Dismantling Pathological Shortcuts: A Causal Framework for Faithful LVLM Decoding
Pith reviewed 2026-06-29 01:15 UTC · model grok-4.3
The pith
Hallucinations in large vision-language models are triggered when specific attention heads decouple from visual evidence and follow language priors instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
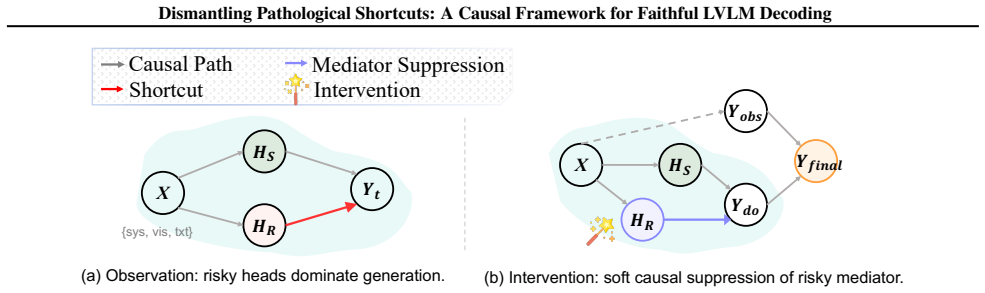
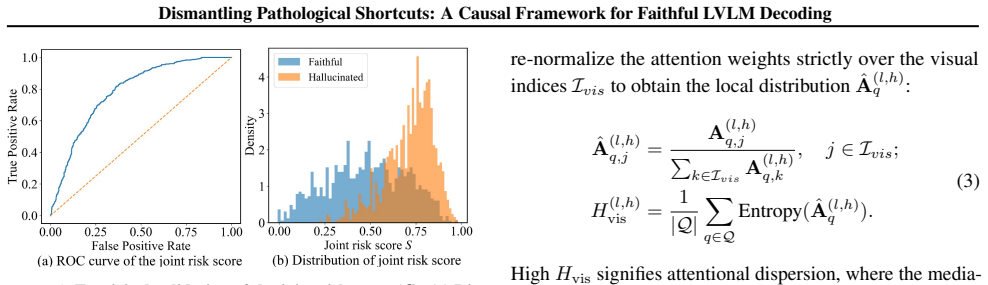
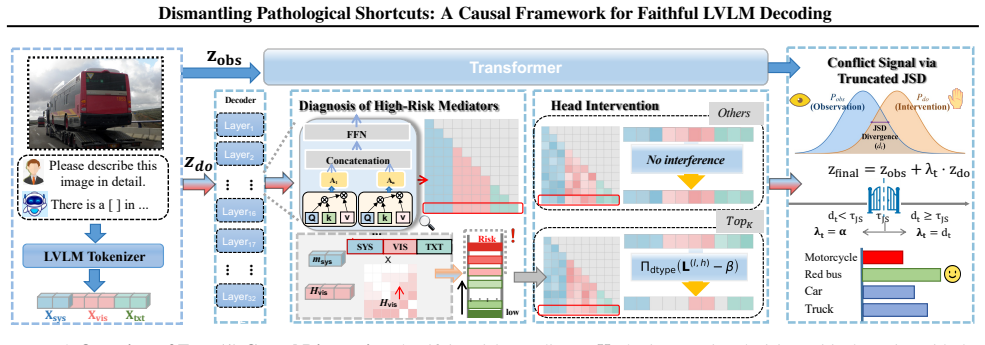
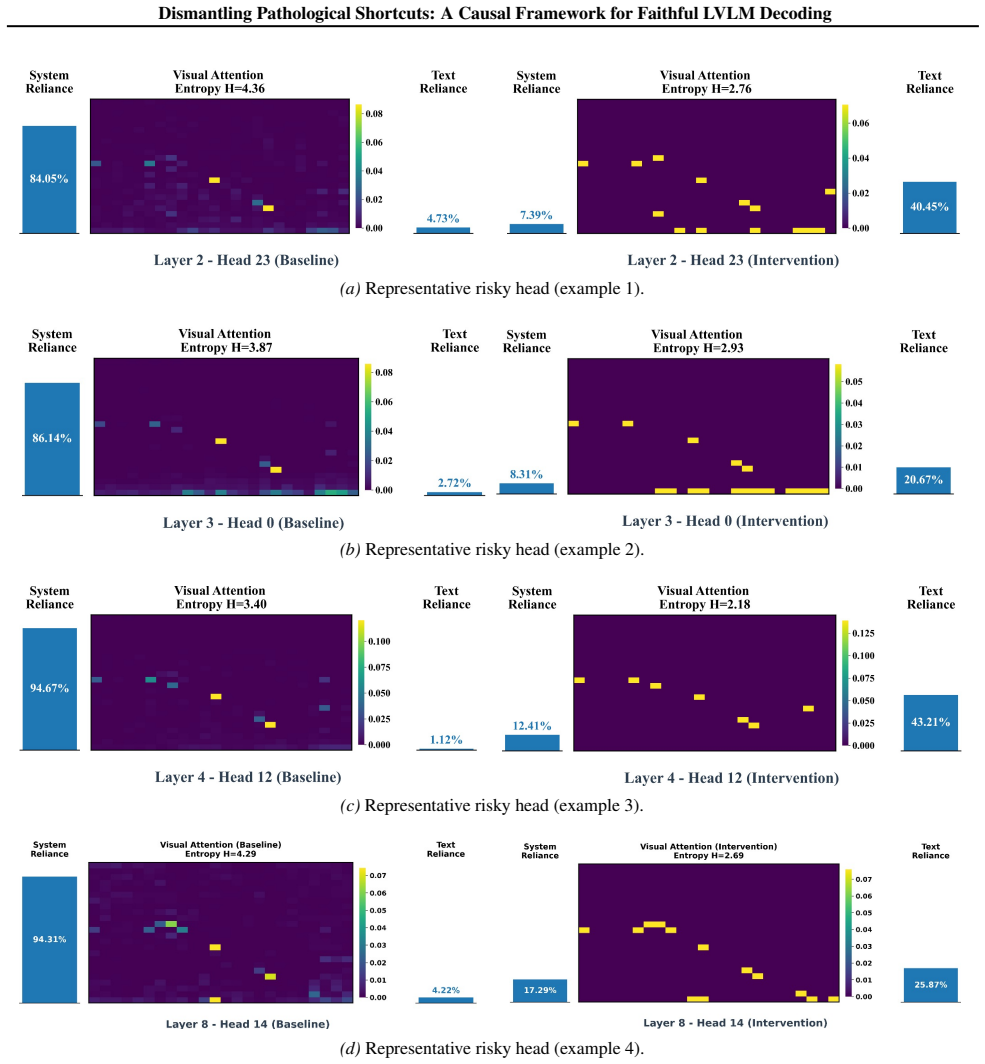
Hallucination is triggered at decision-critical steps where specific attention heads, acting as risky mediators, decouple from visual evidence to lock onto language priors. This establishes a pathological shortcut that bypasses visual grounding. Fox diagnoses the misalignment with a visual attention entropy probe that localizes the risky mediators in an unsupervised manner, performs causal intervention by numerical logit saturation to sever the shortcut, and reconciles the result with a conflict-gated cooperative decoding strategy that preserves observational fluency.
What carries the argument
risky mediators: the specific attention heads that decouple from visual evidence at decision-critical steps to form pathological shortcuts
If this is right
- Targeted logit saturation on the identified heads severs the shortcut and lowers hallucination rates.
- The resulting outputs maintain linguistic richness while increasing faithfulness to the image.
- The entire procedure runs at inference time with no model retraining required.
