When Does Learning to Stop Help? A Cost-Aware Study of Early Exits in Reasoning Models
Pith reviewed 2026-07-01 01:48 UTC · model grok-4.3
The pith
Learned multi-feature stopping improves the accuracy frontier on free-form math reasoning tasks but is matched or beaten by scalar confidence and entropy rules on multiple-choice and very hard tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
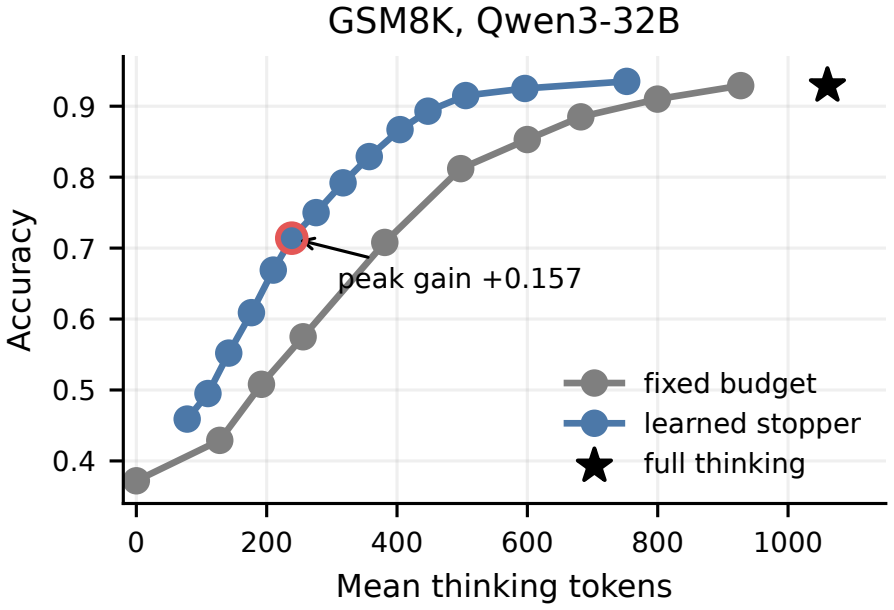
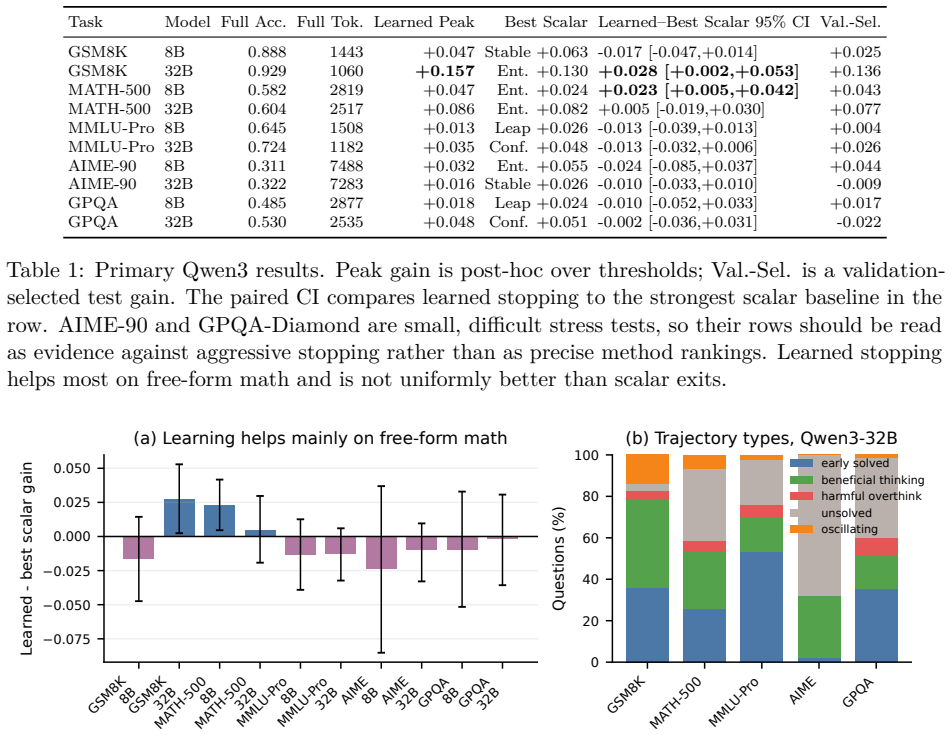
Learned stopping from online prefix features raises the fixed-budget performance frontier on free-form math tasks such as GSM8K, where post-hoc peak adapt gain reaches +0.157 and validation-selected points preserve positive gains with a paired improvement of +0.028 over the strongest scalar baseline; the same approach shows no consistent advantage on multiple-choice and very hard settings, where scalar confidence, entropy, or stability rules are competitive or stronger.
