Beyond 2D Matching: A Unified Single-Stage Framework for Geometry-Aware Cross-View Object Geo-Localization
Pith reviewed 2026-06-30 06:10 UTC · model grok-4.3
The pith
A single-stage framework adapts a 3D foundation model to predict boxes, masks, and poses for cross-view object localization in one pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
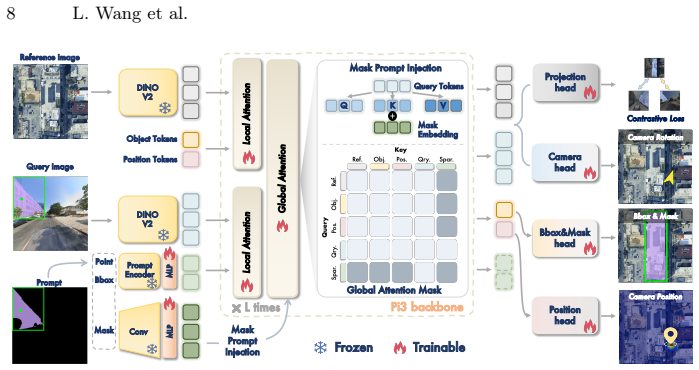
The Geometry-Aware Geo-localization framework (GAGeo) built upon the permutation-equivariant 3D foundation model π³ jointly predicts bounding boxes, segmentation masks, and camera poses in a single forward pass by integrating visual features, referring prompts, and learnable task tokens, while a contrastive loss using the satellite view as anchor enables zero-shot ground-to-drone localization.
What carries the argument
The GAGeo framework that adapts the 3D prior from the permutation-equivariant 3D foundation model π³ through integration of visual features, referring prompts, and learnable task tokens for multi-output prediction.
If this is right
- Supports flexible referring with points, boxes or masks as prompts.
- Provides explicit camera pose prediction for spatial modeling.
- Facilitates zero-shot localization between ground and drone views without specific training pairs.
- Shows strong performance in unseen scenes and novel cross-view setups.
Where Pith is reading between the lines
- Such single-stage geometry-aware models could reduce the need for separate 2D matching pipelines in multi-view applications.
- The large dataset with geometric metadata may enable future work on explicit 3D reconstruction from cross-view images.
- Generalization to novel setups suggests the 3D prior helps in handling variations not seen in training.
Load-bearing premise
The 3D prior inherited from the permutation-equivariant foundation model can be adapted to the cross-view task by integrating visual features, referring prompts, and learnable task tokens for joint prediction.
What would settle it
A controlled experiment where the model without the 3D prior or the integration module performs no better than existing 2D matching methods on the new dataset in unseen scenes would falsify the central claim.
Figures


read the original abstract
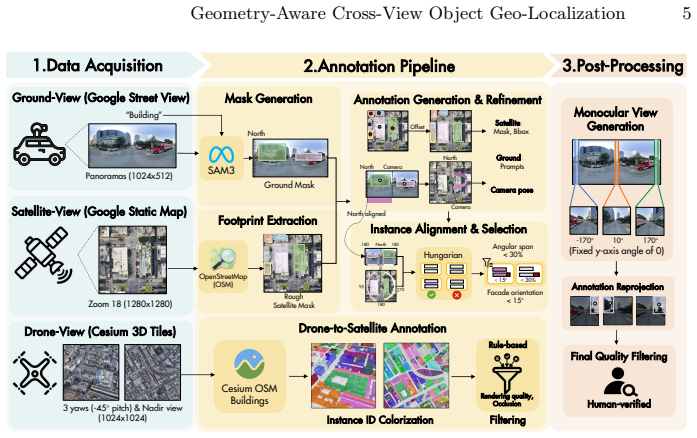
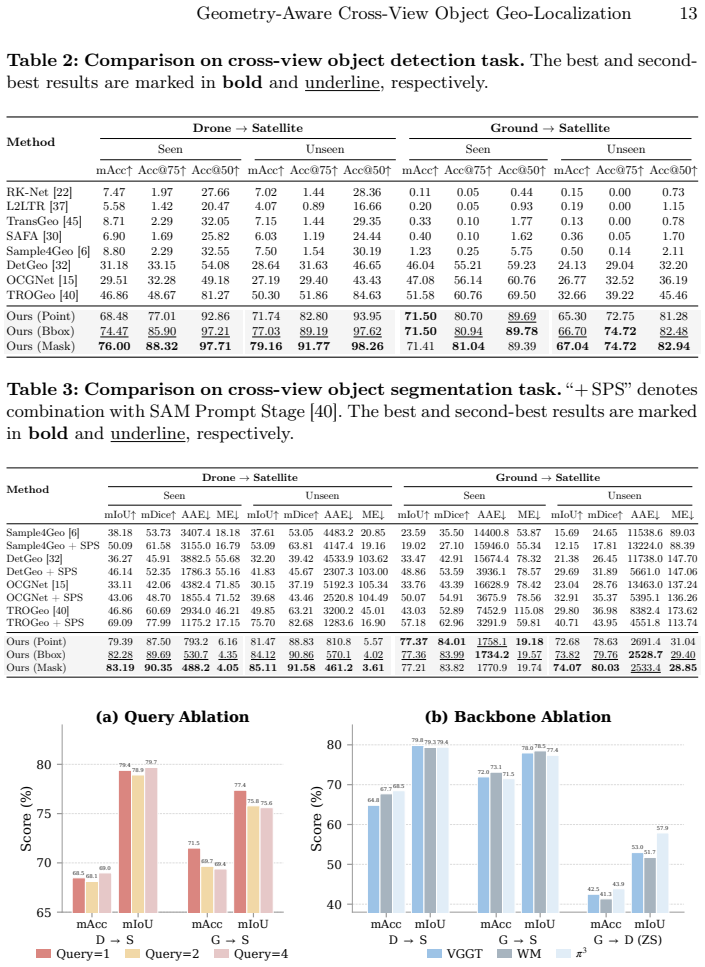
Cross-view object geo-localization (CVOGL) aims to locate a target object from a query view (e.g., ground or drone) within a geo-tagged reference image (e.g., satellite). Existing approaches heavily rely on 2D appearance matching and are constrained by limited datasets lacking geometric metadata, diverse prompts, and standard field-of-view imagery. To address these intertwined challenges, we first introduce \dataset, a large-scale, high-fidelity building dataset