See Only When Needed: Context-Aware Attention Intervention for Mitigating Hallucinations in LVLMs
Pith reviewed 2026-06-30 06:44 UTC · model grok-4.3
The pith
Context-aware attention intervention reduces object hallucinations in vision-language models by intervening selectively on uncertain tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAI derives token-specific visual relevance from early-layer representations to localize semantically aligned regions and applies a conservative entropy- and depth-gated attention tilt only to uncertainty-spiking tokens in deeper layers, enforcing see-only-when-needed selectivity that strengthens grounding while preserving fluency and achieving state-of-the-art hallucination mitigation as a KL-minimal reweighting with bounded interference under inactive gates or small tilts.
What carries the argument
Context-aware Attention Intervention (CAI), the two-axis selectivity mechanism that uses early-layer visual relevance for localization and applies gated attention reweighting only on uncertain deeper-layer tokens.
If this is right
- The method yields consistent hallucination reductions across multiple LVLM backbones without any training.
- Linguistic fluency is maintained because confident tokens and irrelevant regions receive no change.
- Contrastive decoding remains optional rather than required for the gains.
- The intervention is characterized as KL-minimal reweighting with interference bounded by inactive gates or small tilts.
Where Pith is reading between the lines
- The approach implies that visual grounding errors concentrate in deeper layers specifically around high-entropy tokens rather than uniformly.
- It could extend to other generation flaws in multimodal models where selective correction might avoid side effects.
- The early-to-late layer distinction suggests a natural division of labor that future architectures might exploit directly.
Load-bearing premise
Early-layer representations accurately identify which image regions matter for each specific token, and selectively tilting attention on uncertain tokens strengthens correct grounding without adding new errors or reducing output quality.
What would settle it
A controlled test on standard benchmarks where the attention tilt is applied only to tokens flagged as uncertain shows no reduction in hallucination rates relative to the unmodified model.
Figures

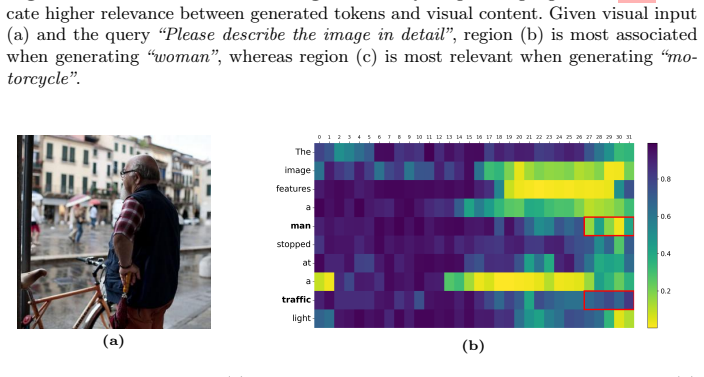
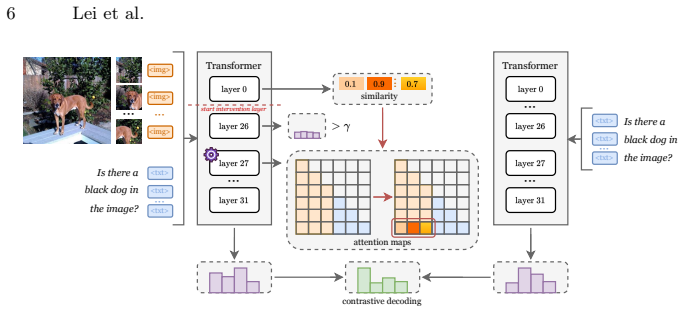



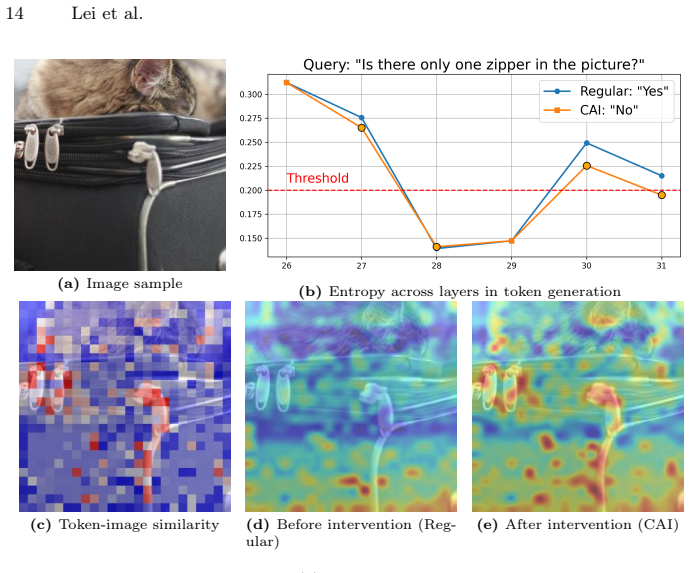


read the original abstract
Large Vision-Language Models (LVLMs) excel at multimodal tasks but remain prone to object hallucinations. Prior training-free remedies often uniformly strengthen visual signals, which may also amplify irrelevant regions and introduce spurious evidence, harming fluency. We propose Context-aware Attention Intervention (CAI), a training-free inference-time mechanism that enforces a see only when needed principle via two-axis selectivity: where to look and when to intervene. At each decoding step, CAI derives token-specific visual relevance from early-layer representations to localize semantically aligned regions, and applies a conservative, entropy- and depth-gated attention tilt only for uncertainty-spiking tokens in deeper layers where visual grounding degrades, leaving confident tokens and irrelevant regions largely unchanged. This targeted intervention strengthens visual grounding while preserving