Beyond IID: How General Are Tabular Foundation Models, Really?
Pith reviewed 2026-06-30 06:56 UTC · model grok-4.3
The pith
Tabular foundation models excel only on tiny to medium IID data while traditional models dominate non-IID, large, and high-dimensional cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
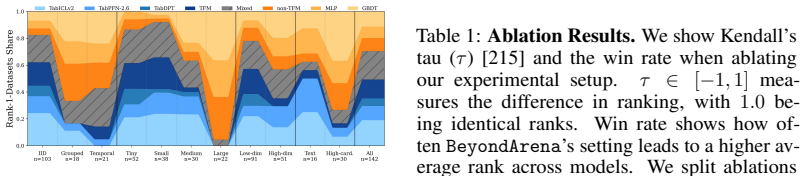
The paper establishes that existing tabular foundation models excel on tiny- to medium-sized IID data, while traditional tree-based and deep learning models still dominate on non-IID, large, and high-dimensional datasets, as shown by results from a new benchmark that unifies evaluation across task types, scales, and disciplines previously handled in fragmented ways.
What carries the argument
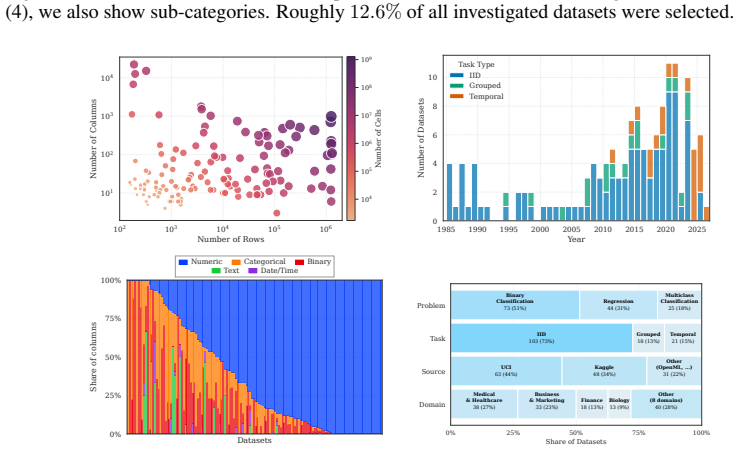
BeyondArena, a unified benchmark and associated curation framework that supports IID, temporal, and grouped tasks across sample-size and dimensionality scales plus diverse feature types.
If this is right
- Model development should shift focus from marginal gains on IID data toward handling non-IID, temporal, grouped, and high-dimensional regimes.
- Fragmented task-specific evaluations can be replaced by a single framework that enables direct comparison across previously inaccessible scenarios.
- Truly general tabular foundation models will require explicit progress on the dataset regimes where current foundation models underperform.
- The curation approach allows incorporation of additional datasets from new disciplines without breaking evaluation consistency.
Where Pith is reading between the lines
- Architectures that embed explicit handling of temporal or grouping structure may close the observed gap with traditional methods.
- The performance pattern suggests that current foundation-model pretraining objectives may lack the inductive biases needed for non-stationary or clustered tabular distributions.
- Extending the benchmark to even higher-dimensional or streaming data would test whether the dominance pattern persists at larger scales.
Load-bearing premise
The one hundred forty two curated datasets and the supported task types sufficiently represent the most challenging scenarios for tabular data that standard benchmarks exclude.
What would settle it
Observation of a tabular foundation model that outperforms traditional models on a large non-IID tabular dataset drawn from outside the one hundred forty two evaluated collections would falsify the reported performance gap.
Figures




read the original abstract
Foundation models for predictive machine learning on tabular data have recently gained significant traction in academia and industry. Research communities across disciplines are increasingly evaluating tabular foundation models on diverse datasets and tasks. However, these task- and discipline-specific evaluations remain largely inaccessible to model researchers because benchmark software and evaluation protocols are fragmented. As a result, model researchers rely on standard benchmarks, which are mostly defined for tasks where tabular foundation models already excel. The most challenging scenarios are excluded, limiting meaningful progress in the field by focusing on marginal improvements on IID data rather than on broader, more demanding challenges. To overcome this, we introduce BeyondArena, the first unified holistic benchmark for tabular data that supports diverse task types (IID, temporal, grouped), across sample size and feature dimensionality scales, with diverse feature types (with text, with high cardinality) from a broad range of disciplines. To enable unified benchmarking beyond standard benchmarks, we introduce Data Foundry, a Python framework and metadata schema for curating tabular datasets for predictive machine learning. Our results across 11 models and 142 curated datasets show that existing tabular foundation models excel on tiny- to medium-sized IID data, while traditional tree-based and deep learning models still dominate on non-IID, large, and high-dimensional datasets. BeyondArena guides model research for the most demanding challenges in tabular data, enabling progress towards truly foundational tabular models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Data Foundry, a Python framework and metadata schema for curating tabular datasets, and BeyondArena, the first unified holistic benchmark supporting diverse task types (IID, temporal, grouped), sample/feature scales, and feature types (including text and high-cardinality) from multiple disciplines. Evaluations of 11 models on 142 curated datasets support the central claim that tabular foundation models excel on tiny- to medium-sized IID data while traditional tree-based and deep learning models dominate on non-IID, large, and high-dimensional datasets.
