Agent-Computer Observation Interfaces Enable Dynamic Computer Use
Pith reviewed 2026-06-30 06:57 UTC · model grok-4.3
The pith
Agent-Computer Observation Interfaces let models gain 17-48 points on dynamic tasks by adding gated audio and persistent narration to screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
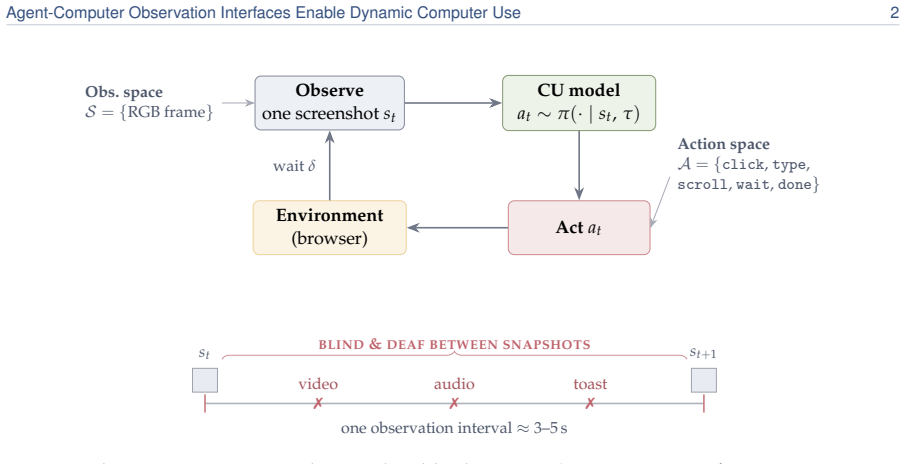
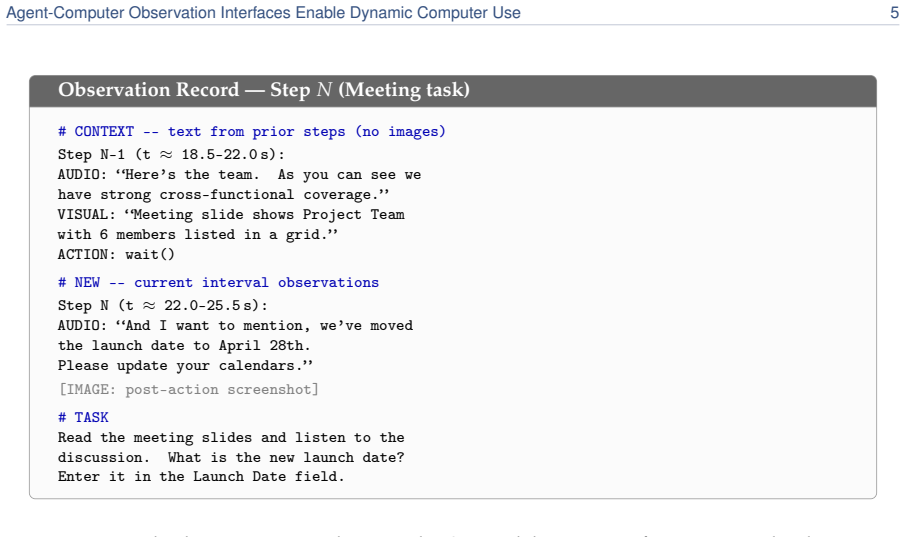
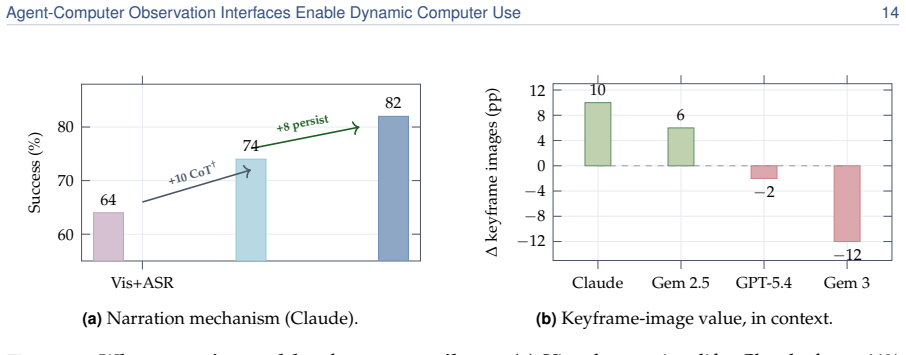
The Agent-Computer Observation Interface (AOI) decouples continuous adaptive observation from discrete actions through three gated components—inter-step keyframe capture, volume-gated audio transcription, and CU-model-generated visual narration that persists as text—producing almost nothing on static silent content and enabling CU models from 7B to frontier scale to achieve +17 to +48 percentage point gains over screenshot baselines on DynaCU-Bench dynamic tasks with zero retraining.
