MotionAtlas: Detailed Region Captioning for Motion-Centric Videos
Pith reviewed 2026-06-30 07:18 UTC · model grok-4.3
The pith
Region-aware motion captioning with spatiotemporal masks improves Video-MLLM performance on motion tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
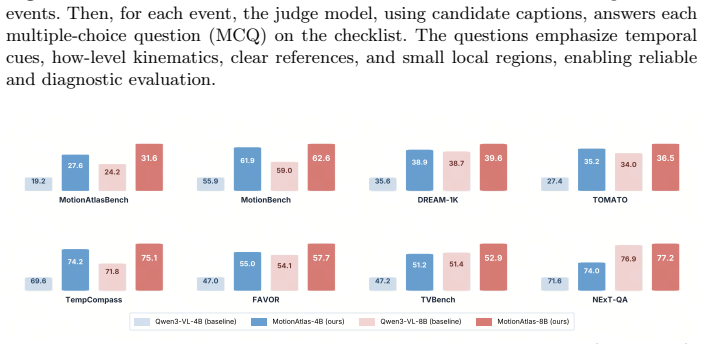
MotionAtlas establishes that region-aware captioning—given a video and a spatiotemporal mask—produces accurate motion descriptions within the target region, supported by a human-annotated benchmark of 2073 questions, a scalable pipeline yielding 159k refined captions via self-bootstrap refinement, and a training composition strategy that delivers consistent gains across Video-MLLMs including a 5.2 percentage point average improvement for the 4B model over Qwen3-VL-4B on general motion benchmarks.
What carries the argument
Region-aware motion captioning that takes a video plus a spatiotemporal mask and outputs a description limited to motion inside the masked region.
If this is right
- The benchmark enables reliable, quantifiable evaluation of fine-grained motion understanding.
- The data pipeline supplies 159k high-quality motion captioning samples.
- The tailored training composition produces consistent performance gains across multiple Video-MLLM baselines.
- MotionAtlas-4B exceeds Qwen3-VL-4B by 5.2 percentage points on average across general motion benchmarks.
Where Pith is reading between the lines
- The region-masking technique could extend to other video tasks that suffer from background clutter, such as action localization in crowded scenes.
- Public release of the benchmark and dataset may allow direct comparison of future region-aware captioning methods.
- The approach might integrate with temporal models to handle longer motion sequences while keeping the same mask-based isolation.
Load-bearing premise
The self-bootstrap refinement step produces captions that are high-quality and free of systematic biases that would inflate downstream benchmark scores.
What would settle it
An independently collected motion benchmark where models trained on the MotionAtlas pipeline show no average improvement over the same baselines.
Figures








read the original abstract
We propose MotionAtlas, a system for detailed captioning of motion-centric videos, comprising (1) a dedicated human-annotated benchmark, (2) a scalable, high-quality pipeline to construct training samples, and (3) a family of powerful Video-MLLMs. Unlike conventional global motion captioning datasets, we focus on region-aware motion captioning: given a video and a spatiotemporal mask, the model generates precise descriptions of motion within the target region, thereby alleviating visual clutter and motion entanglement and enabling reliable, quantifiable evaluation. Concretely, we first build MotionAtlas-Bench, a comprehensive benchmark comprising 2,073 multiple-choice questions, meticulously annotated for a curated set of high-quality, motion-centric videos, to evaluate fine-grained motion understanding of the objects in question. Second, we design a rigorous and scalable data pipeline that leverages self-bootstrap refinement to suppress fine-grained hallucinations, yielding 159k high-quality motion captioning data. Third, we design a tailored training data composition strategy, which achieves consistent and substantial performance gains across diverse baseline Video-MLLMs, including Molmo2 and Qwen3-VL. For instance, MotionAtlas-4B surpasses Qwen3-VL-4B by an average of 5.2 percentage points across general motion benchmarks. The benchmark, dataset, and code have been released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MotionAtlas for region-aware motion captioning in videos. It contributes (1) MotionAtlas-Bench, a human-annotated benchmark of 2,073 multiple-choice questions on motion-centric videos; (2) a scalable pipeline that uses self-bootstrap refinement to produce 159k training captions; and (3) fine-tuned Video-MLLMs (e.g., MotionAtlas-4B) that report consistent gains over baselines such as Qwen3-VL-4B (average +5.2 pp on general motion benchmarks). The benchmark, dataset, and code are released.
