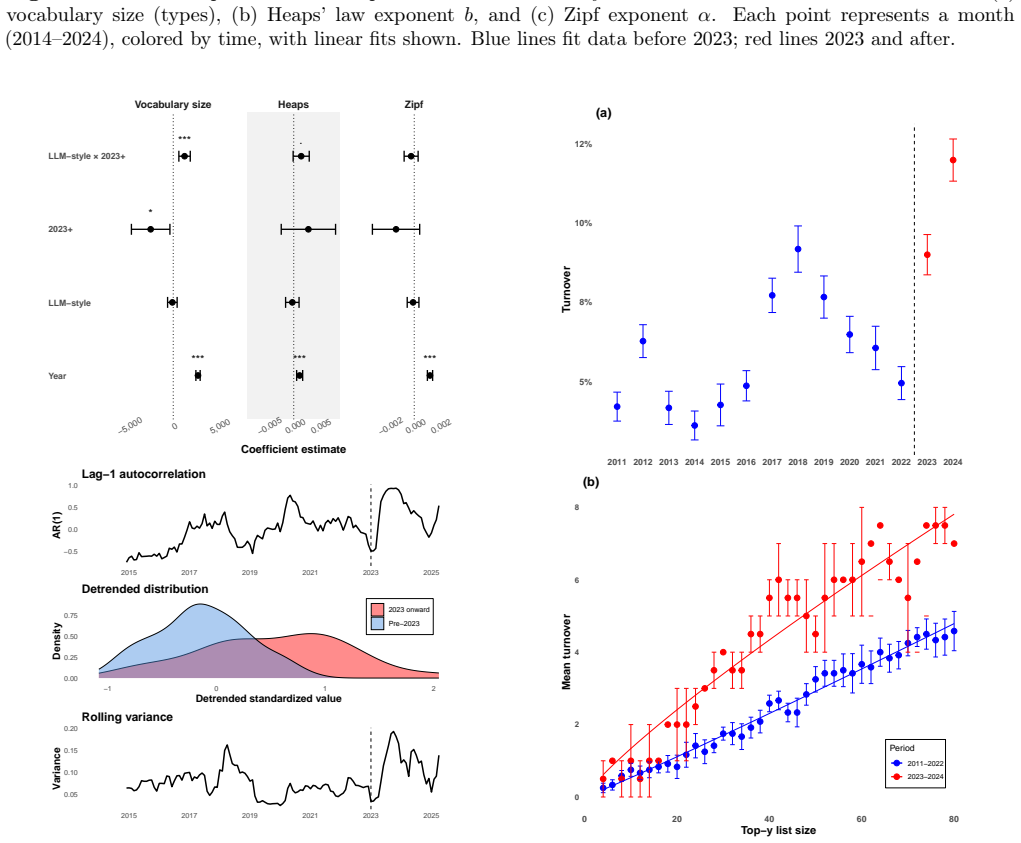
The paper establishes that after early 2023 the positive relationship between an LLM-associated style index and three complexity metrics (vocabulary size, Heaps' law exponent, Zipf's law exponent) becomes flatter, while turnover among top-ranked words rises sharply; these shifts, alongside only minor changes in the law exponents themselves, are presented as evidence of altered emergent properties in scientific text within a mixed human-AI linguistic ecosystem.
What carries the argument
The LLM-associated style index, a composite measure of linguistic patterns linked to LLM output, whose post-2022 relationship to vocabulary size and the exponents of Heaps' and Zipf's laws is tracked across arXiv abstracts.
If this is right
- Turnover among the highest-ranked words increases sharply from 2023 onward.
- The positive correlation between LLM-associated style and vocabulary size, Heaps' exponent, and Zipf's exponent flattens after 2022.
- Overall exponents of Zipf's law and Heaps' law show only subtle shifts across the same period.
- These metric changes are consistent with new emergent properties arising in scientific text under human-LLM collaboration.
