SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
Pith reviewed 2026-06-29 04:01 UTC · model grok-4.3
The pith
A video-to-simulation system creates digital twins that enable zero-shot transfer of robot policies from simulation to real multi-step manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
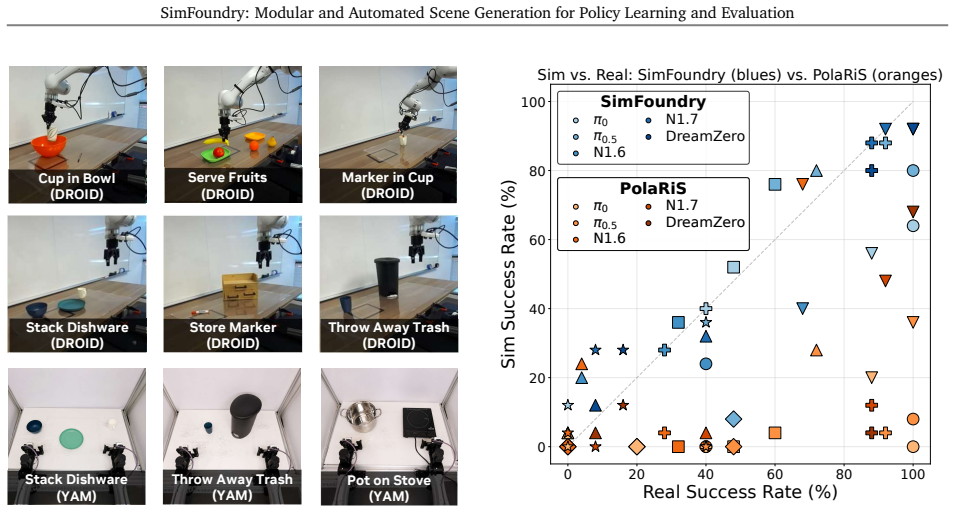
SimFoundry automates the construction of digital twins from video and the generation of affordance-preserving variations, resulting in policies that transfer zero-shot to real tasks involving multi-step manipulation, articulated objects, and bimanual interaction, with simulation evaluations correlating at a mean Pearson value of 0.911 to real performance and yielding success rate gains of 17 to 40 percent when training on variations.
What carries the argument
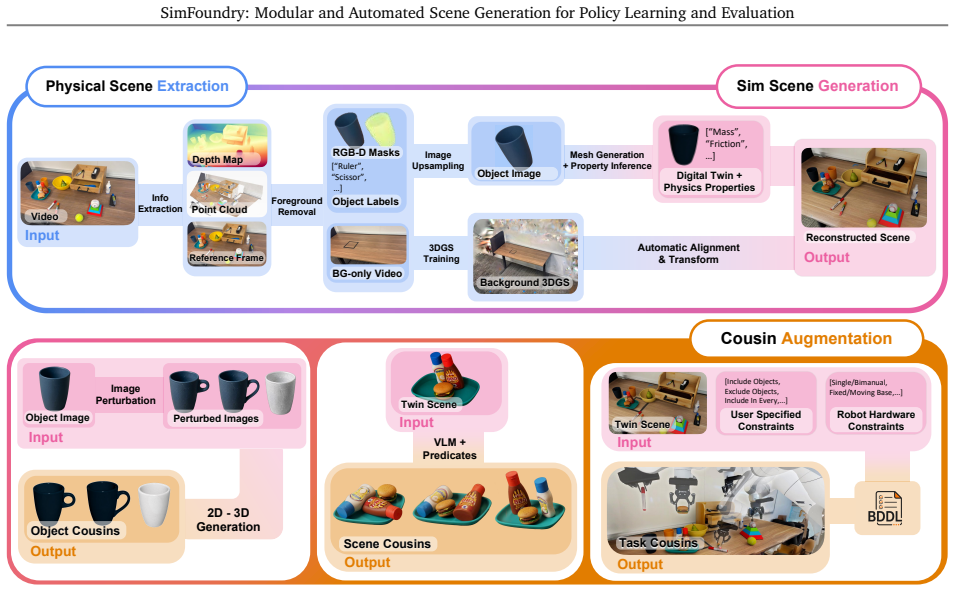
The SimFoundry system for modular automated real-to-sim scene construction from video, which produces sim-ready digital twins and supports object, scene, and task editing for digital cousins.
