LeVo 2: Stable and Melodious Song Generation via Hierarchical Representation Modeling and Progressive Post-Training
Pith reviewed 2026-06-30 04:18 UTC · model grok-4.3
The pith
LeVo 2 generates full-length songs by first planning with mixed tokens then refining vocal and accompaniment tracks separately through staged preference training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
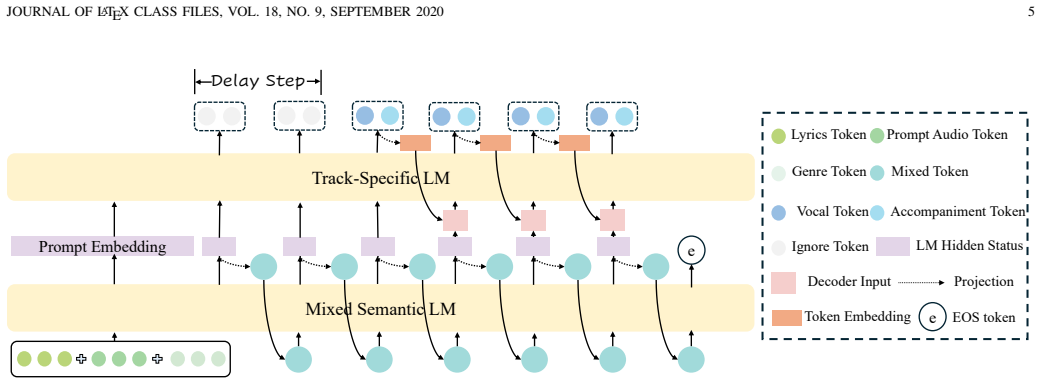
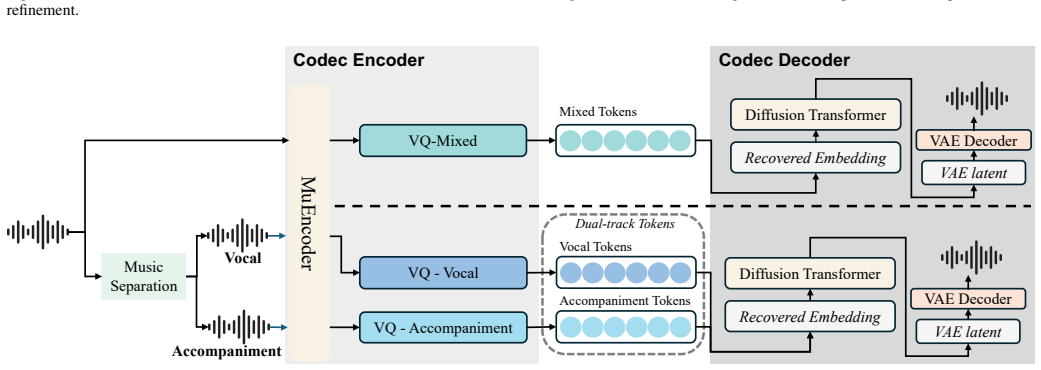
LeVo 2 is a hybrid LLM-Diffusion framework that formulates full-length song generation as hierarchical modeling: an LLM first predicts mixed tokens for semantic planning, then predicts vocal and accompaniment tokens in parallel for track-specific refinement, while a diffusion-based Music Codec reconstructs full-length waveforms. The central training contribution is an aesthetics-guided progressive post-training schedule that applies SFT, large-scale offline DPO, and closed-loop semi-online DPO, followed by modular extension of the Track-Specific LM. This schedule separates musicality learning, controllability alignment, and acoustic refinement to mitigate optimization conflicts and the limit
What carries the argument
Hierarchical LeLM token prediction that first produces mixed tokens then parallel vocal and accompaniment tokens, combined with the progressive post-training schedule of SFT followed by offline then semi-online DPO.
If this is right
- Expert listening tests show LeVo 2 outperforms open-source baselines across six subjective dimensions.
- The system approaches leading commercial systems on several listening metrics.
