Translating Natural Language to Strategic Temporal Specifications via LLMs
Pith reviewed 2026-07-03 22:33 UTC · model grok-4.3
The pith
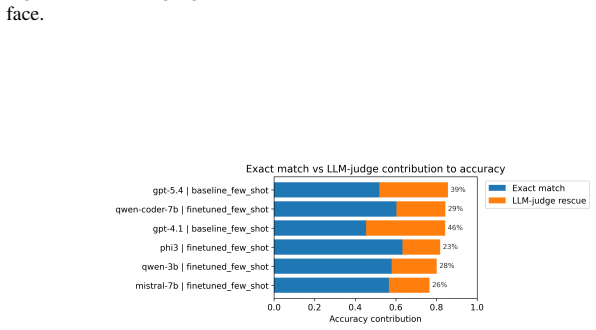
Fine-tuned 3-7B open-weight models translate natural language strategic requirements into ATL/ATL* formulas at 0.84 semantic accuracy, matching the 0.86 score of strong few-shot proprietary baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a translation pipeline based on LLMs, trained on a newly curated expert-validated dataset, converts natural language statements of strategic and temporal requirements into correct ATL/ATL* formulas. Evaluated with the LLM judge that best matches human annotations, the best fine-tuned 3-7B open-weight model reaches 0.84 semantic accuracy, statistically equivalent to the 0.86 accuracy of the strongest few-shot proprietary baseline. The work additionally shows that judge reliability is inverse to generator strength and demonstrates practical use by embedding the translator inside a strategic model checker.
What carries the argument
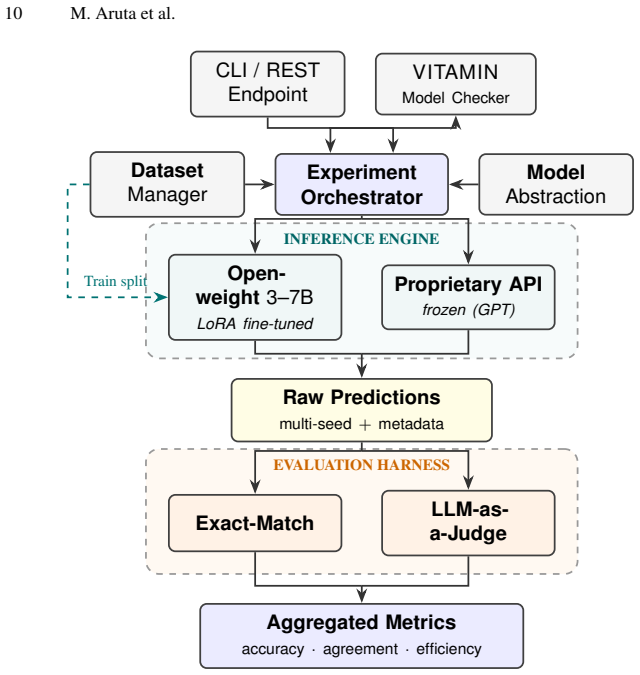
An LLM-based translation pipeline that maps natural language descriptions of strategic abilities and temporal objectives in multi-agent systems onto well-formed ATL/ATL* formulas, trained and evaluated on a new expert-validated dataset.
If this is right
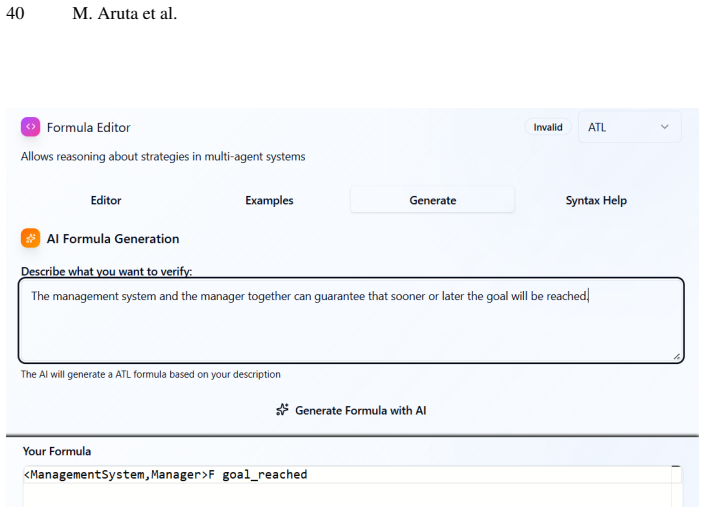
- Non-expert users can express strategic properties in natural language and immediately check them in an existing ATL/ATL* model checker.