Where Pith is reading between the lines
- If the patterns hold, models trained on growing volumes of this mixed text may reinforce the same flattening and turnover trends in future outputs.
- The observed changes could alter how novelty and emphasis are signaled in papers, affecting citation patterns over longer timescales.
- Similar style and turnover shifts might appear in non-scientific domains once LLM use reaches comparable penetration.
Load-bearing premise
The sharp rise in the LLM-associated style index after early 2023 and the flattening of its link to complexity metrics are caused mainly by LLM adoption rather than other simultaneous changes in publishing or data.
What would settle it
Re-running the analysis on a control corpus of abstracts written entirely without LLM assistance and finding no post-2023 rise in word turnover or flattening of the style-complexity relationship would undermine the claim.
Figures

read the original abstract
While human language has long been studied as a complex system, Large Language Models (LLMs) are rapidly becoming contributors to its dynamics. Because LLMs are trained on human language use, their effects on the broader human-AI linguistic ecosystem are likely subtle at first. As their use becomes more widespread, however, LLMs may alter emergent properties of language, particularly as models increasingly train on mixed human-LLM textual data. Here, we draw on complexity science to look for subtle LLM effects in millions of arXiv abstracts from 2010 to 2025. The year 2023, when LLMs rapidly became widely used, serves as a landmark in a natural experiment. While we find a sharp increase in a composite LLM-associated style index after early 2023, we observe only subtle changes in the exponents of Zipf's law and Heaps' law. More compelling, however, are two subtle changes in complexity metrics that emerge from 2023 onward. First, turnover among top-ranked words increases sharply. Second, the positive relationship between the LLM-associated style index and three complexity metrics--vocabulary size and the exponents of Heaps' and Zipf's laws--becomes flatter after 2022. Together, these patterns are consistent with changes in the emergent properties of scientific text in a mixed human-AI linguistic ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes millions of arXiv abstracts (2010–2025) as a natural experiment around the 2023 rise of LLMs. It reports a sharp post-early-2023 increase in a composite LLM-associated style index, increased turnover among top-ranked words, only subtle shifts in Zipf and Heaps exponents, and a flattening after 2022 of the positive relationship between the style index and three complexity metrics (vocabulary size, Heaps’ exponent, Zipf’s exponent). These patterns are interpreted as evidence of altered emergent properties of scientific text in a mixed human–AI linguistic ecosystem.
Significance. If the post-2023 patterns can be isolated from concurrent trends and the style index is shown to be robust, the work would supply large-scale observational data on how LLM adoption may be modulating statistical regularities in scientific writing, linking complexity science to studies of AI-mediated language change. The scale of the arXiv corpus and the focus on established metrics (Zipf, Heaps) are methodological strengths.
major comments (3)
- [Abstract] Abstract: the central claim that the observed 2023 inflection and subsequent flattening are 'consistent with changes in the emergent properties of scientific text in a mixed human-AI linguistic ecosystem' treats 2023 as a clean marker of LLM adoption, yet the manuscript provides no explicit controls, falsification tests, or discussion of concurrent factors (field-composition shifts, submission-volume changes, abstract-length norms, or metadata artifacts) that could produce the same breakpoint.
- [Abstract] Abstract: the composite LLM-associated style index is introduced without any description of its construction, component weights, validation against human-labeled data, or robustness checks; because the reported sharp rise and the flattening of its correlations with complexity metrics rest entirely on this index, the absence of these details renders the quantitative patterns unverifiable.
- [Abstract] Abstract: no error bars, confidence intervals, or statistical tests are reported for the claimed increase in top-word turnover or for the change in slope of the style-index–complexity relationships, leaving open whether the post-2022 flattening is distinguishable from sampling variability.
minor comments (1)
- [Abstract] Abstract: the endpoint '2025' should be clarified (data cutoff date) given that the manuscript is presumably written before the end of 2025.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments and will revise the abstract and discussion as needed to improve clarity and address concerns about verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the observed 2023 inflection and subsequent flattening are 'consistent with changes in the emergent properties of scientific text in a mixed human-AI linguistic ecosystem' treats 2023 as a clean marker of LLM adoption, yet the manuscript provides no explicit controls, falsification tests, or discussion of concurrent factors (field-composition shifts, submission-volume changes, abstract-length norms, or metadata artifacts) that could produce the same breakpoint.