- Ablations confirm benefits from the training strategy, aesthetics guidance, scaling, and hierarchical architecture.
- The schedule mitigates limitations of static offline preference pairs by moving to closed-loop semi-online optimization.
- Modular extension trains track-specific refinement while preserving the already-aligned semantic planner.
Where Pith is reading between the lines
- The staged separation of objectives could extend to other multi-track generative tasks such as video or multi-instrument audio where global and local constraints compete.
- Automated aesthetic tiering in pre-training may lower the volume of human preference data needed for later alignment stages.
- If the hierarchy proves stable, similar layered token schemes might support even longer coherent outputs without proportional increases in sequence length.
Load-bearing premise
The progressive post-training schedule successfully separates musicality learning, controllability alignment, and acoustic refinement without introducing optimization conflicts.
What would settle it
A controlled experiment that measures musicality, controllability, and acoustic quality scores independently after each successive stage of post-training on the same set of prompts and checks whether gains remain additive or begin to conflict as song length increases.
Figures

read the original abstract
Full-length song generation must preserve coherence and musicality, render detailed vocal and accompaniment acoustics, and follow lyrics and prompts. Existing language model-based systems face a structural trade-off: mixed-token modeling preserves vocal-instrument coordination but obscures track-specific details, whereas dual-track prediction improves acoustics but requires longer sequences and weakens global planning. We present LeVo 2, a hybrid LLM-Diffusion framework for controllable full-length song generation. LeVo 2 formulates this trade-off as hierarchical modeling: LeLM first predicts mixed tokens for semantic planning, then predicts vocal and accompaniment tokens in parallel for track-specific refinement, while a diffusion-based Music Codec reconstructs full-length waveforms. A central contribution of this extended version is an aesthetics-guided training schedule for alignment. During pre-training, an automated music aesthetic evaluation framework assigns musicality-tier conditions to large-scale data, providing musicality priors before preference alignment. Progressive post-training applies SFT, large-scale offline DPO, and closed-loop semi-online DPO to separately improve generation quality, controllability, and musicality. Modular extension then trains the Track-Specific LM for acoustic refinement while preserving the aligned semantic planner. This schedule separates musicality learning, controllability alignment, and acoustic refinement, mitigating optimization conflict and the limitations of static offline preference pairs. Expert listening tests and objective evaluations show that LeVo 2 outperforms open-source baselines across six subjective dimensions, and approaches leading commercial systems on several listening metrics. Ablations validate the effects of the training strategy, aesthetics guidance, scaling, and hierarchical architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LeVo 2, a hybrid LLM-Diffusion framework for controllable full-length song generation. It addresses trade-offs in mixed-token vs. dual-track modeling via hierarchical representation: LeLM predicts mixed tokens for semantic planning then vocal/accompaniment tokens in parallel, with a diffusion-based Music Codec for waveform reconstruction. A key contribution is an aesthetics-guided progressive post-training schedule (SFT, large-scale offline DPO, closed-loop semi-online DPO) to separately improve quality, controllability, and musicality, followed by modular Track-Specific LM extension. Expert listening tests and objective metrics show outperformance over open-source baselines across six subjective dimensions and approaching commercial systems; ablations are said to validate the training strategy, aesthetics guidance, scaling, and architecture.
Significance. If the performance claims and ablation results hold under rigorous controls, the work would advance multi-objective alignment techniques for long-form audio generation by demonstrating a staged training approach that mitigates conflicts between musicality, controllability, and acoustic objectives. The automated aesthetic evaluation for priors and the hierarchical separation of planning from refinement represent practical contributions to stable song synthesis systems.
major comments (1)
- [Abstract (training schedule and ablation description)] The central claim that the progressive post-training schedule (SFT followed by offline DPO then semi-online DPO) successfully separates musicality learning, controllability alignment, and acoustic refinement without optimization conflicts rests on ablations that validate the training strategy. However, these ablations do not include an explicit joint-optimization baseline or quantitative conflict metrics (e.g., gradient interference or preference-pair staleness), making it impossible to isolate whether the staged schedule is required rather than incidental to the reported gains in listening tests.
minor comments (2)
- [Abstract] The abstract refers to 'six subjective dimensions' and 'several listening metrics' without naming them or providing effect sizes; this should be expanded with concrete metric names and numerical deltas in the results section for reproducibility.
