SemFlowRAG: Directed Semantic Flow from Abstraction to Evidence for Complex Reasoning
Pith reviewed 2026-06-30 01:28 UTC · model grok-4.3
The pith
SemFlowRAG directs retrieval along a semantic abstractness gradient to avoid probability black holes in complex reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
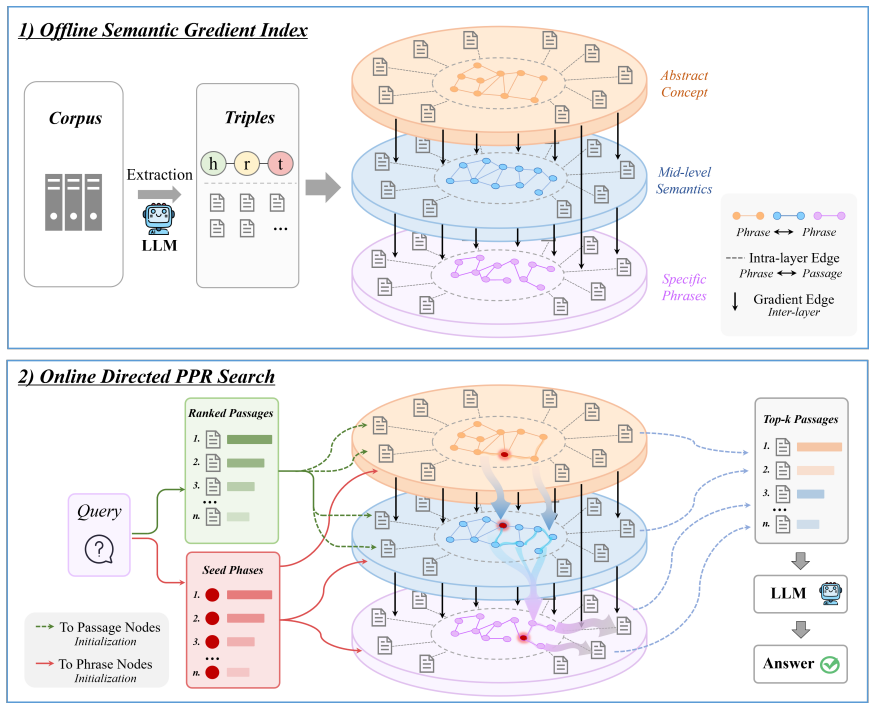
By reconstructing the retrieval space into a corpus-adaptive semantic gradient graph and applying an abstractness-guided directed PageRank, SemFlowRAG forces the retrieval trajectory to follow a high-to-low semantic abstractness gradient, ensuring layer-by-layer evidence convergence from abstract concepts to specific document evidence and mitigating the probability black holes issue.
What carries the argument
The abstractness-guided directed PageRank on the semantic gradient graph, where abstractness is quantified by embedding variance to impose directed constraints from high to low abstractness.
If this is right
- Retrieval avoids trapping in high-degree abstract concept nodes.
- The process achieves layer-by-layer convergence to specific evidence.
- Structural noise is suppressed through the hierarchical directed structure.
- Performance improves on both retrieval and downstream reasoning tasks compared to undirected baselines.
- A natural hierarchy emerges from the corpus data distribution without manual design.
Where Pith is reading between the lines
- This directed gradient approach might apply to other graph traversal problems in search and recommendation systems.
- It could inspire methods to dynamically adjust directionality based on query context rather than fixed corpus properties.
- Testing whether the variance measure holds across different embedding spaces would be a useful extension.
- The framework might reduce the accumulation of irrelevant paths in very large knowledge graphs.
Load-bearing premise
The embedding variance of passages associated with an entity accurately reflects its semantic abstractness in a manner that produces useful directed edges for guiding retrieval.
What would settle it
Running the directed PageRank versus an undirected version on the same graph and finding no difference or worse performance in evidence quality on a standard multi-hop QA benchmark would challenge the central claim.