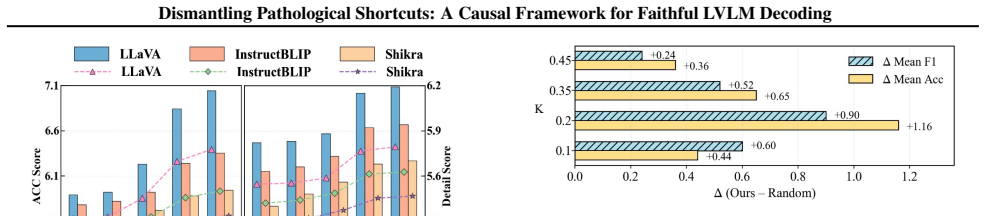
- The method reports a 29.1 percent improvement over the prior SID baseline on standard hallucination benchmarks.
Where Pith is reading between the lines
- If entropy reliably flags causal heads, the same probe could be adapted to diagnose other systematic failures such as inconsistent reasoning across modalities.
- The logit-saturation step implies that attention patterns in frozen transformers can be edited post hoc to enforce grounding without changing weights.
- Extending the localization step to video or audio inputs would require only redefining the entropy calculation over the new evidence stream.
Load-bearing premise
Visual attention entropy can reliably and unsupervisedly identify the exact attention heads whose decoupling is the direct cause of the pathological shortcut.
What would settle it
If intervening on the entropy-localized heads reduces hallucinations no more than intervening on randomly chosen heads, the claim that those heads are the load-bearing cause would be falsified.
Figures











read the original abstract
Large Vision-Language Models (LVLMs) exhibit sophisticated reasoning but remain susceptible to object hallucination. Deviating from the prevailing attention intensity assumption, we reveal a deeper dynamic structural misalignment: hallucination is triggered at decision-critical steps where specific attention heads, acting as risky mediators, decouple from visual evidence to lock onto language priors. This establishes a pathological shortcut that bypasses visual grounding. To dismantle this, we propose Fox (Faithfulness and Observational-flow via eXpression-rectification), a training-free inference-time framework. Fox diagnoses structural misalignment using a visual attention entropy probe to localize risky mediators unsupervisedly. We then execute a targeted causal intervention via numerical logit saturation to physically sever the shortcut path. Finally, a conflict-gated cooperative decoding strategy reconciles interventional faithfulness with observational fluency. Extensive experiments demonstrate that Fox achieves SOTA performance, outperforming SID by 29.1% while preserving linguistic richness. Code is available at https://github.com/Cc2021start/Fox.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that object hallucination in LVLMs stems from a structural misalignment at decision-critical steps, where specific attention heads ('risky mediators') decouple from visual evidence and lock onto language priors, creating a pathological shortcut. It introduces the training-free Fox framework, which diagnoses this via an unsupervised visual attention entropy probe to localize the mediators, applies numerical logit saturation as a causal intervention to sever the shortcut, and uses conflict-gated cooperative decoding to balance faithfulness and fluency. Experiments are said to show SOTA results, including a 29.1% improvement over SID while preserving linguistic richness, with code released.
Significance. If the causal mechanism and intervention hold, the work provides a mechanistic account of hallucination beyond attention intensity assumptions and a practical inference-time method for mitigation. The release of code supports reproducibility and allows verification of the claimed gains.
major comments (3)
- [Abstract, §3] Abstract and §3 (diagnosis step): The central claim requires that the visual attention entropy probe unsupervisedly isolates the precise attention heads whose decoupling constitutes the load-bearing causal shortcut. No controlled ablation is described showing that intervening specifically on entropy-localized heads (vs. random heads or high-entropy heads) produces the claimed reduction in hallucination while preserving other behaviors; without this, the subsequent logit saturation step may address a correlate rather than the mediator.
- [§4, experiments] §4 (intervention) and experiments: The numerical logit saturation is presented as physically severing the shortcut path, but the manuscript provides no derivation or measurement (e.g., via do-calculus style intervention or path-specific effect) confirming that saturation on the localized heads alters the decision distribution in the manner predicted by the risky-mediator hypothesis rather than via a generic regularization effect.