linguistic fluency, and it yields consistent improvements even without contrastive decoding, which remains optional as an auxiliary bias-suppression module. Extensive experiments across multiple LVLM backbones and benchmarks show that CAI achieves state-of-the-art hallucination mitigation, and our analysis characterizes CAI as a KL-minimal attention reweighting with bounded interference under inactive gates or small tilts. Code is available at https://github.com/Iris1946/CAI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Context-aware Attention Intervention (CAI), a training-free inference-time mechanism for mitigating object hallucinations in LVLMs. It enforces a 'see only when needed' principle through two-axis selectivity: deriving token-specific visual relevance from early-layer representations to localize semantically aligned regions, then applying entropy- and depth-gated attention tilts only to uncertainty-spiking tokens in deeper layers. The method claims consistent SOTA improvements across multiple LVLM backbones and benchmarks, even without contrastive decoding (which is optional), and characterizes the intervention as KL-minimal reweighting with bounded interference under inactive gates or small tilts. Code is released publicly.
Significance. If the empirical results and the KL-minimal characterization hold under the stated assumptions, this would represent a meaningful advance by providing a targeted, training-free intervention that avoids the fluency degradation and spurious evidence risks of uniform visual strengthening approaches. The public code release supports reproducibility and enables direct follow-up work on LVLM reliability.
major comments (2)
- [Experiments] The central claim that two-axis selectivity strengthens grounding without amplifying irrelevant regions or harming fluency rests on the accuracy of token-specific visual relevance derived from early-layer representations. No quantitative validation of this localization (e.g., overlap metrics with ground-truth object regions or ablation isolating localization quality from the gating) appears in the experiments, leaving the bounded-interference guarantee unsupported.
- [Analysis] The analysis section characterizes CAI as KL-minimal attention reweighting, but the abstract provides no derivation, closed-form expression, or controlled measurement showing that the reweighting is minimal or that interference remains bounded when gates are inactive; this property is load-bearing for the 'conservative' and 'parameter-free' framing of the intervention.
minor comments (1)
- [Abstract] The abstract states 'extensive experiments across multiple LVLM backbones and benchmarks' but does not name the specific models or datasets in the opening paragraph; moving this detail forward would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications and indicate planned revisions to strengthen the empirical and analytical support.
read point-by-point responses
-
Referee: [Experiments] The central claim that two-axis selectivity strengthens grounding without amplifying irrelevant regions or harming fluency rests on the accuracy of token-specific visual relevance derived from early-layer representations. No quantitative validation of this localization (e.g., overlap metrics with ground-truth object regions or ablation isolating localization quality from the gating) appears in the experiments, leaving the bounded-interference guarantee unsupported.
