When Is a Draft Accepted? A Theory of Acceptance in Speculative Decoding
Pith reviewed 2026-06-30 07:37 UTC · model grok-4.3
The pith
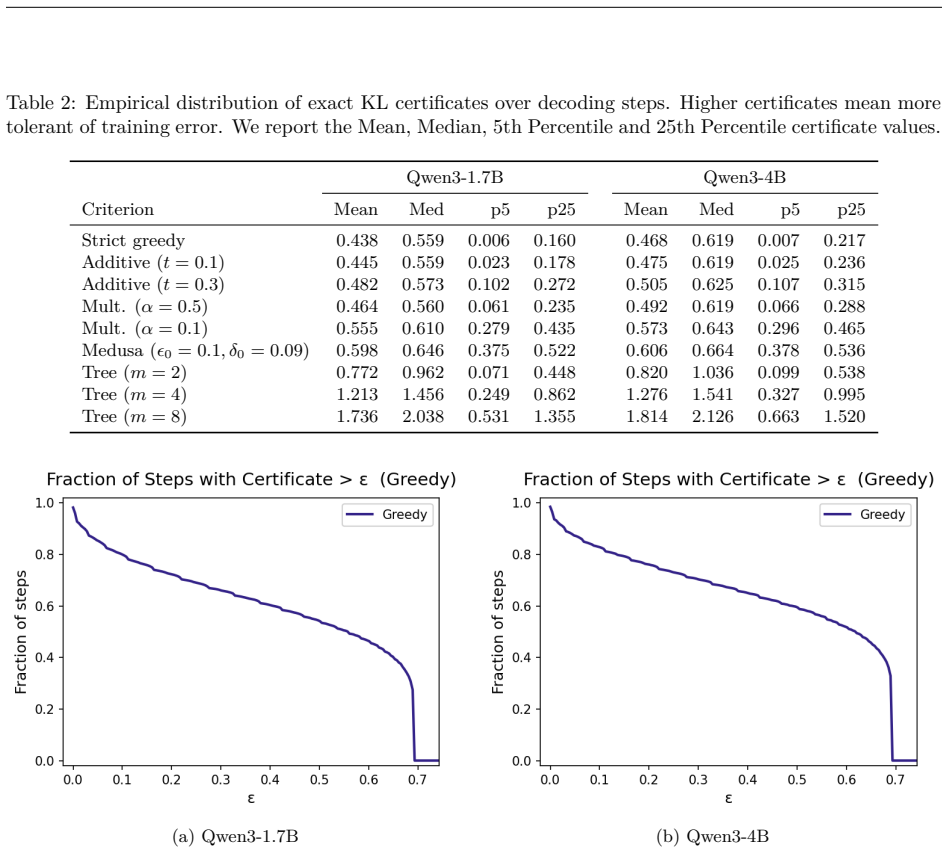
Many common acceptance criteria in speculative decoding have rejection regions that are lower level sets of the target distribution, allowing exact KL certificates and margin bounds for greedy, relaxed, and tree rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
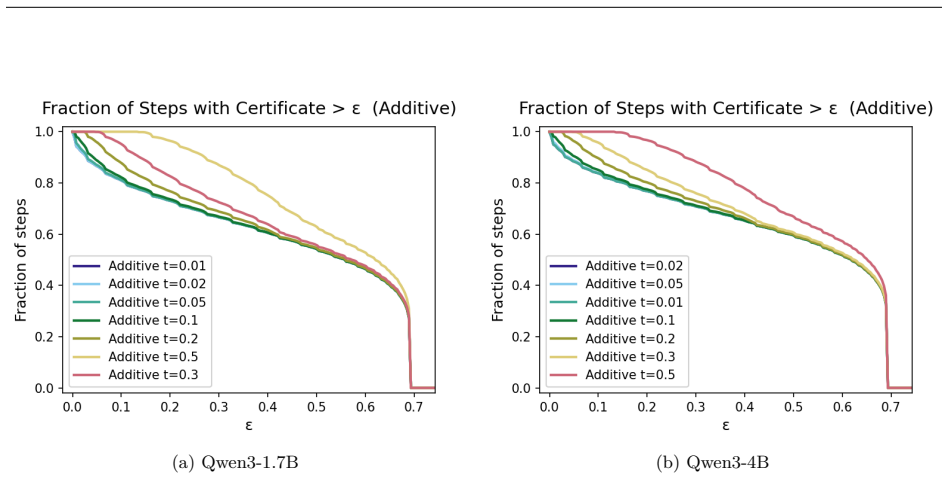
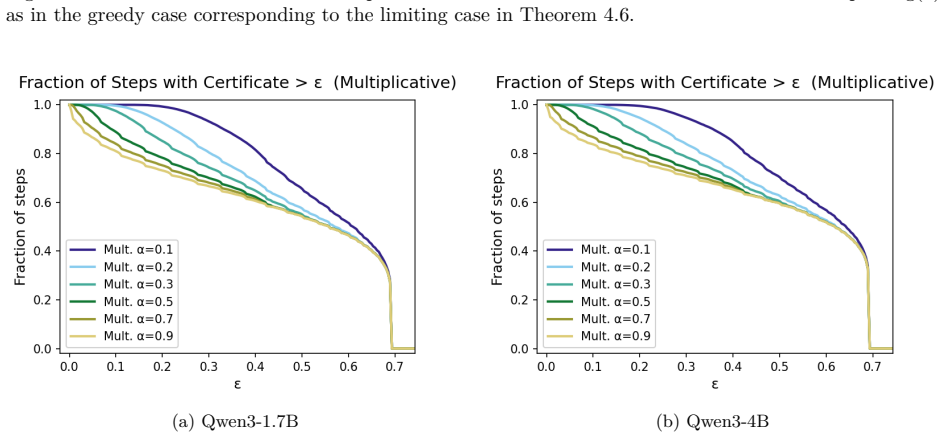
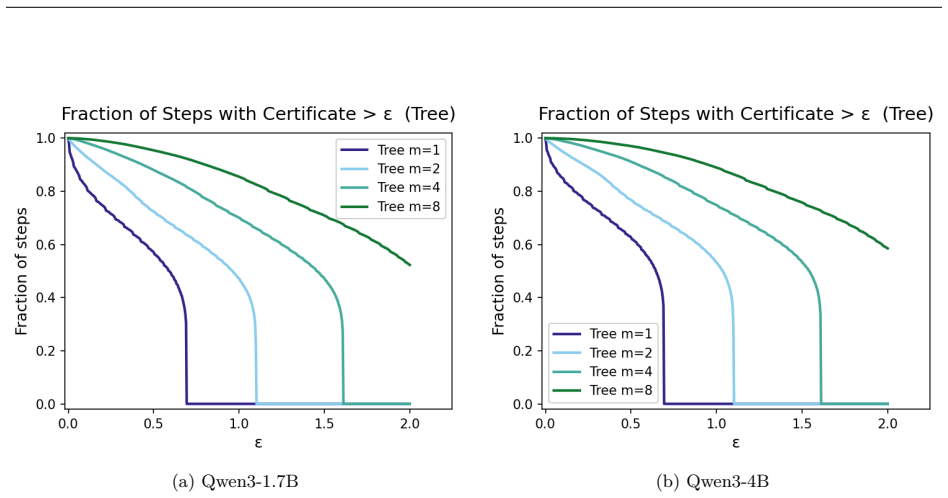
For acceptance criteria whose rejection regions are lower level sets of the target distribution, the exact KL divergence needed to produce rejection can be derived in closed form, supplying exact certificates together with sharp margin-based bounds for strict greedy decoding, additive and multiplicative relaxed acceptance, top-m relaxed criteria, entropy-thresholded acceptance, and greedy tree decoding.
What carries the argument
Lower level sets of the target distribution that characterize the rejection regions of common acceptance criteria.
If this is right
- Exact KL certificates become available for strict greedy decoding.
- Sharp margin bounds apply to additive, multiplicative, top-m, and entropy-thresholded relaxed acceptance.
- Exact and margin-only certificates extend to greedy tree decoding for coverage of the target greedy token.
- Relaxed and tree criteria enlarge the certified acceptance region compared with strict rules, especially at low target margins.
Where Pith is reading between the lines
- Drafter training objectives could be adjusted to maximize the derived margins rather than matching the full target distribution.
- The level-set view may transfer to other local-ranking verification schemes outside speculative decoding.
- Certificate computation could be integrated into runtime monitoring to decide when to fall back to the target model.
Load-bearing premise
The acceptance criteria actually used in systems have rejection regions that are exactly lower level sets of the target distribution.