If this is right
- Policies trained in SimFoundry transfer zero-shot to challenging real tasks.
- Simulation evaluations predict real-world performance with mean Pearson correlation 0.911.
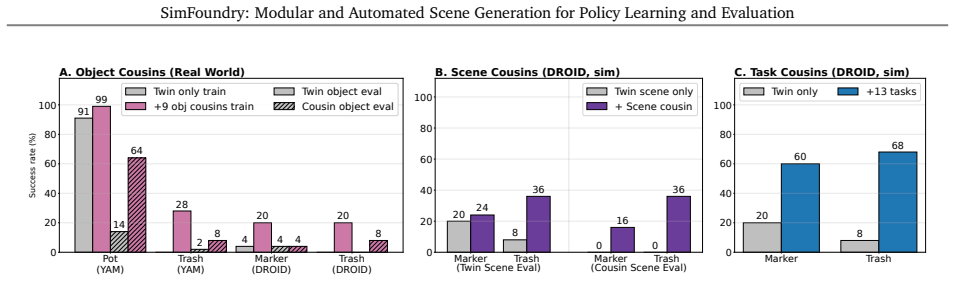
- Training with digital cousins improves real success rates by average 17% for object variations, 21% for scene, and 40% for task.
- The correlation holds across 7 manipulation tasks and 5 policy architectures.
Where Pith is reading between the lines
- The method could be applied to generate large datasets for training more general robot policies beyond the tested tasks.
- High sim-real correlation might allow using simulation for hyperparameter tuning and architecture selection without real tests.
- Extending the automation to include physics parameter tuning could further improve transfer fidelity.
Load-bearing premise
The digital twins and cousins must preserve real-world physics, contact dynamics, and affordances without simulation artifacts that would break the transfer or correlation.
What would settle it
Observation of low or negative correlation between simulation and real-world policy performance rankings on the 7 tasks, or failure of zero-shot transfer on the described manipulation tasks.
Figures


read the original abstract
Training and evaluating robot policies in the real world is costly and difficult to scale. We introduce SimFoundry, a modular and automated system for zero-shot real-to-sim scene construction from a video. SimFoundry generates sim-ready digital twins and supports object, scene, and task editing, enabling the automated generation of diverse digital cousins: affordance-preserving variations of reconstructed real-world scenes. Policies trained on SimFoundry data transfer zero-shot to challenging real tasks involving multi-step manipulation, articulated object interaction, and bimanual interaction, and its digital cousins (variations of the original scene, objects, and tasks) facilitate generalization to new real-world conditions. Across 7 manipulation tasks and 5 policy architectures, SimFoundry simulation evaluations strongly predict real-world performance, with mean Pearson correlation 0.911 and mean maximum ranking violation 0.018. When evaluating sim-trained policies zero-shot in the real world, policies trained with object, scene, and task cousins in simulation show average task success rate improvements of 17%, 21%, and 40%, respectively. Additional details at https://research.nvidia.com/labs/gear/simfoundry/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SimFoundry, a modular automated pipeline that reconstructs sim-ready digital twins from single videos and generates affordance-preserving variations (object, scene, and task cousins). It reports zero-shot transfer of policies trained in these environments to real multi-step, articulated, and bimanual manipulation tasks, together with a mean Pearson correlation of 0.911 between SimFoundry simulation metrics and real-world performance across 7 tasks and 5 policy architectures; training on cousins yields average success-rate gains of 17–40 %.
Significance. If the empirical claims hold after validation, the work would provide a practical route to scalable, automated generation of diverse training and evaluation data for robot learning, directly addressing the cost and safety barriers of real-world data collection while supplying a quantitative predictor of sim-to-real transfer.
major comments (2)
- [Methods and Results (implicit in abstract claims)] The central claims of zero-shot transfer and 0.911 mean Pearson correlation presuppose that the generated digital twins faithfully reproduce real contact dynamics, friction, and object affordances. No quantitative validation against real force/torque measurements, high-speed contact trajectories, or parameter-fitting experiments is reported in the methods or results sections, leaving open the possibility that the observed correlation arises primarily on tasks where dynamics mismatches are irrelevant.