Authors: We acknowledge the value of quantitative validation for the early-layer localization. The current manuscript provides qualitative attention visualizations demonstrating semantic alignment, but we agree that overlap metrics and isolating ablations would offer stronger evidence. In the revised version, we will add mean IoU overlap with ground-truth object regions on a benchmark subset and an ablation separating localization quality from the entropy/depth gates to better support the bounded-interference property. revision: yes
-
Referee: [Analysis] The analysis section characterizes CAI as KL-minimal attention reweighting, but the abstract provides no derivation, closed-form expression, or controlled measurement showing that the reweighting is minimal or that interference remains bounded when gates are inactive; this property is load-bearing for the 'conservative' and 'parameter-free' framing of the intervention.
Authors: The analysis section derives the KL-minimal characterization and states the bounded-interference property under inactive gates or small tilts. To make this more explicit as requested, the revision will include a dedicated subsection with the closed-form KL divergence expression between original and intervened distributions, plus controlled empirical measurements of KL values across gate states and tilt sizes. This will reinforce the conservative framing without altering the core method. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical intervention
full rationale
The paper introduces CAI as a training-free inference-time mechanism that derives token-specific visual relevance from early-layer representations and applies entropy- and depth-gated attention tilt. The central result (SOTA hallucination mitigation with KL-minimal reweighting characterization) is supported by experiments across multiple LVLM backbones and benchmarks, with the characterization presented as an analysis of the proposed method rather than a reduction to fitted inputs or self-citations. No load-bearing steps reduce by construction to the paper's own definitions, predictions, or prior self-citations. The method remains independent of its inputs and externally falsifiable via the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard multi-head attention and layer-wise representation properties in transformer-based LVLMs
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
An, W., Tian, F., Leng, S., Nie, J., Lin, H., Wang, Q., Chen, P., Zhang, X., Lu, S.: Mitigating object hallucinations in large vision-language models with assembly of global and local attention. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29915–29926 (2025)
2025
-
[2]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Hallucination of Multimodal Large Language Models: A Survey
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., Shou, M.Z.: Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Advances in Neural Information Processing Systems37, 7400–7426 (2024)
Basu, S., Grayson, M., Morrison, C., Nushi, B., Feizi, S., Massiceti, D.: Under- standing information storage and transfer in multi-modal large language models. Advances in Neural Information Processing Systems37, 7400–7426 (2024)
2024
-
[5]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, J., Zhang, T., Huang, S., Niu, Y., Zhang, L., Wen, L., Hu, X.: Ict: Image- object cross-level trusted intervention for mitigating object hallucination in large vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4209–4221 (2025)
2025
-
[7]
arXiv preprint arXiv:2311.16479 (2023) 16 Lei et al
Chen, Z., Zhu, Y., Zhan, Y., Li, Z., Zhao, C., Wang, J., Tang, M.: Mitigating hallucination in visual language models with visual supervision. arXiv preprint arXiv:2311.16479 (2023) 16 Lei et al
-
[8]
Journal of Machine Learning Research24(240), 1–113 (2023)
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., et al.: Palm: Scaling lan- guage modeling with pathways. Journal of Machine Learning Research24(240), 1–113 (2023)
2023
-
[9]
In: International Conference on Learning Representations
Chuang, Y.S., Xie, Y., Luo, H., Kim, Y., Glass, J.R., He, P.: Dola: Decoding by contrasting layers improves factuality in large language models. In: International Conference on Learning Representations. vol. 2024, pp. 54158–54183 (2024)
2024
-
[10]
Advances in neural information processing systems36, 49250–49267 (2023)
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023)
