HiReFF: High-Resolution Feedforward Human Reconstruction from Uncalibrated Sparse-View Video
Pith reviewed 2026-06-30 07:33 UTC · model grok-4.3
The pith
HiReFF turns four uncalibrated 90-degree video views into 2K 360-degree human reconstructions in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
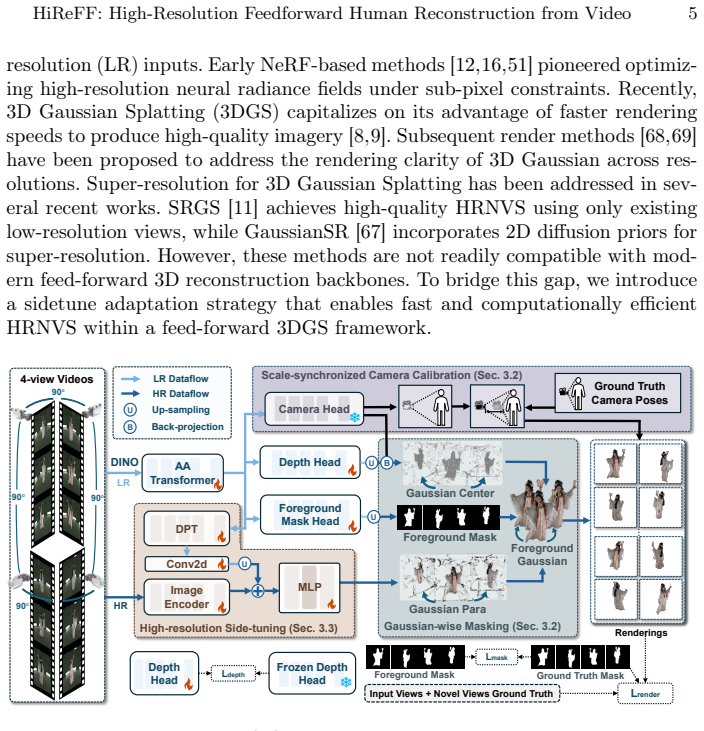
HiReFF is a feed-forward method for 2K-resolution 360° human video reconstruction from uncalibrated sparse-view videos that decomposes the task into foreground 3D Gaussian reconstruction using Scale-synchronized Camera Calibration and Gaussian-wise Foreground Masking, followed by High-resolution Side-tuning that augments the Gaussian head with supplementary features to achieve efficient 2K rendering while keeping the backbone at 0.5K.
What carries the argument
3D Gaussian representation with Scale-synchronized Camera Calibration to resolve scale for multi-view supervision, Gaussian-wise Foreground Masking to modulate parameters for clean foregrounds, and High-resolution Side-tuning to add detail for 2K output.
If this is right
- Removes the requirement for calibrated camera rigs or per-scene optimization in high-resolution human volumetric video.
- Delivers 2K rendering while the main network stays at 0.5K, cutting compute for streaming applications.
- Produces temporally consistent reconstructions directly from video input rather than single frames.
- Enables deployment on ordinary uncalibrated camera setups for AR/VR and holographic communication.
Where Pith is reading between the lines
- The side-tuning pattern could transfer to other sparse-view Gaussian reconstruction tasks beyond humans.
- If the 90-degree spacing assumption is relaxed, the calibration step might need re-derivation for arbitrary camera placements.
- Real-world use would still require handling fast motion or clothing deformation that the current four-view setup may not capture cleanly.
Load-bearing premise
Four views separated by 90 degrees together with the calibration and masking steps suffice to produce accurate clean foreground 3D Gaussians without per-scene optimization or extra constraints.
What would settle it
A test on held-out multi-view video where the 3D Gaussian output from exactly those four uncalibrated views is compared to ground-truth geometry; if surface error or visual quality falls below optimized per-scene baselines, the claim does not hold.