- [Abstract and evaluation sections] The reported quantitative results (0.911 correlation, 17/21/40 % gains) are presented without accompanying details on data exclusion criteria, per-task error bars, statistical significance tests, or the precise definition of “maximum ranking violation,” which are required to evaluate the robustness of the cross-architecture and cross-task claims.
minor comments (2)
- [Introduction / System Overview] The term “digital cousins” and the precise mechanism by which they preserve affordances while varying geometry, mass, or task parameters should be defined explicitly with an accompanying figure or pseudocode.
- [Figures] Figure captions and axis labels in the correlation plots should include the exact number of policy–task pairs and the confidence intervals on the Pearson coefficients.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with honest assessment of what the current manuscript contains and where revisions are warranted.
read point-by-point responses
-
Referee: The central claims of zero-shot transfer and 0.911 mean Pearson correlation presuppose that the generated digital twins faithfully reproduce real contact dynamics, friction, and object affordances. No quantitative validation against real force/torque measurements, high-speed contact trajectories, or parameter-fitting experiments is reported in the methods or results sections, leaving open the possibility that the observed correlation arises primarily on tasks where dynamics mismatches are irrelevant.
Authors: We agree that the manuscript does not report direct quantitative validation of contact dynamics (force/torque, high-speed trajectories, or parameter fitting). The SimFoundry contribution centers on automated video-to-sim reconstruction of geometry, appearance, and task affordances, with empirical evidence that simulation metrics correlate with real-world policy performance across the evaluated tasks. These tasks include contact (grasping, pushing, articulated interaction), yet we did not conduct separate dynamics identification experiments. In revision we will add an explicit limitations paragraph in the Discussion that states the absence of such validation and notes that the reported correlation is an empirical, task-level observation rather than a claim of full physical fidelity. We will also clarify that digital cousins are designed to preserve affordances at the task level. revision: partial
-
Referee: The reported quantitative results (0.911 correlation, 17/21/40 % gains) are presented without accompanying details on data exclusion criteria, per-task error bars, statistical significance tests, or the precise definition of “maximum ranking violation,” which are required to evaluate the robustness of the cross-architecture and cross-task claims.
Authors: We acknowledge that the current presentation of aggregate metrics lacks the requested supporting details. In the revised manuscript we will expand the evaluation section (and add an appendix) to report: per-task Pearson correlations with standard-error bars from multiple random seeds; an explicit statement that no tasks were excluded (all seven are included); p-values or other significance tests for the correlations; and the precise definition and computation of “maximum ranking violation.” These additions will be placed in the main text or supplementary material so readers can assess robustness across architectures and tasks. revision: yes
Circularity Check
No circularity: purely empirical system and evaluation results
full rationale
The paper describes an automated scene generation pipeline (SimFoundry) and reports empirical outcomes: zero-shot sim-to-real policy transfer success rates, Pearson correlations (0.911) between sim and real performance across 7 tasks and 5 architectures, and relative gains from digital cousins. These are direct measurements against external real-world benchmarks rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, ansatzes, or uniqueness theorems appear in the provided text; the central claims rest on observed task success and correlation numbers, not on internal reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A bayesian treatment of real-to-sim for deformable object manipulation.IEEE Robotics and Automation Letters, 7(3):5819–5826, 2022
Rika Antonova, Jingyun Yang, Priya Sundaresan, Dieter Fox, Fabio Ramos, and Jeannette Bohg. A bayesian treatment of real-to-sim for deformable object manipulation.IEEE Robotics and Automation Letters, 7(3):5819–5826, 2022. 3
2022
-
[2]
Scan2cad: Learning cad model alignment in rgb-d scans
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X Chang, and Matthias Nießner. Scan2cad: Learning cad model alignment in rgb-d scans. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 2614–2623, 2019. 3
2019
-
[3]
Apurva Badithela, David Snyder, Lihan Zha, Joseph Mikhail, Matthew O’Kelly, Anushri Dixit, and Anirudha Majumdar. Reliable and scalable robot policy evaluation with imperfect simulators.arXiv preprint arXiv:2510.04354, 2025. 2, 3, 21
arXiv 2025
-
[4]
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331, 2025. 2
Pith/arXiv arXiv 2025
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.𝜋0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 2, 7, 21
Pith/arXiv arXiv 2024
-
[6]
Rt-1: Robotics transformer for real- world control at scale.arXiv preprint arXiv:2212.06817, 2022
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real- world control at scale.arXiv preprint arXiv:2212.06817, 2022. 2, 21
Pith/arXiv arXiv 2022
-
[7]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023. 21
Pith/arXiv arXiv 2023
-
[8]
Sauser, Darwin G
Sylvain Calinon, Florent D’halluin, Eric L. Sauser, Darwin G. Caldwell, and Aude Billard. Learning and reproduction of gestures by imitation.IEEE Robotics and Automation Magazine, 17, 2010. 21
2010
-
[9]
Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M. Dollar. The ycbobjectandmodelset: Towardscommonbenchmarksformanipulationresearch. In2015International Conference on Advanced Robotics (ICAR), pages 510–517, 2015. doi: 10.1109/ICAR.2015.7251504. 47
-
[10]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chai- tanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Lilian...
