Can LLM-as-a-Judge Reliably Verify Rubrics in Agentic Scenarios?
Pith reviewed 2026-06-30 06:40 UTC · model grok-4.3
The pith
Even advanced LLMs exhibit substantial noise when verifying rubrics on long agentic outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
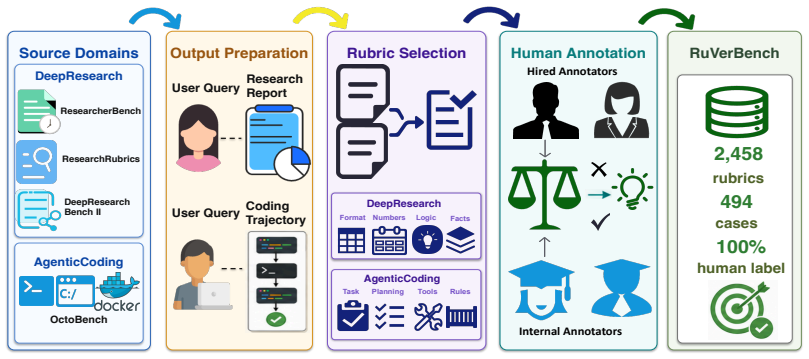
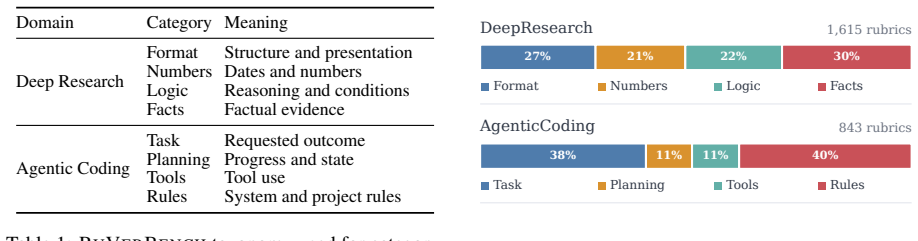
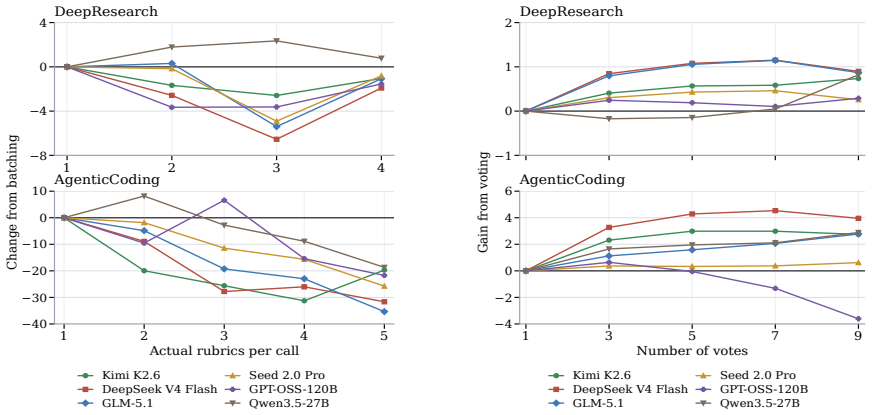
We introduce RuVerBench to meta-evaluate LLM-as-a-Judge reliability for rubric verification in agentic scenarios. The benchmark spans deep research and agentic coding with 2458 instances containing model outputs, rubrics, and human satisfaction labels. Frontier models reach strong aggregate performance yet display substantial per-instance noise; weaker models prove more sensitive to prompt changes, batched scoring trades accuracy for speed, and majority voting helps but yields diminishing returns.
What carries the argument
RuVerBench, a dataset of model outputs paired with rubrics and human-verified satisfaction labels across two agentic domains.
If this is right
- Weaker models change judgments more when prompt wording varies.
- Batched rubric verification reduces compute but lowers accuracy compared with separate calls.
- Majority voting across multiple judgments improves reliability yet shows diminishing gains beyond a small number of votes.
- Long, complex agent outputs remain harder for LaaJ to score consistently than shorter responses.
Where Pith is reading between the lines
- If the human labels contain their own inconsistencies, the measured LaaJ noise may be inflated.
- Automated agent evaluations that rely solely on current LaaJ rubric checks may need supplementary human review or ensemble methods.
- Future benchmarks could test whether rubric verification improves when the judge model is allowed to request clarification on ambiguous rubrics.
Load-bearing premise
The human-annotated labels collected for RuVerBench constitute reliable ground truth for whether a model-generated output satisfies each rubric.
What would settle it
Collecting a fresh set of independent human annotations on the same 2458 instances and finding systematic disagreement with the original labels on a large fraction of cases would show the reported noise levels rest on unreliable ground truth.