What carries the argument
The Agent-Computer Observation Interface (AOI), a perception layer whose three gated components produce persistent text only when content is dynamic or voiced and otherwise reduce to the standard screenshot loop.
If this is right
- Spoken-content tasks become fully solvable while screenshot-only agents solve none.
- The performance value comes mainly from narrating captured frames into persistent text rather than from keyframe selection itself.
- Individual AOI components must be chosen per model because the keyframe stream can regress performance on newer models through image-token dilution.
- Static control tasks show no degradation, so the interface preserves baseline behavior when content is unchanging.
Where Pith is reading between the lines
- Observation design choices may matter as much as action design for enabling agents to operate in live environments.
- The same gated components could allow existing models to handle live meetings or interactive software sessions without further training.
Load-bearing premise
The DynaCU-Bench tasks represent real-world dynamic computer-use scenarios and the measured gains are caused by the AOI components rather than benchmark construction details or model-specific interactions with the narration text.
What would settle it
Running the same models on a fresh set of dynamic browser tasks outside DynaCU-Bench and finding that the 17-48 point gains disappear or that equivalent narration text supplied without the gated AOI structure produces identical results.
Figures








read the original abstract
SWE-agent established the action interface as an underexplored design axis for software-engineering agents; we make the analogous case for the observation interface in computer-use (CU) agents. Current CU agents, closed and open-source alike, tie observation to action--one screenshot every 3-5 s, no audio--leaving them blind and deaf between screenshots to video, animations, transient UI events, meetings, and spoken instructions. We introduce the Agent-Computer Observation Interface (AOI), a model-agnostic perception layer that decouples continuous, adaptive observation from discrete actions through three gated components: inter-step keyframe capture, volume-gated audio transcription, and CU-model-generated visual narration that persists as text. Each produces almost nothing on static, silent content, reducing to the standard loop without degrading it. On DynaCU-Bench (100 dynamic browser tasks plus a 50-task static control), CU models from 7B to frontier scale gain +17 to +48 pp over their screenshot baselines with zero retraining, turning tasks that are near-impossible from periodic screenshots into largely solved ones. The gap is starkest on audio: on a spoken-content subset AOI agents solve every task, whereas streaming voice models hear accurately but cannot act on what they hear without the scaffold. The decomposition is as informative as the headline gain: keyframe selection turns out not to matter--the value comes from narrating captured frames into persistent text--and the interface is not a fixed bundle, since on a newer model (Gemini 3 Flash) the keyframe stream actively regresses through image-token dilution, so its components must be selected per model rather than shipped as one configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that current computer-use (CU) agents are limited by observation tied to discrete actions (periodic screenshots, no audio), and introduces the Agent-Computer Observation Interface (AOI) as a model-agnostic perception layer with three gated components: inter-step keyframe capture, volume-gated audio transcription, and model-generated visual narration that persists as text. On the new DynaCU-Bench (100 dynamic browser tasks + 50-task static control), AOI yields +17 to +48 pp gains over screenshot baselines across 7B-to-frontier models with zero retraining; the decomposition finds narration into persistent text as the main driver while keyframe selection adds little value (and can regress on some models via token dilution).
Significance. If the gains are shown to be caused by the AOI components rather than benchmark construction or narration-model interactions, the work would usefully extend the design-space analysis begun by SWE-agent from actions to observations, offering a practical, zero-retraining intervention that turns near-impossible dynamic tasks into largely solved ones. The model-specific component selection finding and the audio-subset result (AOI solves all tasks while streaming voice models cannot act) are actionable. The absence of statistical details, task-authoring descriptions, and explicit ablations currently limits how far these claims can be taken.
major comments (3)
- [Abstract / DynaCU-Bench] Abstract and DynaCU-Bench evaluation: the manuscript provides no description of how the 100 dynamic browser tasks were authored, how transient events or spoken instructions were injected, or what exact prompts/context the narration model receives. This is load-bearing for the central claim because the largest gaps occur on the audio subset; without these details it remains possible that narration content systematically supplies information unavailable to the pure screenshot baseline.
- [Abstract] Abstract: the decomposition claim that 'keyframe selection turns out not to matter' and that 'the value comes from narrating captured frames into persistent text' is presented without quantitative ablation tables or controls showing the incremental contribution of each gated component; this directly underpins the paper's guidance that components must be selected per model.