2025
-
[11]
Freeart3d: Training-free articulated object generation using 3d diffusion
Chuhao Chen, Isabella Liu, Xinyue Wei, Hao Su, and Minghua Liu. Freeart3d: Training-free articulated object generation using 3d diffusion. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–13, 2025. 3 10 SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
2025
-
[12]
Zoey Chen, Aaron Walsman, Marius Memmel, Kaichun Mo, Alex Fang, Karthikeya Vemuri, Alan Wu, Dieter Fox, and Abhishek Gupta. Urdformer: A pipeline for constructing articulated simulation environ- ments from real-world images.arXiv preprint arXiv:2405.11656, 2024. 3
arXiv 2024
-
[13]
Shuo Cheng, Liqian Ma, Zhenyang Chen, Ajay Mandlekar, Caelan Garrett, and Danfei Xu. Generalizable domain adaptation for sim-and-real policy co-training.arXiv preprint arXiv:2509.18631, 2025. 2, 21
arXiv 2025
-
[14]
Embodiedsplat: Personalized real-to-sim-to-real navigation with gaussian splats from a mobile device
GunjanChhablani,XiaomengYe,MuhammadZubairIrshad,andZsoltKira. Embodiedsplat: Personalized real-to-sim-to-real navigation with gaussian splats from a mobile device. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25431–25441, 2025. 3, 21
2025
-
[15]
Diffusion policy: Visuomotor policy learning via action diffusion.The Int’l Journal of Robotics Research, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The Int’l Journal of Robotics Research, 2023. 21
2023
-
[16]
Pybullet, a python module for physics simulation for games, robotics and machine learning.http://pybullet.org, 2016–2021
Erwin Coumans and Yunfei Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning.http://pybullet.org, 2016–2021. 5
2016
-
[17]
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning.arXiv preprint arXiv:2410.07408, 2024. 2, 3, 4, 8, 21, 36
arXiv 2024
-
[18]
Imitating task and motion planning with visuomotor transformers
Murtaza Dalal, Ajay Mandlekar, Caelan Reed Garrett, Ankur Handa, Ruslan Salakhutdinov, and Dieter Fox. Imitating task and motion planning with visuomotor transformers. InConf on Robot Learning,
-
[19]
X-sim: Cross-embodiment learning via real-to-sim-to-real.arXiv preprint arXiv:2505.07096, 2025
Prithwish Dan, Kushal Kedia, Angela Chao, Edward Weiyi Duan, Maximus Adrian Pace, Wei-Chiu Ma, and Sanjiban Choudhury. X-sim: Cross-embodiment learning via real-to-sim-to-real.arXiv preprint arXiv:2505.07096, 2025. 2, 3
arXiv 2025
-
[20]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Dani- ilidis, Chelsea Finn, and Sergey Levine. Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets. InRobotics: Science and Systems, 2022. 2, 21