comprising over 220,000 ground-satellite and drone-satellite pairs. It provides multi-modal prompts (points, boxes, masks) and camera poses to enable flexible target referring and explicit spatial modeling. Furthermore, we propose a novel single-stage Geometry-Aware Geo-localization framework (GAGeo), built upon the permutation-equivariant 3D foundation model $\pi^3$. By seamlessly integrating visual features, referring prompts, and learnable task tokens, our model adapts the inherited 3D prior to jointly predict bounding boxes, segmentation masks, and camera poses in a single forward pass. Additionally, we introduce a contrastive loss that utilizes the satellite view as a universal anchor, implicitly aligning ground and drone representations to enable zero-shot ground-to-drone localization without requiring triplet training data. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art methods, exhibiting exceptional generalization ability in unseen scenes and novel cross-view setups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address limitations in cross-view object geo-localization (CVOGL) by introducing a new large-scale dataset \dataset with over 220,000 ground-satellite and drone-satellite pairs that include multi-modal prompts (points, boxes, masks) and camera poses. It proposes the single-stage Geometry-Aware Geo-localization (GAGeo) framework built on the permutation-equivariant 3D foundation model π³, which integrates visual features, referring prompts, and learnable task tokens to jointly predict bounding boxes, segmentation masks, and camera poses in one forward pass. A contrastive loss is introduced that uses the satellite view as a universal anchor to implicitly align ground and drone representations, enabling zero-shot ground-to-drone localization. The authors state that extensive experiments demonstrate significant outperformance over state-of-the-art methods along with strong generalization to unseen scenes and novel cross-view setups.
Significance. If the experimental claims hold, the work would advance CVOGL by shifting from 2D appearance matching to a geometry-aware unified framework that reuses 3D priors from a foundation model. The new dataset supplies geometric metadata and flexible multi-modal referring, which directly tackles documented dataset limitations and could serve as a reusable benchmark. The satellite-anchor contrastive loss provides a practical route to zero-shot transfer without triplet data. Credit is given for the dataset release and the single-stage multi-task formulation that jointly handles detection, segmentation, and pose estimation.
minor comments (2)
- [Abstract] Abstract: the dataset is denoted only as \dataset with no expanded name or acronym; this should be clarified on first use for readability.