Figures






read the original abstract
Uncalibrated volumetric video streaming for human reconstruction is essential for holographic communication and AR/VR, yet remains challenging due to the need for temporal consistency and computational efficiency from sparse-view inputs. Existing methods rely on per-scene optimization or calibrated cameras, while recent feed-forward models are limited to low-resolution (0.5K) single-frame synthesis. We present HiReFF, a feed-forward method for 2K-resolution 360{\deg} human video reconstruction from uncalibrated sparse-view videos. Our framework decomposes the problem into two key tasks: foreground 3D Gaussian reconstruction from sparse-view videos (four views separated by 90{\deg}) and computationally efficient high-resolution synthesis. To enable the former, we propose Scale-synchronized Camera Calibration to resolve scale ambiguity for multi-view supervision, and Gaussian-wise Foreground Masking to reconstruct clean foregrounds by modulating Gaussian parameters. For efficient high-resolution synthesis, our High-resolution Side-tuning achieves 2K rendering by augmenting the Gaussian head with supplementary features while keeping the backbone at 0.5K, drastically reducing computational overhead. Experiments demonstrate that HiReFF significantly outperforms existing methods in high-resolution streaming volumetric video reconstruction. https://iridescentjiang.github.io/HiReFF
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HiReFF, a feed-forward method for 2K-resolution 360° human video reconstruction from uncalibrated sparse-view videos (four views separated by 90°). It decomposes the task into foreground 3D Gaussian reconstruction via Scale-synchronized Camera Calibration (to resolve scale ambiguity) and Gaussian-wise Foreground Masking (to produce clean foregrounds), plus High-resolution Side-tuning to enable efficient 2K rendering by augmenting a 0.5K backbone. The abstract claims that experiments demonstrate significant outperformance over existing methods in high-resolution streaming volumetric video reconstruction.
Significance. If the central claims hold with supporting evidence, the work would advance feed-forward human reconstruction by enabling high-resolution output without per-scene optimization or calibrated cameras, with potential impact on AR/VR and holographic communication applications. The approach of side-tuning for resolution and the specific calibration/masking modules could address key efficiency and quality bottlenecks in sparse-view settings.
major comments (2)
- [Abstract] Abstract: the assertion that 'experiments demonstrate that HiReFF significantly outperforms existing methods in high-resolution streaming volumetric video reconstruction' supplies no metrics, datasets, baselines, implementation details, or quantitative results. This evidence gap is load-bearing for the central claim of outperformance and prevents verification of whether the proposed modules and 90° view configuration suffice for accurate clean foreground 3D Gaussians.
- [Method] The method description relies on the assumption that Scale-synchronized Camera Calibration and Gaussian-wise Foreground Masking, combined with four 90°-separated views, enable accurate feed-forward reconstruction without per-scene optimization; however, the absence of any reported validation (e.g., ablation studies or comparison tables) leaves this core assumption untested in the provided manuscript.
minor comments (1)
- [Abstract] The abstract and title use 'uncalibrated sparse-view videos' but the method specifies a fixed four-view 90° configuration; clarifying whether the approach generalizes beyond this setup would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer evidence in the abstract and explicit validation of the core method assumptions. We address each point below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'experiments demonstrate that HiReFF significantly outperforms existing methods in high-resolution streaming volumetric video reconstruction' supplies no metrics, datasets, baselines, implementation details, or quantitative results. This evidence gap is load-bearing for the central claim of outperformance and prevents verification of whether the proposed modules and 90° view configuration suffice for accurate clean foreground 3D Gaussians.
Authors: We acknowledge that the abstract's brevity omits specific quantitative support for the outperformance claim. The full manuscript (Section 4) provides detailed comparisons on standard datasets against relevant baselines, reporting metrics including PSNR, SSIM, and perceptual scores at both 0.5K and 2K resolutions, along with implementation details. To address the concern, we will revise the abstract to concisely include key quantitative results supporting the claim while remaining within length constraints. revision: yes
-
Referee: [Method] The method description relies on the assumption that Scale-synchronized Camera Calibration and Gaussian-wise Foreground Masking, combined with four 90°-separated views, enable accurate feed-forward reconstruction without per-scene optimization; however, the absence of any reported validation (e.g., ablation studies or comparison tables) leaves this core assumption untested in the provided manuscript.