- [Introduction / Method overview] Notation for the hierarchical components (LeLM, Music Codec, Track-Specific LM) is introduced without an accompanying diagram or equation defining the token flow and conditioning; a figure or formal definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the strength of evidence for our progressive post-training schedule. We address the concern below and agree that additional experiments will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract (training schedule and ablation description)] The central claim that the progressive post-training schedule (SFT followed by offline DPO then semi-online DPO) successfully separates musicality learning, controllability alignment, and acoustic refinement without optimization conflicts rests on ablations that validate the training strategy. However, these ablations do not include an explicit joint-optimization baseline or quantitative conflict metrics (e.g., gradient interference or preference-pair staleness), making it impossible to isolate whether the staged schedule is required rather than incidental to the reported gains in listening tests.
Authors: We agree that an explicit joint-optimization baseline would provide stronger isolation of the staged schedule's benefits. Our current ablations compare incremental stage additions (SFT, then +offline DPO, then +semi-online DPO) and show cumulative gains in listening tests, but they do not directly contrast against simultaneous joint optimization of all objectives. We will add a joint-optimization baseline experiment in the revision to report performance and any observed instabilities or conflicts. For quantitative conflict metrics such as gradient interference or preference-pair staleness, these are not standard in the field and are computationally expensive at our model scale; however, we will include an analysis of preference-pair staleness where feasible to address the referee's point. revision: yes
Circularity Check
No significant circularity; claims rest on external evaluations and ablations
full rationale
The paper's central claims rest on expert listening tests, objective metrics, and ablations that compare the progressive post-training schedule against alternatives. These are presented as independent empirical validations rather than quantities defined by the model's own fitted parameters or self-referential equations. No load-bearing step reduces a prediction to a fitted input by construction, invokes a self-citation uniqueness theorem, or renames a known result as a derivation. The hierarchical modeling and DPO stages are described as design choices whose benefits are measured externally, keeping the derivation self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Midinet: A convolutional generative adversarial network for symbolic-domain music generation,
L. Yang, S. Chou, and Y . Yang, “Midinet: A convolutional generative adversarial network for symbolic-domain music generation,” inProceed- ings of the 18th International Society for Music Information Retrieval Conference, ISMIR, pp. 324–331, 2017
2017
-
[2]
Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment,
H.-W. Dong, W.-Y . Hsiao, L.-C. Yang, and Y .-H. Yang, “Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, 2018
2018
-
[3]
A hierar- chical latent vector model for learning long-term structure in music,
A. Roberts, J. Engel, C. Raffel, C. Hawthorne, and D. Eck, “A hierar- chical latent vector model for learning long-term structure in music,” in International conference on machine learning, pp. 4364–4373, 2018
2018
-
[4]
Museformer: Transformer with fine-and coarse-grained atten- tion for music generation,
B. Yu, P. Lu, R. Wang, W. Hu, X. Tan, W. Ye, S. Zhang, T. Qin, and T.-Y . Liu, “Museformer: Transformer with fine-and coarse-grained atten- tion for music generation,”Advances in neural information processing systems, vol. 35, pp. 1376–1388, 2022