Significance. If the performance gains prove robust to the data-construction process, the work supplies targeted resources that could meaningfully improve fine-grained, region-specific motion understanding in Video-MLLMs, moving beyond global captioning limitations.
major comments (2)
- [Abstract] Abstract: the headline claim that MotionAtlas-4B surpasses Qwen3-VL-4B by an average of 5.2 percentage points supplies no information on statistical testing, data splits, or controls for annotation bias, rendering the central empirical result unverifiable from the provided description.
- [Abstract] Abstract: the self-bootstrap refinement step is presented as producing high-quality data that suppresses hallucinations, yet the manuscript provides no quantitative controls (n-gram overlap, answer-distribution statistics, or held-out human preference scores) that would rule out systematic biases aligned with the 2,073 items in MotionAtlas-Bench; this directly affects the validity of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that greater specificity on evaluation details and data-construction safeguards will improve verifiability. The full manuscript already contains the supporting experimental protocols and ablations; we will revise the abstract to surface these elements concisely. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that MotionAtlas-4B surpasses Qwen3-VL-4B by an average of 5.2 percentage points supplies no information on statistical testing, data splits, or controls for annotation bias, rendering the central empirical result unverifiable from the provided description.
Authors: The abstract is a high-level summary. The Experiments section reports results across multiple held-out general motion benchmarks, with the 2,073-question MotionAtlas-Bench kept strictly separate from all training videos. Gains are shown to be consistent across model scales and architectures (including Molmo2 and Qwen3-VL variants). We will revise the abstract to read: "MotionAtlas-4B surpasses Qwen3-VL-4B by an average of 5.2 percentage points across held-out general motion benchmarks (detailed evaluation protocol and per-benchmark breakdowns in Section 4)." This makes the claim traceable without lengthening the abstract unduly. revision: yes
-
Referee: [Abstract] Abstract: the self-bootstrap refinement step is presented as producing high-quality data that suppresses hallucinations, yet the manuscript provides no quantitative controls (n-gram overlap, answer-distribution statistics, or held-out human preference scores) that would rule out systematic biases aligned with the 2,073 items in MotionAtlas-Bench; this directly affects the validity of the reported gains.
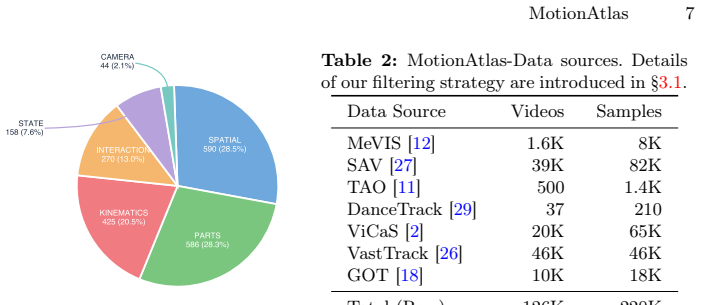
Authors: The self-bootstrap pipeline (Section 3) operates on a video pool with no overlap to the benchmark videos; training captions are generated and refined iteratively using model self-consistency before any benchmark evaluation. The manuscript already includes ablations showing that models trained on the refined 159k captions improve motion-region accuracy without degrading performance on unrelated captioning tasks, which would be expected under benchmark-style leakage. We will update the abstract to reference this separation and the ablation evidence: "The self-bootstrap pipeline yields 159k captions from videos disjoint from MotionAtlas-Bench and is validated by ablations demonstrating reduced hallucinations." Additional n-gram or preference-score tables can be added to the supplement if requested. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks and new data pipeline
full rationale