Figures





read the original abstract
Retrieval-Augmented Generation (RAG) enhanced by Knowledge Graphs has shown promise in complex multi-hop reasoning tasks. However, existing graph-based retrieval methods typically rely on flat, undirected topologies. During the retrieval process, the probability flow often gets trapped in high-degree abstract concept nodes which we define as ``probability black holes'', leading to semantic drift and noise accumulation. To address this, we propose SemFlowRAG, a framework that reconstructs the flat retrieval space into a corpus-adaptive semantic gradient graph. This data-driven self-organization enables a hierarchical structure to emerge naturally from the data distribution, capturing the intrinsic semantic granularity of the corpus to suppress structural noise. By quantifying the semantic abstractness of entities through the embedding variance of their associated passages, we transform static undirected edges into directed semantic constraints. Furthermore, we design an abstractness-guided directed PageRank algorithm that forces the retrieval trajectory to follow a ``high-to-low semantic abstractness'' gradient. This mechanism ensures layer-by-layer evidence convergence, smoothly guiding the retrieval process from abstract concepts to specific document evidence. Extensive experiments on complex QA datasets demonstrate that SemFlowRAG effectively mitigates the ``probability black holes'' issue, outperforming existing baselines in both retrieval and downstream reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SemFlowRAG, a graph-based RAG framework that reconstructs flat undirected retrieval graphs into a corpus-adaptive directed semantic gradient graph. It quantifies entity abstractness via embedding variance of associated passages, converts edges to directed constraints, and applies an abstractness-guided directed PageRank that enforces high-to-low abstractness trajectories to avoid 'probability black holes' (high-degree abstract nodes trapping probability flow). Experiments on complex QA datasets are claimed to show improved retrieval and downstream reasoning over baselines.
Significance. If the variance proxy produces a reliable hierarchy and the directed flow demonstrably reduces noise without discarding evidence paths, the approach could provide a data-driven alternative to hand-crafted hierarchies in graph RAG, addressing a known issue in multi-hop retrieval. The self-organized construction from corpus embeddings is a potentially reusable idea if validated.
major comments (2)
- [Abstract] Abstract (and any § on method): the central mechanism rests on the unvalidated claim that 'embedding variance of their associated passages' quantifies semantic abstractness. No derivation, external validation, or ablation is referenced showing that variance correlates with abstraction level rather than passage length, diversity, or embedding artifacts; if the proxy fails, the induced directions become arbitrary and the 'high-to-low' PageRank cannot guarantee layer-by-layer convergence.
- [Abstract] Abstract: the performance claims ('outperforming existing baselines in both retrieval and downstream reasoning performance') are stated without reference to specific metrics, datasets, statistical significance, or controls for the new directed PageRank hyperparameters; the absence of these details makes it impossible to assess whether the directed constraints actually mitigate black-hole trapping or merely trade one bias for another.
minor comments (1)
- [Abstract] The term 'probability black holes' is introduced without a formal definition or citation to prior work on probability flow in graphs; a brief reference or equation would clarify the phenomenon being addressed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any § on method): the central mechanism rests on the unvalidated claim that 'embedding variance of their associated passages' quantifies semantic abstractness. No derivation, external validation, or ablation is referenced showing that variance correlates with abstraction level rather than passage length, diversity, or embedding artifacts; if the proxy fails, the induced directions become arbitrary and the 'high-to-low' PageRank cannot guarantee layer-by-layer convergence.
Authors: We appreciate the referee's emphasis on validating the embedding-variance proxy. The manuscript motivates this choice by noting that abstract entities typically participate in more diverse contexts, producing higher variance across their associated passage embeddings, while concrete entities exhibit lower variance due to narrower contexts. However, the current version does not include a formal derivation, external correlation study, or ablation isolating variance from confounders such as passage length. We will add a dedicated subsection in the Methods section that (i) provides a short derivation linking variance to semantic granularity, (ii) reports Spearman correlation between variance scores and human-annotated abstractness on a sampled subset of entities, and (iii) presents an ablation replacing variance-based directionality with length- or degree-based alternatives. These additions will directly address the concern that the induced directions could be arbitrary. revision: yes
-
Referee: [Abstract] Abstract: the performance claims ('outperforming existing baselines in both retrieval and downstream reasoning performance') are stated without reference to specific metrics, datasets, statistical significance, or controls for the new directed PageRank hyperparameters; the absence of these details makes it impossible to assess whether the directed constraints actually mitigate black-hole trapping or merely trade one bias for another.
Authors: The abstract is written as a high-level summary; the full experimental section reports results on multiple complex QA benchmarks, retrieval metrics (e.g., Hit@K, MRR), downstream reasoning metrics (F1, EM), statistical significance testing, and hyperparameter sensitivity analysis for the directed PageRank. We agree the abstract would benefit from greater specificity. We will revise it to reference the key quantitative gains and to note that hyperparameter controls and black-hole mitigation analysis (via flow-distribution diagnostics) appear in the Experiments section. revision: yes
Circularity Check
No significant circularity; data-driven construction validated on external benchmarks
full rationale
The paper constructs a directed graph by defining semantic abstractness as the embedding variance of associated passages, then applies an abstractness-guided directed PageRank to enforce high-to-low trajectories. This is an explicit modeling choice presented as emerging from the data distribution, with no equations or steps showing that downstream performance metrics or claims reduce to the same quantities by definition. Retrieval and reasoning results are evaluated on external complex QA datasets, providing independent benchmarks. No self-citations, fitted parameters renamed as predictions, or self-definitional loops appear in the derivation chain.