2022
-
[21]
Gaussgym: An open-source real-to-sim framework for learning locomotion from pixels
Alejandro Escontrela, Justin Kerr, Arthur Allshire, Jonas Frey, Rocky Duan, Carmelo Sferrazza, and Pieter Abbeel. Gaussgym: An open-source real-to-sim framework for learning locomotion from pixels. arXiv preprint arXiv:2510.15352, 2025. 3, 21
arXiv 2025
-
[22]
Diffcad: Weakly-supervised probabilistic cad model retrieval and alignment from an rgb image.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024
Daoyi Gao, Dávid Rozenberszki, Stefan Leutenegger, and Angela Dai. Diffcad: Weakly-supervised probabilistic cad model retrieval and alignment from an rgb image.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024. 3
2024
-
[23]
Caelan Garrett, Ajay Mandlekar, Bowen Wen, and Dieter Fox. Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment.arXiv preprint arXiv:2410.18907, 2024. 2, 21
arXiv 2024
-
[24]
Chenghao Gu, Haolan Kang, Junchao Lin, Jinghe Wang, Duo Wu, Shuzhao Xie, Fanding Huang, Junchen Ge, Ziyang Gong, Letian Li, et al. Igen: Scalable data generation for robot learning from open-world images.arXiv preprint arXiv:2512.01773, 2025. 3, 21
Pith/arXiv arXiv 2025
-
[25]
Roca: Robust cad model retrieval and alignment from a single image
Can Gümeli, Angela Dai, and Matthias Nießner. Roca: Robust cad model retrieval and alignment from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4022–4031, 2022. 3
2022
-
[26]
Siddhant Haldar, Lars Johannsmeier, Lerrel Pinto, Abhishek Gupta, Dieter Fox, Yashraj Narang, and Ajay Mandlekar. Point bridge: 3d representations for cross domain policy learning.arXiv preprint arXiv:2601.16212, 2026. 2, 21 11 SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
arXiv 2026
-
[27]
Xiaoshen Han, Minghuan Liu, Yilun Chen, Junqiu Yu, Xiaoyang Lyu, Yang Tian, Bolun Wang, Weinan Zhang, and Jiangmiao Pang. Re3sim: Generating high-fidelity simulation data via 3d-photorealistic real-to-sim for robotic manipulation.arXiv preprint arXiv:2502.08645, 2025. 2, 3, 21
arXiv 2025
-
[28]
Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023. 3
Pith/arXiv arXiv 2023
-
[29]
Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material, 2025
Team Hunyuan3D, Shuhui Yang, Mingxin Yang, Yifei Feng, Xin Huang, Sheng Zhang, Zebin He, Di Luo, Haolin Liu, Yunfei Zhao, Qingxiang Lin, Zeqiang Lai, Xianghui Yang, Huiwen Shi, Zibo Zhao, Bowen Zhang, Hongyu Yan, Lifu Wang, Sicong Liu, Jihong Zhang, Meng Chen, Liang Dong, Yiwen Jia, Yulin Cai, Jiaao Yu, Yixuan Tang, Dongyuan Guo, Junlin Yu, Hao Zhang, Zhe...