- [Results (Table 1)] Table 1 or equivalent results section: The reported 29.1% improvement over SID lacks accompanying details on the exact evaluation protocol, number of runs, statistical significance, or controls for prompt sensitivity; this makes it impossible to assess whether the gain is attributable to the causal intervention or to other implementation choices.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments' but the provided text contains no quantitative baselines, dataset sizes, or metric definitions; these should be summarized even at high level for clarity.
- [§2-3] Notation for 'risky mediators' and 'visual attention entropy probe' is introduced without an explicit equation or pseudocode in the early sections; adding a compact definition would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, providing clarifications and committing to revisions to enhance the causal validation and experimental details.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (diagnosis step): The central claim requires that the visual attention entropy probe unsupervisedly isolates the precise attention heads whose decoupling constitutes the load-bearing causal shortcut. No controlled ablation is described showing that intervening specifically on entropy-localized heads (vs. random heads or high-entropy heads) produces the claimed reduction in hallucination while preserving other behaviors; without this, the subsequent logit saturation step may address a correlate rather than the mediator.
Authors: We agree that an explicit ablation comparing interventions on entropy-localized heads versus random or high-entropy heads would provide stronger evidence for the specificity of the risky mediators. In the revised manuscript, we will add this controlled ablation study, demonstrating that only the entropy-based localization leads to significant hallucination reduction while maintaining fluency, thereby confirming the probe's effectiveness in isolating the causal shortcut. revision: yes
-
Referee: [§4, experiments] §4 (intervention) and experiments: The numerical logit saturation is presented as physically severing the shortcut path, but the manuscript provides no derivation or measurement (e.g., via do-calculus style intervention or path-specific effect) confirming that saturation on the localized heads alters the decision distribution in the manner predicted by the risky-mediator hypothesis rather than via a generic regularization effect.
Authors: The logit saturation is intended as a targeted intervention to cap the output of the decoupled heads, thereby blocking the language-prior shortcut. While the original manuscript relies on empirical outcomes to support the mechanism, we acknowledge the value of a more formal analysis. We will include additional measurements of the decision distribution shifts and a discussion of the intervention's effect in terms of blocking the identified path, though a full do-calculus derivation may require further theoretical development beyond the scope of this work. revision: partial
-
Referee: [Results (Table 1)] Table 1 or equivalent results section: The reported 29.1% improvement over SID lacks accompanying details on the exact evaluation protocol, number of runs, statistical significance, or controls for prompt sensitivity; this makes it impossible to assess whether the gain is attributable to the causal intervention or to other implementation choices.
Authors: We appreciate this point and will revise the results section to include full details on the evaluation protocol (using POPE and CHAIR benchmarks with standard settings), the number of runs (5 independent runs with reported means and standard deviations), statistical significance tests (p-values), and controls for prompt sensitivity (using fixed prompts from prior literature). This will allow readers to better evaluate the robustness of the 29.1% improvement. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents an empirical, training-free framework (Fox) that diagnoses misalignment via an attention entropy probe and applies logit saturation intervention, with performance validated experimentally against baselines like SID. No equations, self-citations, or steps in the abstract or described chain reduce by construction to fitted inputs, self-definitions, or prior author results; the localization and intervention are framed as novel observational methods rather than tautological renamings or forced predictions. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Visual attention entropy can unsupervisedly localize decision-critical attention heads that have decoupled from visual evidence.