Axiom & Free-Parameter Ledger
invented entities (1)
-
probability black holes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[2]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[3]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[4]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
A survey on rag meeting llms: Towards retrieval-augmented large language models , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[5]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Kag: Boosting llms in professional domains via knowledge augmented generation , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[6]
arXiv preprint arXiv:2507.05714 , year=
Hirag: Hierarchical-thought instruction-tuning retrieval-augmented generation , author=. arXiv preprint arXiv:2507.05714 , year=
-
[7]
International Conference on Learning Representations , volume=
Reasoning on graphs: Faithful and interpretable large language model reasoning , author=. International Conference on Learning Representations , volume=
-
[8]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Towards mitigating LLM hallucination via self reflection , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[9]
Procedia computer science , volume=
A Survey on RAG with LLMs , author=. Procedia computer science , volume=. 2024 , publisher=
2024
-
[10]
Artificial Intelligence , volume=
Acquiring and modeling abstract commonsense knowledge via conceptualization , author=. Artificial Intelligence , volume=. 2024 , publisher=
2024
-
[11]
Applied Network Science , volume=
Graph-based exploration and clustering analysis of semantic spaces , author=. Applied Network Science , volume=. 2019 , publisher=
2019
-
[12]
arXiv preprint arXiv:2502.14802 , year=
From rag to memory: Non-parametric continual learning for large language models , author=. arXiv preprint arXiv:2502.14802 , year=
-
[13]
Advances in neural information processing systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in neural information processing systems , volume=
-
[14]
arXiv preprint arXiv:2404.16130 , year=
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Leanrag: Knowledge-graph-based generation with semantic aggregation and hierarchical retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
arXiv preprint arXiv:2506.00783 , year=
Kg-traces: Enhancing large language models with knowledge graph-constrained trajectory reasoning and attribution supervision , author=. arXiv preprint arXiv:2506.00783 , year=
-
[17]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval , url =
Sarthi, Parth and Abdullah, Salman and Tuli, Aditi and Khanna, Shubh and Goldie, Anna and Manning, Christopher , booktitle =. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval , url =
-
[18]
graphrag: A systematic evaluation and key insights , author=
Rag vs. graphrag: A systematic evaluation and key insights , author=. arXiv preprint arXiv:2502.11371 , year=
-
[19]
arXiv preprint arXiv:2501.00309 , year=
Retrieval-augmented generation with graphs (graphrag) , author=. arXiv preprint arXiv:2501.00309 , year=
-
[20]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[21]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[22]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[23]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[24]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[25]
arXiv preprint arXiv:2402.05136 , year=
Lv-eval: A balanced long-context benchmark with 5 length levels up to 256k , author=. arXiv preprint arXiv:2402.05136 , year=
-
[26]
Transactions of the Association for Computational Linguistics , volume=
The narrativeqa reading comprehension challenge , author=. Transactions of the Association for Computational Linguistics , volume=. 2018 , publisher=
2018
-
[27]
Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval , author=. SIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University , pages=. 1994 , organization=
1994
-
[28]
arXiv preprint arXiv:2112.09118 , year=
Unsupervised dense information retrieval with contrastive learning , author=. arXiv preprint arXiv:2112.09118 , year=
-
[29]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Large dual encoders are generalizable retrievers , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[30]
arXiv preprint arXiv:2308.03281 , year=
Towards general text embeddings with multi-stage contrastive learning , author=. arXiv preprint arXiv:2308.03281 , year=
-
[31]
International Conference on Learning Representations , volume=
Generative representational instruction tuning , author=. International Conference on Learning Representations , volume=
-
[32]
International Conference on Learning Representations , volume=
Nv-embed: Improved techniques for training llms as generalist embedding models , author=. International Conference on Learning Representations , volume=
-
[33]
arXiv preprint arXiv:2410.05779 , volume=
Lightrag: Simple and fast retrieval-augmented generation , author=. arXiv preprint arXiv:2410.05779 , volume=
-
[34]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[35]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
GNN-RAG: Graph neural retrieval for efficient large language model reasoning on knowledge graphs , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[36]
Proceedings of the 11th international conference on World Wide Web , pages=
Topic-sensitive pagerank , author=. Proceedings of the 11th international conference on World Wide Web , pages=
-
[37]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.