The paper introduces a new benchmark (MotionAtlas-Bench with 2,073 questions), a data construction pipeline using self-bootstrap refinement to produce 159k captions, and trained Video-MLLMs evaluated against external baselines such as Qwen3-VL-4B. No equations, derivations, fitted parameters, or uniqueness theorems appear in the provided text. Performance claims (e.g., +5.2 pp average gain) are presented as direct comparisons on general motion benchmarks rather than reductions to self-generated inputs by construction. The self-bootstrap step is a data-generation procedure, not a load-bearing self-citation chain or ansatz smuggled via prior work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multiple-choice questions on motion-centric videos can measure fine-grained motion understanding without annotation bias
- domain assumption Self-bootstrap refinement reliably suppresses fine-grained hallucinations while preserving motion details
invented entities (1)
-
MotionAtlas
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: CVPR (2025)
Athar, A., Deng, X., Chen, L.C.: Vicas: A dataset for combining holistic and pixel- level video understanding using captions with grounded segmentation. In: CVPR (2025)
2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: ICLR (2025)
Chai, W., Song, E., Du, Y., Meng, C., Madhavan, V., Bar-Tal, O., Hwang, J.N., Xie, S., Manning, C.D.: Auroracap: Efficient, performant video detailed captioning and a new benchmark. In: ICLR (2025)
2025
-
[5]
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleash- ing multimodal llm’s referential dialogue magic (2023),https://arxiv.org/abs/ 2306.15195
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
In: NeurIPS Datasets and Benchmarks Track (2024)
Chen, L., Wei, X., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Lin, B., Tang, Z., Yuan, L., Qiao, Y., Lin, D., Zhao, F., Wang, J.: ShareGPT4video: Improving video understanding and generation with better captions. In: NeurIPS Datasets and Benchmarks Track (2024)
2024
-
[7]
In: NeurIPS (2025)
Cho, J.H., Madotto, A., Mavroudi, E., Afouras, T., Nagarajan, T., Maaz, M., Song, Y., Ma, T., Hu, S., Jain, S., Martin, M., Wang, H., Rasheed, H.A., Sun, P., Huang, P.Y., Bolya, D., Ravi, N., Jain, S., Stark, T., Moon, S., Damavandi, B., Lee, V., Westbury, A., Khan, S., Kraehenbuehl, P., Dollar, P., Torresani, L., Grauman, K., Feichtenhofer, C.: Perceptio...
2025
-
[8]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Clark, C., Zhang, J., Ma, Z., Park, J.S., Salehi, M., Tripathi, R., Lee, S., Ren, Z., Kim, C.D., Yang, Y., et al.: Molmo2: Open weights and data for vision-language models with video understanding and grounding. arXiv preprint arXiv:2601.10611 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Comanici, G., et al.: Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities (2025), https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Cores,D.,Dorkenwald,M.,Mucientes,M.,Snoek,C.G.M.,Asano,Y.M.:TVBench: Redesigning video-language evaluation (2025),https://openreview.net/forum? id=DrNN5qx66Z
2025
-
[11]
In: ECCV (2020)
Dave, A., Khurana, T., Tokmakov, P., Schmid, C., Ramanan, D.: Tao: A large-scale benchmark for tracking any object. In: ECCV (2020)
2020
-
[12]
In: ICCV (2023)
Ding, H., Liu, C., He, S., Jiang, X., Loy, C.C.: Mevis: A large-scale benchmark for video segmentation with motion expressions. In: ICCV (2023)
2023
-
[13]
arXiv preprint arXiv:2506.01674 (2025) 16 W
Du, Y., Fan, T., Nan, K., Xie, R., Zhou, P., Li, X., Yang, J., Yang, Z., Tai, Y.: Mo- tionsight: Boosting fine-grained motion understanding in multimodal llms. arXiv preprint arXiv:2506.01674 (2025) 16 W. Liu et al
-
[14]
Duan, H., Fang, X., Yang, J., Zhao, X., Qiao, Y., Li, M., Agarwal, A., Chen, Z., Chen, L., Liu, Y., Ma, Y., Sun, H., Zhang, Y., Lu, S., Wong, T.H., Wang, W., Zhou, P., Li, X., Fu, C., Cui, J., Chen, J., Song, E., Mao, S., Ding, S., Liang, T., Zhang, Z., Dong, X., Zang, Y., Zhang, P., Wang, J., Lin, D., Chen, K.: Vlmevalkit: An open-source toolkit for eval...