2023
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Favero, A., Zancato, L., Trager, M., Choudhary, S., Perera, P., Achille, A., Swami- nathan, A., Soatto, S.: Multi-modal hallucination control by visual information grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14303–14312 (2024)
2024
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entan- gled language hallucination and visual illusion in large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14375–14385 (2024)
2024
-
[13]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Hu, Y., Lin, S.: Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
2019
-
[15]
arXiv preprint arXiv:2408.02032 (2024)
Huo, F., Xu, W., Zhang, Z., Wang, H., Chen, Z., Zhao, P.: Self-introspective de- coding: Alleviating hallucinations for large vision-language models. arXiv preprint arXiv:2408.02032 (2024)
-
[16]
Jiang, C., Xu, H., Dong, M., Chen, J., Ye, W., Yan, M., Ye, Q., Zhang, J., Huang, F., Zhang, S.: Hallucination augmented contrastive learning for multimodal large languagemodel.In:ProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition. pp. 27036–27046 (2024)
2024
-
[17]
Proceedings of the 2023 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (2023)
Lee, S., Park, S.H., Jo, Y., Seo, M.: Volcano: mitigating multimodal hallucination through self-feedback guided revision. Proceedings of the 2023 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (2023)
2023
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13872–13882 (2024)
2024
-
[19]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[20]
VisualBERT: A Simple and Performant Baseline for Vision and Language
Li, L.H., Yatskar, M., Yin, D., Hsieh, C.J., Chang, K.W.: Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[21]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023) Context-Aware Attention Intervention for Mitigating Hallucinations 17
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hallucination in large vision-language models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023) Context-Aware Attention Intervention for Mitigating Hallucinations 17
2023
-
[22]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[23]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., Wang, L.: Mitigating hallucina- tion in large multi-modal models via robust instruction tuning. arXiv preprint arXiv:2306.14565 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
A Survey on Hallucination in Large Vision-Language Models
Liu, H., Xue, W., Chen, Y., Chen, D., Zhao, X., Wang, K., Hou, L., Li, R., Peng, W.: A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[26]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[27]
In: The Thirteenth International Conference on Learning Representations (2025)
Liu, S., Ye, H., Zou, J.: Reducing hallucinations in large vision-language models via latent space steering. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[28]
In: European Conference on Com- puter Vision
Liu, S., Zheng, K., Chen, W.: Paying more attention to image: A training-free method for alleviating hallucination in lvlms. In: European Conference on Com- puter Vision. pp. 125–140. Springer (2024)
2024
-
[29]
Visual-RFT: Visual Reinforcement Fine-Tuning
Liu, Z., Sun, Z., Zang, Y., Dong, X., Cao, Y., Duan, H., Lin, D., Wang, J.: Visual- rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
In: The Thirteenth International Conference on Learning Representations (2025)
Neo, C., Ong, L., Torr, P., Geva, M., Krueger, D., Barez, F.: Towards interpret- ing visual information processing in vision-language models. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[31]
Advances in neural information processing sys- tems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022)
2022
-
[32]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing p
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object hallu- cination in image captioning. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing p. 4035–4045 (2018)
2018
-
[33]
In: European conference on computer vision
Schwenk, D., Khandelwal, A., Clark, C., Marino, K., Mottaghi, R.: A-okvqa: A benchmark for visual question answering using world knowledge. In: European conference on computer vision. pp. 146–162. Springer (2022)
2022
-
[34]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Shen, H., Liu, P., Li, J., Fang, C., Ma, Y., Liao, J., Shen, Q., Zhang, Z., Zhao, K., Zhang, Q., et al.: Vlm-r1: A stable and generalizable r1-style large vision-language model. arXiv preprint arXiv:2504.07615 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