What carries the argument
LearnStop, a hidden-state-free checkpoint stopper that at fixed-budget points probes a short answer from the current reasoning prefix and predicts its eventual correctness from online features including answer confidence, entropy, prefix vote share, answer stability, and backtracking-marker density.
If this is right
- On free-form math, multi-feature stopping can raise the accuracy frontier at fixed compute.
- Validation-selected operating points preserve positive adaptive gains on tasks where scalar signals are weak.
- On multiple-choice and very hard problems, scalar thresholds already solve most of the stopping problem.
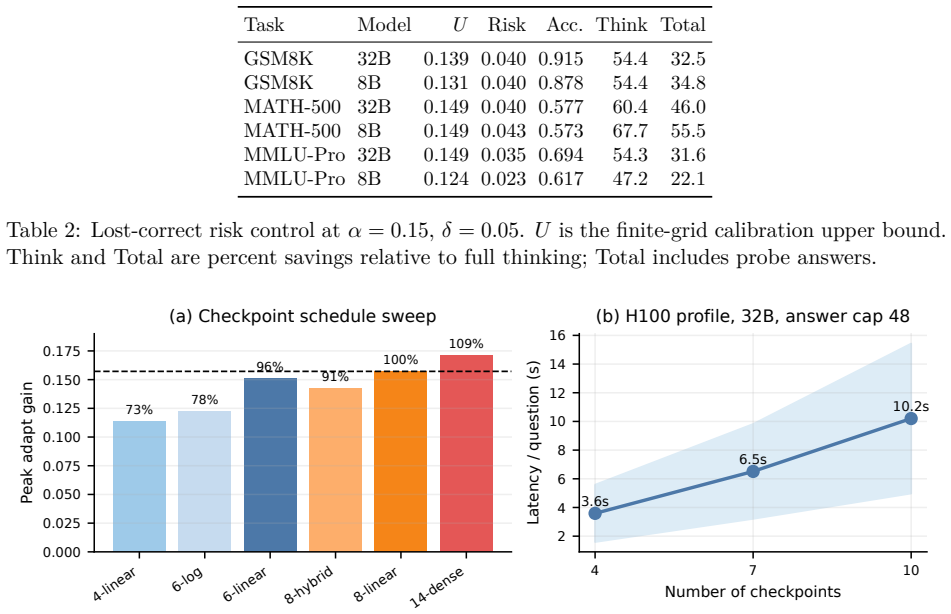
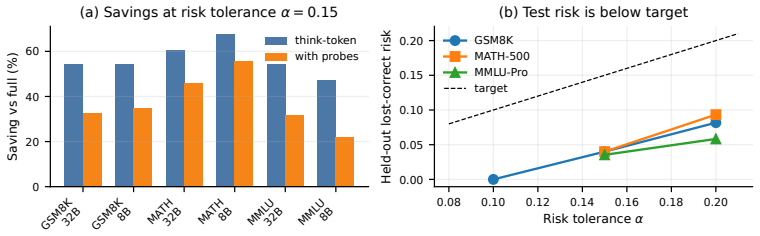
- Cost accounting under KV-fork, prefix-cache, and black-box regimes shows the practical overhead of learned stopping is modest when the accuracy gain materializes.
Where Pith is reading between the lines
- The result implies that stopping-rule design should begin with a check for whether any single scalar already captures most of the useful trajectory variation.
- If the pattern holds, future work could test whether adding a small set of task-type indicators lets a single system switch between learned and scalar modes automatically.
- The absence of hidden-state features in LearnStop leaves open whether richer internal representations would extend the regime where learned stopping helps.
Load-bearing premise
The online features extracted from the reasoning prefix are predictive of whether that prefix will produce a correct final answer.
What would settle it
A paired bootstrap test on GSM8K with Qwen3-32B showing that validation-selected LearnStop points produce no positive gain over the strongest scalar baseline.