- [§3] The integration of referring prompts and task tokens into π³ is described at a high level; adding a short equation or diagram in §3 or §4 that shows the token concatenation and output heads would improve clarity without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the significance of the new dataset and GAGeo framework, and recommendation for minor revision. We appreciate the credit given for the dataset release, the single-stage multi-task formulation, and the satellite-anchor contrastive loss.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central claims rest on a new dataset with explicit geometric metadata and multi-modal prompts, an adaptation of the external π³ foundation model via added visual features/referring prompts/task tokens for joint prediction, and a contrastive loss that treats satellite as anchor for alignment. These components are introduced as independent contributions rather than derived from the target performance metrics or prior self-citations. No equations, fitted parameters, or load-bearing self-citations reduce the reported outperformance or generalization results to inputs by construction. The experimental validation is presented as separate grounding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Computer43(6), 32–38 (2010)
Anguelov, D., Dulong, C., Filip, D., Frueh, C., Lafon, S., Lyon, R., Ogale, A., Vincent, L., Weaver, J.: Google street view: Capturing the world at street level. Computer43(6), 32–38 (2010)
2010
-
[2]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: ECCV
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: ECCV. pp. 213–229. Springer (2020)
2020
-
[4]
IEEE TCSVT32(7), 4376–4389 (2021)
Dai, M., Hu, J., Zhuang, J., Zheng, E.: A transformer-based feature segmentation and region alignment method for uav-view geo-localization. IEEE TCSVT32(7), 4376–4389 (2021)
2021
-
[5]
IEEE TIP33, 493–508 (2023)
Dai, M., Zheng, E., Feng, Z., Qi, L., Zhuang, J., Yang, W.: Vision-based uav self- positioning in low-altitude urban environments. IEEE TIP33, 493–508 (2023)
2023
-
[6]
In: ICCV
Deuser, F., Habel, K., Oswald, N.: Sample4geo: Hard negative sampling for cross- view geo-localisation. In: ICCV. pp. 16847–16856 (2023)
2023
-
[7]
NeurIPS34, 26183–26197 (2021)
Fang, Y., Liao, B., Wang, X., Fang, J., Qi, J., Wu, R., Niu, J., Liu, W.: You only look at one sequence: Rethinking transformer in vision through object detection. NeurIPS34, 26183–26197 (2021)
2021
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., et al.: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
In: CVPR
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: CVPR. pp. 15180–15190 (2023)
2023
-
[10]
Remote sens- ing of Environment202, 18–27 (2017)
Gorelick, N., Hancher, M., Dixon, M., Ilyushchenko, S., Thau, D., Moore, R.: Google earth engine: Planetary-scale geospatial analysis for everyone. Remote sens- ing of Environment202, 18–27 (2017)
2017
-
[11]
IEEE Perva- sive computing7(4), 12–18 (2008)
Haklay, M., Weber, P.: Openstreetmap: User-generated street maps. IEEE Perva- sive computing7(4), 12–18 (2008)
2008
-
[12]
In: CVPR
Hänsch, R., Arndt, J., Lunga, D., Gibb, M., Pedelose, T., Boedihardjo, A., Petrie, D., Bacastow, T.M.: Spacenet 8-the detection of flooded roads and buildings. In: CVPR. pp. 1472–1480 (2022)
2022
-
[13]
In: CVPR
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: CVPR. pp. 9729–9738 (2020)
2020
-
[14]
In: CVPR
Hu, S., Feng, M., Nguyen, R.M., Lee, G.H.: Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization. In: CVPR. pp. 7258–7267 (2018)
2018
-
[15]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2025)
Huang, Z., Aryal, J., Nahavandi, S., Lu, X., Lim, C.P., Wei, L., Zhou, H.: Object- level cross-view geo-localization with location enhancement and multi-head cross attention. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2025)
2025
-
[16]
In: ICCV
Ju, H., Huang, S., Liu, S., Zheng, Z.: Video2bev: Transforming drone videos to bevs for video-based geo-localization. In: ICCV. pp. 27073–27083 (2025)
2025
-
[17]
In: ICCV
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: ICCV. pp. 4015–4026 (2023)
2023
-
[18]
In: ECCV
Law, H., Deng, J.: Cornernet: Detecting objects as paired keypoints. In: ECCV. pp. 734–750 (2018) Geometry-Aware Cross-View Object Geo-Localization 17
2018
-
[19]
In: ECCV
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: ECCV. pp. 71–91. Springer (2024)
2024
-
[20]
In: CVPR
