Direct Causation in International Humanitarian Law and the Challenge of AI-Mediated Civilian Cyber Operations
Pith reviewed 2026-06-30 07:46 UTC · model grok-4.3
The pith
AI-mediated civilian cyber operations using autonomous systems fail the direct causation test under international humanitarian law.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
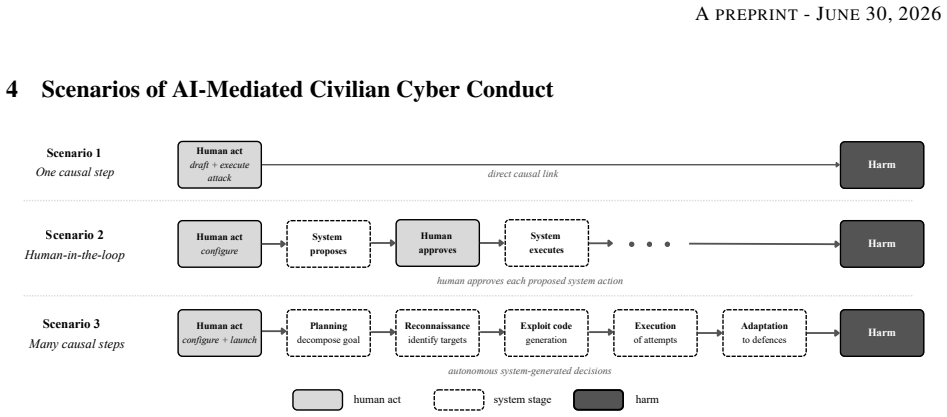
When a civilian deploys an autonomous multi-agent cyber system of the kind recently demonstrated in offensive AI research, the one causal step standard fails because harm is produced by system-generated decisions made after human disengagement, and the integral-part requirement does not extend because it presupposes downstream human contributors whose conduct can be independently classified. The framework therefore defaults to treating such deployments as indirect participation, in tension with its purpose of capturing civilians who personally take part in hostilities. The paper classifies AI-mediated operations along a five-level spectrum based on goal-specification granularity and shows th
What carries the argument
The one causal step standard and integral-part requirement within the direct causation element of the three-criterion test for direct participation in hostilities.
If this is right
- Such deployments default to treatment as indirect participation.
- This outcome creates tension with the purpose of the test to capture civilians who personally take part in hostilities.
- Goal-specification granularity is the property on which the integral-part test's concreteness component implicitly turns.
- AI-mediated operations are classified along a five-level spectrum according to this granularity.
- Existing technical AI governance instruments do not log or report goal-specification granularity.
Where Pith is reading between the lines
- Legal classification of these operations would require examining the specific level of goal detail provided to the autonomous system.
- The gap in the test suggests a need for updated criteria that address causation when non-human agents generate the final harmful decisions.
- Governance standards for AI tools could be extended to require logging of goal-specification levels to support consistent application of participation rules.
Load-bearing premise
The integral-part requirement of the direct causation test presupposes downstream human contributors whose conduct can be independently classified as direct or indirect participation.
What would settle it
A doctrinal analysis or legal ruling that applies the integral-part requirement to causation chains ending in autonomous non-human decisions without requiring separate classification of downstream human conduct.
Figures
read the original abstract
International humanitarian law protects civilians from direct attack unless and for such time as they take direct part in hostilities, with the ICRC's 2009 Interpretive Guidance operationalising this rule through a three-criterion cumulative test. This paper argues that AI-mediated civilian cyber operations challenge the direct causation element of this test in a structurally specific way: when a civilian deploys an autonomous multi-agent cyber system of the kind recently demonstrated in offensive AI research, the "one causal step" standard fails because harm is produced by system-generated decisions made after human disengagement, and the integral-part requirement does not extend because it presupposes downstream human contributors whose conduct can be independently classified. The framework therefore defaults to treating such deployments as indirect participation, in tension with its purpose of capturing civilians who personally take part in hostilities. Beyond the doctrinal analysis, this paper identifies goal-specification granularity as the property on which the integral-part test's concreteness component implicitly turns, classifies AI-mediated operations along a five-level spectrum, and argues that existing technical AI governance instruments do not log or report this property.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI-mediated civilian cyber operations, particularly deployment of autonomous multi-agent systems as demonstrated in recent offensive AI research, structurally challenge the direct causation element of the ICRC 2009 Interpretive Guidance's three-criterion test for direct participation in hostilities. The 'one causal step' standard fails because harm arises from post-disengagement system decisions, while the integral-part requirement does not extend as it presupposes downstream human contributors whose conduct can be independently classified as direct or indirect; this defaults such operations to indirect participation, contrary to the test's purpose. The paper further identifies goal-specification granularity as the implicit basis for the test's concreteness component, classifies operations on a five-level spectrum, and argues that current AI governance instruments fail to log or report this property.