- [Evaluation results] Evaluation results: no information is supplied on the number of evaluation runs, variance, or statistical significance testing for the reported +17 to +48 pp gains across model scales. This is required to assess whether the headline improvements are reliable or could be artifacts of single-run or implementation-specific effects.
minor comments (1)
- [AOI description] The phrase 'each produces almost nothing on static, silent content, reducing to the standard loop without degrading it' would benefit from an explicit statement of the fallback behavior and any measured overhead.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional detail will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract / DynaCU-Bench] Abstract and DynaCU-Bench evaluation: the manuscript provides no description of how the 100 dynamic browser tasks were authored, how transient events or spoken instructions were injected, or what exact prompts/context the narration model receives. This is load-bearing for the central claim because the largest gaps occur on the audio subset; without these details it remains possible that narration content systematically supplies information unavailable to the pure screenshot baseline.
Authors: We agree these details are necessary for reproducibility and to substantiate the audio-subset claims. The current manuscript does not include a full description of task authoring, transient event injection, spoken instruction mechanisms, or the exact prompts and context given to the narration model. In the revised manuscript we will add a dedicated subsection to the DynaCU-Bench description that specifies the task creation process, how dynamic and audio elements are injected, and the complete prompt templates used for visual narration. revision: yes
-
Referee: [Abstract] Abstract: the decomposition claim that 'keyframe selection turns out not to matter' and that 'the value comes from narrating captured frames into persistent text' is presented without quantitative ablation tables or controls showing the incremental contribution of each gated component; this directly underpins the paper's guidance that components must be selected per model.
Authors: The abstract summarizes our experimental decomposition, which found narration to persistent text as the dominant factor and keyframe selection to add little value (sometimes regressing via token dilution). However, the manuscript does not present explicit quantitative ablation tables showing incremental contributions of each component. We will add these ablation tables and controls to the evaluation section of the revised manuscript to support the per-model component selection guidance. revision: yes
-
Referee: [Evaluation results] Evaluation results: no information is supplied on the number of evaluation runs, variance, or statistical significance testing for the reported +17 to +48 pp gains across model scales. This is required to assess whether the headline improvements are reliable or could be artifacts of single-run or implementation-specific effects.
Authors: We acknowledge that the number of runs, variance, and statistical significance testing are required to evaluate result reliability. The manuscript currently omits these details. In the revision we will add an evaluation protocol subsection reporting the number of runs per task and model, observed variance, and any statistical significance tests performed. revision: yes
Circularity Check
No circularity: purely empirical performance deltas on introduced benchmark
full rationale
The paper reports measured success-rate gains (+17 to +48 pp) of AOI-augmented agents versus screenshot baselines on DynaCU-Bench. No equations, derivations, fitted parameters, or uniqueness theorems appear; the central claims are direct experimental comparisons. The decomposition (narration as main driver) is likewise an observed outcome, not a reduction to self-defined inputs. Self-citations, if present, are not load-bearing for any derivation. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Periodic screenshot observation is the relevant baseline for computer-use agents.
invented entities (1)
-
Agent-Computer Observation Interface (AOI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Surfer 2: The next generation of cross-platform computer use agents
Mathieu Andreux et al. Surfer 2: The next generation of cross-platform computer use agents. arXiv preprint arXiv:2510.19949,
-
[2]
Anthropic. Claude computer use. https://docs.anthropic.com/en/docs/ agents-and-tools/computer-use, 2024a. Agent-Computer Observation Interfaces Enable Dynamic Computer Use 20 Anthropic. Model context protocol.https://modelcontextprotocol.io, 2024b. Ahmed Awadallah et al. Fara-7B: An efficient agentic model for computer use.arXiv preprint arXiv:2511.19663,
-
[3]
Dongping Chen et al. GUI-World: A video benchmark and dataset for multimodal GUI- oriented understanding.arXiv preprint arXiv:2406.10819,
-
[4]
CUA-Suite: 55 hours of real computer-use recordings for agent benchmarking