Figures


read the original abstract
Rubric-based scoring has become a widely used paradigm in model evaluation, typically with LLM-as-a-Judge (LaaJ) for rubric scoring. However, the reliability of LaaJ for rubric scoring remains underexplored. This concern is especially pronounced in agentic scenarios, where long, complex outputs further challenge reliable scoring. To address this, we conduct a systematic meta-evaluation of LaaJ reliability for rubric verification. We introduce RuVerBench, the first benchmark for assessing LaaJ reliability in rubric verification for agentic scenarios. RuVerBench covers two prevalent agentic domains, deep research and agentic coding, with 2,458 instances, each containing a model-generated output, a rubric, and a human-annotated label indicating whether the output satisfies the rubric. Using RuVerBench, we evaluate numerous frontier LLMs and find that even the most advanced models achieve strong performance but still exhibit substantial noise. We further analyze the impact of key LaaJ strategies, including prompt design, batching, and majority voting, on rubric verification. We find that weaker models are more sensitive to prompt variations, batched verification presents a trade-off between accuracy and efficiency, and majority voting yields effective but diminishing returns. We have released our dataset and code to facilitate future research: https://github.com/THU-KEG/RuVerBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RuVerBench, a benchmark of 2,458 instances across deep research and agentic coding domains. Each instance pairs a model-generated output with a rubric and a human-annotated binary label indicating whether the output satisfies the rubric. The work meta-evaluates frontier LLMs as judges for rubric verification, reporting that even the strongest models achieve strong performance yet exhibit substantial noise; it further examines the effects of prompt design, batching, and majority voting on verification reliability and releases the dataset and code.
Significance. If the human labels prove reliable, RuVerBench would supply a needed empirical resource for quantifying LaaJ limitations in long, subjective agentic outputs and for testing mitigation strategies. The public release of the dataset and code is a clear positive that enables follow-on work.
major comments (1)
- [RuVerBench construction / dataset description] The RuVerBench construction section provides no information on the human annotation protocol: number of annotators per instance, inter-annotator agreement statistics, adjudication procedure, or any validation against an external reference. Because all reported performance numbers and the claim of 'substantial noise' are computed against these binary labels, the absence of reliability evidence directly undermines the central empirical conclusions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and commit to revising the paper accordingly.
read point-by-point responses
-
Referee: [RuVerBench construction / dataset description] The RuVerBench construction section provides no information on the human annotation protocol: number of annotators per instance, inter-annotator agreement statistics, adjudication procedure, or any validation against an external reference. Because all reported performance numbers and the claim of 'substantial noise' are computed against these binary labels, the absence of reliability evidence directly undermines the central empirical conclusions.
Authors: We agree that the manuscript currently lacks a detailed description of the human annotation protocol, which is necessary to substantiate the reliability of the binary labels and the associated performance claims. In the revised version, we will add a dedicated subsection to the RuVerBench construction section that specifies the number of annotators per instance, reports inter-annotator agreement statistics, describes the adjudication procedure, and outlines any validation steps performed against external references. This addition will directly address the concern and strengthen the empirical basis of our results. revision: yes
Circularity Check
No circularity: empirical benchmark with independent human labels and model evaluations
full rationale
The paper introduces RuVerBench, a new dataset of 2,458 instances with model outputs, rubrics, and human-annotated binary labels, then reports empirical performance of frontier LLMs on rubric verification. No equations, derivations, fitted parameters, or predictions appear in the provided text. Claims rest on direct comparison to the released human labels rather than any self-referential construction, renaming, or self-citation chain. The work is self-contained as a benchmark release and evaluation; human-label reliability is an external validity concern, not a circularity issue in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations provide reliable ground truth for rubric satisfaction.
Reference graph
Works this paper leans on
-
[1]
AlpaGasus: Training a better alpaca with fewer data.Preprint, arXiv:2307.08701. Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Shari- fymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. 2025. Browseco...
-
[2]
Long-form factuality in large language models. Preprint, arXiv:2403.18802. Xiaomi MiMo Team. 2026. MiMo-V2.5-Pro. https: //mimo.xiaomi.com/. Renjun Xu and Jingwen Peng. 2025. A comprehensive survey of deep research: Systems, methodologies, and applications.arXiv preprint arXiv:2506.12594. Tianze Xu, Pengrui Lu, Lyumanshan Ye, Xiangkun Hu, and Pengfei Liu....
-
[4]
success"`: the assistant clearly followed the requirement -`
Decision criteria: -`"success"`: the assistant clearly followed the requirement -`"fail"`: the assistant clearly violated the requirement, or failed to follow it when it should apply 3.`reasoning`field: - For "fail": briefly explain how the assistant violated the requirement - For "success": briefly explain how the assistant followed the requirement -----...
-
[6]
The output must be valid JSON; do not add any text outside the JSON object
-
[7]
You are an Agent instruction-following evaluator
Ensure that the output check_id exactly matches the input check_id Please evaluate strictly according to the Check description.{prompt_style_instruction} Agentic Coding all-rubrics batching template. You are an Agent instruction-following evaluator. Your task is to evaluate the assistant's behavior in the conversation item by item according to the given C...
-
[8]
assistant
Evaluation basis: inspect all messages where `role == "assistant"`, including: - natural-language outputs - internal reasoning (reasoning_content, if available) - tool calls (tool_calls)
-
[9]
success"`: the assistant clearly followed the requirement -`
Decision criteria: -`"success"`: the assistant clearly followed the requirement -`"fail"`: the assistant clearly violated the requirement, or failed to follow it when it should apply 3.`reasoning`field: - For "fail": briefly explain how the assistant violated the requirement - For "success": briefly explain how the assistant followed the requirement -----...
-
[10]
success" or
result must be either "success" or "fail" in lowercase, with no other values allowed
-
[11]
The output must be valid JSON; do not add any text outside the JSON array
-
[12]
success" only when the assistant explicitly and completely satisfies the Check. If satisfaction is implicit, ambiguous, partial, or missing a key detail, classify as
Ensure that every input check_id appears exactly once in the output; do not omit or rewrite check_id by relying on order Please evaluate strictly according to each Check description.{prompt_style_instruction} Agentic Coding batched check serialization. {index}. Category: {category} Check ID: {check_id} Description: {description} Agentic Coding prompt-styl...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.