- Translation and verification can be performed entirely on-premises using small open-weight models.
- Judge reliability decreases as generator strength increases, so weaker models may be preferable for automatic evaluation.
- The same dataset and fine-tuning approach can support additional strategic logics beyond ATL/ATL*.
Where Pith is reading between the lines
- The method could be tested on real deployed multi-agent systems to measure how often the generated formulas catch actual specification errors.
- Extending the dataset with more complex nested strategic operators might reveal where fine-tuning still falls short of proprietary models.
- Combining the translator with automated repair suggestions could create an end-to-end assistant that both writes and corrects formal requirements.
Load-bearing premise
The chosen LLM judge that best agrees with expert annotations serves as a reliable proxy for whether the generated ATL/ATL* formulas are semantically correct.
What would settle it
A fresh round of human expert annotation on the held-out test set that finds the fine-tuned models produce significantly more semantically incorrect formulas than the proprietary baselines.
Figures






read the original abstract
A rigorous formalization of system requirements is a fundamental prerequisite for the verification of Multi-Agent Systems (MAS). However, writing correct formal specifications is well known as an error-prone, time-consuming, and expertise-intensive task. This difficulty is further accentuated in MAS, where requirements must capture strategic abilities and temporal objectives. At present, there is no established methodology for deriving MAS specifications from natural language. We present a framework for translating Natural Language descriptions of strategic requirements into well-formed ATL/ATL* formulas using Large Language Models (LLMs). Since no available dataset supports supervised learning for the NL-to-ATL/ATL* translation task, we create and curate a novel expert-validated dataset, employed for training and evaluating fine-tuned models. On a held-out test set, evaluated under the LLM judge that best agrees with expert annotations, in-domain fine-tuning of small open-weight models (3 - 7B parameters) matches strong few-shot proprietary API baselines. Our best fine-tuned system reaches 0.84 semantic accuracy, statistically on par with 0.86 for the strongest few-shot proprietary baseline, while keeping requirements on-premises. We further find that judge reliability is inverse to generator strength. The open-weight Llama-3.3-70B tracks human verdicts most closely, whereas the strongest proprietary models are the least reliable judges, over-rejecting faithful paraphrases of the reference. To assess the practical applicability of the generated specifications, we embed our tool to an existing strategic logics model checker, enabling non-expert users to specify strategic properties in natural language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for translating natural language descriptions of strategic requirements for multi-agent systems into well-formed ATL/ATL* formulas using LLMs. Since no suitable dataset exists, the authors create and curate a novel expert-validated dataset for supervised fine-tuning and evaluation. On a held-out test set, evaluated under the LLM judge with highest agreement to expert annotations, in-domain fine-tuning of small open-weight models (3-7B parameters) reaches 0.84 semantic accuracy, statistically on par with 0.86 for the strongest few-shot proprietary API baseline. The work also reports that judge reliability is inversely related to generator strength, with stronger proprietary models over-rejecting faithful paraphrases, and demonstrates integration with an existing strategic logics model checker to enable non-expert specification.
Significance. If the reported evaluation holds under scrutiny, the work has clear practical significance for lowering the barrier to formalizing strategic temporal properties in MAS verification, particularly by supporting on-premises use of small fine-tuned models. The creation of the expert-validated NL-to-ATL/ATL* dataset is a foundational contribution that can enable further research. The empirical comparison between fine-tuned open models and proprietary few-shot baselines, along with the observation on judge reliability, provides actionable insights for LLM-based formalization tasks. The model-checker integration shows direct applicability.
major comments (2)
- [Dataset creation and evaluation] Dataset creation and evaluation (as described in the abstract): The central claims rest on a held-out test set with expert validation and reported statistical parity (0.84 vs. 0.86), yet the manuscript provides no details on dataset size, exclusion criteria, inter-annotator agreement, or exact prompting and fine-tuning procedures. These omissions are load-bearing for assessing the reliability and representativeness of the accuracy numbers and the parity conclusion.
