Extrapolating from Regularised Solutions for Solving Ill-Conditioned Linear Systems in Machine Learning
Pith reviewed 2026-06-30 03:56 UTC · model grok-4.3
The pith
Richardson extrapolation on multiple Tikhonov-regularized solutions solves ill-conditioned linear systems more accurately than any single nugget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that autonugget recovers the solution of an ill-conditioned linear system by combining multiple Tikhonov-regularized solves through Richardson extrapolation, yielding higher accuracy than any single-nugget approximation while remaining stable under automatic differentiation.
What carries the argument
autonugget, which performs Richardson extrapolation across Tikhonov-regularized solutions obtained with a sequence of nugget values.
Load-bearing premise
Richardson extrapolation applied to a sequence of Tikhonov-regularized solutions will converge to a more accurate solution of the original ill-conditioned system than any single regularized solve, and that this holds stably under automatic differentiation.
What would settle it
Solve a known ill-conditioned system whose exact solution is available, compute both the single-nugget approximations and the extrapolated result, and check whether the extrapolated error is smaller for every tested matrix and nugget sequence.
Figures


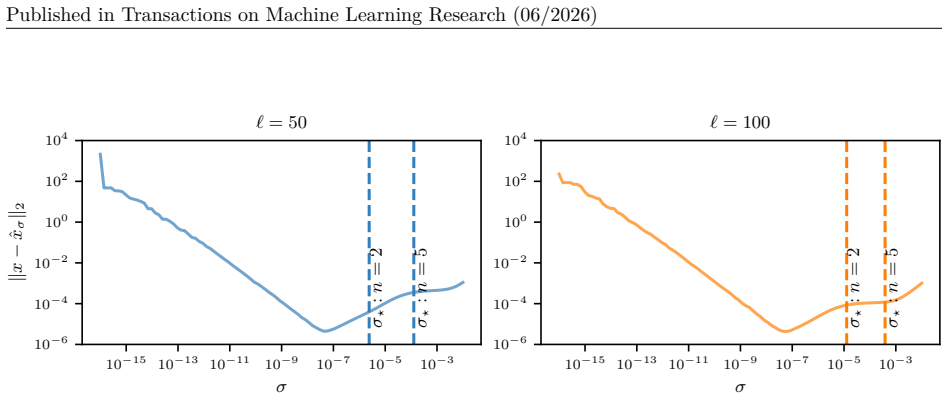
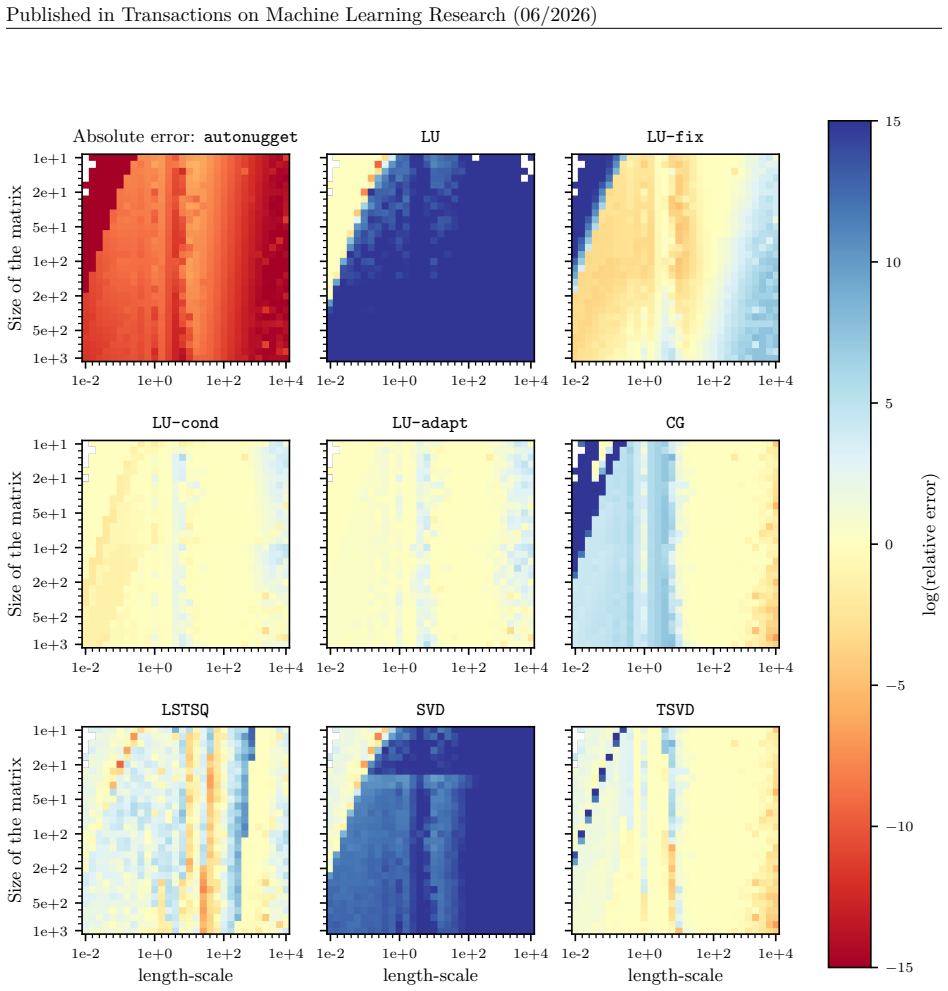



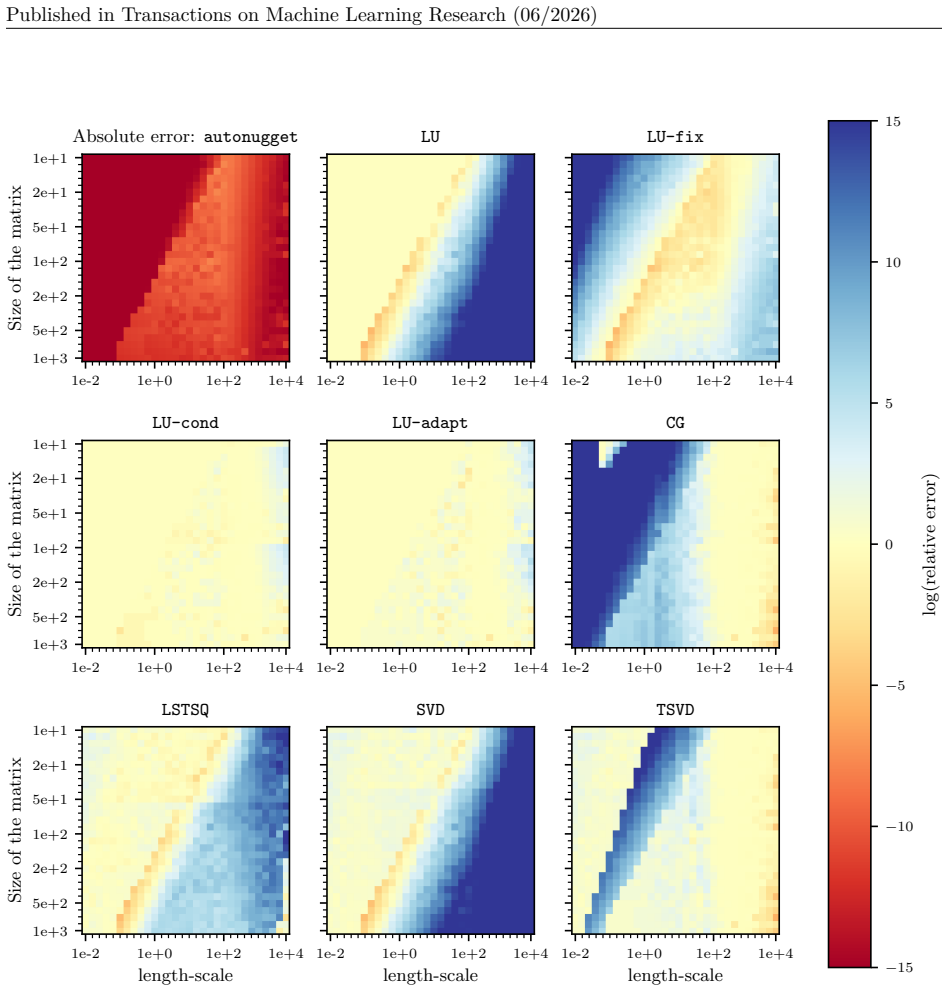


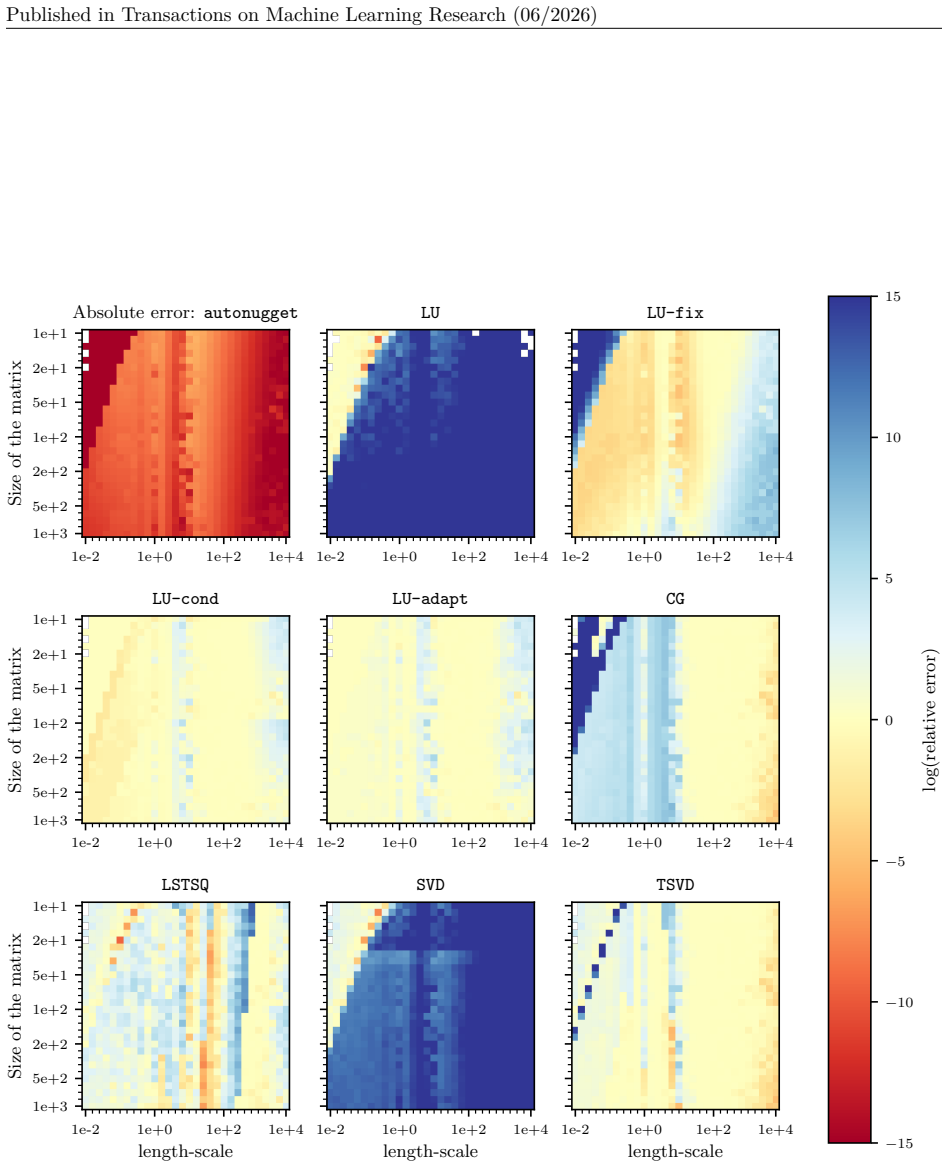



read the original abstract
Rapid prototyping of algorithms is a critical step in modern machine learning. Most algorithms exploit linear algebra, creating a need for lightweight numerical routines which -- while potentially sub-optimal for the task at hand -- can be rapidly implemented. For the numerical solution of ill-conditioned linear systems of equations, the standard solution for prototyping is Tikhonov-regularised inversion using a nugget. However, selection of the size of nugget is often difficult, and the use of data-adaptive procedures precludes automatic differentiation, introducing instabilities into end-to-end training. Further, while data-adaptive procedures perform multiple linear solves to select the size of nugget, only the result of one such solve is returned, which we argue is wasteful. This paper aims to circumvent the above difficulties, presenting autonugget; a Python package for automatic and stable numerical solution of linear systems suitable for rapid prototyping, and fully compatible with automatic differentiation using JAX. autonugget combines multiple linear solves using Richardson extrapolation to determine the solution of the ill-conditioned system, improving in accuracy over approximations based on a single nugget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents autonugget, a Python package for solving ill-conditioned linear systems in machine learning prototyping. It uses Richardson extrapolation on multiple Tikhonov-regularized solutions (with varying nugget sizes) to obtain the solution, claiming improved accuracy over any single regularized solve, while remaining stable and compatible with automatic differentiation in JAX without requiring data-adaptive nugget selection.