2022
-
[5]
Musiclm: Generating music from text,
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchi,et al., “Musiclm: Generating music from text,”arXiv preprint arXiv:2301.11325, 2023
Pith/arXiv arXiv 2023
-
[6]
Moˆusai: Text-to-music genera- tion with long-context latent diffusion,
F. Schneider, Z. Jin, and B. Sch ¨olkopf, “Moˆusai: Text-to-music genera- tion with long-context latent diffusion,”arXiv e-prints, pp. arXiv–2301, 2023
2023
-
[7]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. D ´efossez, “Simple and controllable music generation,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[8]
Efficient neural music generation,
M. W. Lam, Q. Tian, T. Li, Z. Yin, S. Feng, M. Tu, Y . Ji, R. Xia, M. Ma, X. Song,et al., “Efficient neural music generation,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[9]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization,
N. Majumder, C.-Y . Hung, D. Ghosal, W.-N. Hsu, R. Mihalcea, and S. Poria, “Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization,” inProceedings of the 32nd ACM International Conference on Multimedia, pp. 564–572, 2024
2024
-
[10]
Hifisinger: To- wards high-fidelity neural singing voice synthesis,
J. Chen, X. Tan, J. Luan, T. Qin, and T.-Y . Liu, “Hifisinger: To- wards high-fidelity neural singing voice synthesis,”arXiv preprint arXiv:2009.01776, 2020
arXiv 2009
-
[11]
Singgan: Generative adversarial network for high-fidelity singing voice generation,
R. Huang, C. Cui, F. Chen, Y . Ren, J. Liu, Z. Zhao, B. Huai, and Z. Wang, “Singgan: Generative adversarial network for high-fidelity singing voice generation,” inProceedings of the 30th ACM International Conference on Multimedia, pp. 2525–2535, 2022
2022
-
[12]
Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,
Y . Zhang, J. Cong, H. Xue, L. Xie, P. Zhu, and M. Bi, “Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7237–7241, 2022
2022
-
[13]
Diffsinger: Singing voice synthesis via shallow diffusion mechanism,
J. Liu, C. Li, Y . Ren, F. Chen, and Z. Zhao, “Diffsinger: Singing voice synthesis via shallow diffusion mechanism,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, pp. 11020–11028, 2022
2022
-
[14]
Unisinger: Unified end-to-end singing voice synthesis with cross- modality information matching,
Z. Hong, C. Cui, R. Huang, L. Zhang, J. Liu, J. He, and Z. Zhao, “Unisinger: Unified end-to-end singing voice synthesis with cross- modality information matching,” inProceedings of the 31st ACM International Conference on Multimedia, pp. 7569–7579, 2023
2023
-
[15]
Jukebox: A generative model for music,
P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: A generative model for music,”arXiv preprint arXiv:2005.00341, 2020. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 12
Pith/arXiv arXiv 2005
-
[16]
Songcreator: Lyrics-based universal song generation,
S. Lei, Y . Zhou, B. Tang, M. W. Lam, H. Liu, J. Wu, S. Kang, Z. Wu, H. Meng,et al., “Songcreator: Lyrics-based universal song generation,” Advances in Neural Information Processing Systems, vol. 37, pp. 80107– 80140, 2024
2024
-
[17]
Analyzable chain-of-musical-thought prompting for high-fidelity music generation,
M. W. Lam, Y . Xing, W. You, J. Wu, Z. Yin, F. Jiang, H. Liu, F. Liu, X. Li, W.-T. Lu,et al., “Analyzable chain-of-musical-thought prompting for high-fidelity music generation,”arXiv preprint arXiv:2503.19611, 2025
arXiv 2025
-
[18]
Songbloom: Coherent song generation via interleaved autoregressive sketching and diffusion refinement,
C. Yang, S. Wang, H. Chen, W. Tan, J. Yu, and H. Li, “Songbloom: Coherent song generation via interleaved autoregressive sketching and diffusion refinement,”Advances in Neural Information Processing Sys- tems, 2025
2025
-
[19]
Muse: Towards reproducible long- form song generation with fine-grained style control,