- [Judge selection and evaluation methodology] Judge selection and evaluation methodology (as described in the abstract): Performance is reported exclusively under the single LLM judge selected for maximal agreement with expert annotations on the held-out set. Combined with the paper's own finding that judge reliability decreases with generator strength and that strong proprietary models over-reject faithful paraphrases, this selection risks introducing bias that could systematically favor or disfavor fine-tuned open models versus few-shot proprietary baselines, undermining the statistical parity claim without further validation (e.g., results under alternative judges).
minor comments (1)
- [Abstract] The abstract introduces ATL/ATL* and MAS without spelling out the acronyms on first use, though they are standard in the field; a brief parenthetical expansion would improve accessibility for a broader readership.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We agree that the manuscript requires additional details on dataset creation and a more robust evaluation of the judge methodology to support the central claims. We will revise the paper accordingly. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Dataset creation and evaluation] Dataset creation and evaluation (as described in the abstract): The central claims rest on a held-out test set with expert validation and reported statistical parity (0.84 vs. 0.86), yet the manuscript provides no details on dataset size, exclusion criteria, inter-annotator agreement, or exact prompting and fine-tuning procedures. These omissions are load-bearing for assessing the reliability and representativeness of the accuracy numbers and the parity conclusion.
Authors: We agree that the manuscript as currently written does not include these details, which limits the ability to fully assess the results. In the revised version we will expand the dataset and methods sections to report the exact dataset size (including train/validation/test splits), the exclusion criteria applied during curation, inter-annotator agreement statistics, and the precise prompting templates together with all fine-tuning hyperparameters and training procedures. revision: yes
-