What would settle it
A direct computation or sampling experiment on a concrete acceptance rule showing that its rejection set is not a lower level set of the target probabilities, or a measured rejection frequency that deviates from the KL-derived prediction.
Figures


read the original abstract
Speculative decoding accelerates language model inference by using a fast drafter to propose candidate tokens that are then verified by a larger target model. Existing theory largely studies the stochastic, distribution-preserving setting, where the goal is to exactly sample from the target distribution. In contrast, many practical systems use greedy decoding, relaxed acceptance rules, or tree-based candidate sets, where success is governed by local ranking and threshold events rather than exact distributional equality. We develop a theory for these regimes. We identify that many common acceptance criteria have rejection regions that can be characterized as lower level sets of the target distribution. For these, we characterize the exact KL divergence required for rejection yielding exact certificates and sharp margin-based bounds for strict greedy decoding, additive and multiplicative relaxed acceptance, top-(m) relaxed criteria, and entropy-thresholded acceptance. We then extend the framework to greedy tree decoding, deriving exact and margin-only certificates for when the target greedy token remains covered by the drafter's top-(m) candidates. Finally, we evaluate the resulting certificates on Qwen3 models, showing that relaxed and tree-based criteria substantially enlarge the region of certified acceptance, especially on decoding steps with low target model distribution margin. These results complement existing distribution-preserving analyses of speculative decoding by characterizing the deterministic local acceptance events common in practical inference systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a theory of acceptance for speculative decoding in deterministic regimes (greedy, relaxed, tree-based) rather than exact distribution-preserving sampling. It claims that common acceptance criteria have rejection regions exactly equal to lower level sets of the target distribution p; from this identification it derives exact KL-divergence certificates for rejection and sharp margin-based bounds for strict greedy decoding, additive/multiplicative relaxed acceptance, top-(m) criteria, entropy-thresholded acceptance, and an extension to greedy tree decoding that certifies when the target greedy token remains covered by the drafter's top-(m) candidates. The certificates are evaluated on Qwen3 models and shown to enlarge the certified-acceptance region, especially at low-margin decoding steps.
Significance. If the level-set identification holds without gaps, the work supplies exact, parameter-free certificates and sharp bounds that directly characterize the local ranking and threshold events used in practical inference systems. This complements existing stochastic analyses by giving deterministic guarantees and could inform the design of acceptance rules that maximize certified throughput. The Qwen3 evaluation provides concrete evidence that relaxed and tree criteria materially expand the certified region relative to strict greedy.
major comments (2)
- [Abstract / identification section] Abstract and § on identification of acceptance criteria: the central premise that rejection regions for greedy, additive/multiplicative relaxed, top-(m), entropy-thresholded, and tree variants are exactly lower level sets of p must be shown explicitly for each criterion (with the precise definition of the level set and the acceptance rule) to confirm there are no post-hoc adjustments or edge cases that break the equality.
- [tree decoding section] § on tree decoding: the exact and margin-only certificates for coverage of the target greedy token by the drafter's top-(m) candidates rely on the level-set property carrying over to the joint tree structure; any deviation in how the tree is constructed (e.g., shared prefixes or non-independent proposals) would require an additional argument that the rejection region remains a level set.
minor comments (2)
- [Abstract] Notation for the target distribution p and drafter q should be introduced once and used consistently; the abstract uses both "target distribution" and "p" without an explicit definition paragraph.
- [evaluation section] The evaluation section would benefit from a table listing, for each criterion, the fraction of steps where the certificate is non-vacuous and the average margin improvement, to make the "substantially enlarge" claim quantitative.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the constructive comments on explicitness. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / identification section] Abstract and § on identification of acceptance criteria: the central premise that rejection regions for greedy, additive/multiplicative relaxed, top-(m), entropy-thresholded, and tree variants are exactly lower level sets of p must be shown explicitly for each criterion (with the precise definition of the level set and the acceptance rule) to confirm there are no post-hoc adjustments or edge cases that break the equality.