Significance. If the empirical patterns hold under the reported curation, this work is significant for shifting tabular foundation model research away from marginal gains on IID-heavy standard benchmarks toward more demanding scenarios. The curation framework and benchmark directly target fragmentation and selection bias in existing evaluations, providing a reproducible resource that could guide development of more general models.
major comments (2)
- [Data curation and selection] Data selection and curation section: the claim that the 142 datasets sufficiently represent the most challenging non-IID scenarios excluded from standard benchmarks requires explicit selection criteria, inclusion/exclusion rules, and coverage statistics; without these, the headline pattern cannot be fully assessed for representativeness.
- [Results] Results section (comparisons across 11 models and 142 datasets): performance differences are reported without error bars, confidence intervals, or statistical tests for variability across dataset splits or random seeds, which is load-bearing for claims of dominance on non-IID/large/high-dimensional regimes.
minor comments (2)
- [Results] Define quantitative thresholds for 'tiny- to medium-sized' (e.g., sample count ranges) when presenting the scale-based breakdowns.
- [Abstract and Results] The abstract lists supported feature types (text, high cardinality) but the results could include an explicit breakdown or ablation by feature type to strengthen the generality claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [Data curation and selection] Data selection and curation section: the claim that the 142 datasets sufficiently represent the most challenging non-IID scenarios excluded from standard benchmarks requires explicit selection criteria, inclusion/exclusion rules, and coverage statistics; without these, the headline pattern cannot be fully assessed for representativeness.
Authors: We concur that explicit selection criteria and coverage details are necessary to substantiate the representativeness claim. Although the manuscript outlines the use of Data Foundry for curation from multiple disciplines and task types, we will revise the Data curation and selection section to include precise inclusion/exclusion rules (e.g., datasets must have at least one non-IID characteristic or be from underrepresented domains), and provide statistics on the proportion of datasets in each category (IID vs. non-IID, size bins, dimensionality bins, feature types). This addition will be made in the next version of the manuscript. revision: yes
-
Referee: [Results] Results section (comparisons across 11 models and 142 datasets): performance differences are reported without error bars, confidence intervals, or statistical tests for variability across dataset splits or random seeds, which is load-bearing for claims of dominance on non-IID/large/high-dimensional regimes.
Authors: We acknowledge that the absence of error bars and statistical tests limits the strength of the dominance claims. To address this, we will update the Results section to include confidence intervals or standard deviations where multiple runs are performed, and apply appropriate statistical tests (e.g., Friedman test followed by post-hoc analysis) across the aggregated results for different regimes. Given the scale of the benchmark, we will focus on reporting these for the main model class comparisons rather than every individual dataset-model pair. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper's central claim—that tabular foundation models excel on tiny- to medium-sized IID data while tree-based and deep learning models dominate on non-IID, large, and high-dimensional datasets—is an empirical result obtained by evaluating 11 models across 142 curated datasets in the newly introduced BeyondArena benchmark. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the reported patterns are direct comparisons against external models on held-out task types and scales. The introduction of Data Foundry and BeyondArena is a tooling contribution whose value is assessed by the external benchmark outcomes rather than by internal redefinition. This is a standard self-contained empirical benchmark paper with no detectable circularity in its derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected 142 datasets from a broad range of disciplines adequately capture the challenging non-IID, large, and high-dimensional scenarios.