Authors: We agree the abstract presents 2023 as a landmark without explicit qualification. The manuscript examines submission-volume and field-composition trends, but we will revise the abstract to temper the central claim and expand the discussion section with additional analysis of concurrent factors and any falsification tests. revision: yes
-
Referee: [Abstract] Abstract: the composite LLM-associated style index is introduced without any description of its construction, component weights, validation against human-labeled data, or robustness checks; because the reported sharp rise and the flattening of its correlations with complexity metrics rest entirely on this index, the absence of these details renders the quantitative patterns unverifiable.
Authors: The index construction, weights, validation against labeled data, and robustness checks are described in the Methods section. We will revise the abstract to add a brief description of the index and its validation to improve immediate verifiability. revision: yes
-
Referee: [Abstract] Abstract: no error bars, confidence intervals, or statistical tests are reported for the claimed increase in top-word turnover or for the change in slope of the style-index–complexity relationships, leaving open whether the post-2022 flattening is distinguishable from sampling variability.
Authors: Error bars, confidence intervals, and statistical tests appear in the figures and results sections. We will revise the abstract to reference that the reported changes are supported by these statistical analyses in the main text. revision: yes
Circularity Check
No significant circularity; direct empirical measurements on external data
full rationale
The paper reports observational patterns from arXiv abstracts (2010-2025), including a composite LLM-style index and complexity metrics (vocabulary size, Heaps' and Zipf's exponents). No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The central claims rest on direct measurement of external data rather than any derivation that reduces to its own inputs by construction. This is the expected outcome for a measurement-focused study without theoretical modeling steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wang, H.et al.Scientific discovery in the age of artificial intelligence.Nature620, 47–60 (2023)
2023
-
[2]
Yerramilli-Rao, B.et al.Strategy in an era of abun- dant expertise.Harvard Business ReviewMarch-April (2025)
2025
-
[3]
Zenil, H.et al.The future of fundamental science led by generative closed-loop artificial intelligence.ArXiv abs/2307.07522(2023)
arXiv 2023
-
[4]
D.et al.The automation of science.Science 324, 85 – 89 (2009)
King, R. D.et al.The automation of science.Science 324, 85 – 89 (2009)
2009
-
[5]
D.et al.Language agents achieve superhu- man synthesis of scientific knowledge (2024)
Skarlinski, M. D.et al.Language agents achieve superhu- man synthesis of scientific knowledge (2024). 2409.13740
arXiv 2024
-
[6]
Practice Innovations(2025)
Rousmaniere, T.et al.Large language models as mental health resources: Patterns of use in the united states. Practice Innovations(2025)
2025
-
[7]
N.et al.Representation in science and trust in scientists in the USA.Nature human behaviour 10, 476–491 (2025)
Druckman, J. N.et al.Representation in science and trust in scientists in the USA.Nature human behaviour 10, 476–491 (2025)
2025
-
[8]
H.et al.Durably reducing conspiracy beliefs through dialogues with AI.Science385, eadq1814 (2024)
Costello, T. H.et al.Durably reducing conspiracy beliefs through dialogues with AI.Science385, eadq1814 (2024)