Authors: The method section describes the proposed components, with the validation of their effectiveness (including ablations on the calibration and masking modules, and comparisons under the 90° sparse-view setup) presented in the subsequent experiments section of the manuscript. If the provided review copy did not clearly link these, we will add explicit cross-references from the method to the corresponding ablation and comparison results to make the validation more immediate. revision: partial
Circularity Check
No significant circularity
full rationale
The abstract and described framework introduce two new modules (Scale-synchronized Camera Calibration and Gaussian-wise Foreground Masking) plus High-resolution Side-tuning as independent engineering contributions for feed-forward 3D Gaussian reconstruction. No equations, parameter fits, or derivations are shown that reduce by construction to the inputs; the central claim rests on experimental outperformance rather than self-referential fitting or self-citation chains. The method is presented as externally validated against prior work without load-bearing uniqueness theorems or ansatzes imported from the same authors.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.19296 (2025)
Bahmani, S., Shen, T., Ren, J., Huang, J., Jiang, Y., Turki, H., Tagliasacchi, A., Lindell, D.B., Gojcic, Z., Fidler, S., Ling, H., Gao, J., Ren, X.: Lyra: Generative 3d scene reconstruction via self-distillation with video diffusion models. arXiv preprint arXiv:2509.19296 (2025)
-
[2]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Baumgartner, T., Klatt, S.: Monocular 3d human pose estimation for sports broad- casts using partial sports field registration. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 5109–5118 (2023)
2023
-
[3]
In: The Thirteenth International Conference on Learning Representations, ICLR (2025)
Chen, J., Li, C., Zhang, J., Zhu, L., Huang, B., Chen, H., Lee, G.H.: Generaliz- able human gaussians from single-view image. In: The Thirteenth International Conference on Learning Representations, ICLR (2025)
2025
-
[4]
arXiv preprint arXiv:2510.06219 (2025)
Chen, Y., Chen, X., Xue, Y., Chen, A., Xiu, Y., Gerard, P.M.: Human3r: Everyone everywhere all at once. arXiv preprint arXiv:2510.06219 (2025)
-
[5]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference. vol. 15079, pp. 370– 386 (2024)
2024
-
[6]
arXiv preprint arXiv:2508.13154 (2025)
Chen, Z., Liu, T., Zhuo, L., Ren, J., Tao, Z., Zhu, H., Hong, F., Pan, L., Liu, Z.: 4dnex: Feed-forward 4d generative modeling made easy. arXiv preprint arXiv:2508.13154 (2025)
-
[7]
In: IEEE/CVF International Conference on Computer Vision, ICCV
Cheng, W., Chen, R., Fan, S., Yin, W., Chen, K., Cai, Z., Wang, J., Gao, Y., Yu, Z., Lin, Z., Ren, D., Yang, L., Liu, Z., Loy, C.C., Qian, C., Wu, W., Lin, D., Dai, B., Lin, K.: Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering. In: IEEE/CVF International Conference on Computer Vision, ICCV. pp. 19925–19936 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Deng, T., Chen, X., Chen, Y., Chen, Q., Xu, Y., Yang, L., Xu, L., Zhang, Y., Zhang, B., Huang, W., Wang, H.: Gaussiandwm: 3d gaussian driving world model for unified scene understanding and multi-modal generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10656–10667 (June 2026)
2026
-
[9]
In: 2025 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS)
Deng, T., Chen, Y., Yang, J., Yuan, S., Liu, J., Wang, D., Chen, W.: Cgs-slam: Compact 3d gaussian splatting for dense visual slam. In: 2025 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS). pp. 1606–1613 (2025)
2025
-
[10]
In: CVPR (2021)
Fang, Q., Shuai, Q., Dong, J., Bao, H., Zhou, X.: Reconstructing 3d human pose by watching humans in the mirror. In: CVPR (2021)
2021
-
[11]
SRGS: Super-Resolution 3D Gaussian Splatting,