Reference graph
Works this paper leans on
-
[1]
Jeongwhan Choi, Woosung Kang, Minseo Kim, Jongwoo Kim, and Noseong Park. Can tabpfn compete with gnns for node classification via graph tabularization?arXiv preprint arXiv:2512.08798, 2025
-
[2]
Turning Tabular Foundation Models into Graph Foundation Models
Dmitry Eremeev, Gleb Bazhenov, Oleg Platonov, Artem Babenko, and Liudmila Prokhorenkova. Turning tabular foundation models into graph foundation models.arXiv preprint arXiv:2508.20906, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Adrian Hayler, Xingyue Huang, Ismail Ilkan Ceylan, Michael Bronstein, and Ben Finkelshtein. Bringing graphs to the table: Zero-shot node classification via tabular foundation models. arXiv preprint arXiv:2509.07143, 2025
-
[4]
Tianyin Liao, Chunyu Hu, Yicheng Sui, Xingxuan Zhang, Peng Cui, Jianxin Li, and Zi- wei Zhang. Tfmlinker: Universal link predictor by graph in-context learning with tabular foundation models.arXiv preprint arXiv:2602.08592, 2026
-
[5]
Rosen Ting-Ying Yu, Cyril Picard, and Faez Ahmed. Git-bo: High-dimensional bayesian optimization with tabular foundation models.arXiv preprint arXiv:2505.20685, 2025
-
[6]
Meta-black-box optimization with bi-space landscape analysis and dual-control mechanism for saea
Yukun Du, Haiyue Yu, Xiaotong Xie, Yan Zheng, Lixin Zhan, Yudong Du, Chongshuang Hu, Boxuan Wang, and Jiang Jiang. Meta-black-box optimization with bi-space landscape analysis and dual-control mechanism for saea. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 36891–36899, 2026
2026
-
[7]
Foundation-model surrogates enable data-efficient active learning for materials discovery, 2026
Jeffrey Hu, Rongzhi Dong, Ying Feng, Ming Hu, and Jianjun Hu. Foundation-model surrogates enable data-efficient active learning for materials discovery, 2026
2026
-
[8]
Foundation models for cybersecurity: A comprehensive multi-modal evaluation of tabpfn and tabicl for tabular intrusion detection.Electronics, 14(19):3792, 2025
Pablo García, J de Curtò, I de Zarzà, Juan Carlos Cano, and Carlos T Calafate. Foundation models for cybersecurity: A comprehensive multi-modal evaluation of tabpfn and tabicl for tabular intrusion detection.Electronics, 14(19):3792, 2025
2025
-
[9]
Modern neural networks for small tabular datasets: The new default for field-scale digital soil mapping? European Journal of Soil Science, 77(2):e70299, 2026
Viacheslav Barkov, Jonas Schmidinger, Robin Gebbers, and Martin Atzmueller. Modern neural networks for small tabular datasets: The new default for field-scale digital soil mapping? European Journal of Soil Science, 77(2):e70299, 2026
2026
-
[10]
Established machine learning matches tabular foundation models in clinical predictions.medRxiv, pages 2026–02, 2026
Lawrence A Shaktah, Marco Gustav, Tim Lenz, Junhao Liang, Lars Hilgers, Zunamys I Carrero, and Jakob Nikolas Kather. Established machine learning matches tabular foundation models in clinical predictions.medRxiv, pages 2026–02, 2026
2026
-
[11]
Tabarena: A living benchmark for machine learning on tabular data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[12]
Talent: A tabular analytics and learning toolbox.arXiv preprint arXiv:2407.04057, 2024
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and Han-Jia Ye. Talent: A tabular analytics and learning toolbox.arXiv preprint arXiv:2407.04057, 2024
-
[13]
Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, et al. Limix: Unleashing structured-data modeling capability for generalist intelligence.arXiv preprint arXiv:2509.03505, 2025
-
[14]
Pmlbmini: A tabular classification bench- mark suite for data-scarce applications
Ricardo Knauer, Marvin Grimm, and Erik Rodner. Pmlbmini: A tabular classification bench- mark suite for data-scarce applications. InAutoML Conference 2024 (ABCD Track), 2024
2024
-
[15]
Ivan Rubachev, Nikolay Kartashev, Yury Gorishniy, and Artem Babenko. Tabred: Ana- lyzing pitfalls and filling the gaps in tabular deep learning benchmarks.arXiv preprint arXiv:2406.19380, 2024
-
[16]
arXiv preprint arXiv:2507.07829 , year=