Pith/arXiv arXiv 2025
-
[30]
Movement imitation with nonlinear dynamical systems in humanoid robots.Proceedings 2002 IEEE Int’l Conf on Robotics and Automation, 2, 2002
Auke Jan Ijspeert, Jun Nakanishi, and Stefan Schaal. Movement imitation with nonlinear dynamical systems in humanoid robots.Proceedings 2002 IEEE Int’l Conf on Robotics and Automation, 2, 2002. 21
2002
-
[31]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.𝜋0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. 7, 8
Pith/arXiv arXiv 2025
-
[32]
Arhan Jain, Mingtong Zhang, Kanav Arora, William Chen, Marcel Torne, Muhammad Zubair Irshad, Sergey Zakharov, Yue Wang, Sergey Levine, Chelsea Finn, et al. Polaris: Scalable real-to-sim evaluations for generalist robot policies.arXiv preprint arXiv:2512.16881, 2025. 2, 3, 4, 7, 21, 34, 42, 43
arXiv 2025
-
[33]
RobotArena∞: Scalable robot benchmarking via real-to-sim translation
Yash Jangir, Yidi Zhang, Kashu Yamazaki, Chenyu Zhang, Kuan-Hsun Tu, Tsung-Wei Ke, Lei Ke, Yonatan Bisk, and Katerina Fragkiadaki. RobotArena∞: Scalable robot benchmarking via real-to-sim translation. arXiv preprint arXiv:2510.23571, 2025. 2, 3, 21
arXiv 2025
-
[34]
Gsworld: Closed-loop photo-realistic simulation suite for robotic manipulation
Guangqi Jiang, Haoran Chang, Ri-Zhao Qiu, Yutong Liang, Mazeyu Ji, Jiyue Zhu, Zhao Dong, Xueyan Zou, and Xiaolong Wang. Gsworld: Closed-loop photo-realistic simulation suite for robotic manipulation. arXiv preprint arXiv:2510.20813, 2025. 2, 3, 21
arXiv 2025
-
[35]
Yunfan Jiang, Ruohan Zhang, Josiah Wong, Chen Wang, Yanjie Ze, Hang Yin, Cem Gokmen, Shuran Song, Jiajun Wu, and Li Fei-Fei. Behavior robot suite: Streamlining real-world whole-body manipulation for everyday household activities.arXiv preprint arXiv:2503.05652, 2025. 39, 40
arXiv 2025
-
[36]
Ditto: Building digital twins of articulated objects from interaction
Zhenyu Jiang, Cheng-Chun Hsu, and Yuke Zhu. Ditto: Building digital twins of articulated objects from interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5616–5626, 2022. 3
2022
-
[37]
Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Fan, and Yuke Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning. arXiv preprint arXiv:2410.24185, 2024. 2, 4, 21
arXiv 2024
-
[38]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023. 6, 24, 25
2023
-
[39]
Droid: A large- scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
AlexanderKhazatsky, KarlPertsch, SurajNair, AshwinBalakrishna, SudeepDasari, SiddharthKaramcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large- scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. 2, 6, 21, 40 12 SimFoundry: Modular and Automated Scene Generation for Pol...
Pith/arXiv arXiv 2024
-
[40]
Molmospaces: A large-scale open ecosystem for robot navigation and manipulation, 2026
Yejin Kim, Wilbert Pumacay, Omar Rayyan, Max Argus, Winson Han, Eli VanderBilt, Jordi Salvador, Abhay Deshpande, Rose Hendrix, Snehal Jauhri, Shuo Liu, Nur Muhammad Mahi Shafiullah, Maya Guru, Ainaz Eftekhar, Karen Farley, Donovan Clay, Jiafei Duan, Arjun Guru, Piper Wolters, Alvaro Herrasti, Ying-Chun Lee, Georgia Chalvatzaki, Yuchen Cui, Ali Farhadi, Di...
2026
-
[41]
Mask2cad: 3d shape prediction by learning to segment and retrieve
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. Mask2cad: 3d shape prediction by learning to segment and retrieve. InEuropean Conference on Computer Vision, pages 260–277. Springer,
-
[42]
Patch2cad: Patchwise embedding learning for in-the-wild shape retrieval from a single image
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. Patch2cad: Patchwise embedding learning for in-the-wild shape retrieval from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12589–12599, 2021. 3
2021
-
[43]
Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Krishna, Dinesh Jayaraman, and Eric Eaton. Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model.arXiv preprint arXiv:2410.13882, 2024. 3, 5, 23
arXiv 2024
-
[44]
Any6d: Model-free 6d pose estimation of novel objects.CVPR, 2025
Taeyeop Lee, Bowen Wen, Minjun Kang, Gyuree Kang, In So Kweon, and Kuk-Jin Yoon. Any6d: Model-free 6d pose estimation of novel objects.CVPR, 2025. 3
2025
-
[45]
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023. 29
2023
-
[46]
Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation
Chengshu Li, Mengdi Xu, Arpit Bahety, Hang Yin, Yunfan Jiang, Huang Huang, Josiah Wong, Sujay Garlanka, Cem Gokmen, Ruohan Zhang, Weiyu Liu, Jiajun Wu, Roberto Martín-Martín, and Li Fei-Fei. Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation. InRSS 2025 Workshop on Whole-body Control and Bimanual...