Feng, X., He, Y., Wang, Y., Yang, Y., Kuang, Z., Yu, J., Fan, J., Ding, J.: SRGS: super-resolution 3d gaussian splatting. CoRRabs/2404.10318(2024)
-
[12]
IEEE Trans
Han, Y., Yu, T., Yu, X., Xu, D., Zheng, B., Dai, Z., Yang, C., Wang, Y., Dai, Q.: Super-nerf: View-consistent detail generation for nerf super-resolution. IEEE Trans. Vis. Comput. Graph.31(9), 6053–6066 (2025) 16 Y. Jiang, H. Tu et al
2025
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence
He, X., Wu, Z., Li, X., Kang, D., Zhang, C., Ye, J., Chen, L., Gao, X., Zhang, H., Zhuang, H.: Magicman: Generative novel view synthesis of humans with 3d- aware diffusion and iterative refinement. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 3437–3445 (2025)
2025
-
[14]
Hu, Y., He, Y., Chen, J., Yuan, W., Qiu, K., Lin, Z., Zhu, S., Dong, Z., Zhang, J.: Forge4d: Feed-forward 4d human reconstruction and interpolation from uncal- ibrated sparse-view videos. CoRRabs/2509.24209(2025)
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hu, Y., Liu, Z., Shao, J., Lin, Z., Zhang, J.: Eva-gaussian: 3d gaussian-based real- time human novel view synthesis under diverse multi-view camera settings. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2613–2622 (2025)
2025
-
[16]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang,X.,Li,W.,Hu,J.,Chen,H.,Wang,Y.:Refsr-nerf:Towardshighfidelityand super resolution view synthesis. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8244–8253 (2023)
2023
-
[17]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
2025
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence40(7), 5459–5467 (2026)
Jiang, Y., Song, W., Li, S., Hao, A.: Decon: Reconstruction of clothed-geometric multiple humans from a single image via geometry-guided decoupling. Proceedings of the AAAI Conference on Artificial Intelligence40(7), 5459–5467 (2026)
2026
-
[19]
IEEE Transactions on Visualization and Computer Graphics32(2), 2152–2164 (2026)
Jiang, Y., Song, W., Li, S., Hao, A.: Hfhuman: High-fidelity human reconstruction from single image with multi-modality fusion. IEEE Transactions on Visualization and Computer Graphics32(2), 2152–2164 (2026)
2026
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jin, Y., Peng, S., Wang, X., Xie, T., Xu, Z., Yang, Y., Shen, Y., Bao, H., Zhou, X.: Diffuman4d: 4d consistent human view synthesis from sparse-view videos with spatio-temporal diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11047–11057 (2025)
2025
-
[21]
In: Leibe, B., Matas, J., Sebe, N., Welling, M
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision - ECCV 2016 - 14th European Conference. vol. 9906, pp. 694–711 (2016)
2016
-
[22]
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., et al.: Mapanything: Universal feed-forward metric 3d reconstruction; map-anything. github. io. In: 2026 Interna- tional Conference on 3D Vision (3DV). pp. 499–509. IEEE (2026)
2026
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kirschstein,T.,Romero,J.,Sevastopolsky,A., Nießner,M.,Saito,S.:Avat3r:Large animatable gaussian reconstruction model for high-fidelity 3d head avatars. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12089–12100 (2025)
2025
-
[24]
arXiv preprint arXiv:2505.01838 (2025)
Li, C., Liao, H., Zhi, Y., Yang, X., Sun, Z., Chang, J., Cui, S., Han, X.: Mvhu- mannet++: A large-scale dataset of multi-view daily dressing human captures with richer annotations for 3d human digitization. arXiv preprint arXiv:2505.01838 (2025)
-
[25]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, P., Zheng, W., Liu, Y., Yu, T., Li, Y., Qi, X., Chi, X., Xia, S., Cao, Y., Xue, W., Luo, W., Guo, Y.: Pshuman: Photorealistic single-image 3d human reconstruc- tion using cross-scale multiview diffusion and explicit remeshing. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16008–16018 (2025)
