CSD: Content-aware Speculative Decoding for Efficient Image Generation
Pith reviewed 2026-06-29 04:48 UTC · model grok-4.3
The pith
Content-aware speculative decoding raises token acceptance in low-entropy image regions while a filter keeps the output distribution aligned with the target model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
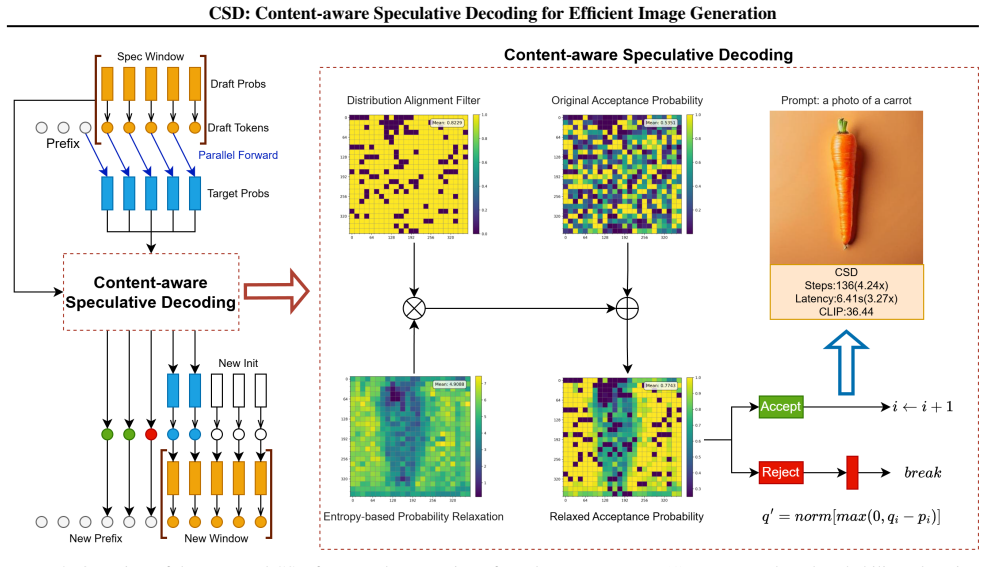
CSD integrates an entropy-based probability relaxation mechanism with an optimal resampling strategy to enhance the inference efficiency for autoregressive image generation. By leveraging the informational uncertainty inherent in different regions of an image, CSD dynamically adjusts the acceptance probability of candidate tokens, increasing the acceptance rate in low-detail areas to accelerate generation. Moreover, a distribution alignment filter is introduced to ensure the output distribution to be aligned with the target model, which significantly improves the generative quality.
What carries the argument
The entropy-based probability relaxation mechanism paired with a distribution alignment filter, which raises acceptance thresholds according to regional uncertainty and then corrects distribution drift.
If this is right
- Acceptance rates rise in uniform or low-detail image regions, shortening the number of forward passes required.
- The alignment filter restores distributional match, so final image statistics remain close to those of the original target model.
- Overall wall-clock inference time decreases while preserving the generative quality that standard speculative decoding would achieve.
- The method applies directly to any autoregressive image model that already supports speculative decoding.
Where Pith is reading between the lines
- The same entropy-driven relaxation could be tested on autoregressive models for other modalities such as audio or video sequences.
- One could measure whether the added entropy computation overhead ever offsets the acceptance-rate gains on very small images.
- Adaptive per-layer entropy thresholds might further improve the speed-quality trade-off beyond the fixed mechanism described.
Load-bearing premise
Dynamically raising acceptance probabilities in low-entropy regions will not introduce visible artifacts or distribution shifts that the alignment filter cannot fully correct.
What would settle it
Generate the same prompts with both CSD and standard decoding on an autoregressive image model, then compare perceptual quality metrics and side-by-side human judgments; a clear drop in the CSD outputs would falsify the claim.
Figures





read the original abstract
Speculative decoding (SD) has emerged as a key solution to accelerate the inference of autoregressive models. However, in the field of image generation, it faces the challenge of low acceptance rates, and directly relaxing its criteria leads to degradation in image quality. In this paper, we propose a novel content-aware speculative decoding algorithm, termed CSD, which integrates an entropy-based probability relaxation mechanism with an optimal resampling strategy to enhance the inference efficiency for autoregressive image generation. By leveraging the informational uncertainty inherent in different regions of an image, CSD dynamically adjusts the acceptance probability of candidate tokens, increasing the acceptance rate in low-detail areas to accelerate generation. Moreover, a distribution alignment filter is introduced to ensure the output distribution to be aligned with the target model, which significantly improves the generative quality. Experiments conducted on Lumina-mGPT and Janus-Pro demonstrate that the superiority of the proposed CSD. Our source code is available at https://github.com/aderfebr/CSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CSD, a content-aware speculative decoding method for autoregressive image generation. It combines an entropy-based probability relaxation mechanism and optimal resampling to raise acceptance rates in low-detail (low-entropy) image regions, together with a distribution alignment filter intended to restore equivalence to the target model's output distribution. Experiments on Lumina-mGPT and Janus-Pro are asserted to show superiority over standard speculative decoding, and source code is released.
Significance. If the central claims hold, CSD could provide a practical, content-adaptive acceleration technique for large autoregressive image models by exploiting regional uncertainty, which is relevant for efficient inference. The open release of source code is a clear strength that supports reproducibility and follow-up work.
major comments (3)
- [§3] §3 (Distribution alignment filter): The claim that the filter 'ensures the output distribution to be aligned with the target model' and 'significantly improves generative quality' lacks any derivation, theorem, or quantitative bound (e.g., on total variation distance or KL divergence) demonstrating that it fully corrects the distributional shift induced by entropy-based relaxation rather than providing only an approximate mitigation. This is load-bearing for the central efficiency-without-quality-loss claim.