2024
-
[9]
H.et al.AI can help humans find common ground in democratic deliberation.Science386, eadq2852 (2024)
Tessler, M. H.et al.AI can help humans find common ground in democratic deliberation.Science386, eadq2852 (2024)
2024
-
[10]
F.et al.Emergent social conventions and collective bias in LLM populations.Science Advances11, eadu9368 (2025)
Ashery, A. F.et al.Emergent social conventions and collective bias in LLM populations.Science Advances11, eadu9368 (2025)
2025
-
[11]
& Pruthi, D
Gupta, T. & Pruthi, D. All that glitters is not novel: Plagiarism in AI generated research. InAnnual Meeting of the Association for Computational Linguistics(2025)
2025
-
[12]
Keener, R. More A than I: Testing for large language model plagiarism in political science.PS: Political Science & Politics58, doi:10.1017/S104909652500036 (2025)
-
[13]
Yakura, H.et al.Empirical evidence of large language model’sinfluenceonhumanspokencommunication.ArXiv abs/2409.01754(2024)
arXiv 2024
-
[14]
Perez, J.et al.When llms play the telephone game: Cumulative changes and attractors in iterated cultural transmissions.ArXivabs/2407.04503(2024)
arXiv 2024
-
[15]
Brinkmann, L.et al.Machine culture.Nature Human Behaviour7, 1855 – 1868 (2023)
2023
-
[16]
Perez, J.et al.Cultural evolution in populations of large language models.ArXivabs/2403.08882(2024)
arXiv 2024
-
[17]
& Arita, T
Suzuki, R. & Arita, T. An evolutionary model of person- ality traits related to cooperative behavior using a large language model.Scientific Reports14, 5989 (2023)
2023
-
[18]
Farrell, H.et al.Large AI models are cultural and social technologies.Science387, 1153–1156 (2025)
2025
-
[19]
LeCun, Y.et al.Deep learning.Nature521, 436–444 (2015)
2015
-
[20]
Evans, J.et al.Agentic ai and the next intelligence explosion.Science391 6791, eaeg1895 (2026)
2026
-
[21]
Qiang, J.et al.Redefining simplicity: Benchmarking large language models from lexical to document simplification. ArXivabs/2502.08281(2025)
arXiv 2025
-
[22]
A., Hahn, M
Bentley, R. A., Hahn, M. W. & Shennan, S. J. Random drift and culture change.Proceedings of the Royal Society of London. Series B: Biological Sciences271, 1443–1450 (2004)
2004
-
[23]
Duran-Nebreda, S.et al.Dilution of expertise in the rise and fall of collective innovation.Humanities and Social Sciences Communications9, 1–10 (2022)
2022
-
[24]
Rosillo-Rodes, P.et al.Simon’s model does not produce zipf’s law: The fundamental rich-get-richer mechanism for any power-law size ranking (2026)
2026
-
[25]
Vidiella, B.et al.A cultural evolutionary theory that explains both gradual and punctuated change.Journal of the Royal Society Interface19(2022)
2022
-
[26]
The AI revolution is running out of data
Jones, N. The AI revolution is running out of data. what 7 can researchers do?Nature636 8042, 290–292 (2024)
2024
-
[27]
Longpré, S.et al.Consent in crisis: The rapid decline of the AI Data Commons.ArXivabs/2407.14933(2024)
arXiv 2024
-
[28]
Peterson, A. J. Ai and the problem of knowledge collapse. ArXivabs/2404.03502(2024)
arXiv 2024
-
[29]
Shumailov, I.et al.Ai models collapse when trained on recursively generated data.Nature631, 755–759 (2024)
2024
-
[30]
& Domenico, M
Zomer, N. & Domenico, M. D. Unraveling the emergence of collective behavior in networks of cognitive agents.npj Artificial Intelligence2, 36 (2026)
2026
-
[31]
Ferrarotti, L.et al.Generative ai collective behavior needs an interactionist paradigm.ArXivabs/2601.10567 (2026)
arXiv 2026
-
[32]
A.et al.Mapping collective behavior in the big-data era.Behav