2025
-
[26]
Li, X., Wang, T., Gu, Z., Zhang, S., Guo, C., Cao, L.: Flashworld: High-quality 3d scene generation within seconds (2025)
2025
-
[27]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Zheng, Z., Wang, L., Liu, Y.: Animatable gaussians: Learning pose- dependent gaussian maps for high-fidelity human avatar modeling. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19711–19722 (2024) HiReFF: High-Resolution Feedforward Human Reconstruction from Video 17
2024
-
[28]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Lin, S., Yang, L., Saleemi, I., Sengupta, S.: Robust high-resolution video matting with temporal guidance. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 238–247 (2022)
2022
-
[30]
ACM Trans
Loper,M.,Mahmood,N.,Romero,J.,Pons-Moll,G.,Black,M.J.:SMPL:askinned multi-person linear model. ACM Trans. Graph.34(6), 248:1–248:16 (2015)
2015
-
[31]
In: International Workshop on Computational Aspects of Deep Learning at 17th European Conference on Computer Vision (CADL2022)
Maaz, M., Shaker, A., Cholakkal, H., Khan, S., Zamir, S.W., Anwer, R.M., Khan, F.S.: Edgenext: Efficiently amalgamated cnn-transformer architecture for mobile vision applications. In: International Workshop on Computational Aspects of Deep Learning at 17th European Conference on Computer Vision (CADL2022). Springer (2022)
2022
-
[32]
arXiv preprint arXiv:2512.10685 (2025)
Mescheder, L., Dong, W., Li, S., Bai, X., Santos, M., Hu, P., Lecouat, B., Zhen, M., Delaunoy, A., Fang, T., et al.: Sharp monocular view synthesis in less than a second. arXiv preprint arXiv:2512.10685 (2025)
-
[33]
In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C
Pan, P., Su, Z., Lin, C., Fan, Z., Zhang, Y., Li, Z., Shen, T., Mu, Y., Liu, Y.: Humansplat: Generalizable single-image human gaussian splatting with structure priors. In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C. (eds.) Advances in Neural Information Processing Systems 38: Annual Conference on Neural Informat...
2024
-
[34]
In: CVPR (2021)
Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: CVPR (2021)
2021
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Qian, Z., Wang, S., Mihajlovic, M., Geiger, A., Tang, S.: 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5020–5030 (2024)
2024
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qiu, L., Gu, X., Li, P., Zuo, Q., Shen, W., Zhang, J., Qiu, K., Yuan, W., Chen, G., Dong, Z., et al.: Lhm: Large animatable human reconstruction model for single image to 3d in seconds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14184–14194 (2025)
2025
-
[37]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qiu, L., Zhu, S., Zuo, Q., Gu, X., Dong, Y., Zhang, J., Xu, C., Li, Z., Yuan, W., Bo, L., Chen, G., Dong, Z.: Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21148–21158 (2025)
2025
-
[38]
IEEE Trans
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell.44(3), 1623–1637 (2022)
2022
-
[39]
ACM Transactions on Graphics (TOG)43(6) (2024)
Shao, R., Pang, Y., Zheng, Z., Sun, J., Liu, Y.: Human4dit: 360-degree human video generation with 4d diffusion transformer. ACM Transactions on Graphics (TOG)43(6) (2024)
2024
-
[40]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shao, R., Zhang, H., Zhang, H., Chen, M., Cao, Y., Yu, T., Liu, Y.: Doublefield: Bridging the neural surface and radiance fields for high-fidelity human reconstruc- tion and rendering. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15851–15861 (2022)
2022
-
[41]
In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T
Shao, R., Zheng, Z., Zhang, H., Sun, J., Liu, Y.: Diffustereo: High quality hu- man reconstruction via diffusion-based stereo using sparse cameras. In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision - ECCV 2022 - 17th European Conference. vol. 13692, pp. 702–720 (2022)