- [§4] §4 (Experiments): No ablation isolating the contribution of the alignment filter versus the relaxation mechanism is reported, nor are quantitative results, baselines, or error bars supplied for the two named models; without these, it is impossible to verify whether residual artifacts remain in regions where acceptance probability is most aggressively raised.
- [§3.1] §3.1 (Entropy-based relaxation): The description of dynamically raising acceptance probability in low-entropy regions contains no analysis of the resulting bias before the filter is applied, leaving open whether the subsequent filter can always restore exact equivalence as asserted.
minor comments (2)
- [Abstract] Abstract: The final sentence is grammatically incomplete ('demonstrate that the superiority of the proposed CSD').
- [§3] Notation: The terms 'optimal resampling strategy' and 'distribution alignment filter' are introduced without explicit algorithmic pseudocode or parameter definitions in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate planned revisions to improve the manuscript's rigor.
read point-by-point responses
-
Referee: [§3] §3 (Distribution alignment filter): The claim that the filter 'ensures the output distribution to be aligned with the target model' and 'significantly improves generative quality' lacks any derivation, theorem, or quantitative bound (e.g., on total variation distance or KL divergence) demonstrating that it fully corrects the distributional shift induced by entropy-based relaxation rather than providing only an approximate mitigation. This is load-bearing for the central efficiency-without-quality-loss claim.
Authors: We acknowledge that the manuscript asserts alignment without a formal derivation or quantitative bounds such as TV distance or KL divergence. The filter resamples from the target distribution after relaxation to mitigate shift, supported by empirical quality gains. We agree a rigorous analysis is needed and will add a derivation of the filter's effect along with empirical KL/TV measurements before and after the filter in the revision. revision: partial
-
Referee: [§4] §4 (Experiments): No ablation isolating the contribution of the alignment filter versus the relaxation mechanism is reported, nor are quantitative results, baselines, or error bars supplied for the two named models; without these, it is impossible to verify whether residual artifacts remain in regions where acceptance probability is most aggressively raised.
Authors: We agree that the experiments lack isolating ablations, detailed quantitative results, baselines, and error bars. The revised manuscript will add an ablation study separating the relaxation mechanism from the alignment filter, plus full quantitative metrics, acceptance rates, quality scores, baselines, and error bars for Lumina-mGPT and Janus-Pro to enable verification of performance and artifacts. revision: yes
-
Referee: [§3.1] §3.1 (Entropy-based relaxation): The description of dynamically raising acceptance probability in low-entropy regions contains no analysis of the resulting bias before the filter is applied, leaving open whether the subsequent filter can always restore exact equivalence as asserted.
Authors: The relaxation adjusts acceptance based on local entropy to exploit content variation. We recognize the absence of pre-filter bias analysis. In revision we will include an analysis of the bias induced by relaxation and clarify the filter's ability to restore equivalence, noting any limitations where correction is approximate rather than exact. revision: partial
Circularity Check
No circularity: algorithmic proposal is self-contained
full rationale
The paper introduces CSD as a new speculative decoding algorithm combining entropy-based relaxation, optimal resampling, and a distribution alignment filter. No equations, fitted parameters, or derivations are shown that reduce by construction to the method's own inputs or prior self-citations. The central claims rest on the design of the components and reported experiments rather than any self-definitional or load-bearing self-referential step. This is the expected outcome for a methods paper presenting an independent algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cao, K., Wang, J., Ma, A., Feng, J., Zhang, Z., He, X., Liu, S., Cheng, B., Leng, D., Yin, Y ., et al. Relactrl: Relevance-guided efficient control for diffusion trans- formers.arXiv preprint arXiv:2502.14377,
-
[3]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and Ruan, C. Janus-pro: Unified multimodal understand- ing and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Y ., Jung, Y ., Yun, J., Kundu, S., Kim, S.-Y ., and Yang, E
Jang, D., Park, S., Yang, J. Y ., Jung, Y ., Yun, J., Kundu, S., Kim, S.-Y ., and Yang, E. Lantern: Accelerating visual autoregressive models with relaxed speculative decoding. arXiv preprint arXiv:2410.03355,
-
[5]
Kang, Z., Zhao, X., and Song, D. Scalable best-of-n selec- tion for large language models via self-certainty.arXiv preprint arXiv:2502.18581,
-
[6]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Li, Y ., Wei, F., Zhang, C., and Zhang, H. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Liu, D., Zhao, S., Zhuo, L., Lin, W., Xin, Y ., Li, X., Qin, Q., Qiao, Y ., Li, H., and Gao, P. Lumina-mgpt: Illu- minate flexible photorealistic text-to-image generation with multimoda...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Salimans, T., Karpathy, A., Chen, X., and Kingma, D. P. Pixelcnn++: Improving the pixelcnn with discretized lo- gistic mixture likelihood and other modifications.arXiv preprint arXiv:1701.05517,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
10 CSD: Content-aware Speculative Decoding for Efficient Image Generation Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding
Teng, Y ., Shi, H., Liu, X., Ning, X., Dai, G., Wang, Y ., Li, Z., and Liu, X. Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding. arXiv preprint arXiv:2410.01699,
-
[12]
Teng, Y ., Wang, F., Liu, X., Chen, Z., Shi, H., Wang, Y ., Li, Z., Liu, W., Zou, D., and Liu, X. Speculative jacobi- denoising decoding for accelerating autoregressive text- to-image generation.arXiv preprint arXiv:2510.08994,
-
[13]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.