Referee: [Judge selection and evaluation methodology] Judge selection and evaluation methodology (as described in the abstract): Performance is reported exclusively under the single LLM judge selected for maximal agreement with expert annotations on the held-out set. Combined with the paper's own finding that judge reliability decreases with generator strength and that strong proprietary models over-reject faithful paraphrases, this selection risks introducing bias that could systematically favor or disfavor fine-tuned open models versus few-shot proprietary baselines, undermining the statistical parity claim without further validation (e.g., results under alternative judges).
Authors: We acknowledge the risk of bias highlighted by the referee. While selecting the judge with highest expert agreement was intended to maximize evaluation reliability, we agree that reporting results under only one judge is insufficient given our own findings on judge behavior. In the revision we will add performance numbers under at least two additional judges (including the strongest proprietary model) and will expand the discussion to explicitly address how judge choice affects the parity conclusion. revision: yes
Circularity Check
No significant circularity: empirical results on held-out set with expert-anchored judge metric
full rationale
The paper reports an empirical ML study: creation of an expert-validated NL-to-ATL/ATL* dataset, fine-tuning of open models, and evaluation of semantic accuracy on a held-out test set using an LLM judge selected for maximum agreement with expert annotations. No equations, derivations, or self-citations are present that reduce the reported accuracies (0.84 vs 0.86) to fitted parameters or inputs by construction. The central claim rests on external expert validation and a held-out split, satisfying the criteria for a self-contained result (score 0-2). The judge selection is a methodological choice validated against experts independently of the generators being compared.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of the ACM (JACM)49(5), 672–713 (2002)
Alur, R., Henzinger, T.A., Kupferman, O.: Alternating-time temporal logic. Journal of the ACM (JACM)49(5), 672–713 (2002)
2002
-
[2]
KR16, 258–267 (2016)
Aminof, B., Murano, A., Rubin, S., Zuleger, F.: Prompt alternating-time epistemic logics. KR16, 258–267 (2016)
2016
-
[3]
In: Proc
Belardinelli, F., Jamroga, W., Kurpiewski, D., Malvone, V ., Murano, A.: Strategy logic with simple goals: Tractable reasoning about strategies. In: Proc. of IJCAI
-
[4]
pp. 88–94. ijcai.org (2019)
2019