Authors: Section 3 already supplies direct proofs for each criterion, defining the lower level set L_τ(p) = {x : p(x) ≤ τ} and showing equality to the rejection region via the acceptance rule. For strict greedy the rejection region is exactly the open lower level set below the mode; for additive relaxed it is the level set below p(target) − α; for multiplicative it is the level set scaled by β; for top-(m) it is the level set below the m-th order statistic; and for entropy-thresholded it is the level set below the entropy-derived τ. The proofs contain no post-hoc adjustments and handle edge cases (ties, zero probabilities) explicitly. To improve readability we will insert a summary table in the revised manuscript that lists, for each criterion, the precise acceptance rule, the corresponding level-set definition, and the theorem reference. revision: yes
-
Referee: [tree decoding section] § on tree decoding: the exact and margin-only certificates for coverage of the target greedy token by the drafter's top-(m) candidates rely on the level-set property carrying over to the joint tree structure; any deviation in how the tree is constructed (e.g., shared prefixes or non-independent proposals) would require an additional argument that the rejection region remains a level set.
Authors: The level-set identification is applied token-wise: each candidate in the tree is accepted or rejected according to the same per-token rule used in the non-tree case. Because the acceptance predicate depends only on the probability of the token being verified (not on path dependence or prefix sharing), the rejection region for every verification step remains exactly a lower level set of p. The tree certificates are obtained by requiring that every competing branch is rejected under this per-token rule; the joint structure therefore inherits the level-set property without modification. The manuscript already states this token-wise invariance in the tree section, so no further argument is required. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper's derivation begins by identifying that listed acceptance criteria (greedy, additive/multiplicative relaxed, top-m, entropy-thresholded, tree variants) have rejection regions exactly equal to lower level sets of the target distribution p; once this property holds, standard level-set arguments on KL divergence produce the exact certificates and margin bounds. This identification is a direct claim about the structure of the criteria themselves rather than a reduction to fitted parameters, self-citations, or ansatzes imported from prior work. No equations or load-bearing steps in the provided abstract reduce the claimed results to the inputs by construction, and the framework is presented as self-contained once the level-set characterization is granted. The evaluation on Qwen3 models is empirical validation, not part of the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Su, Qidong and Giannoula, Christina and Pekhimenko, Gennady , year =. The. doi:10.48550/ARXIV.2310.18813 , abstract =
-
[2]
Yang, Sen and Huang, Shujian and Dai, Xinyu and Chen, Jiajun , year =. Multi-. doi:10.48550/ARXIV.2401.06706 , abstract =
-
[3]
DFlash: Block Diffusion for Flash Speculative Decoding
Chen, Jian and Liang, Yesheng and Liu, Zhijian , year =. doi:10.48550/ARXIV.2602.06036 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.06036
-
[4]
PARD-2: Target-Aligned Parallel Draft Model for Dual-Mode Speculative Decoding
An, Zihao and Liu, Taichi and Liu, Ziqiong and Li, Dong and Liu, Ruofeng and Barsoum, Emad , year =. doi:10.48550/ARXIV.2605.08632 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.08632
-
[5]
Accelerating Large Language Model Decoding with Speculative Sampling
Chen, Charlie and Borgeaud, Sebastian and Irving, Geoffrey and Lespiau, Jean-Baptiste and Sifre, Laurent and Jumper, John , year =. Accelerating. doi:10.48550/ARXIV.2302.01318 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.01318
-
[6]
Miao, Xupeng and Oliaro, Gabriele and Zhang, Zhihao and Cheng, Xinhao and Wang, Zeyu and Zhang, Zhengxin and Wong, Rae Ying Yee and Zhu, Alan and Yang, Lijie and Shi, Xiaoxiang and Shi, Chunan and Chen, Zhuoming and Arfeen, Daiyaan and Abhyankar, Reyna and Jia, Zhihao , month = apr, year =. Proceedings of the 29th. doi:10.1145/3620666.3651335 , language =
-
[7]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , year =. Proceedings of the 2024. doi:10.18653/v1/2024.emnlp-main.422 , language =
-
[8]
Wertheimer, Davis and Rosenkranz, Joshua and Parnell, Thomas and Suneja, Sahil and Ranganathan, Pavithra and Ganti, Raghu and Srivatsa, Mudhakar , year =. Accelerating. doi:10.48550/ARXIV.2404.19124 , abstract =
-
[11]