Martin Mráz, Breenda Das, Anshul Gupta, Lennart Purucker, and Frank Hutter. Towards benchmarking foundation models for tabular data with text.arXiv preprint arXiv:2507.07829, 2025
-
[17]
A closer look at tabpfn v2: Strength, limitation, and extension
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Chao. A closer look at tabpfn v2: Strength, limitation, and extension.arXiv preprint arXiv:2502.17361, 2025
-
[18]
Comparing task-agnostic embedding models for tabular data.arXiv preprint arXiv:2511.14276, 2026
Frederik Hoppe, Lars Kleinemeier, Astrid Franz, and Udo Göbel. Comparing task-agnostic embedding models for tabular data.arXiv preprint arXiv:2511.14276, 2026
-
[19]
Realistic evaluation of tabpfn v2 in open environments.arXiv preprint arXiv:2505.16226, 2025
Zi-Jian Cheng, Zi-Yi Jia, Zhi Zhou, Yu-Feng Li, and Lan-Zhe Guo. Realistic evaluation of tabpfn v2 in open environments.arXiv preprint arXiv:2505.16226, 2025
-
[20]
Do foundation models learn fair representations? a critical evaluation of tabpfn on algorithmic fairness benchmarks.TRUST-AI: The European Workshop on Trustworthy AI., 2025
Sam Schiffman. Do foundation models learn fair representations? a critical evaluation of tabpfn on algorithmic fairness benchmarks.TRUST-AI: The European Workshop on Trustworthy AI., 2025
2025
-
[21]
The tabular foundation model tabpfn outperforms specialized time series forecasting models based on simple features
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. The tabular foundation model tabpfn outperforms specialized time series forecasting models based on simple features. In NeurIPS 2024 Third Table Representation Learning Workshop, 2024. 11
2024
-
[22]
No Need to Train Your RDB Foundation Model
Linjie Xu, Yanlin Zhang, Quan Gan, Minjie Wang, and David Wipf. No need to train your rdb foundation model.arXiv preprint arXiv:2602.13697, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Jonas Landsgesell, Pascal Knoll, and Tizian Wenzel. Distributional regression with tabular foundation models: Evaluating probabilistic predictions via proper scoring rules, 2026. URL https://arxiv.org/abs/2603.08206
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Tabpfn: One model to rule them all?arXiv preprint arXiv:2505.20003, 2025
Qiong Zhang, Yan Shuo Tan, Qinglong Tian, and Pengfei Li. Tabpfn: One model to rule them all?arXiv preprint arXiv:2505.20003, 2025
-
[25]
Jessup Byun, Xiaofeng Lin, Joshua Ward, and Guang Cheng. Risk in context: Benchmarking privacy leakage of foundation models in synthetic tabular data generation.arXiv preprint arXiv:2507.17066, 2025
-
[26]
Nguyen Gia Hien Vu, Yifan Tang, Rey Lim, Yifan Yang, Hang Ma, Ke Wang, and G Gary Wang. Adaptation and fine-tuning with tabpfn for travelling salesman problem.arXiv preprint arXiv:2511.05872, 2025
-
[27]
Afonso Lourenço, João Gama, Eric P Xing, and Goreti Marreiros. Bridging streaming continual learning via in-context large tabular models.arXiv preprint arXiv:2512.11668, 2025
-
[28]
Computing conditional shapley values using tabular foundation models.arXiv e-prints, pages arXiv–2602, 2026
Lars Henry Berge Olsen and Dennis Christensen. Computing conditional shapley values using tabular foundation models.arXiv e-prints, pages arXiv–2602, 2026
2026
-
[29]
Rosen Ting-Ying Yu, Nicholas Sung, and Faez Ahmed. Fire: Multi-fidelity regression with distribution-conditioned in-context learning using tabular foundation models.arXiv preprint arXiv:2601.22371, 2026
-
[30]
Jianqiao Zheng, Cameron Gordon, Yiping Ji, Hemanth Saratchandran, and Simon Lucey. From tables to signals: Revealing spectral adaptivity in tabpfn.arXiv preprint arXiv:2511.18278, 2025
-
[31]
Gradient free deep reinforcement learning with tabpfn.arXiv preprint arXiv:2509.11259, 2025
David Schiff, Ofir Lindenbaum, and Yonathan Efroni. Gradient free deep reinforcement learning with tabpfn.arXiv preprint arXiv:2509.11259, 2025
-
[32]
Tabular foundation models are strong graph anomaly detectors.arXiv preprint arXiv:2601.17301, 2026
Yunhui Liu, Tieke He, Yongchao Liu, Can Yi, Hong Jin, and Chuntao Hong. Tabular foundation models are strong graph anomaly detectors.arXiv preprint arXiv:2601.17301, 2026
-
[33]