-
[5]
In: Proc
Cermák, P., Lomuscio, A., Murano, A.: Verifying and synthesising multi-agent systems against one-goal strategy logic specifications. In: Proc. of AAAI. pp. 2038–2044. AAAI Press (2015)
2038
-
[6]
In: Jacobs, R.A., Rosenbaum, P.S
Chomsky, N.: Remarks on nominalization. In: Jacobs, R.A., Rosenbaum, P.S. (eds.) Readings in English Transformational Grammar, pp. 184–221. Ginn, Waltham, MA (1970)
1970
-
[7]
In: Workshop on logic of programs
Clarke, E.M., Emerson, E.A.: Design and synthesis of synchronization skeletons using branching time temporal logic. In: Workshop on logic of programs. pp. 52–71. Springer (1981)
1981
-
[8]
In: CA V 2023
Cosler, M., Hahn, C., Mendoza, D., Schmitt, F., Trippel, C.: nl2spec: Interactively translating unstructured natural language to temporal logics with large language models. In: CA V 2023. pp. 383–396. Springer (2023)
2023
-
[9]
arXiv preprint arXiv:2303.01158 (2023)
Cosler, M., Schmitt, F., Hahn, C., Finkbeiner, B.: Iterative circuit repair against formal specifications. arXiv preprint arXiv:2303.01158 (2023)
-
[10]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: QLoRA: Efficient fine- tuning of quantized LLMs. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[11]
In: AAMAS 2025
Ferrando, A., Malvone, V .: VITAMIN: verification of A multi agent system. In: AAMAS 2025. pp. 3023–3025. IFAAMAS (2025)
2025
-
[12]
ArXivabs/2003.04218(2020), https://api.semanticscholar.org/ CorpusID:212633677
Finkbeiner, B., Hahn, C., Rabe, M.N., Schmitt, F.: Teaching temporal logics to neural networks. ArXivabs/2003.04218(2020), https://api.semanticscholar.org/ CorpusID:212633677
-
[13]
Linguistics and Philosophy5(3), 355–398 (1982)
Fodor, J.D., Sag, I.A.: Referential and quantificational indefinites. Linguistics and Philosophy5(3), 355–398 (1982)
1982
-
[14]
Translations from the philosophical writings of Gottlob Frege2, 56–85 (1892)
Frege, G.: On sense and reference. Translations from the philosophical writings of Gottlob Frege2, 56–85 (1892)
-
[15]
In: AAAI 2023
Fuggitti, F., Chakraborti, T.: Nl2ltl–a python package for converting natural lan- guage (nl) instructions to linear temporal logic (ltl) formulas. In: AAAI 2023. vol. 37, pp. 16428–16430 (2023)
2023
-
[16]
In: ICSE 2022
He, J., Bartocci, E., Nickovic, D., Isakovic, H., Grosu, R.: Deepstl - from english requirements to signal temporal logic. In: ICSE 2022. pp. 610–622. ACM (2022)