Figures
read the original abstract
Reasoning models spend different amounts of useful computation across instances, but it remains unclear when a learned stopping rule improves over simple confidence or convergence thresholds. We study this question with LearnStop, a hidden-state-free checkpoint stopper for reasoning language models. At fixed budget checkpoints, LearnStop probes a short answer from the current reasoning prefix and predicts prefix correctness from online features such as answer confidence, entropy, prefix vote share, answer stability, and backtracking-marker density. Across 18 task-model settings spanning GSM8K, MATH-500, MMLU-Pro, AIME-90, GPQA, Qwen3, and DeepSeek-R1 distillations, the answer is task-dependent. On free-form math, learned multi-feature stopping improves the fixed-budget frontier and often beats scalar exits: on GSM8K with Qwen3-32B, the empirical frontier reaches a post-hoc peak adapt gain of +0.157, validation-selected operating points preserve positive gains, and the paired gain over the strongest scalar baseline is +0.028. On multiple-choice and very hard settings, scalar confidence, entropy, or stability rules are competitive or stronger. We therefore frame learned stopping not as a universal replacement for scalar exits, but as a tool whose value depends on trajectory structure. We further provide validation-selected operating points, paired bootstrap tests, finite-grid lost-correct risk calibration, cost accounting under KV-fork, prefix-cache, and black-box regimes, H100 serving profiles, checkpoint-schedule sweeps, transfer analyses, and robustness checks. The main practical finding is that learned stopping is useful when many questions become correct before full budget but do not exhibit a single reliable scalar stopping signal; its benefits largely disappear when confidence or answer convergence already solves the stopping problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LearnStop, a hidden-state-free early-exit method for reasoning LLMs. At fixed checkpoints it probes a short answer from the current prefix and trains a predictor on online features (answer confidence, entropy, prefix vote share, answer stability, backtracking-marker density) to decide whether to stop. Across 18 task-model combinations the authors report that multi-feature learned stopping improves the fixed-budget accuracy frontier on free-form math (e.g., GSM8K/Qwen3-32B post-hoc peak adapt gain +0.157, validation-selected paired gain over strongest scalar baseline +0.028) while scalar confidence/entropy/stability rules remain competitive on multiple-choice and very-hard settings. The work supplies validation-selected operating points, paired bootstrap tests, lost-correct risk calibration, cost accounting under KV-fork/prefix-cache/black-box regimes, H100 profiles, and transfer/robustness checks, concluding that learned stopping is useful precisely when many instances become correct before full budget yet lack a single reliable scalar signal.
Significance. If the cost accounting is shown to be net of probe tokens, the paper supplies a concrete, task-dependent empirical map of when learned early exits add value over scalar thresholds in reasoning models. The provision of paired bootstrap tests, regime-specific cost profiles, and validation-selected points strengthens reproducibility and practical utility; the finding that benefits largely vanish once scalar convergence already solves the stopping problem is a useful negative result for the field.
major comments (1)
- [Cost accounting under KV-fork, prefix-cache, and black-box regimes] Cost-accounting sections (regimes discussion and H100 profiles): the reported adapt gains (+0.157 post-hoc peak, +0.028 paired) are computed under a fixed token budget, yet the manuscript does not explicitly state that the tokens consumed by the short-answer probes are debited from that budget in the black-box regime. Because scalar baselines incur zero extra generation cost, failure to subtract probe tokens would systematically overstate LearnStop’s efficiency advantage; a table or paragraph showing net token counts (including probes) for each operating point is required to support the central cost-aware claims.
minor comments (2)
- [Abstract] Abstract: the description of LearnStop training procedure, exact feature definitions, and the precise controls used for the scalar baselines could be expanded by one sentence each to improve standalone readability.
- The paper mentions “finite-grid lost-correct risk calibration” but does not cite the specific table or figure that reports the calibration curves; adding the reference would aid verification.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for explicit cost accounting. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Cost accounting under KV-fork, prefix-cache, and black-box regimes] Cost-accounting sections (regimes discussion and H100 profiles): the reported adapt gains (+0.157 post-hoc peak, +0.028 paired) are computed under a fixed token budget, yet the manuscript does not explicitly state that the tokens consumed by the short-answer probes are debited from that budget in the black-box regime. Because scalar baselines incur zero extra generation cost, failure to subtract probe tokens would systematically overstate LearnStop’s efficiency advantage; a table or paragraph showing net token counts (including probes) for each operating point is required to support the central cost-aware claims.