Significance. If the claimed accuracy improvement holds and the method remains stable under AD for typical ML linear systems, autonugget could provide a practical, lightweight alternative to manual regularization tuning for rapid algorithm prototyping. The approach avoids wasting computation on multiple solves used only for parameter selection and integrates directly with differentiable pipelines.
major comments (2)
- [Abstract] Abstract: The central claim that Richardson extrapolation on the sequence of Tikhonov solutions x_λ improves accuracy over the best single-λ solve is load-bearing but unsupported. No equations, error analysis, or conditions are supplied showing that the map λ ↦ x_λ admits an asymptotic expansion x_λ = x* + c₁λ + c₂λ² + … whose leading terms can be cancelled. For general ill-conditioned A the bias is governed by singular-value decay and the projection of b, so the effective order is not uniform in λ.
- [Abstract] Abstract: The stability claim under automatic differentiation is asserted without any description of the implementation (how the multiple solves and extrapolation are coded in JAX) or verification that the extrapolated result remains differentiable and closer to the minimum-norm solution than a single solve.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We respond point-by-point to the major comments and will make the indicated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Richardson extrapolation on the sequence of Tikhonov solutions x_λ improves accuracy over the best single-λ solve is load-bearing but unsupported. No equations, error analysis, or conditions are supplied showing that the map λ ↦ x_λ admits an asymptotic expansion x_λ = x* + c₁λ + c₂λ² + … whose leading terms can be cancelled. For general ill-conditioned A the bias is governed by singular-value decay and the projection of b, so the effective order is not uniform in λ.
Authors: We agree that the abstract would be strengthened by an explicit reference to the asymptotic expansion. The approach applies standard Richardson extrapolation to the bias term of Tikhonov regularization, which admits an expansion in powers of λ for sufficiently small λ when the right-hand side has a suitable projection onto the singular vectors. We will revise the abstract to include a brief statement of the expansion and add a short paragraph in the methods section that states the conditions (in terms of singular-value decay) under which the leading terms cancel, while acknowledging that the effective order is not uniform for arbitrary ill-conditioned operators. revision: yes
-
Referee: [Abstract] Abstract: The stability claim under automatic differentiation is asserted without any description of the implementation (how the multiple solves and extrapolation are coded in JAX) or verification that the extrapolated result remains differentiable and closer to the minimum-norm solution than a single solve.
Authors: We accept that the current abstract lacks implementation details and verification. The package implements the procedure by vmapping JAX's linear_solve over a fixed sequence of nugget values and then forming a linear combination of the resulting vectors; because each solve is differentiable and the combination is a fixed linear map, the overall map remains differentiable. We will add a dedicated implementation subsection describing the JAX code and include numerical checks confirming that the gradient through the extrapolated solution is stable and that the result is closer to the minimum-norm solution than any individual regularized solve on the reported examples. revision: yes
Circularity Check
No circularity detected; method is a direct numerical procedure
full rationale
The paper presents autonugget as a numerical routine that applies Richardson extrapolation to a sequence of Tikhonov-regularized solves. No equations, derivations, or self-citations are exhibited that reduce the claimed accuracy improvement to a fitted parameter, self-definition, or prior result by the same authors. The central claim rests on the numerical behavior of the extrapolation operator applied to the regularized map, which is independent of any input that is itself defined in terms of the output. This is the most common honest finding for a methods paper whose contribution is algorithmic rather than deductive.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Richardson extrapolation applied to a sequence of Tikhonov-regularized solutions recovers an accurate solution to the original ill-conditioned system