Tabular foundation models can do survival analysis.arXiv preprint arXiv:2601.22259, 2026
Da In Kim, Wei Siang Lai, and Kelly W Zhang. Tabular foundation models can do survival analysis.arXiv preprint arXiv:2601.22259, 2026
-
[34]
Tabular foundation models can learn association rules.arXiv preprint arXiv:2602.14622, 2026
Erkan Karabulut, Daniel Daza, Paul Groth, Martijn C Schut, and Victoria Degeler. Tabular foundation models can learn association rules.arXiv preprint arXiv:2602.14622, 2026
-
[35]
Patryk Marszałek, Tomasz Ku´smierczyk, and Marek ´Smieja. Tactic for navigating the unknown: Tabular anomaly detection via in-context inference.arXiv preprint arXiv:2603.14171, 2026
-
[36]
Lakemlb: Data lake machine learning benchmark.arXiv preprint arXiv:2602.10441, 2026
Feiyu Pan, Tianbin Zhang, Aoqian Zhang, Yu Sun, Zheng Wang, Lixing Chen, Li Pan, and Jian- hua Li. Lakemlb: Data lake machine learning benchmark.arXiv preprint arXiv:2602.10441, 2026
-
[37]
Com- prehensive peripheral blood immunoprofiling reveals five immunotypes with immunotherapy response characteristics in patients with cancer.Cancer cell, 42(5):759–779, 2024
Daniiar Dyikanov, Aleksandr Zaitsev, Tatiana Vasileva, Iris Wang, Arseniy A Sokolov, Ev- genii S Bolshakov, Alena Frank, Polina Turova, Olga Golubeva, Anna Gantseva, et al. Com- prehensive peripheral blood immunoprofiling reveals five immunotypes with immunotherapy response characteristics in patients with cancer.Cancer cell, 42(5):759–779, 2024
2024
-
[38]
Predicting dementia in parkinson’s disease on a small tabular dataset using hybrid lightgbm–tabpfn and shap.Digital Health, 10: 20552076241272585, 2024
Vinh Quang Tran and Haewon Byeon. Predicting dementia in parkinson’s disease on a small tabular dataset using hybrid lightgbm–tabpfn and shap.Digital Health, 10: 20552076241272585, 2024
2024
-
[39]
Early prediction of gestational diabetes using integrated cell-free dna features and omics-derived genetic scores.medRxiv, pages 2025–09, 2025
Vinh Nguyen Dao, Nhat-Thang Tran, Ta-Son V o, Hong-Thinh Le, Thu-Ha Thi Nguyen, Quoc-Huy Vu Nguyen, Minh-Thi Thi Ha, Tam Minh Le, Diem-Tuyet Thi Hoang, Khanh- Trang Nguyen Huynh, et al. Early prediction of gestational diabetes using integrated cell-free dna features and omics-derived genetic scores.medRxiv, pages 2025–09, 2025
2025
-
[40]
Data-driven prognostication in distal medium vessel occlusions using explainable machine learning.American Journal of Neuroradiology, 46(4):725–732, 2025
Mert Karabacak, Burak Berksu Ozkara, Tobias D Faizy, Trevor Hardigan, Jeremy J Heit, Dhairya A Lakhani, Konstantinos Margetis, J Mocco, Kambiz Nael, Max Wintermark, et al. Data-driven prognostication in distal medium vessel occlusions using explainable machine learning.American Journal of Neuroradiology, 46(4):725–732, 2025. 12
2025
-
[41]
Early fault classification in rotating machinery with limited data using tabpfn.IEEE Sensors Journal, 23(24):30960–30970, 2023
Luis Magadán, José Roldán-Gómez, Juan Carlos Granda, and Francisco José Suárez. Early fault classification in rotating machinery with limited data using tabpfn.IEEE Sensors Journal, 23(24):30960–30970, 2023
2023
-
[42]
Artificial intelligence-driven predictive framework for early detection of still birth
Sarah A Alzakari, Asma Aldrees, Muhammad Umer, Lucia Cascone, Nisreen Innab, and Imran Ashraf. Artificial intelligence-driven predictive framework for early detection of still birth. SLAS technology, 29(6):100203, 2024
2024
-
[43]
Machine learning-based diagnostic prediction of minimal change disease: model development study.Scientific reports, 14(1): 23460, 2024
Ryunosuke Noda, Daisuke Ichikawa, and Yugo Shibagaki. Machine learning-based diagnostic prediction of minimal change disease: model development study.Scientific reports, 14(1): 23460, 2024
2024
-
[44]
Comparing the performance of a deep learning model (tabpfn) for predicting river algal blooms with varying data composition.Journal of Wetlands Research, 26(3):197–203, 2024
Hyunseok Yang and Jungsu Park. Comparing the performance of a deep learning model (tabpfn) for predicting river algal blooms with varying data composition.Journal of Wetlands Research, 26(3):197–203, 2024