C. Jiang, J. Chen, Z. Xiang, Z. Yang, H. Wang, J. Zhuang, X. Che, J. Sun, H. Li, Y . Cao,et al., “Muse: Towards reproducible long- form song generation with fine-grained style control,”arXiv preprint arXiv:2601.03973, 2026
arXiv 2026
-
[20]
Heartmula: A family of open sourced music foundation models,
D. Yang, Y . Xie, Y . Yin, Z. Wang, X. Yi, G. Zhu, X. Weng, Z. Xiong, Y . Ma, D. Cong,et al., “Heartmula: A family of open sourced music foundation models,”arXiv preprint arXiv:2601.10547, 2026
arXiv 2026
-
[21]
Yue: Scaling open foundation models for long- form music generation,
R. Yuan, H. Lin, S. Guo, G. Zhang, J. Pan, Y . Zang, H. Liu, Y . Liang, W. Ma, X. Du,et al., “Yue: Scaling open foundation models for long- form music generation,”arXiv preprint arXiv:2503.08638, 2025
arXiv 2025
-
[22]
Songgen: A single stage auto-regressive transformer for text-to-song generation,
Z. Liu, S. Ding, Z. Zhang, X. Dong, P. Zhang, Y . Zang, Y . Cao, D. Lin, and J. Wang, “Songgen: A single stage auto-regressive transformer for text-to-song generation,”arXiv preprint arXiv:2502.13128, 2025
arXiv 2025
-
[23]
Z. Ning, H. Chen, Y . Jiang, C. Hao, G. Ma, S. Wang, J. Yao, and L. Xie, “Diffrhythm: Blazingly fast and embarrassingly simple end-to- end full-length song generation with latent diffusion,”arXiv preprint arXiv:2503.01183, 2025
arXiv 2025
-
[24]
Diffrhythm+: Controllable and flexible full- length song generation with preference optimization,
H. Chen, Y . Jiang, G. Ma, C. Hao, S. Wang, J. Yao, Z. Ning, M. Meng, J. Luan, and L. Xie, “Diffrhythm+: Controllable and flexible full- length song generation with preference optimization,”arXiv preprint arXiv:2507.12890, 2025
arXiv 2025
-
[25]
Diffrhythm 2: Efficient and high fidelity song generation via block flow matching,
Y . Jiang, H. Chen, Z. Ning, J. Yao, Z. Han, D. Wu, M. Meng, J. Luan, Z. Fu, and L. Xie, “Diffrhythm 2: Efficient and high fidelity song generation via block flow matching,”arXiv preprint arXiv:2510.22950, 2025
arXiv 2025
-
[26]
Ace-step: A step towards music generation foundation model,
J. Gong, S. Zhao, S. Wang, S. Xu, and J. Guo, “Ace-step: A step towards music generation foundation model,”arXiv preprint arXiv:2506.00045, 2025
arXiv 2025
-
[27]
Ace-step 1.5: Pushing the boundaries of open-source music generation,
J. Gong, Y . Song, W. Zhao, S. Wang, S. Xu, and J. Guo, “Ace-step 1.5: Pushing the boundaries of open-source music generation,”arXiv preprint arXiv:2602.00744, 2026
arXiv 2026
-
[28]
Suno v5,
Suno team, “Suno v5,”URL https://suno.com/, 2025
2025
-
[29]
Udio team, “Udio,”URL https://www.udio.com/song-builder, 2024
2024
-
[30]
Mureka v8,
Mureka team, “Mureka v8,”URL https://www.mureka.ai, 2025
2025
-
[31]
Minimax music 2.5,
MiniMax team, “Minimax music 2.5,”URL https://www.minimax.io/audio/music, 2025
2025
-
[32]
Levo: High-quality song generation with multi- preference alignment,
S. Lei, Y . Xu, H. Zhang, H. Chen, Y . Zhang, C. Yang, H. Zhu, S. Wang, Z. Wu, D. Yu,et al., “Levo: High-quality song generation with multi- preference alignment,”The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[33]
A Multi-Scale Attentive Transformer for Multi-Instrument Symbolic Music Genera- tion,
X. Wei, J. Chen, Z. Zheng, L. Guo, L. Li, and D. Wang, “A Multi-Scale Attentive Transformer for Multi-Instrument Symbolic Music Genera- tion,” inProc. INTERSPEECH 2023, pp. 5391–5395, 2023
2023
-
[34]
Lamda: Language models for dialog applications,
R. Thoppilan, D. De Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.- T. Cheng, A. Jin, T. Bos, L. Baker, Y . Du,et al., “Lamda: Language models for dialog applications,”arXiv preprint arXiv:2201.08239, 2022
Pith/arXiv arXiv 2022
-
[35]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat,et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[36]
Llama: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar,et al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[37]