Reference graph
Works this paper leans on
-
[1]
Learning the optimal T ikhonov regularizer for inverse problems
Giovanni S Alberti, Ernesto De Vito, Matti Lassas, Luca Ratti, and Matteo Santacesaria. Learning the optimal T ikhonov regularizer for inverse problems. Advances in Neural Information Processing Systems, 34: 0 25205--25216, 2021
2021
-
[2]
The effect of the nugget on G aussian process emulators of computer models
Ioannis Andrianakis and Peter G Challenor. The effect of the nugget on G aussian process emulators of computer models. Computational Statistics & Data Analysis, 56 0 (12): 0 4215--4228, 2012
2012
-
[3]
On the effectiveness of R ichardson extrapolation in data science
Francis Bach. On the effectiveness of R ichardson extrapolation in data science. SIAM Journal on Mathematics of Data Science, 3 0 (4): 0 1251--1277, 2021
2021
-
[4]
JAX : C omposable transformations of P ython+ N um P y programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake Vander P las, Skye Wanderman- M ilne, and Qiao Zhang. JAX : C omposable transformations of P ython+ N um P y programs, 2018. URL http://github.com/jax-ml/jax
2018
-
[5]
Sparse C holesky factorization for solving nonlinear PDE s via G aussian processes
Yifan Chen, Houman Owhadi, and Florian Sch \"a fer. Sparse C holesky factorization for solving nonlinear PDE s via G aussian processes. Mathematics of Computation, 94 0 (353): 0 1235--1280, 2025
2025
-
[6]
Learning regularization parameters for general-form T ikhonov
Julianne Chung and Malena I Espa \ n ol. Learning regularization parameters for general-form T ikhonov. Inverse Problems, 33 0 (7): 0 074004, 2017
2017
-
[7]
Preconditioning kernel matrices
Kurt Cutajar, Michael Osborne, John Cunningham, and Maurizio Filippone. Preconditioning kernel matrices. In International Conference on Machine Learning, pages 2529--2538. PMLR, 2016
2016
-
[8]
A machine learning approach to optimal T ikhonov regularization I : A ffine manifolds
Ernesto De Vito, Massimo Fornasier, and Valeriya Naumova. A machine learning approach to optimal T ikhonov regularization I : A ffine manifolds. Analysis and Applications, 20 0 (02): 0 353--400, 2022
2022
-
[9]
Computing eigenvalues and singular values to high relative accuracy
Zlatko Drma c . Computing eigenvalues and singular values to high relative accuracy. In Handbook of Linear Algebra, pages 46--1. Chapman and Hall/CRC, 2006
2006
-
[10]
On the choice of the regularization parameter for iterated T ikhonov regularization of ill-posed problems
Heinz W Engl. On the choice of the regularization parameter for iterated T ikhonov regularization of ill-posed problems. Journal of Approximation Theory, 49 0 (1): 0 55--63, 1987
1987
-
[11]
Bayesian Optimization
Roman Garnett. Bayesian Optimization . Cambridge University Press, 2023
2023
-
[12]
On K rylov projection methods and T ikhonov regularization
Silvia Gazzola, Paolo Novati, Maria Rosaria Russo, et al. On K rylov projection methods and T ikhonov regularization. Electronic Transactions on Numerical Analysis, 44 0 (1): 0 83--123, 2015
2015
-
[13]
An a posteriori parameter choice for ordinary and iterated T ikhonov regularization of ill-posed problems leading to optimal convergence rates
Helmut Gfrerer. An a posteriori parameter choice for ordinary and iterated T ikhonov regularization of ill-posed problems leading to optimal convergence rates. Mathematics of Computation, 49 0 (180): 0 507--522, 1987
1987
-
[14]
Robert B. Gramacy. Surrogates: Gaussian Process Modeling , Design , and Optimization for the Applied Sciences . Chapman and Hall/CRC, New York, March 2020. ISBN 978-0-367-81549-3. doi:10.1201/9780367815493
-
[15]
Extrapolation and the method of regularization for generalized inverses
CW Groetsch and JT King. Extrapolation and the method of regularization for generalized inverses. Journal of Approximation Theory, 25 0 (3): 0 233--247, 1979
1979
-
[16]
Harris, K
Charles R. Harris, K. Jarrod Millman, St \' e fan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fern \' a ndez del R \' i o, Mark Wiebe, Pearu Peterson, Pierre G \' e rard-M...