- domain assumption Numerical logit saturation physically severs the pathological shortcut path without harming observational fluency when combined with conflict-gated decoding.
invented entities (1)
-
risky mediators (specific attention heads)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mitigating object hallucinations in large vision-language models with assembly of global and local attention
An, W., Tian, F., Leng, S., Nie, J., Lin, H., Wang, Q., Chen, P., Zhang, X., and Lu, S. Mitigating object hallucinations in large vision-language models with assembly of global and local attention. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 29915--29926, 2025
2025
-
[2]
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., and Shou, M. Z. Hallucination of multimodal large language models: A survey, 2025. URL https://arxiv.org/abs/2404.18930
Pith/arXiv arXiv 2025
-
[3]
Q., Jia, J., Qin, W., Tang, R., and Pavlovic, V
Che, L., Liu, T. Q., Jia, J., Qin, W., Tang, R., and Pavlovic, V. Hallucinatory image tokens: A training-free eazy approach on detecting and mitigating object hallucinations in lvlms, 2025. URL https://arxiv.org/abs/2503.07772
arXiv 2025
-
[5]
Chen, X., Zhang, Y., Liu, Q., Wu, J., Zhang, F., and Tan, T. Mixture of decoding: An attention-inspired adaptive decoding strategy to mitigate hallucinations in large vision-language models, 2025. URL https://arxiv.org/abs/2505.17061
arXiv 2025
-
[6]
Halc: Object hallucination reduction via adaptive focal-contrast decoding, 2024
Chen, Z., Zhao, Z., Luo, H., Yao, H., Li, B., and Zhou, J. Halc: Object hallucination reduction via adaptive focal-contrast decoding, 2024. URL https://arxiv.org/abs/2403.00425
arXiv 2024
-
[7]
N., and Hoi, S
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P. N., and Hoi, S. Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems, 36: 0 49250--49267, 2023
2023
-
[8]
Mitigating hallucination in large vision-language models via adaptive attention calibration, 2025
Fazli, M., Wei, B., Sari, A., and Zhu, Z. Mitigating hallucination in large vision-language models via adaptive attention calibration, 2025. URL https://arxiv.org/abs/2505.21472
Pith/arXiv arXiv 2025
-
[9]
Mme: A comprehensive evaluation benchmark for multimodal large language models
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al. Mme: A comprehensive evaluation benchmark for multimodal large language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[11]
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., and Yu, N. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13418--13427, 2024 b
2024
-
[12]
Self-introspective decoding: Alleviating hallucinations for large vision-language models, 2025
Huo, F., Xu, W., Zhang, Z., Wang, H., Chen, Z., and Zhao, P. Self-introspective decoding: Alleviating hallucinations for large vision-language models, 2025. URL https://arxiv.org/abs/2408.02032
arXiv 2025
-
[13]
Leng, S., Xing, Y., Cheng, Z., Zhou, Y., Zhang, H., Li, X., Zhao, D., Lu, S., Miao, C., and Bing, L. The curse of multi-modalities: Evaluating hallucinations of large multimodal models across language, visual, and audio, 2024 a . URL https://arxiv.org/abs/2410.12787
arXiv 2024
-
[14]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., and Bing, L. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13872--13882, 2024 b
2024
-
[15]
Li, J., Zhang, J., Jie, Z., Ma, L., and Li, G. Mitigating hallucination for large vision language model by inter-modality correlation calibration decoding, 2025. URL https://arxiv.org/abs/2501.01926
Pith/arXiv arXiv 2025
-
[17]
Mitigating hallucination in large multi-modal models via robust instruction tuning, 2024 a
Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., and Wang, L. Mitigating hallucination in large multi-modal models via robust instruction tuning, 2024 a . URL https://arxiv.org/abs/2306.14565
Pith/arXiv arXiv 2024
-
[18]
Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual instruction tuning. Advances in neural information processing systems, 36: 0 34892--34916, 2023
2023
-
[19]