Bentley, R. A.et al.Mapping collective behavior in the big-data era.Behav. Brain Sci.37, 63 – 76 (2014)
2014
-
[33]
Brock, W. A. B., Bentley, R. A.et al.Estimating a path through a map of decision making.PLoS ONE9, e111022 (2014)
2014
-
[34]
Muñoz-Ortiz, A.et al.Contrasting linguistic patterns in human and llm-generated news text.Artificial Intelligence Review57(2023)
2023
-
[35]
Reinhart, A.et al.Do LLMs write like humans? variation in grammatical and rhetorical styles.Proceedings of the National Academy of Sciences of the United States of America122, e2422455122 (2025)
2025
-
[36]
P.et al.A simple generative model of collective online behavior.Proceedings of the National Academy of Sciences111, 10411 – 10415 (2013)
Gleeson, J. P.et al.A simple generative model of collective online behavior.Proceedings of the National Academy of Sciences111, 10411 – 10415 (2013)
2013
-
[37]
A.et al.Regular rates of popular culture change reflect random copying.Evolution and Human Behavior28, 151–158 (2007)
Bentley, R. A.et al.Regular rates of popular culture change reflect random copying.Evolution and Human Behavior28, 151–158 (2007)
2007
-
[38]
& Bentley, R
Acerbi, A. & Bentley, R. A. Biases in cultural transmis- sion shape the turnover of popular traits.Evolution and Human Behavior35, 228–236 (2014)
2014
-
[39]
J.et al.Role of neutral evolution in word turnover during centuries of english word popularity.Adv
Ruck, D. J.et al.Role of neutral evolution in word turnover during centuries of english word popularity.Adv. Complex Syst.20, 1750012 (2017)
2017
-
[40]
Evans, T. S. & Giometto, A. Turnover rate of popularity charts in neutral models.ArXivabs/1105.4044(2011)
Pith/arXiv arXiv 2011
-
[41]
Chatgpt usage: Statistics and facts
Burmagina, K. Chatgpt usage: Statistics and facts. https: //elfsight.com/blog/chatgpt-usage-statistics/ (2026). Ac- cessed: 2026-04-21
2026
-
[42]
Geng, M. & Trotta, R. Is chatgpt transforming academics’ writing style?ArXivabs/2404.08627(2024)
arXiv 2024
-
[43]
& Lause, J
Kobak, D., Gonz’alez-M’arquez, R., ágnes Horvát, E. & Lause, J. Delving into llm-assisted writing in biomedical publications through excess vocabulary.Science Advances 11, eadt3813 (2025)
2025
-
[44]
A.et al.Comparing scientific abstracts generated by chatgpt to real abstracts with detectors and blinded human reviewers.NPJ Digital Medicine6, 75 (2023)
Gao, C. A.et al.Comparing scientific abstracts generated by chatgpt to real abstracts with detectors and blinded human reviewers.NPJ Digital Medicine6, 75 (2023)
2023
-
[45]
Su, Y. & Wu, Y. Robust detection of llm-generated text: A comparative analysis.ArXivabs/2411.06248(2024)
arXiv 2024
-
[46]
Scheffer, M.et al.Early-warning signals for critical tran- sitions.Nature461, 53–59 (2009)
2009
-
[47]
Scheffer, M.et al.Anticipating critical transitions.Science 338, 344 – 348 (2012)
2012
-
[48]
Large language models surpass human experts in predicting neuroscience results.Nature Human Behaviour9, 305 – 315 (2024)
Luo, X., Rechardt, A., Sun, G., Nejad, K.K.&etal. Large language models surpass human experts in predicting neuroscience results.Nature Human Behaviour9, 305 – 315 (2024)
2024
-
[49]
Sparrow, B., Liu, J. J. W. & Wegner, D. M. Google effects on memory: Cognitive consequences of having information at our fingertips.Science333, 776 – 778 (2011)
2011
-
[50]
Fan, Y.et al.Beware of metacognitive laziness.ArXiv abs/2412.09315(2024)
arXiv 2024
-
[51]
Shojaee, P.et al.The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity (2025). 8
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.