Authors: We agree that the treatment of probe tokens must be stated unambiguously. In the black-box regime the fixed token budget is defined as the total number of tokens generated by the model (including all short-answer probes), so the reported gains already reflect net cost after probes. In the KV-fork and prefix-cache regimes the probe cost is zero or negligible because the prefix is reused. We will add an explicit paragraph in the cost-accounting section and a supplementary table that lists, for each operating point and regime, (i) gross tokens, (ii) probe tokens, and (iii) net tokens after probes, together with the corresponding accuracy. This will make the comparison with scalar baselines transparent and remove any ambiguity. revision: yes
Circularity Check
Empirical comparisons with no circular derivations
full rationale
The paper reports direct experimental results from held-out evaluations across 18 task-model settings, using validation-selected operating points, paired bootstrap tests, and explicit cost accounting under multiple regimes. No equations or claims reduce a 'prediction' or 'first-principles result' to fitted inputs by construction, and there are no load-bearing self-citations or uniqueness theorems. All reported gains (e.g., +0.157 post-hoc peak adapt gain) are measured outcomes on external benchmarks rather than self-referential definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- LearnStop predictor weights
Reference graph
Works this paper leans on
-
[1]
AI-MO/aimo-validation-aime, 2024
AI-MO. AI-MO/aimo-validation-aime, 2024. URLhttps://huggingface.co/datasets/AI- MO/aimo-validation-aime. Hugging Face dataset containing AIME 2022–2024 problems
2024
-
[2]
Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster
Anastasios N. Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Confor- mal risk control. InInternational Conference on Learning Representations, 2024
2024
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025. 15
2025
-
[5]
Rosing, Ion Stoica, and Hao Zhang
Yichao Fu, Junda Chen, Siqi Zhu, Zheyu Fu, Zhongdongming Dai, Yonghao Zhuang, Yian Ma, Aurick Qiao, Tajana S. Rosing, Ion Stoica, and Hao Zhang. Efficiently scal- ing LLM reasoning programs with Certaindex. InAdvances in Neural Information Pro- cessing Systems, 2025. URL https://papers.nips.cc/paper_files/paper/2025/hash/ d037fd021c9aace128b8ce25001cdb6c-...
2025
-
[6]
Token-Budget-Aware LLM Reasoning
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. Token-budget-aware LLM reasoning. InFindings of the Association for Computational Lin- guistics: ACL 2025, pages 24842–24855, 2025. doi: 10.18653/v1/2025.findings-acl.1274
-
[7]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems, 2021
2021
-
[8]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, 2024. URL https://openreview.net/ forum?id=v8L0pN6EOi
2024
-
[9]
MAA invitational competitions: American invitational mathematics examination, 2026
Mathematical Association of America. MAA invitational competitions: American invitational mathematics examination, 2026. URLhttps://maa.org/maa-invitational-competitions/
2026
-
[10]
Stop when reasoning converges: Semantic-preserving early exit for reasoning models, 2026
Dehai Min, Giovanni Vaccarino, Huiyi Chen, Yongliang Wu, Gal Yona, and Lu Cheng. Stop when reasoning converges: Semantic-preserving early exit for reasoning models, 2026
2026
-
[11]
s1: Simple test-time scaling , booktitle =
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20275–20321, 2025. doi: 10.18653/v1/2025.emnlp-main.1025. URL htt...
-
[12]
TERMINATOR: Learning optimal exit points for early stopping in chain-of- thought reasoning, 2026
Alliot Nagle, Jakhongir Saydaliev, Dhia Garbaya, Michael Gastpar, Ashok Vardhan Makkuva, and Hyeji Kim. TERMINATOR: Learning optimal exit points for early stopping in chain-of- thought reasoning, 2026
2026
-
[13]
Conformal language modeling
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi Jaakkola, and Regina Barzilay. Conformal language modeling. InInternational Conference on Learning Representations, 2024
2024
-
[14]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[15]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark, 2023
2023
-
[16]
Oseledets, and Elena Tutubalina
Pavel Tikhonov, Ivan V. Oseledets, and Elena Tutubalina. Confidence leaps in LLM reasoning: Early stopping and cross-model transfer. InProceedings of the 2026 Conference of the European Chapter of the Association for Computational Linguistics: Short Papers, 2026
2026
-
[17]
Entropy after </Think> for reasoning model early exiting, 2025
Xi Wang, James McInerney, Lequn Wang, and Nathan Kallus. Entropy after </Think> for reasoning model early exiting, 2025. 16
2025
-
[18]
Conformal thinking: Risk control for reasoning on a compute budget, 2026
Xi Wang, Anushri Suresh, Alvin Zhang, Rishi More, William Jurayj, Benjamin Van Durme, Mehrdad Farajtabar, Daniel Khashabi, and Eric Nalisnick. Conformal thinking: Risk control for reasoning on a compute budget, 2026
2026
-
[19]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems Datasets ...
2024
-
[20]
Thought calibration: Efficient and confident test-time scaling
Menghua Wu, Cai Zhou, Stephen Bates, and Tommi Jaakkola. Thought calibration: Efficient and confident test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[21]
Dynamic early exit in reasoning models
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Qiaowei Li, Minghui Chen, Zheng Lin, and Weiping Wang. Dynamic early exit in reasoning models. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id= NpU7ZXafRi. 17
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.