Paying more attention to image: A training-free method for alleviating hallucination in lvlms
Liu, S., Zheng, K., and Chen, W. Paying more attention to image: A training-free method for alleviating hallucination in lvlms. In European Conference on Computer Vision, pp.\ 125--140. Springer, 2024 b
2024
-
[20]
Debiasing intrinsic bias and application bias jointly via invariant risk minimization (student abstract)
Mao, Y., Yu, L., Yang, Y., Zhou, F., and Zhong, T. Debiasing intrinsic bias and application bias jointly via invariant risk minimization (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp.\ 16280--16281, 2023
2023
-
[21]
Nie, J., Zhang, G., An, W., Xing, Y., Tan, Y.-P., Kot, A. C., and Lu, S. Mmrel: Benchmarking relation understanding in multi-modal large language models, 2025. URL https://arxiv.org/abs/2406.09121
arXiv 2025
-
[22]
Causality
Pearl, J. Causality. Cambridge university press, 2009
2009
-
[24]
Aligning large multimodal models with factually augmented rlhf, 2023
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L.-Y., Wang, Y.-X., Yang, Y., Keutzer, K., and Darrell, T. Aligning large multimodal models with factually augmented rlhf, 2023. URL https://arxiv.org/abs/2309.14525
Pith/arXiv arXiv 2023
-
[25]
Drivevlm: The convergence of autonomous driving and large vision-language models, 2024
Tian, X., Gu, J., Li, B., Liu, Y., Wang, Y., Zhao, Z., Zhan, K., Jia, P., Lang, X., and Zhao, H. Drivevlm: The convergence of autonomous driving and large vision-language models, 2024. URL https://arxiv.org/abs/2402.12289
Pith/arXiv arXiv 2024
-
[27]
Instructpart: Task-oriented part segmentation with instruction reasoning, 2025
Wan, Z., Xie, Y., Zhang, C., Lin, Z., Wang, Z., Stepputtis, S., Ramanan, D., and Sycara, K. Instructpart: Task-oriented part segmentation with instruction reasoning, 2025. URL https://arxiv.org/abs/2505.18291
arXiv 2025
-
[28]
Chatcad: Interactive computer-aided diagnosis on medical image using large language models, 2023
Wang, S., Zhao, Z., Ouyang, X., Wang, Q., and Shen, D. Chatcad: Interactive computer-aided diagnosis on medical image using large language models, 2023. URL https://arxiv.org/abs/2302.07257
arXiv 2023
-
[30]
The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023
Yang, Z., Li, L., Lin, K., Wang, J., Lin, C.-C., Liu, Z., and Wang, L. The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023. URL https://arxiv.org/abs/2309.17421
Pith/arXiv arXiv 2023
-
[31]
Mixup-based unified framework to overcome gender bias resurgence
Yu, L., Mao, Y., Wu, J., and Zhou, F. Mixup-based unified framework to overcome gender bias resurgence. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.\ 1755--1759, 2023
2023
-
[32]
Biases mitigation and expressiveness preservation in language models: A comprehensive pipeline (student abstract)
Yu, L., Guo, L., Kuang, P., and Zhou, F. Biases mitigation and expressiveness preservation in language models: A comprehensive pipeline (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 23701--23702, 2024
2024
-
[33]
Bridging the fairness gap: Enhancing pre-trained models with llm-generated sentences
Yu, L., Guo, L., Kuang, P., and Zhou, F. Bridging the fairness gap: Enhancing pre-trained models with llm-generated sentences. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2025 a
2025
-
[34]
Bimodal debiasing for text-to-image diffusion: Adaptive guidance in textual and visual spaces
Yu, L., Sun, J., Kuang, P., Zhou, R., Zhou, F., and Feng, Z. Bimodal debiasing for text-to-image diffusion: Adaptive guidance in textual and visual spaces. In Proceedings of the 33rd ACM International Conference on Multimedia, pp.\ 11249--11258, 2025 b
2025
-
[35]
Amplifying commonsense knowledge via bi-directional relation integrated graph-based contrastive pre-training from large language models
Yu, L., Tian, F., Kuang, P., and Zhou, F. Amplifying commonsense knowledge via bi-directional relation integrated graph-based contrastive pre-training from large language models. Information Processing & Management, 62 0 (3): 0 104068, 2025 c
2025
-
[36]