-
[15]
In: CVPR (2025)
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: CVPR (2025)
2025
-
[16]
In: CVPR (2024)
Guo, Q., De Mello, S., Yin, H., Byeon, W., Cheung, K.C., Yu, Y., Luo, P., Liu, S.: Regiongpt: Towards region understanding vision language model. In: CVPR (2024)
2024
-
[17]
In: CVPR (2025)
Hong, W., Cheng, Y., Yang, Z., Wang, W., Wang, L., Gu, X., Huang, S., Dong, Y., Tang, J.: Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models. In: CVPR (2025)
2025
-
[18]
IEEE transactions on pattern analysis and machine intelligence43(5), 1562–1577 (2019)
Huang, L., Zhao, X., Huang, K.: Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE transactions on pattern analysis and machine intelligence43(5), 1562–1577 (2019)
2019
-
[19]
In: CVPR (2024)
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: CVPR (2024)
2024
-
[20]
In: ICLR (2025)
Li, L., Liu, Y., Yao, L., Zhang, P., An, C., Wang, L., Sun, X., Kong, L., Liu, Q.: Temporal reasoning transfer from text to video. In: ICLR (2025)
2025
-
[21]
arXiv preprint arXiv:2506.24102 (2025)
Li, X., Zhang, T., Li, Y., Yuan, H., Chen, S., Zhou, Y., Meng, J., Sun, Y., Xu, S., Qi, L., Cheng, T., Lin, Y., Huang, Z., Huang, W., Feng, J., Shi, G.: Denseworld- 1m: Towards detailed dense grounded caption in the real world. arXiv preprint arXiv:2506.24102 (2025)
-
[22]
In: NeurIPS (2025)
Lin, W., Wei, X., An, R., Ren, T., Chen, T., Zhang, R., Guo, Z., Zhang, W., Zhang, L., Li, H.: Perceive anything: Recognize, explain, caption, and segment anything in images and videos. In: NeurIPS (2025)
2025
-
[23]
In: EMNLP (2023)
Manakul, P., Liusie, A., Gales, M.: Selfcheckgpt: Zero-resource black-box halluci- nation detection for generative large language models. In: EMNLP (2023)
2023
-
[24]
arXiv preprint arXiv:2510.20579 (2025)
Meng, J., Li, X., Wang, H., Tan, Y., Zhang, T., Kong, L., Tong, Y., Wang, A., Teng, Z., Wang, Y., Wang, Z.: Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence. arXiv preprint arXiv:2510.20579 (2025)
-
[25]
OpenAI: Introducing gpt-5.2 (2025),https://openai.com/index/introducing- gpt-5-2/
2025
-
[26]
NeurIPS (2024)
Peng, L., Gao, J., Liu, X., Li, W., Dong, S., Zhang, Z., Fan, H., Zhang, L.: Vast- track: Vast category visual object tracking. NeurIPS (2024)
2024
-
[27]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
In: ICLR (2025)
Shangguan, Z., Li, C., Ding, Y., Zheng, Y., Zhao, Y., Fitzgerald, T., Cohan, A.: TOMATO: Assessing visual temporal reasoning capabilities in multimodal foun- dation models. In: ICLR (2025)
2025
-
[29]
In: CVPR (2022)
Sun, P., Cao, J., Jiang, Y., Yuan, Z., Bai, S., Kitani, K., Luo, P.: Dancetrack: Multi-object tracking in uniform appearance and diverse motion. In: CVPR (2022)
2022
-
[30]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, G., bastien Grill, J., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., MotionAtlas 17 Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Busa-Fekete, R., Feng, A., Sac...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
In: NeurIPS Datasets and Benchmarks Track (2025)
Tu, C., Zhang, L., Chen, P., Ye, P., Zeng, X., Cheng, W., YU, G., Chen, T.: FAVOR-bench: A comprehensive benchmark for fine-grained video motion under- standing. In: NeurIPS Datasets and Benchmarks Track (2025)
2025
-
[32]
ICLR (2026)
Wang, H., Wang, Y., Zhang, T., Zhou, Y., Li, Y., Wang, J., Tian, Y., Meng, J., Huang, Z., Mai, G., Wang, A., Tong, Y., Wang, Z., Li, X., Zhang, Z.: Grasp any region: Towards precise, contextual pixel understanding for multimodal llms. ICLR (2026)
2026
-
[33]
arXiv preprint arXiv:2509.09676 (2025)