2024
-
[45]
Harnessing small-data machine learning for transformative mental health forecasting: Towards precision psychiatry with personalised digital phenotyping, 2025
Peng Wang, Hongjun Liu, Yiming Shi, Ao Liu, Qingyu Zhu, Irina Albu, Maja Pacholec, Lulu Cheng, Xu Sun, and Xinli Chi. Harnessing small-data machine learning for transformative mental health forecasting: Towards precision psychiatry with personalised digital phenotyping, 2025
2025
-
[46]
Yunhua Li, Jianfeng Yang, Pan Xiao, Haibo Liu, Yingjun Zhou, Xiuqi Yang, Gangwen Chen, and Zhichao Zuo. Mri delta-radiomics and morphological feature-driven tabpfn model for preoperative prediction of lymphovascular invasion in invasive breast cancer.Technology in Cancer Research & Treatment, 24:15330338251362050, 2025
2025
-
[47]
A tabpfn-based framework for slope stability analysis using geometric features and shear strength parameters.Rock Mechanics Bulletin, page 100326, 2026
Xun Li and Yujing Jiang. A tabpfn-based framework for slope stability analysis using geometric features and shear strength parameters.Rock Mechanics Bulletin, page 100326, 2026
2026
-
[48]
Evaluating tabpfn for regression tasks in solar energy meteorology.Solar Energy, 309:114472, 2026
Bai Liu, Yun Chen, and Dazhi Yang. Evaluating tabpfn for regression tasks in solar energy meteorology.Solar Energy, 309:114472, 2026
2026
-
[49]
Adapting tabpfn for zero-inflated metagenomic data
Giulia Perciballi, Federica Granese, Ahmad Fall, Farida Zehraoui, Edi Prifti, and Jean-Daniel Zucker. Adapting tabpfn for zero-inflated metagenomic data. InNeurIPS 2024 Third Table Representation Learning Workshop, 2024
2024
-
[50]
Redefining surgical health economics: The potential of tabpfn for real-time precision modelling.Journal of Computer and Communica- tions, 13(11):30–40, 2025
Enoch Chi Ngai Lim and Chi Eung Danforn Lim. Redefining surgical health economics: The potential of tabpfn for real-time precision modelling.Journal of Computer and Communica- tions, 13(11):30–40, 2025
2025
-
[51]
The limitations of tabpfn for high-dimensional rna-seq analysis.bioRxiv, pages 2025–08, 2025
Summer Zhou, Vinayak Agarwal, Ashwin Gopinath, and Timothy Kassis. The limitations of tabpfn for high-dimensional rna-seq analysis.bioRxiv, pages 2025–08, 2025
2025
-
[52]
Kriging prior regression: A case for kriging-based spatial features with tabpfn in soil mapping.Computers and Electronics in Agriculture, 243:111352, 2026
Jonas Schmidinger, Viacheslav Barkov, Sebastian V ogel, Martin Atzmueller, and Gerard BM Heuvelink. Kriging prior regression: A case for kriging-based spatial features with tabpfn in soil mapping.Computers and Electronics in Agriculture, 243:111352, 2026
2026
-
[53]
Predicting adverse events for risk stratification of chemotherapy based stem cell mobilization in multiple myeloma
F Schwarz, L Levien, M Maulhardt, G Wulf, N Brökers, and E Aydilek. Predicting adverse events for risk stratification of chemotherapy based stem cell mobilization in multiple myeloma. npj Digital Medicine, 2026
2026
-
[54]
Wenpeng Zhao, Shanchuan Guo, Xueliang Zhang, Pengfei Tang, Xiaoquan Pan, Haowei Mu, Chenghan Yang, Zilong Xia, Zheng Wang, Jun Du, et al. A weakly supervised approach for large-scale agricultural parcel extraction from vhr imagery via foundation models and adaptive noise correction.ISPRS Journal of Photogrammetry and Remote Sensing, 233:180–208, 2026
2026
-
[55]
Tabular foundation models as a new portable standard in local surgical risk prediction.Surgery, 192:110078, 2026
Chris Varghese, Elizabeth Habermann, Kristine Hanson, Ashok Choudhary, Hojjat Salehinejad, and Cornelius Thiels. Tabular foundation models as a new portable standard in local surgical risk prediction.Surgery, 192:110078, 2026
2026
-
[56]
Yilang Ding, Jiawen Ren, Jiaying Lu, Gloria Hyunjung Kwak, Armin Iraji, Shengpu Tang, and Alex Fedorov. Longitudinal progression prediction of alzheimer’s disease with tabular foundation model.arXiv preprint arXiv:2508.17649, 2025
-
[57]
A method for better mapping of susceptibility to thaw hazards in data-scarce cold regions.Remote Sensing of Environment, 337:115338, 2026