Significance. If the interpretive analysis of the ICRC Guidance holds, the result would be significant for IHL doctrine on civilian cyber participation in an era of autonomous AI systems, identifying a specific doctrinal gap and linking it to a measurable technical property (goal granularity) that could inform future legal-technical interfaces. The five-level classification and governance critique provide a concrete framework for further analysis.
major comments (2)
- [Abstract / central doctrinal claim] Abstract and central argument: the claim that the integral-part requirement 'does not extend because it presupposes downstream human contributors whose conduct can be independently classified' is load-bearing but not derived from the 2009 ICRC Guidance text itself. The Guidance defines the criterion in terms of whether the act forms an integral part of a specific military operation; no explicit textual basis is provided showing that this functional test requires or presupposes later human actors. Without a close reading of the Guidance paragraphs on integral part (or counterexamples from case law), the structural failure does not follow.
- [Abstract / direct causation analysis] The 'one causal step' standard failure is asserted for autonomous multi-agent systems but lacks derivation steps, specific case examples from IHL practice, or analysis of how the Guidance's causation language would apply to algorithmic vs. human intermediaries. This weakens the claim that the framework defaults to indirect participation.
minor comments (2)
- The five-level spectrum based on goal-specification granularity is introduced but its mapping to the ICRC test's concreteness component would benefit from an explicit table or enumerated examples.
- References to 'recently demonstrated in offensive AI research' should include specific citations to the technical papers or systems invoked.
Simulated Author's Rebuttal
We thank the referee for these precise comments on the central doctrinal claims. We agree that the manuscript would be strengthened by more explicit textual derivation from the ICRC Guidance and additional analysis of causation language. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / central doctrinal claim] Abstract and central argument: the claim that the integral-part requirement 'does not extend because it presupposes downstream human contributors whose conduct can be independently classified' is load-bearing but not derived from the 2009 ICRC Guidance text itself. The Guidance defines the criterion in terms of whether the act forms an integral part of a specific military operation; no explicit textual basis is provided showing that this functional test requires or presupposes later human actors. Without a close reading of the Guidance paragraphs on integral part (or counterexamples from case law), the structural failure does not follow.
Authors: We accept that the current text asserts the presupposition of downstream human contributors without sufficient derivation from the Guidance itself. The claim rests on an interpretive reading of the functional test's design, which is intended to permit independent classification of each actor's conduct within a military operation. To address this, the revised manuscript will include a close reading of the relevant paragraphs in the 2009 ICRC Interpretive Guidance on the integral-part criterion and will explain why the test's structure presupposes the possibility of classifying subsequent human conduct. We will also note the absence of direct case-law counterexamples involving fully autonomous systems. revision: yes
-
Referee: [Abstract / direct causation analysis] The 'one causal step' standard failure is asserted for autonomous multi-agent systems but lacks derivation steps, specific case examples from IHL practice, or analysis of how the Guidance's causation language would apply to algorithmic vs. human intermediaries. This weakens the claim that the framework defaults to indirect participation.