In: Proceedings of the IEEE/CVF international conference on computer vision
Sun,C.,Myers,A.,Vondrick,C.,Murphy,K.,Schmid,C.:Videobert:Ajointmodel for video and language representation learning. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7464–7473 (2019)
2019
-
[36]
Aligning Large Multimodal Models with Factually Augmented RLHF
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L.Y., Wang, Y.X., Yang, Y., et al.: Aligning large multimodal models with factually augmented rlhf. arXiv preprint arXiv:2309.14525 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
arXiv preprint arXiv:2503.20752 (2025)
Tan, H., Ji, Y., Hao, X., Lin, M., Wang, P., Wang, Z., Zhang, S.: Reason-rft: Reinforcement fine-tuning for visual reasoning. arXiv preprint arXiv:2503.20752 (2025)
-
[38]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, F., Liu, C., Xu, Z., Hu, M., Huang, Z., Xue, H., Chen, Z., Peng, Z., Yang, Z., Zhou, S., et al.: Seeing far and clearly: Mitigating hallucinations in mllms with attention causal decoding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26147–26159 (2025) 18 Lei et al
2025
-
[39]
Team, Q.: Qwen3.5: Accelerating productivity with native multimodal agents (February 2026),https://qwen.ai/blog?id=qwen3.5
2026
-
[40]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Proceedings of the International Confer- ence on Computer Vision (2025)
Wan, Z., Zhang, C., Yong, S., Ma, M.Q., Stepputtis, S., Morency, L.P., Ramanan, D., Sycara, K., Xie, Y.: Only: One-layer intervention sufficiently mitigates halluci- nations in large vision-language models. Proceedings of the International Confer- ence on Computer Vision (2025)
2025
-
[42]
Proceedings of the 29th International Conference on Computational Linguistics p
Wu, Y., Zhao, Y., Zhao, S., Zhang, Y., Yuan, X., Zhao, G., Jiang, N.: Overcoming language priors in visual question answering via distinguishing superficially simi- lar instances. Proceedings of the 29th International Conference on Computational Linguistics p. 5721–5729 (2022)
2022
-
[43]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Ye, Q., Xu, H., Xu, G., Ye, J., Yan, M., Zhou, Y., Wang, J., Hu, A., Shi, P., Shi, Y., et al.: mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[45]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Yu, Q., Li, J., Wei, L., Pang, L., Ye, W., Qin, B., Tang, S., Tian, Q., Zhuang, Y.: Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 12944–12953 (2024)
2024
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, T., Yao, Y., Zhang, H., He, T., Han, Y., Cui, G., Hu, J., Liu, Z., Zheng, H.T., Sun, M., et al.: Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13807–13816 (2024)
2024
-
[47]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics pp
Yue, Z., Zhang, L., Jin, Q.: Less is more: Mitigating multimodal hallucination from an eos decision perspective. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics pp. 11766–11781 (2024)
2024
-
[48]
arXiv preprint arXiv:2601.20279 (2026)
Zhang, X., Zhu, Y., Gu, C., Yuan, X., Zhao, Q., Cao, J., Tang, F., Fan, S., Shen, Y., Shen, C., et al.: Hallucination begins where saliency drops. arXiv preprint arXiv:2601.20279 (2026)
-
[49]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Zhao, Z., Wang, B., Ouyang, L., Dong, X., Wang, J., He, C.: Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model
Zhou, H., Li, X., Wang, R., Cheng, M., Zhou, T., Hsieh, C.J.: R1-zero’s" aha mo- ment" in visual reasoning on a 2b non-sft model. arXiv preprint arXiv:2503.05132 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
The Eleventh International Conference on Learning Representations (2023)
Zhou, Y., Cui, C., Yoon, J., Zhang, L., Deng, Z., Finn, C., Bansal, M., Yao, H.: Analyzing and mitigating object hallucination in large vision-language models. The Eleventh International Conference on Learning Representations (2023)
2023
-
[52]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Please describe this image in detail
Zou, X., Wang, Y., Yan, Y., Lyu, Y., Zheng, K., Huang, S., Chen, J., Jiang, P., Liu, J., Tang, C., Hu, X.: Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models. The Forty-second International Conference on Machine Learning (ICML) (2025) Context-Aware Attention Intervention for Mitigat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.