Hualiang Zhu, Xianwei Zhang, Gang Wei, Qingzhi Wang, Xinyu Liu, Lei Yan, and Gang Wang. A method for better mapping of susceptibility to thaw hazards in data-scarce cold regions.Remote Sensing of Environment, 337:115338, 2026
2026
-
[58]
Advancing biogeographical ancestry predictions through machine learning.Forensic Science International: Genetics, 79:103290, 2025
Carola Sophia Heinzel, Lennart Purucker, Frank Hutter, and Peter Pfaffelhuber. Advancing biogeographical ancestry predictions through machine learning.Forensic Science International: Genetics, 79:103290, 2025. 13
2025
-
[59]
Predicting the maximum loading in zeolites for hydroisomerization applications: A machine learning approach.The Journal of Physical Chemistry C, 2026
Eric Johnsson, Shrinjay Sharma, Arvind Gangoli Rao, David Dubbeldam, Sofia Calero, and Thijs JH Vlugt. Predicting the maximum loading in zeolites for hydroisomerization applications: A machine learning approach.The Journal of Physical Chemistry C, 2026
2026
-
[60]
Jian Guo, Haoxuan Ren, and Kaijiang Ma. Predicting initial accident states in hazardous chemical road transportation: a causal and interpretable machine learning approach.Reliability Engineering & System Safety, page 112430, 2026
2026
-
[61]
Transformer-based foundation models for assessing earthquake-and vehicle-induced damage in bridges.Engineering Structures, 358: 122587, 2026
Gil Hwan Wang, Sujith Mangalathu, and Jong-Su Jeon. Transformer-based foundation models for assessing earthquake-and vehicle-induced damage in bridges.Engineering Structures, 358: 122587, 2026
2026
-
[62]
In-context learning for nano-pcm thermal behavior prediction in battery thermal management via lattice boltzmann simulation.Energy, page 138693, 2025
Bichen Shang, Guo Li, Weijie Sun, Liwei Zhang, Guanzhe Cui, Jiyuan Tu, Xiang Fang, and Xueren Li. In-context learning for nano-pcm thermal behavior prediction in battery thermal management via lattice boltzmann simulation.Energy, page 138693, 2025
2025
-
[63]
Panmetai- a high performance tabular foundation model for accurate pancreatic cancer diagnosis via nmr metabolomics.Nature Communications, 17(1):1595, 2026
Dan-Ni Wu, Joey Jen, Erickson Fajiculay, Min-Fen Hsu, Ming-Chu Chang, Jen-Chen Yeh, Karen Sargsyan, Juozas Kupcinskas, Jurgita Skieceviciene, Ruta Steponaitiene, et al. Panmetai- a high performance tabular foundation model for accurate pancreatic cancer diagnosis via nmr metabolomics.Nature Communications, 17(1):1595, 2026
2026
-
[64]
A machine learning–based tool for enhancing position accuracy in industrial robots with a reduced dataset.Robotics and Computer-Integrated Manufacturing, 101:103289, 2026
Giuseppe Romano, Pietro Bilancia, Alberto Locatelli, Mirko Mucciarini, Manuel Iori, and Marcello Pellicciari. A machine learning–based tool for enhancing position accuracy in industrial robots with a reduced dataset.Robotics and Computer-Integrated Manufacturing, 101:103289, 2026
2026
-
[65]
Machine learning ap- proaches for assessing avocado alternate bearing using sentinel-2 and climate variables—a case study in limpopo, south africa.Remote Sensing, 17(24):3935, 2025
Muhammad Moshiur Rahman, Andrew Robson, and Theo Bekker. Machine learning ap- proaches for assessing avocado alternate bearing using sentinel-2 and climate variables—a case study in limpopo, south africa.Remote Sensing, 17(24):3935, 2025
2025
-
[66]
Data-augmented machine learning for predicting biomass-derived hard carbon anode performance in sodium-ion batteries.Journal of Energy Chemistry, 2026
Gang Chen, Zihan Yang, Peng Sun, Junfeng Li, Chenglong Wang, Jinliang Li, Guang Yang, and Likun Pan. Data-augmented machine learning for predicting biomass-derived hard carbon anode performance in sodium-ion batteries.Journal of Energy Chemistry, 2026
2026
-
[67]
Coupling eur predic- tion with fracturing optimization: An integrated machine learning framework for shale gas development.Unconventional Resources, page 100246, 2025
Hongjian Chen, Feifei Fang, Pujun Long, Putian Yang, and Wei Guo. Coupling eur predic- tion with fracturing optimization: An integrated machine learning framework for shale gas development.Unconventional Resources, page 100246, 2025