2022
-
[17]
In: International Conference on Learning Representations (ICLR) (2022) Translating Natural Language to Strategic Temporal Specifications via LLMs 21
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (ICLR) (2022) Translating Natural Language to Strategic Temporal Specifications via LLMs 21
2022
-
[18]
Jamroga, W., van der Hoek, W.: Agents that know how to play. Fundam. Infor- maticae63(2-3), 185–219 (2004), http://content.iospress.com/articles/fundamenta- informaticae/fi63-2-3-05
2004
-
[19]
In: Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems
Jamroga, W., Malvone, V ., Murano, A.: Reasoning about natural strategic ability. In: Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems. pp. 714–722 (2017)
2017
-
[20]
arXiv preprint arXiv:2502.16339 (2025)
Kulkarni, A.N., Liu, A., Gaglione, J.R., Fried, D., Topcu, U.: Dynamic coali- tion structure detection in natural language-based interactions. arXiv preprint arXiv:2502.16339 (2025)
-
[21]
In: International symposium on formal techniques in real-time and fault-tolerant systems
Maler, O., Nickovic, D.: Monitoring temporal properties of continuous signals. In: International symposium on formal techniques in real-time and fault-tolerant systems. pp. 152–166. Springer (2004)
2004
-
[22]
In: 2024 Formal Methods in Computer-Aided Design (FMCAD)
Mendoza, D., Hahn, C., Trippel, C.: Translating natural language to temporal logics with large language models and model checkers. In: 2024 Formal Methods in Computer-Aided Design (FMCAD). pp. 1–11. IEEE (2024)
2024
-
[23]
Mogavero, F., Murano, A., Perelli, G., Vardi, M.Y .: Reasoning about strategies: On the model-checking problem. ACM Trans. Comput. Log.15(4), 34:1–34:47 (2014). https://doi.org/10.1145/2631917, https://doi.org/10.1145/2631917
-
[24]
In: REFSQ 2022
Nayak, A., Timmapathini, H.P., Murali, V ., Ponnalagu, K., Venkoparao, V .G., Post, A.: Req2spec: Transforming software requirements into formal specifications using natural language processing. In: REFSQ 2022. pp. 87–95. Springer (2022)
2022
-
[25]
In: 18th annual symposium on founda- tions of computer science (sfcs 1977)
Pnueli, A.: The temporal logic of programs. In: 18th annual symposium on founda- tions of computer science (sfcs 1977). pp. 46–57. ieee (1977)
1977
-
[26]
Linguistics and Philosophy20(4), 335–397 (1997)
Reinhart, T.: Quantifier scope: How labor is divided between qr and choice func- tions. Linguistics and Philosophy20(4), 335–397 (1997)