Authors: We agree the manuscript would benefit from explicit derivation steps and comparative analysis. The argument is that post-disengagement algorithmic decisions introduce additional causal steps not present with human intermediaries. In revision we will add a step-by-step application of the Guidance's causation language to algorithmic intermediaries, contrasting it with human-chain examples, and will reference analogous IHL practice on indirect participation through technical means. Specific AI case law is necessarily limited by the technology's novelty, but the added analysis will clarify why the one-causal-step requirement fails. revision: yes
Circularity Check
No circularity; derivation rests on external ICRC Guidance and independent doctrinal reading
full rationale
The paper interprets the 2009 ICRC Interpretive Guidance's three-criterion test for direct participation in hostilities, specifically arguing that the integral-part requirement presupposes downstream human contributors. This is presented as a textual reading of an external source (ICRC Guidance) whose authors are unrelated to the present paper. No self-citations are invoked as load-bearing premises, no parameters are fitted, and no equations reduce claims to prior outputs. The argument classifies AI operations along a spectrum and notes gaps in governance instruments, all without reducing to self-referential definitions or renamings. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ICRC's 2009 Interpretive Guidance supplies the authoritative three-criterion cumulative test for direct participation in hostilities.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Project Glasswing, 2026a. URL https://www.anthropic.com/project/glasswing . Accessed: 2026-04-22. Anthropic. Claude Mythos preview, 2026b. URL https://red.anthropic.com/2026/mythos- preview/ . Accessed: 2026-04-22. Manish Bhatt, Sahana Chennabasappa, Cyrus Nikolaidis, Shengye Wan, Ivan Evtimov, Dominik Gabi, Daniel Song, Faizan Ahmad, Cornelius...
-
[2]
LLM Agents can Autonomously Exploit One-day Vulnerabilities
URLhttps://cyberconflicts.cyberpeaceinstitute.org/report. Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. LLM agents can autonomously exploit one-day vulnerabilities.arXiv preprint arXiv:2404.08144, 2024a. Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. Teams of LLM agents can exploit zero-day vulnerabilities.arXiv ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A watermark for large language models, 2024
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models.arXiv preprint arXiv:2301.10226,
-
[4]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, and Jie Tang. AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Nils Melzer.Interpretive Guidance on the Notion of Direct Participation in Hostilities under International Humanitarian Law
URL https://blogs.icrc.org/law-and-policy/2023/ 10/04/8-rules-civilian-hackers-war-4-obligations-states-restrain-them/. Nils Melzer.Interpretive Guidance on the Notion of Direct Participation in Hostilities under International Humanitarian Law. International Committee of the Red Cross, Geneva,
2023
-
[6]
Staying ahead of threat actors in the age of AI
10 APREPRINT- JUNE30, 2026 Microsoft Threat Intelligence. Staying ahead of threat actors in the age of AI. Technical report, Microsoft,
2026
-
[7]
Filippo Santoni de Sio and Jeroen van den Hoven
URL https://www.microsoft.com/en-us/security/blog/2024/02/14/staying-ahead-of-threat- actors-in-the-age-of-ai/. Filippo Santoni de Sio and Jeroen van den Hoven. Meaningful human control over autonomous systems: A philosophical account.Frontiers in Robotics and AI, 5:15,
2024
-
[8]
doi: 10.3389/frobt.2018.00015. Michael N. Schmitt. Deconstructing direct participation in hostilities: The constitutive elements.New York University Journal of International Law and Politics, 42(3):697–739,
-
[9]
Haoyu Wang, Zibo Xiao, Yedi Zhang, Christopher M
URL https://css.ethz.ch/content/dam/ethz/special-interest/gess/ cis/center-for-securities-studies/pdfs/Cyber-Reports-2022-06-IT-Army-of-Ukraine.pdf. Haoyu Wang, Zibo Xiao, Yedi Zhang, Christopher M. Poskitt, and Jun Sun. SafeClaw-R: Towards safe and secure multi-agent personal assistants.arXiv preprint arXiv:2603.28807,
-
[10]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering.arXiv preprint arXiv:2405.15793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Brandon Yee and Krishna Sharma. Molt dynamics: Emergent social phenomena in autonomous AI agent populations. arXiv preprint arXiv:2603.03555,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Zhang, Neil Perry, Riya Dulepet, Joey Jones, Justin W
Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Jones, Justin W. Lin, Justin Ji, Celeste Menders, Gashon Hussein, Samantha Liu, Donovan Jasper, Pura Peetathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Mike Yang, Teddy Zhang, Rishi Alluri, and Percy Liang. Cybench: A framework for evaluating cybersecurity capabili...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.