2020
-
[17]
Philipp Hennig, Michael A. Osborne, and Hans P. Kersting. Probabilistic Numerics: Computation as Machine Learning. Cambridge University Press, Cambridge, 2022. ISBN 978-1-107-16344-7. doi:10.1017/9781316681411
-
[18]
Methods of conjugate gradients for solving linear systems
Magnus R Hestenes, Eduard Stiefel, et al. Methods of conjugate gradients for solving linear systems. Journal of Research of the National Bureau of Standards, 49 0 (6): 0 409--436, 1952
1952
-
[19]
Splines and PDE s: F rom approximation theory to numerical linear algebra
Angela Kunoth, Tom Lyche, Giancarlo Sangalli, Stefano Serra-Capizzano, Carla Manni, and Hendrik Speleers. Splines and PDE s: F rom approximation theory to numerical linear algebra . Springer, 2018
2018
-
[20]
The Splitting Extrapolation Method: A New Technique In Numerical Solution Of Multidimensional Problems
Chin Bo Liem and Tsimin Shih. The Splitting Extrapolation Method: A New Technique In Numerical Solution Of Multidimensional Problems . World Scientific, 1995
1995
-
[21]
Improving linear system solvers for hyperparameter optimisation in iterative G aussian processes
Jihao Andreas Lin, Shreyas Padhy, Bruno Mlodozeniec, Javier Antor \'a n, and Jos \'e Miguel Hern \'a ndez-Lobato. Improving linear system solvers for hyperparameter optimisation in iterative G aussian processes. Advances in Neural Information Processing Systems, 37: 0 15460--15496, 2024
2024
-
[22]
A dynamical T ikhonov regularization for solving ill-posed linear algebraic systems
Chein-Shan Liu. A dynamical T ikhonov regularization for solving ill-posed linear algebraic systems. Acta Applicandae Mathematicae, 123 0 (1): 0 285--307, 2013
2013
-
[23]
Preconditioning discretizations of systems of partial differential equations
Kent-Andre Mardal and Ragnar Winther. Preconditioning discretizations of systems of partial differential equations. Numerical Linear Algebra with Applications, 18 0 (1): 0 1--40, 2011
2011
-
[24]
Jorge Nocedal and Stephen J. Wright. Numerical Optimization. Springer, 2nd edition, 2006
2006
-
[25]
Probabilistic R ichardson extrapolation
Chris J Oates, Toni Karvonen, Aretha L Teckentrup, Marina Strocchi, and Steven A Niederer. Probabilistic R ichardson extrapolation. Journal of the Royal Statistical Society Series B: Statistical Methodology, 87 0 (2): 0 457--479, 2025
2025
-
[26]
Gaussian Processes for Machine Learning
Carl Edward Rasmussen and Christopher KI Williams. Gaussian Processes for Machine Learning. MIT Press Cambridge, MA, 2006
2006
-
[27]
The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam
Lewis Fry Richardson. The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam. Philosophical Transactions of the Royal Society of London, Series A, 210 0 (459-470): 0 307--357, 1911
1911
-
[28]
FALKON : A n optimal large scale kernel method
Alessandro Rudi, Luigi Carratino, and Lorenzo Rosasco. FALKON : A n optimal large scale kernel method. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[29]
Scaled conjugate gradient method for nonconvex optimization in deep neural networks
Naoki Sato, Koshiro Izumi, and Hideaki Iiduka. Scaled conjugate gradient method for nonconvex optimization in deep neural networks. Journal of Machine Learning Research, 25 0 (395): 0 1--37, 2024
2024
-
[30]
Compression, inversion, and approximate PCA of dense kernel matrices at near-linear computational complexity
Florian Schafer, Timothy John Sullivan, and Houman Owhadi. Compression, inversion, and approximate PCA of dense kernel matrices at near-linear computational complexity. Multiscale Modeling & Simulation, 19 0 (2): 0 688--730, 2021
2021
-
[31]
Approximation of generalized inverses by iterated regularization
J Thomas King and David Chillingworth. Approximation of generalized inverses by iterated regularization. Numerical Functional Analysis and Optimization, 1 0 (5): 0 499--513, 1979
1979
-
[32]
Numerical Linear Algebra
Lloyd N Trefethen and David Bau. Numerical Linear Algebra. SIAM, 2022
2022
-
[33]
Average condition number for solving linear equations
N Weiss, GW Wasilkowski, H Wo \'z niakowski, and M Shub. Average condition number for solving linear equations. Linear Algebra and Its Applications, 83: 0 79--102, 1986
1986
-
[34]
Accurate inverses for computing eigenvalues of extremely ill-conditioned matrices and differential operators
Qiang Ye. Accurate inverses for computing eigenvalues of extremely ill-conditioned matrices and differential operators. Mathematics of Computation, 87 0 (309): 0 237--259, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.