1997
-
[27]
In: Haegeman, L
Rizzi, L.: The fine structure of the left periphery. In: Haegeman, L. (ed.) Elements of Grammar, pp. 281–337. Kluwer, Dordrecht (1997)
1997
-
[28]
Mind14(56), 479–493 (1905)
Russell, B.: On denoting. Mind14(56), 479–493 (1905)
1905
-
[29]
Russell, B.: The philosophy of logical atomism. The Monist29(1), 32–63 (1919). https://doi.org/10.5840/monist191929120
-
[30]
Duckworth, London ([1916] 1983), (trans
de Saussure, F.: Course in General Linguistics. Duckworth, London ([1916] 1983), (trans. Roy Harris)
1916
-
[31]
Cambridge University Press (2008)
Shoham, Y ., Leyton-Brown, K.: Multiagent systems: Algorithmic, game-theoretic, and logical foundations. Cambridge University Press (2008)
2008
-
[32]
(eds.): Lexical Ambiguity Resolution: Perspective from Psycholinguistics, Neuropsychology and Artificial Intelligence
Small, S.L., Cottrell, G.W., Tanenhaus, M.K. (eds.): Lexical Ambiguity Resolution: Perspective from Psycholinguistics, Neuropsychology and Artificial Intelligence. Elsevier (2013)
2013
-
[33]
arXiv preprint arXiv:2502.04498 (2025)
Wang, Z., Jiang, J., Zhou, H., Zheng, W., Zhang, X., Bansal, C., Yao, H.: Verifiable format control for large language model generations. arXiv preprint arXiv:2502.04498 (2025)
-
[34]
John wiley & sons (2009)
Wooldridge, M.: An introduction to multiagent systems. John wiley & sons (2009)
2009
-
[35]
Advances in neural information processing systems35, 32353–32368 (2022)
Wu, Y ., Jiang, A.Q., Li, W., Rabe, M., Staats, C., Jamnik, M., Szegedy, C.: Autofor- malization with large language models. Advances in neural information processing systems35, 32353–32368 (2022)
2022
-
[36]
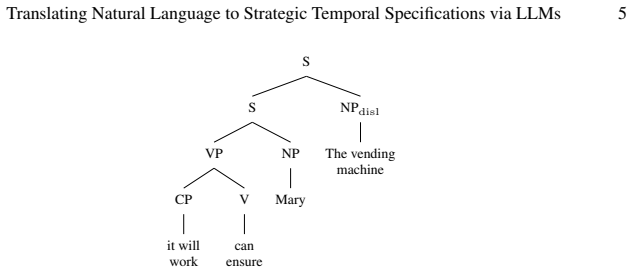
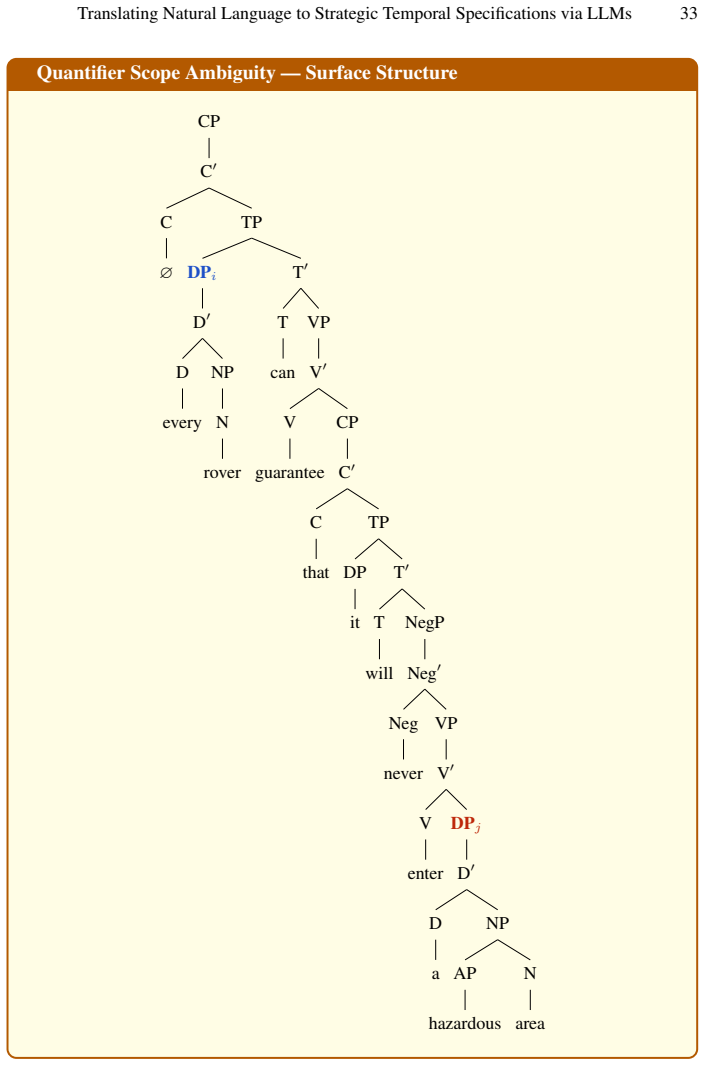
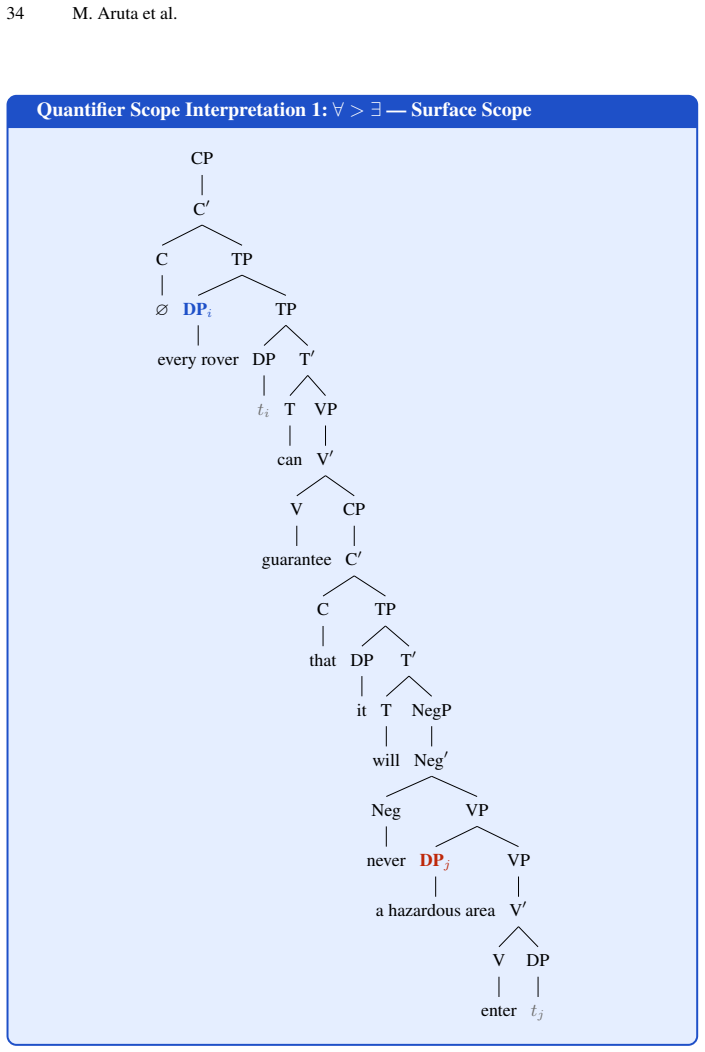
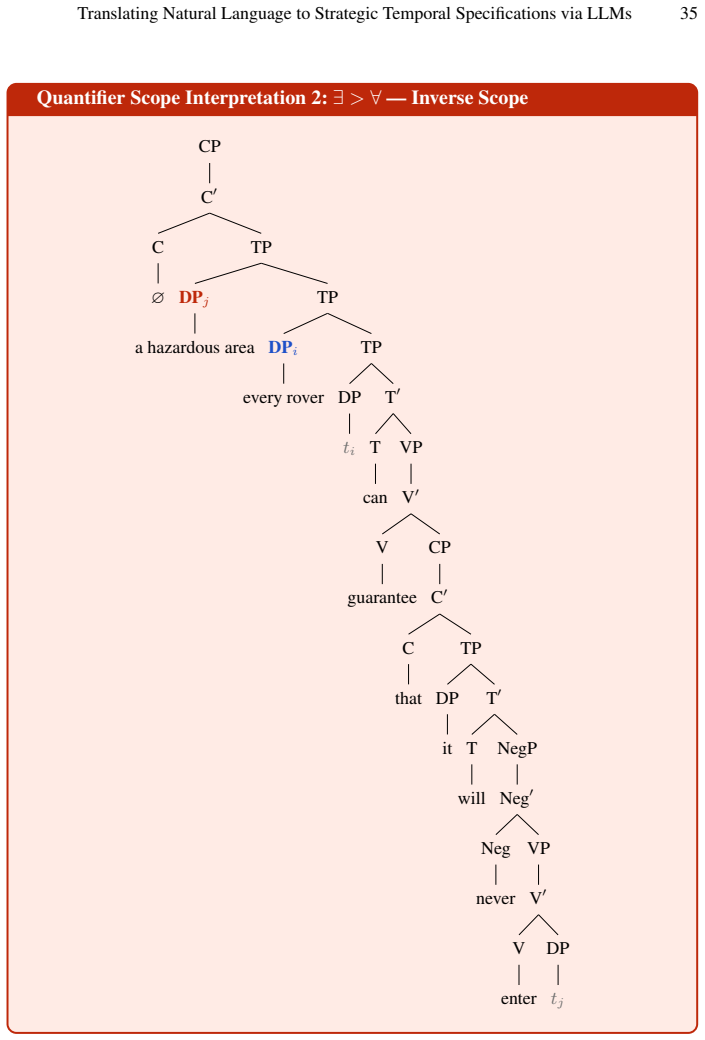
for every rover, there is a possibly different hazardous area such that the rover can guarantee that it will never enter it
Zrelli, R., Misson, H.A., Ben Attia, M., Gohring de Magalhaes, F., Shabah, A., Nicolescu, G.: Automatic translation of natural language requirements into ctl spec- 22 M. Aruta et al. ifications using large language models: A multi-approach evaluation⋆. Available at SSRN 5334216 A Technical Appendix The syntactic trees in this appendix employ X-bar theoret...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.