Wang, J., Yuan, Y., Zheng, R., Lin, Y., Gao, J., Chen, L.Z., Bao, Y., Zhang, Y., Zeng, C., Zhou, Y., et al.: Spatialvid: A large-scale video dataset with spatial annotations. arXiv preprint arXiv:2509.09676 (2025)
- [34]
-
[35]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022) 18 W. Liu et al
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Wang, Y., Li, X., Yan, Z., He, Y., Yu, J., Zeng, X., Wang, C., Ma, C., Huang, H., Gao, J., Dou, M., Chen, K., Wang, W., Qiao, Y., Wang, Y., Wang, L.: Intern- video2.5: Empowering video mllms with long and rich context modeling (2025), https://arxiv.org/abs/2501.12386
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
In: CVPR (2021)
Xiao,J.,Shang,X.,Yao,A.,Chua,T.S.:Next-qa:Nextphaseofquestion-answering to explaining temporal actions. In: CVPR (2021)
2021
-
[39]
In: CVPR (2022)
Xu, J., Rao, Y., Yu, X., Chen, G., Zhou, J., Lu, J.: Finediving: A fine-grained dataset for procedure-aware action quality assessment. In: CVPR (2022)
2022
-
[40]
Yang,S.,Liu,Y.,Zhai,B.,Sun,X.,Liu,Z.,Barsoum,E.,Li,M.,Xu,C.:Captionqa: Is your caption as useful as the image itself? arXiv preprint arXiv:2511.21025 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
In: AAAI (2019)
Yu, Z., Xu, D., Yu, J., Yu, T., Zhao, Z., Zhuang, Y., Tao, D.: Activitynet-qa: A dataset for understanding complex web videos via question answering. In: AAAI (2019)
2019
-
[42]
arXiv preprint (2025)
Yuan, H., Li, X., Zhang, T., Sun, Y., Huang, Z., Xu, S., Ji, S., Tong, Y., Qi, L., Feng, J., Yang, M.H.: Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos. arXiv preprint (2025)
2025
-
[43]
arXiv preprint arXiv:2501.07888 (2025)
Yuan, L., Wang, J., Sun, H., Zhang, Y., Lin, Y.: Tarsier2: Advancing large vision- language models from detailed video description to comprehensive video under- standing. arXiv preprint arXiv:2501.07888 (2025)
-
[44]
In: CVPR (2024)
Yuan, Y., Li, W., Liu, J., Tang, D., Luo, X., Qin, C., Zhang, L., Zhu, J.: Osprey: Pixel understanding with visual instruction tuning. In: CVPR (2024)
2024
-
[45]
In: CVPR (2025)
Yuan, Y., Zhang, H., Li, W., Cheng, Z., Zhang, B., Li, L., Li, X., Zhao, D., Zhang, W., Zhuang, Y., et al.: Videorefer suite: Advancing spatial-temporal object under- standing with video llm. In: CVPR (2025)
2025
- [46]
-
[47]
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., Jin, P., Zhang, W., Wang, F., Bing, L., Zhao, D.: Videollama 3: Frontier multimodal foundation models for image and video understanding (2025), https://arxiv.org/abs/2501.13106
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: Findings of NAACL (2025)
Zhang, K., Li, B., Zhang, P., Pu, F., Cahyono, J.A., Hu, K., Liu, S., Zhang, Y., Yang, J., Li, C., Liu, Z.: Lmms-eval: Reality check on the evaluation of large multimodal models. In: Findings of NAACL (2025)
2025
-
[49]
Zhang, S., Sun, P., Chen, S., Xiao, M., Shao, W., Zhang, W., Liu, Y., Chen, K., Luo, P.: GPT4roi: Instruction tuning large language model on region-of-interest (2024),https://openreview.net/forum?id=DzxaRFVsgC
2024
-
[50]
In: NeurIPS (2024)
Zhang, T., Li, X., Fei, H., Yuan, H., Wu, S., Ji, S., Chen, C.L., Yan, S.: Omg- llava: Bridging image-level, object-level, pixel-level reasoning and understanding. In: NeurIPS (2024)
2024
-
[51]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024) MotionAtlas 19 Overview.In this appendix, we provide additional implementation details, qualitative results, and analyses to complement the main paper. Furthermore, we include asupplementary demo vid...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.