2025
-
[47]
Evaluatingreal-worldrobotmanipulationpoliciesinsimulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat,IsabelSieh,SeanKirmani,etal. Evaluatingreal-worldrobotmanipulationpoliciesinsimulation. arXiv preprint arXiv:2405.05941, 2024. 2, 3, 4, 21, 42
Pith/arXiv arXiv 2024
-
[48]
Art: Articulated reconstruction transformer.arXiv preprint arXiv:2512.14671, 2025
Zizhang Li, Cheng Zhang, Zhengqin Li, Henry Howard-Jenkins, Zhaoyang Lv, Chen Geng, Jiajun Wu, Richard Newcombe, Jakob Engel, and Zhao Dong. Art: Articulated reconstruction transformer.arXiv preprint arXiv:2512.14671, 2025. 3
Pith/arXiv arXiv 2025
-
[49]
Planar robot casting with real2sim2real self-supervised learning
Vincent Lim, Huang Huang, Lawrence Yunliang Chen, Jonathan Wang, Jeffrey Ichnowski, Daniel Seita, Michael Laskey, and Ken Goldberg. Planar robot casting with real2sim2real self-supervised learning. arXiv preprint arXiv:2111.04814, 2021. 3
arXiv 2021
-
[50]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
-
[51]
Jiayi Liu, Denys Iliash, Angel X Chang, Manolis Savva, and Ali Mahdavi-Amiri. Singapo: Single image controlled generation of articulated parts in objects.arXiv preprint arXiv:2410.16499, 2024. 3
arXiv 2024
-
[52]
Partfield: Learning 3d feature fields for part segmentation and beyond
Minghua Liu, Mikaela Angelina Uy, Donglai Xiang, Hao Su, Sanja Fidler, Nicholas Sharp, and Jun Gao. Partfield: Learning 3d feature fields for part segmentation and beyond. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9704–9715, 2025. 22
2025
-
[53]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024. 3 13 SimFoundry: Modular and Automated Scene Generation for Policy Learni...
2024
-
[54]
P3-sam: Native 3d part segmentation.arXiv preprint arXiv:2509.06784,
Changfeng Ma, Yang Li, Xinhao Yan, Jiachen Xu, Yunhan Yang, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, and Chunchao Guo. P3-sam: Native 3d part segmentation.arXiv preprint arXiv:2509.06784,
-
[55]
Abhiram Maddukuri, Zhenyu Jiang, Lawrence Yunliang Chen, Soroush Nasiriany, Yuqi Xie, Yu Fang, Wenqi Huang, Zu Wang, Zhenjia Xu, Nikita Chernyadev, et al. Sim-and-real co-training: A simple recipe for vision-based robotic manipulation.arXiv preprint arXiv:2503.24361, 2025. 2, 4, 21
arXiv 2025
-
[56]
Roboturk: A crowdsourcing platform for robotic skill learning through imitation
Ajay Mandlekar, Yuke Zhu, Animesh Garg, Jonathan Booher, Max Spero, Albert Tung, Julian Gao, John Emmons, Anchit Gupta, Emre Orbay, et al. Roboturk: A crowdsourcing platform for robotic skill learning through imitation. InConf on Robot Learning, 2018. 21
2018
-
[57]
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021. 21
Pith/arXiv arXiv 2021
-
[58]
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations.arXiv preprint arXiv:2310.17596, 2023. 2, 21, 29, 39
Pith/arXiv arXiv 2023
-
[59]
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano- Munoz,XinjieYao,RenéZurbrügg,NikitaRudin,etal. Isaaclab: Agpu-acceleratedsimulationframework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025. 5, 29
Pith/arXiv arXiv 2025
-
[60]
Void: Video object and interaction deletion.arXiv preprint arXiv:2604.02296, 2026
Saman Motamed, William Harvey, Benjamin Klein, Luc Van Gool, Zhuoning Yuan, and Ta-Ying Cheng. Void: Video object and interaction deletion.arXiv preprint arXiv:2604.02296, 2026. 23
arXiv 2026
-
[61]
NVIDIA, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 2, 7, 21, 39
Pith/arXiv arXiv 2025
-
[62]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE Int’l Conf on Robotics and Automation (ICRA), 2024. 21
2024
-
[63]
Scenesmith: Agentic generation of simulation-ready indoor scenes, 2026