Li, W., Lai, Y., Xu, L., Xiangli, Y., Yu, J., He, C., Xia, G.S., Lin, D.: Omnicity: Omnipotent city understanding with multi-level and multi-view images. In: CVPR. pp. 17397–17407 (2023)
2023
-
[21]
In: ICASSP
Li, Z., Yuan, X., Liu, W., Xu, X.: Vageo: View-specific attention for cross-view object geo-localization. In: ICASSP. pp. 1–5. IEEE (2025)
2025
-
[22]
IEEE TIP 31, 3780–3792 (2022)
Lin, J., Zheng, Z., Zhong, Z., Luo, Z., Li, S., Yang, Y., Sebe, N.: Joint represen- tation learning and keypoint detection for cross-view geo-localization. IEEE TIP 31, 3780–3792 (2022)
2022
-
[23]
In: CVPR
Lin, T.Y., Belongie, S., Hays, J.: Cross-view image geolocalization. In: CVPR. pp. 891–898 (2013)
2013
-
[24]
In: CVPR
Liu, L., Li, H.: Lending orientation to neural networks for cross-view geo- localization. In: CVPR. pp. 5624–5633 (2019)
2019
- [25]
-
[26]
In: 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR)
Mithun, N.C., Minhas, K.S., Chiu, H.P., Oskiper, T., Sizintsev, M., Samarasekera, S., Kumar, R.: Cross-view visual geo-localization for outdoor augmented reality. In: 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR). pp. 493–502. IEEE (2023)
2023
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
In: CVPR
Shi, Y., Li, H.: Beyond cross-view image retrieval: Highly accurate vehicle local- ization using satellite image. In: CVPR. pp. 17010–17020 (2022)
2022
-
[30]
NeurIPS32(2019)
Shi, Y., Liu, L., Yu, X., Li, H.: Spatial-aware feature aggregation for image based cross-view geo-localization. NeurIPS32(2019)
2019
-
[31]
In: ICLR (2022)
Song, H., Sun, D., Chun, S., Jampani, V., Han, D., Heo, B., Kim, W., Yang, M.H.: Vidt: An efficient and effective fully transformer-based object detector. In: ICLR (2022)
2022
-
[32]
IEEE TGRS61, 1–16 (2023)
Sun, Y., Ye, Y., Kang, J., Fernandez-Beltran, R., Feng, S., Li, X., Luo, C., Zhang, P., Plaza, A.: Cross-view object geo-localization in a local region with satellite imagery. IEEE TGRS61, 1–16 (2023)
2023
-
[33]
In: CVPR
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: CVPR. pp. 5294–5306 (2025)
2025
-
[34]
IEEE TCSVT32(2), 867–879 (2021)
Wang, T., Zheng, Z., Yan, C., Zhang, J., Sun, Y., Zheng, B., Yang, Y.: Each part matters: Local patterns facilitate cross-view geo-localization. IEEE TCSVT32(2), 867–879 (2021)
2021
-
[35]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π 3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
In: ICCV
Workman, S., Souvenir, R., Jacobs, N.: Wide-area image geolocalization with aerial reference imagery. In: ICCV. pp. 3961–3969 (2015)
2015
-
[37]
NeurIPS34, 29009–29020 (2021)
Yang, H., Lu, X., Zhu, Y.: Cross-view geo-localization with layer-to-layer trans- former. NeurIPS34, 29009–29020 (2021)
2021
-
[38]
In: CVPR
Zhai, M., Bessinger, Z., Workman, S., Jacobs, N.: Predicting ground-level scene layout from aerial imagery. In: CVPR. pp. 867–875 (2017) 18 L. Wang et al
2017
-
[39]
In: CVPR
Zhang, C., Wang, S.: Good at captioning bad at counting: Benchmarking gpt-4v on earth observation data. In: CVPR. pp. 7839–7849 (2024)
2024
-
[40]
In: ICCV
Zhang, Q., Zhu, Y.: Breaking rectangular shackles: Cross-view object segmentation for fine-grained object geo-localization. In: ICCV. pp. 8197–8206 (2025)
2025
-
[41]
arXiv preprint arXiv:2509.12757 (2025)
Zhang,X.,Cao,S.Y.,Bai,X.,Li,Y.,Shen,Z.,Wu,Z.,Hu,X.,Shen,H.l.:Recurrent cross-view object geo-localization. arXiv preprint arXiv:2509.12757 (2025)
-
[42]
IEEE TPAMI46(12), 10419–10433 (2024)
Zhang, X., Li, X., Sultani, W., Chen, C., Wshah, S.: Geodtr+: Toward generic cross-view geolocalization via geometric disentanglement. IEEE TPAMI46(12), 10419–10433 (2024)
2024
-
[43]
arXiv preprint arXiv:2511.22686 (2025)
Zhang, Y., Tung, J., Cai, R., Fouhey, D., Averbuch-Elor, H.: Emergent extreme- view geometry in 3d foundation models. arXiv preprint arXiv:2511.22686 (2025)
-
[44]
In: ACM MM
Zheng, Z., Wei, Y., Yang, Y.: University-1652: A multi-view multi-source bench- mark for drone-based geo-localization. In: ACM MM. pp. 1395–1403 (2020)
2020
-
[45]
In: CVPR
Zhu, S., Shah, M., Chen, C.: Transgeo: Transformer is all you need for cross-view image geo-localization. In: CVPR. pp. 1162–1171 (2022)
2022
-
[46]
In: CVPR
Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one- to-one retrieval. In: CVPR. pp. 3640–3649 (2021)
2021
-
[47]
arXiv preprint arXiv:2510.27139 (2025)
Zhu, X.L.Y.: Improving cross-view object geo-localization: A dual attention ap- proach with cross-view interaction and multi-scale spatial features. arXiv preprint arXiv:2510.27139 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.