Audiolm: a language modeling approach to audio generation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Shar- ifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi,et al., “Audiolm: a language modeling approach to audio generation,”IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, 2023
2023
-
[38]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyals,et al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[39]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021
2021
-
[40]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, pp. 27980–27993, 2023
2023
-
[41]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 4195–4205, 2023
2023
-
[42]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022
2022
-
[43]
Audioldm 2: Learning holis- tic audio generation with self-supervised pretraining,
H. Liu, Q. Tian, Y . Yuan, X. Liu, X. Mei, Q. Kong, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holis- tic audio generation with self-supervised pretraining,”arXiv preprint arXiv:2308.05734, 2023
arXiv 2023
-
[44]
Text-to-song: Towards controllable music generation incor- porating vocal and accompaniment,
Z. Hong, R. Huang, X. Cheng, Y . Wang, R. Li, F. You, Z. Zhao, and Z. Zhang, “Text-to-song: Towards controllable music generation incor- porating vocal and accompaniment,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6248–6261, 2024
2024
-
[45]
Accompanied singing voice synthesis with fully text- controlled melody,
R. Li, Z. Hong, Y . Wang, L. Zhang, R. Huang, S. Zheng, and Z. Zhao, “Accompanied singing voice synthesis with fully text- controlled melody,”arXiv preprint arXiv:2407.02049, 2024
arXiv 2024
-
[46]
Baton: aligning text-to-audio model using human preference feedback,
H. Liao, H. Han, K. Yang, T. Du, R. Yang, Q. Xu, Z. Xu, J. Liu, J. Lu, and X. Li, “Baton: aligning text-to-audio model using human preference feedback,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pp. 4542–4550, 2024
2024
-
[47]
Musicrl: Aligning music generation to human preferences,
G. Cideron, S. Girgin, M. Verzetti, D. Vincent, M. Kastelic, Z. Borsos, B. Mcwilliams, V . Ungureanu, O. Bachem, O. Pietquin,et al., “Musicrl: Aligning music generation to human preferences,” inInternational Conference on Machine Learning, pp. 8968–8984, PMLR, 2024
2024
-
[48]
Mu- codec: Ultra low-bitrate music codec,
Y . Xu, H. Chen, J. Yu, W. Tan, R. Gu, S. Lei, Z. Lin, and Z. Wu, “Mu- codec: Ultra low-bitrate music codec,”arXiv preprint arXiv:2409.13216, 2024
arXiv 2024
-
[49]
Songeval: A benchmark dataset for song aesthetics evaluation,
J. Yao, G. Ma, H. Xue, H. Chen, C. Hao, Y . Jiang, H. Liu, R. Yuan, J. Xu, W. Xue,et al., “Songeval: A benchmark dataset for song aesthetics evaluation,”arXiv preprint arXiv:2505.10793, 2025
arXiv 2025
-
[50]
Muq: Self-supervised music representation learning with mel residual vector quantization,
H. Zhu, Y . Zhou, H. Chen, J. Yu, Z. Ma, R. Gu, Y . Luo, W. Tan, and X. Chen, “Muq: Self-supervised music representation learning with mel residual vector quantization,”IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[51]
Bridging offline and online reinforcement learning for llms,
J. Lanchantin, A. Chen, J. Lan, X. Li, S. Saha, T. Wang, J. Xu, P. Yu, W. Yuan, J. E. Weston,et al., “Bridging offline and online reinforcement learning for llms,”arXiv preprint arXiv:2506.21495, 2025
arXiv 2025
-
[52]
W. Tan, S. Lei, H. Zhang, G. Li, Y . Zhang, H. Chen, J. Yu, R. Gu, and D. Yu, “Songprep: A preprocessing framework and end-to-end model for full-song structure parsing and lyrics transcription,”arXiv preprint arXiv:2509.17404, 2025
arXiv 2025
-
[53]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin,et al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
Pith/arXiv arXiv 2024
-
[54]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei,et al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.