Causally-grounded dual-path attention intervention for object hallucination mitigation in lvlms
Yu, L., Chen, Z., Kuang, P., Feng, Z., Zhou, F., Wang, L., and Dobbie, G. Causally-grounded dual-path attention intervention for object hallucination mitigation in lvlms. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 36021--36029, 2026
2026
-
[37]
Q., Stepputtis, S., Ramanan, D., Salakhutdinov, R., Morency, L.-P., Sycara, K., and Xie, Y
Zhang, C., Wan, Z., Kan, Z., Ma, M. Q., Stepputtis, S., Ramanan, D., Salakhutdinov, R., Morency, L.-P., Sycara, K., and Xie, Y. Self-correcting decoding with generative feedback for mitigating hallucinations in large vision-language models, 2025. URL https://arxiv.org/abs/2502.06130
arXiv 2025
-
[38]
Zhao, J., Zhang, F., Sun, X., and Feng, C. Mitigating hallucination in large vision-language models through aligning attention distribution to information flow, 2025. URL https://arxiv.org/abs/2505.14257
arXiv 2025
-
[39]
Causal-debias: Unifying debiasing in pretrained language models and fine-tuning via causal invariant learning
Zhou, F., Mao, Y., Yu, L., Yang, Y., and Zhong, T. Causal-debias: Unifying debiasing in pretrained language models and fine-tuning via causal invariant learning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 4227--4241, 2023
2023
-
[40]
Mitigating modality prior-induced hallucinations in multimodal large language models via deciphering attention causality
Zhou, G., Yan, Y., Zou, X., Wang, K., Liu, A., and Hu, X. Mitigating modality prior-induced hallucinations in multimodal large language models via deciphering attention causality. In ICLR, 2025
2025
-
[41]
Analyzing and mitigating object hallucination in large vision-language models, 2024
Zhou, Y., Cui, C., Yoon, J., Zhang, L., Deng, Z., Finn, C., Bansal, M., and Yao, H. Analyzing and mitigating object hallucination in large vision-language models, 2024. URL https://arxiv.org/abs/2310.00754
Pith/arXiv arXiv 2024
-
[42]
Alleviating hallucinations in large language models through multi-model contrastive decoding and dynamic hallucination detection
Zhu, C., Liu, Y., Zhang, H., Wang, A., Chen, G., Wang, L., Luo, W., and Zhang, K. Alleviating hallucinations in large language models through multi-model contrastive decoding and dynamic hallucination detection. Advances in Neural Information Processing Systems, 38: 0 165364--165388, 2026
2026
-
[44]
arXiv preprint arXiv:2304.10592 , year=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
-
[45]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[46]
Proceedings of the 31st ACM international conference on multimedia , pages=
Towards deconfounded image-text matching with causal inference , author=. Proceedings of the 31st ACM international conference on multimedia , pages=
-
[47]
arXiv preprint arXiv:2210.15097 , year=
Contrastive decoding: Open-ended text generation as optimization , author=. arXiv preprint arXiv:2210.15097 , year=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
ICLR , year=
Mitigating modality prior-induced hallucinations in multimodal large language models via deciphering attention causality , author=. ICLR , year=
-
[50]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
arXiv preprint arXiv:2506.17462 , year=
General-Purpose Robotic Navigation via LVLM-Orchestrated Perception, Reasoning, and Acting , author=. arXiv preprint arXiv:2506.17462 , year=
-
[53]
arXiv preprint arXiv:2306.15195 , year=
Shikra: Unleashing multimodal llm's referential dialogue magic , author=. arXiv preprint arXiv:2306.15195 , year=
-
[54]
2023 , eprint=
MultiModal-GPT: A Vision and Language Model for Dialogue with Humans , author=. 2023 , eprint=
2023
-
[55]
2023 , publisher=
Stanford alpaca: An instruction-following llama model , author=. 2023 , publisher=
2023
-
[56]
ChatGPT outperforms crowd workers for text-annotation tasks , volume=
Gilardi, Fabrizio and Alizadeh, Meysam and Kubli, Maël , year=. ChatGPT outperforms crowd workers for text-annotation tasks , volume=. Proceedings of the National Academy of Sciences , publisher=. doi:10.1073/pnas.2305016120 , number=