2022
-
[42]
Jiang, H
Shen, Y., Zhang, Z., Qu, Y., Cao, L.: Fastvggt: Training-free acceleration of visual geometry transformer (2025) 18 Y. Jiang, H. Tu et al
2025
-
[43]
In: Bengio, Y., LeCun, Y
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Conference on Learning Representations, Conference Track Proceedings (2015)
2015
-
[44]
In: Walsh, T., Shah, J., Kolter, Z
Song, W., Ding, Y., Hou, F., Li, S., Hao, A., Hou, X.: Ctrlavatar: Controllable avatars generation via disentangled invertible networks. In: Walsh, T., Shah, J., Kolter, Z. (eds.) AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence. pp. 6959–6967 (2025)
2025
-
[45]
IEEE Trans
Song, W., Wang, X., Jiang, Y., Li, S., Hao, A., Hou, X., Qin, H.: Expressive 3d facial animation generation based on local-to-global latent diffusion. IEEE Trans. Vis. Comput. Graph.30(11), 7397–7407 (2024)
2024
-
[46]
IEEE Transactions on Visualization and Computer Graphics32(3), 2454–2466 (2026)
Song, W., Ye, Z., Wu, Z., Li, S., Hou, X., Hao, A.: Dynavatar: Dynamic 3d head avatar deformation with expression guided gaussian splatting. IEEE Transactions on Visualization and Computer Graphics32(3), 2454–2466 (2026)
2026
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Sun, J., Luo, F., Fan, W., Jiang, Y., Xiao, C.: Humanpro: Single-view 3d clothed human reconstruction with progressive normal guidance. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 9180–9188 (2026)
2026
-
[48]
In: 2025 International Joint Conference on Neural Networks (IJCNN)
Tian, H., Liu, R., Shen, W., Hu, Y., Zheng, Z., Qin, X.: Efficienthuman: Efficient training and reconstruction of moving human using articulated 2d gaussian. In: 2025 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2025)
2025
-
[49]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition
Tu, H., Liao, Z., Zhou, B., Zheng, S., Zhou, X., Zhang, L., Wang, Q., Liu, Y.: Gbc-splat: Generalizable gaussian-based clothed human digitalization under sparse RGB cameras. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. pp. 26377–26387 (2025)
2025
-
[50]
In: Burbano, A., Zorin, D., Jarosz, W
Tu, H., Shao, R., Dong, X., Zheng, S., Zhang, H., Chen, L., Wang, M., Li, W., Ma, S., Zhang, S., Zhou, B., Liu, Y.: Tele-aloha: A telepresence system with low- budget and high-authenticity using sparse RGB cameras. In: Burbano, A., Zorin, D., Jarosz, W. (eds.) ACM SIGGRAPH 2024 Conference Papers. p. 116 (2024)
2024
-
[51]
In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L
Wang, C., Wu, X., Guo, Y., Zhang, S., Tai, Y., Hu, S.: Nerf-sr: High quality neural radiance fields using supersampling. In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L. (eds.) MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14,
-
[52]
6445–6454 (2022)
pp. 6445–6454 (2022)
2022
-
[53]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotný, D.: VGGT: visual geometry grounded transformer. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5294–5306 (2025)
2025
-
[54]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20697–20709 (2024)
2024
-
[55]
VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
Wang, W., Chen, Y., Zhang, Z., Liu, H., Wang, H., Feng, Z., Qin, W., Zhu, Z., Chen, D.Y., Zhuang, B.: Volsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction. arXiv preprint arXiv:2509.19297 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Scalable permutation-equivariant visual geometry learning. CoRR abs/2507.13347(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C
Wang, Y., Huang, T., Chen, H., Lee, G.H.: Freesplat: Generalizable 3d gaussian splatting towards free view synthesis of indoor scenes. In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C. (eds.) Advances in Neural Information Processing Systems 38: Annual Conference on Neural Infor- mation Processing Systems (2024) H...