Nicholas Pfaff, Thomas Cohn, Sergey Zakharov, Rick Cory, and Russ Tedrake. Scenesmith: Agentic generation of simulation-ready indoor scenes, 2026. 2, 3
2026
-
[64]
Alvinn: An autonomous land vehicle in a neural network
Dean A Pomerleau. Alvinn: An autonomous land vehicle in a neural network. InAdvances in neural information processing systems, 1989. 21
1989
-
[65]
Xiaowen Qiu, Jincheng Yang, Yian Wang, Zhehuan Chen, Yufei Wang, Tsun-Hsuan Wang, Zhou Xian, and Chuang Gan. Articulate anymesh: Open-vocabulary 3d articulated objects modeling.arXiv preprint arXiv:2502.02590, 2025. 5, 23
arXiv 2025
-
[66]
Splatsim: Zero-shot sim2real transfer of rgb manipulation policies using gaussian splatting
M Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, and Abhisesh Silwal. Splatsim: Zero-shot sim2real transfer of rgb manipulation policies using gaussian splatting. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6502–6509. IEEE, 2025. 3
2025
-
[67]
Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 3
Pith/arXiv arXiv 2024
-
[68]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. InInternational Conference on Learning Representations, volume 2025, pages 28085–28128,
2025
-
[69]
23 14 SimFoundry: Modular and Automated Scene Generation for Policy Learning and Evaluation
-
[70]
Yam robot arm, 2025
I2RT Robotics. Yam robot arm, 2025. URLhttps://i2rt.com/collections/yam-arm. 6, 40
2025
-
[71]
Is imitation learning the route to humanoid robots?Trends in cognitive sciences, 3, 1999
Stefan Schaal. Is imitation learning the route to humanoid robots?Trends in cognitive sciences, 3, 1999. 21
1999
-
[72]
Structure-from-Motion Revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-Motion Revisited. InConference on Computer Vision and Pattern Recognition (CVPR), 2016. 25
2016
-
[73]
Nerfstudio: A modular framework for neural radiance field development
Matthew Tancik, Ethan Weber, Evonne Ng, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, et al. Nerfstudio: A modular framework for neural radiance field development. InACM SIGGRAPH 2023 conference proceedings, pages 1–12, 2023. 24, 25
2023
-
[74]
Segment any mesh.arXiv preprint arXiv:2408.13679, 2024
George Tang, William Zhao, Logan Ford, David Benhaim, and Paul Zhang. Segment any mesh.arXiv preprint arXiv:2408.13679, 2024. 22, 23
arXiv 2024
-
[75]
Sam 3d: 3dfy anything in images, 2025
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images, 2025. URLht...
Pith/arXiv arXiv 2025
-
[76]
Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details, 2025
Tencent Hunyuan3D Team. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details, 2025. URLhttps://arxiv.org/abs/2506.16504. 3
Pith/arXiv arXiv 2025
-
[77]
Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy. arXiv preprint arXiv:2511.16651, 2025. 21
arXiv 2025
-
[78]
Triposr: Fast 3d object reconstruction from a single image.arXiv preprint arXiv:2403.02151, 2024
Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, and Yan-Pei Cao. Triposr: Fast 3d object reconstruction from a single image.arXiv preprint arXiv:2403.02151, 2024. 3
Pith/arXiv arXiv 2024
-
[79]
Robot learning with super-linear scaling.arXiv preprint arXiv:2412.01770, 2024
MarcelTorne, ArhanJain, JiayiYuan, VidaaranyaMacha, LarsAnkile, AnthonySimeonov, PulkitAgrawal, and Abhishek Gupta. Robot learning with super-linear scaling.arXiv preprint arXiv:2412.01770, 2024. 3, 21
arXiv 2024
-
[80]
Marcel Torne, Anthony Simeonov, Zechu Li, April Chan, Tao Chen, Abhishek Gupta, and Pulkit Agrawal. Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation.arXiv preprint arXiv:2403.03949, 2024. 2, 3, 21
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.