Zhong, Meiyu and Teku, Noel and Tandon, Ravi , year =. Speeding up. doi:10.48550/ARXIV.2502.04557 , abstract =
-
[12]
MARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification
Song, Jingwei and Wang, Xinyu and Wang, Hanbin and Lei, Xiaoxuan and Shi, Bill and Han, Shixin and Yang, Eric and Chang, Xiao-Wen and Ai, Lynn , year =. doi:10.48550/ARXIV.2601.15498 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.15498
-
[13]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Leviathan, Yaniv and Kalman, Matan and Matias, Yossi , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[14]
Workshop on Efficient Systems for Foundation Models II @ ICML2024 , year=
Block Verification Accelerates Speculative Decoding , author=. Workshop on Efficient Systems for Foundation Models II @ ICML2024 , year=
-
[15]
and Chen, Deming and Dao, Tri , title =
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[16]
Recursive Speculative Decoding: Accelerating
Wonseok Jeon and Mukul Gagrani and Raghavv Goel and Junyoung Park and Mingu Lee and Christopher Lott , booktitle=. Recursive Speculative Decoding: Accelerating. 2024 , url=
2024
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Learning Harmonized Representations for Speculative Sampling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
Draft& verify: Lossless large language model acceleration via self-speculative decoding
Zhang, Jun and Wang, Jue and Li, Huan and Shou, Lidan and Chen, Ke and Chen, Gang and Mehrotra, Sharad. Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.607
-
[19]
Kangaroo: Lossless Self-Speculative Decoding for Accelerating
Fangcheng Liu and Yehui Tang and Zhenhua Liu and Yunsheng Ni and Duyu Tang and Kai Han and Yunhe Wang , booktitle=. Kangaroo: Lossless Self-Speculative Decoding for Accelerating. 2024 , url=
2024
-
[20]
2026 , url=
Yuhui Li and Fangyun Wei and Chao Zhang and Hongyang Zhang , booktitle=. 2026 , url=
2026
-
[21]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Sequoia: Scalable and Robust Speculative Decoding , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[22]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[23]
First Conference on Language Modeling , year=
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding , author=. First Conference on Language Modeling , year=
-
[24]
Thirty-seventh Conference on Neural Information Processing Systems , year=
SpecTr: Fast Speculative Decoding via Optimal Transport , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[25]
NeurIPS 2023 Workshop Optimal Transport and Machine Learning , year=
SpecTr++: Improved transport plans for speculative decoding of large language models , author=. NeurIPS 2023 Workshop Optimal Transport and Machine Learning , year=
2023
-
[26]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
A Theoretical Perspective for Speculative Decoding Algorithm , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[27]
Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages =
Stern, Mitchell and Shazeer, Noam and Uszkoreit, Jakob , title =. Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages =. 2018 , publisher =
2018
-
[28]
2026 , url=
Zihao An and Huajun Bai and Ziqiong Liu and Dong Li and Emad Barsoum , booktitle=. 2026 , url=
2026
-
[29]
Gonzalez and Clark Barrett and Ying Sheng , booktitle=
Lianmin Zheng and Liangsheng Yin and Zhiqiang Xie and Chuyue Sun and Jeff Huang and Cody Hao Yu and Shiyi Cao and Christos Kozyrakis and Ion Stoica and Joseph E. Gonzalez and Clark Barrett and Ying Sheng , booktitle=. 2024 , url=
2024
-
[30]
Fuzzy Speculative Decoding for a Tunable Accuracy-Runtime Tradeoff
Holsman, Maximilian and Huang, Yukun and Dhingra, Bhuwan. Fuzzy Speculative Decoding for a Tunable Accuracy-Runtime Tradeoff. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1346
-
[31]
Alignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
Wang, Jikai and Tian, Zhenxu and Li, Juntao and Xia, Qingrong and Duan, Xinyu and Wang, Zhefeng and Huai, Baoxing and Zhang, Min. Alignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.343
-
[32]
2025 , eprint=
Speeding up Speculative Decoding via Sequential Approximate Verification , author=. 2025 , eprint=
2025
-
[33]
2026 , eprint=
MARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification , author=. 2026 , eprint=
2026
-
[34]
2026 , eprint=
Attention Drift: What Autoregressive Speculative Decoding Models Learn , author=. 2026 , eprint=
2026
-
[35]
2021 , eprint=
The Lipschitz Constant of Self-Attention , author=. 2021 , eprint=
2021
-
[36]
Federer, Herbert and Eckmann, B. and Waerden, B. L. , year =. Geometric. doi:10.1007/978-3-642-62010-2 , abstract =
-
[37]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[38]
2023 , eprint=
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.