2025
-
[68]
Boosting pre-trained model with silica nanoparticles cellular toxicity prediction.Scientific Reports, 2025
Huixia Zhang, Jiajun Tong, Minmin Chen, and Xichuan Cao. Boosting pre-trained model with silica nanoparticles cellular toxicity prediction.Scientific Reports, 2025
2025
-
[69]
Junjie Xu, Yilei Yu, Lihu Yang, Xin Wei, Shiqin Wang, Bingxia Liu, and Yamin Shi. Multiscale prediction from ion concentrations to salinity patterns of arid and saline-alkali farmland using machine learning algorithm in xinjiang region of china.Available at SSRN 5591702, 2025
2025
-
[70]
Minimal supervision, maximum accuracy: Tabpfn for microcontroller performance prediction
Nicolò Bellarmino, Riccardo Cantoro, Martin Huch, Tobias Kilian, and Annachiara Ruospo. Minimal supervision, maximum accuracy: Tabpfn for microcontroller performance prediction. In2025 IEEE International Test Conference (ITC), pages 470–473. IEEE, 2025
2025
-
[71]
Fuelcast: Benchmarking tabular and temporal models for ship fuel consumption
Justus Viga, Penelope Mueck, Alexander Löser, and Torben Weis. Fuelcast: Benchmarking tabular and temporal models for ship fuel consumption. InInternational Workshop on Advanced Analytics and Learning on Temporal Data, pages 54–69. Springer, 2025
2025
-
[72]
Deep learning for cross-selling health insurance classification
Jasmin ZK Chu, Joel CM Than, and Hudyjaya Siswoyo Jo. Deep learning for cross-selling health insurance classification. In2024 International Conference on Green Energy, Computing and Sustainable Technology (GECOST), pages 453–457. IEEE, 2024
2024
-
[73]
Taiga Saito, Yu Otake, and Stephen Wu. Tabular foundation model for geoai benchmark problems bm/airportsoilproperties/2/2025.arXiv preprint arXiv:2509.03191, 2025
-
[74]
Evaluating sap rpt-1 for enterprise business process prediction: In-context learning vs
Amit Lal. Evaluating sap rpt-1 for enterprise business process prediction: In-context learning vs. traditional machine learning on structured sap data.arXiv preprint arXiv:2602.19237, 2026
-
[75]
Unreflected use of tabular data repositories can undermine research quality
Andrej Tschalzev, Lennart Purucker, Stefan Lüdtke, Frank Hutter, Christian Bartelt, and Heiner Stuckenschmidt. Unreflected use of tabular data repositories can undermine research quality. InThe Future of Machine Learning Data Practices and Repositories at ICLR 2025, 2025
2025
-
[76]
Chapman and Hall/CRC, 2000
Chris Chatfield.Time-series forecasting. Chapman and Hall/CRC, 2000. 14
2000
-
[77]
Time-series forecasting with deep learning: a survey.Philo- sophical transactions of the royal society a: mathematical, physical and engineering sciences, 379(2194), 2021
Bryan Lim and Stefan Zohren. Time-series forecasting with deep learning: a survey.Philo- sophical transactions of the royal society a: mathematical, physical and engineering sciences, 379(2194), 2021
2021
-
[78]
Autogluon–timeseries: Automl for probabilistic time series forecasting
Oleksandr Shchur, Ali Caner Turkmen, Nick Erickson, Huibin Shen, Alexander Shirkov, Tony Hu, and Bernie Wang. Autogluon–timeseries: Automl for probabilistic time series forecasting. InInternational Conference on Automated Machine Learning, pages 9–1. PMLR, 2023
2023
-
[79]
Zero-shot Multivariate Time Series Forecasting Using Tabular Prior Fitted Networks
Mayuka Jayawardhana, Nihal Sharma, Kazem Meidani, Bayan Bruss, Tom Goldstein, and Doron Bergman. Zero-shot multivariate time series forecasting using tabular prior fitted networks.arXiv preprint arXiv:2604.08400, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[80]
The arrow of time: What tabular foundation models miss in time series forecasting
Andres Potapczynski, Ravi Kiran Selvam, Tatiana Konstantinova, Malcolm Wolff, Kin G Olivares, Ruijun Ma, Michael W Mahoney, Andrew Gordon Wilson, Boris N Oreshkin, and Dmitry Efimov. The arrow of time: What tabular foundation models miss in time series forecasting. In1st ICLR Workshop on Time Series in the Age of Large Models, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.