-
[57]
arXiv preprint arXiv:2308.12966 , volume=
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv preprint arXiv:2308.12966 , volume=
-
[58]
2025 , eprint=
Otter: A Multi-Modal Model with In-Context Instruction Tuning , author=. 2025 , eprint=
2025
-
[59]
Transactions on machine learning research , year=
International conference on machine learning , author=. Transactions on machine learning research , year=
-
[60]
2019 , eprint=
VisualBERT: A Simple and Performant Baseline for Vision and Language , author=. 2019 , eprint=
2019
-
[61]
2023 , eprint=
Aligning Large Multimodal Models with Factually Augmented RLHF , author=. 2023 , eprint=
2023
-
[62]
2024 , eprint=
Analyzing and Mitigating Object Hallucination in Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[63]
2024 , eprint=
Negative Object Presence Evaluation (NOPE) to Measure Object Hallucination in Vision-Language Models , author=. 2024 , eprint=
2024
-
[64]
2023 , eprint=
Evaluation and Analysis of Hallucination in Large Vision-Language Models , author=. 2023 , eprint=
2023
-
[65]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[66]
2023 , eprint=
REPLUG: Retrieval-Augmented Black-Box Language Models , author=. 2023 , eprint=
2023
-
[67]
2025 , eprint=
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. 2025 , eprint=
2025
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards causal vqa: Revealing and reducing spurious correlations by invariant and covariant semantic editing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[69]
2016 , eprint=
Analyzing the Behavior of Visual Question Answering Models , author=. 2016 , eprint=
2016
-
[70]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[71]
2022 , eprint=
Visual Perturbation-aware Collaborative Learning for Overcoming the Language Prior Problem , author=. 2022 , eprint=
2022
-
[72]
2024 , eprint=
Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision , author=. 2024 , eprint=
2024
-
[73]
2024 , eprint=
IBD: Alleviating Hallucinations in Large Vision-Language Models via Image-Biased Decoding , author=. 2024 , eprint=
2024
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
2024 , eprint=
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. 2024 , eprint=
2024
-
[76]
2009 , publisher=
Causality , author=. 2009 , publisher=
2009
-
[77]
arXiv preprint arXiv:1809.02156 , year=
Object hallucination in image captioning , author=. arXiv preprint arXiv:1809.02156 , year=
-
[78]
arXiv preprint arXiv:2509.25177 , year=
Mitigating Hallucination in Multimodal LLMs with Layer Contrastive Decoding , author=. arXiv preprint arXiv:2509.25177 , year=
-
[79]
Advances in Neural Information Processing Systems , volume=
Alleviating hallucinations in large language models through multi-model contrastive decoding and dynamic hallucination detection , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
arXiv preprint arXiv:2412.02946 , year=
Who Brings the Frisbee: Probing Hidden Hallucination Factors in Large Vision-Language Model via Causality Analysis , author=. arXiv preprint arXiv:2412.02946 , year=
-
[81]
IEEE Transactions on Information theory , volume=
Divergence measures based on the Shannon entropy , author=. IEEE Transactions on Information theory , volume=. 2002 , publisher=
2002
-
[82]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[83]
arXiv preprint arXiv:2305.10355 , year=
Evaluating object hallucination in large vision-language models , author=. arXiv preprint arXiv:2305.10355 , year=
-
[84]
arXiv preprint arXiv:2403.18715 , year=
Mitigating hallucinations in large vision-language models with instruction contrastive decoding , author=. arXiv preprint arXiv:2403.18715 , year=
-
[85]
2025 , eprint=
Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models , author=. 2025 , eprint=
2025
-
[86]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[87]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mitigating object hallucinations in large vision-language models with assembly of global and local attention , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.