2024
-
[58]
Weng, C., Curless, B., Kemelmacher-Shlizerman, I.: Vid2actor: Free-viewpoint an- imatable person synthesis from video in the wild. CoRRabs/2012.12884(2020)
-
[59]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, R., Gao, R., Poole, B., Trevithick, A., Zheng, C., Barron, J.T., Holynski, A.: CAT4D: create anything in 4d with multi-view video diffusion models. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26057– 26068 (2025)
2025
-
[60]
In: The Fourteenth International Conference on Learning Representations (2026)
Wu, Y., Chen, X., Wu, Y., Li, W., Lu, Y., Feng, K.: Fastavatar: Towards unified and fast 3d avatar reconstruction with large gaussian reconstruction transformers. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[61]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiao, J., Zhang, Q., Nie, Y., Zhu, L., Zheng, W.S.: Rogsplat: Learning robust gen- eralizable human gaussian splatting from sparse multi-view images. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5980–5990 (2025)
2025
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiong, Z., Li, C., Liu, K., Liao, H., Hu, J., Zhu, J., Ning, S., Qiu, L., Wang, C., Wang, S., et al.: Mvhumannet: A large-scale dataset of multi-view daily dress- ing human captures. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19801–19811 (2024)
2024
-
[63]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- splat: Connecting gaussian splatting and depth. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16453–16463 (2025)
2025
-
[64]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Xu, Z., Li, Z., Dong, Z., Zhou, X., Newcombe, R., Lv, Z.: 4dgt: Learning a 4d gaus- sian transformer using real-world monocular videos. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[65]
ACM Trans
Xu, Z., Xu, Y., Yu, Z., Peng, S., Sun, J., Bao, H., Zhou, X.: Representing long volumetric video with temporal gaussian hierarchy. ACM Trans. Graph.43(6), 171:1–171:18 (2024)
2024
-
[66]
In: The Thirteenth International Conference on Learning Representations, ICLR (2025)
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M., Peng, S.: No pose, no prob- lem: Surprisingly simple 3d gaussian splats from sparse unposed images. In: The Thirteenth International Conference on Learning Representations, ICLR (2025)
2025
-
[67]
Journal of Machine Learning Research26(34), 1–17 (2025)
Ye, V., Li, R., Kerr, J., Turkulainen, M., Yi, B., Pan, Z., Seiskari, O., Ye, J., Hu, J., Tancik, M., Kanazawa, A.: gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research26(34), 1–17 (2025)
2025
-
[68]
GaussianSR: 3D Gaus- sian Super-Resolution with 2D Diffusion Priors,
Yu, X., Zhu, H., He, T., Chen, Z.: Gaussiansr: 3d gaussian super-resolution with 2d diffusion priors. CoRRabs/2406.10111(2024)
-
[69]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, Z., Chen, A., Huang, B., Sattler, T., Geiger, A.: Mip-splatting: Alias-free 3d gaussian splatting. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19447–19456 (2024)
2024
-
[70]
In: Proceed- ings of the AAAI Conference on Artificial Intelligence
Zeng, H., Bai, Y., Fu, Y.: Arbitrary-scale 3d gaussian super-resolution. In: Proceed- ings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 12304–12312 (2026)
2026
-
[71]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J
Zhang, J.O., Sax, A., Zamir, A., Guibas, L.J., Malik, J.: Side-tuning: A baseline for network adaptation via additive side networks. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J. (eds.) Computer Vision - ECCV 2020 - 16th European Conference. vol. 12348, pp. 698–714 (2020)
2020
-
[72]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, S., Wang, J., Xu, Y., Xue, N., Rupprecht, C., Zhou, X., Shen, Y., Wetzstein, G.:FLARE:feed-forwardgeometry,appearanceandcameraestimationfromuncal- ibrated sparse views. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21936–21947 (2025)
2025
-
[73]
Advances in Neural Information Processing Systems37, 50361–50380 (2024) 20 Y
Zhang, S., Fei, X., Liu, F., Song, H., Duan, Y.: Gaussian graph network: Learn- ing efficient and generalizable gaussian representations from multi-view images. Advances in Neural Information Processing Systems37, 50361–50380 (2024) 20 Y. Jiang, H. Tu et al
2024
-
[74]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Z., Yang, Z., Yang, Y.: SIFU: side-view conditioned implicit function for real-world usable clothed human reconstruction. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9936–9947 (2024)
2024
-
[75]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, F., Yang, W., Zhang, J., Lin, P., Zhang, Y., Yu, J., Xu, L.: Humannerf: Efficiently generated human radiance field from sparse inputs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7743–7753 (June 2022)
2022
-
[76]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, S., Zhou, B., Shao, R., Liu, B., Zhang, S., Nie, L., Liu, Y.: Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view syn- thesis. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19680–19690 (2024)
2024
-
[77]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Zhou, B., Zheng, S., Liao, Z., Ma, Z., Tu, H., Liu, B., Liu, Y.: Splat-sap: Feed- forward gaussian splatting for human-centered scene with scale-aware point map reconstruction. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[78]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhuang, Y., Lv, J., Wen, H., Shuai, Q., Zeng, A., Zhu, H., Chen, S., Yang, Y., Cao, X., Liu, W.: Idol: Instant photorealistic 3d human creation from a single image. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26308–26319 (2025)
2025
-
[79]
Streaming 4D Visual Geometry Transformer
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.