Liang Chen et al. CUA-Suite: 55 hours of real computer-use recordings for agent benchmarking. arXiv preprint arXiv:2510.10142,
-
[5]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Ac- cessed 2026-05-15; model idgemini-3-flash-preview. Hongliang He et al. WebVoyager: Building an end-to-end web agent with large multimodal models.arXiv preprint arXiv:2401.13919,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Lawrence Jang et al. VideoWebArena: Evaluating long context multimodal agents with video understanding web tasks.arXiv preprint arXiv:2410.19100,
-
[7]
Yiqiao Jin et al. ScreenLLM: Stateful screen schema for efficient action understanding and prediction.arXiv preprint arXiv:2503.20978,
-
[8]
Microsoft
Accessed 2026-05-14. Microsoft. NLWeb: A conversational interface for websites. https://github.com/microsoft/ NLWeb,
2026
-
[9]
MemGUI-Bench: Benchmarking memory in GUI agents.arXiv preprint arXiv:2509.12233,
Joonsuk Park et al. MemGUI-Bench: Benchmarking memory in GUI agents.arXiv preprint arXiv:2509.12233,
-
[10]
URL https://www.19pine.ai/blog/ pine-ai-the-most-natural-human-computer-interface-is-your-voice . Accessed 2026-06-28. Agent-Computer Observation Interfaces Enable Dynamic Computer Use 21 Rui Qian et al. Dispider: Enabling video LLMs with active real-time interaction via disentan- gled perception, decision, and reaction.arXiv preprint arXiv:2501.03218,
-
[11]
Qwen Team. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Robust Speech Recognition via Large-Scale Weak Supervision
arXiv:2212.04356. Alec Radford et al. Learning transferable visual models from natural language supervision. In ICML,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Learning Transferable Visual Models From Natural Language Supervision
arXiv:2103.00020. Pascal J. Sager et al. A comprehensive survey of agents for computer use: Foundations, challenges, and future directions.arXiv preprint arXiv:2501.16150,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv:2508.03923 [cs.CL] https://arxiv.org/abs/2508.03923
Linxin Song et al. CoAct-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923,
-
[15]
Cradle: Empowering foundation agents towards general computer control
Weihao Tan et al. Cradle: Empowering foundation agents towards general computer control. arXiv preprint arXiv:2403.03186,
-
[16]
Adaptive keyframe sampling for long video understanding.arXiv preprint arXiv:2502.21271,
Xi Tang et al. Adaptive keyframe sampling for long video understanding.arXiv preprint arXiv:2502.21271,
-
[17]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang et al. UI-TARS-2 technical report: Advancing GUI agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025a. Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents. InInternational Conference on Machine Learning (ICML), 2024a. Xinyuan Wang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Accessed 2026-05-14. Tianbao Xie et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
StreamAgent: Towards Anticipatory Agents for Streaming Video Understanding
Haolin Yang et al. StreamAgent: Towards anticipatory agents for streaming video understand- ing.arXiv preprint arXiv:2508.01875,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of- mark prompting unleashes extraordinary visual grounding in GPT-4V.arXiv preprint arXiv:2310.11441,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Agent-Computer Observation Interfaces Enable Dynamic Computer Use 22 John Yang et al. SWE-agent: Agent-computer interfaces enable automated software engineering. arXiv preprint arXiv:2405.15793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Mobile-Agent-v3: Fundamental Agents for GUI Automation
Jiabo Ye et al. Mobile-Agent-v3: Fundamental agents for GUI automation.arXiv preprint arXiv:2508.15144,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
VideoGameBench: Can Vision-Language Models complete popular video games?
Alex L. Zhang et al. VideoGameBench: Can vision-language models complete popular video games?arXiv preprint arXiv:2505.18134,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
A simple LLM framework for long-range video question-answering.arXiv preprint arXiv:2312.17235,
Ce Zhang et al. A simple LLM framework for long-range video question-answering.arXiv preprint arXiv:2312.17235,
-
[25]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou et al. WebArena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Apollo: An exploration of video understanding in large multimodal models
Orr Zohar et al. Apollo: An exploration of video understanding in large multimodal models. arXiv preprint arXiv:2412.10360,
-
[27]
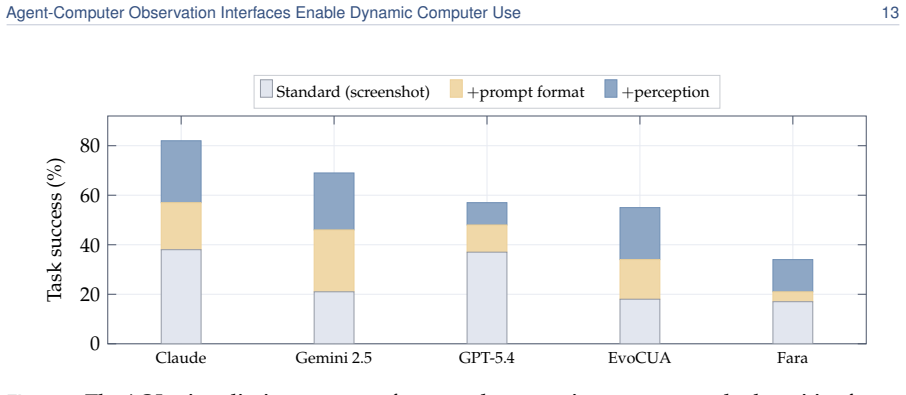
What is the new launch date?
Standard AOI Full ModelEasy Med Hard Easy Med Hard Claude 4.6 17/30 15/40 6/3028/3034/4020/30 GPT-5.4 15/30 17/40 5/30 21/30 26/40 10/30 Gemini 2.5 10/30 9/40 2/30 24/30 33/40 12/30 EvoCUA-32B 6/30 8/40 4/30 20/30 26/40 9/30 Fara-7B 9/30 5/40 3/30 19/30 11/40 4/30 Table 7.Efficiency and cost on the 100-task DynaCU-Bench. Grok-4 is omitted due to inference...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.