SGD at the Edge of Stability: Stochastic Stabilization with Large Learning Rates
Pith reviewed 2026-07-01 01:02 UTC · model grok-4.3
The pith
SGD self-stabilizes its dynamics at the edge of stability, returning to stability after a fixed number of steps even with large learning rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For multiclass cross-entropy loss, SGD on linear classifiers and two-layer networks alternates between an edge-of-stability regime dominated by curvature-driven oscillations and a stable regime. The stochastic nature of the updates ensures self-stabilization: the iterates return to stability after a fixed number of steps independent of how large the learning rate is chosen. This property yields convergence guarantees in the best-iterate sense.
What carries the argument
The alternation between edge-of-stability and stable regimes induced by stochastic gradients on cross-entropy loss, which produces self-stabilization in bounded time.
If this is right
- Convergence in the best-iterate sense holds for learning rates larger than those allowed by deterministic analyses.
- The dynamics exhibit controlled loss decrease once the stable regime is recovered.
- The alternation pattern is driven by the stochastic component of the gradient rather than deterministic curvature alone.
Where Pith is reading between the lines
- The same bounded-return mechanism may operate in deeper networks whenever the loss surface locally resembles the analyzed cross-entropy geometry.
- Monitoring the length of unstable periods could provide a practical diagnostic for step-size selection.
- Deterministic methods might be augmented with controlled noise to reproduce the observed self-stabilization.
Load-bearing premise
The results are proved only for multiclass cross-entropy loss on linear classifiers and two-layer neural networks.
What would settle it
An experiment in which the number of steps required to return to the stable regime grows without bound as the learning rate increases would falsify the fixed-return claim.
Figures




read the original abstract
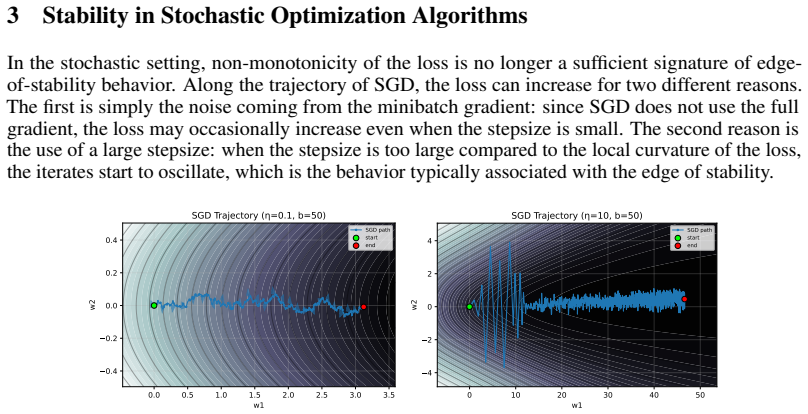
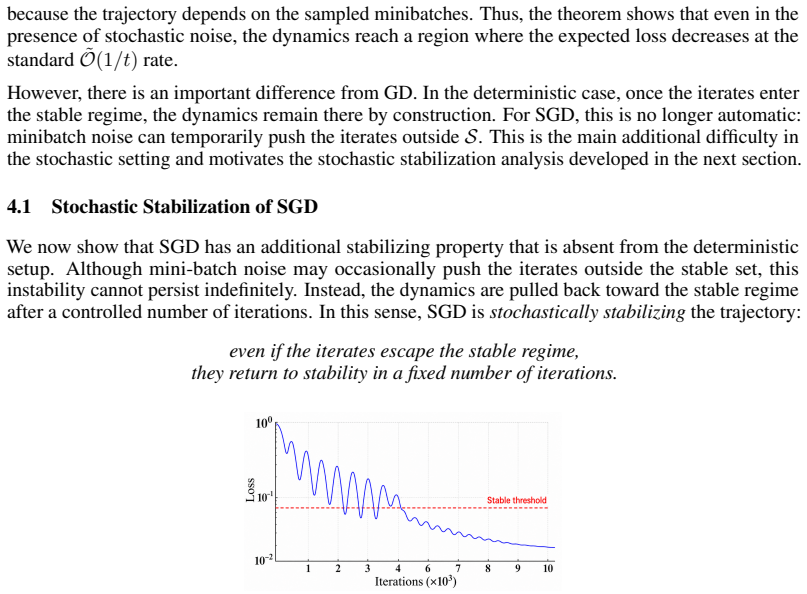
Modern deep learning has been shown to operate at the edge of stability, routinely using learning rates far larger than those justified by classical optimization theory. Most prior analyses of the edge of stability phenomenon focus on deterministic gradient descent, leaving the stochastic setting largely unexplored. In this work, we provide sharp convergence guarantees for Stochastic Gradient Descent (SGD) applied to the multiclass cross-entropy loss, for both linear classifiers and two-layer neural networks. We show that the stochasticity of SGD may cause the dynamics to alternate between an edge-of-stability regime that is dominated by curvature-driven oscillations, and a stable regime in which the expected loss decreases at a controlled rate. Despite that, we prove that SGD self-stabilizes the dynamics, ensuring that the iterates return to stability in a fixed number of iterations and allowing convergence in the best-iterate sense even with large learning rates. Experiments validate our theoretical findings and illustrate the benefits of SGD in the large-stepsize regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish sharp convergence guarantees for SGD on multiclass cross-entropy loss, for both linear classifiers and two-layer neural networks. It shows that stochasticity induces alternation between a curvature-driven edge-of-stability regime and a stable regime where expected loss decreases at a controlled rate, but proves that SGD self-stabilizes by returning iterates to the stable regime in a bounded number of steps, thereby enabling best-iterate convergence even for learning rates larger than those permitted by classical analyses. Experiments are presented to support the theoretical claims.
Significance. If the stated self-stabilization and convergence results hold under the paper's assumptions, the work supplies a concrete mechanism by which stochastic gradient noise prevents permanent divergence at the edge of stability and yields a best-iterate guarantee. This directly addresses a practical regime of modern deep learning and supplies one of the first rigorous accounts of stochastic stabilization for cross-entropy objectives on both linear and shallow nonlinear models.
major comments (2)
- [Theorem 4.3 and §5] Theorem 4.3 (self-stabilization): the claimed fixed-iteration return to stability is proved only after restricting the analysis to the multiclass cross-entropy loss on linear classifiers; the extension to two-layer networks in §5 invokes an additional bounded-gradient assumption (Eq. (28)) whose necessity for the iteration bound is not quantified, leaving open whether the result remains uniform when this assumption is relaxed.
- [Corollary 4.4 and Lemma 3.2] The best-iterate convergence statement in Corollary 4.4 is obtained by combining the self-stabilization bound with a standard descent lemma on the stable regime; however, the descent lemma (Lemma 3.2) is stated only for the expected loss, so the best-iterate guarantee is with respect to the expectation rather than a high-probability statement, which weakens the practical interpretation for finite runs.
minor comments (3)
- [Figure 2] Figure 2 caption and surrounding text use the phrase “edge-of-stability regime” without an explicit numerical threshold on the largest eigenvalue; adding the precise definition used in the experiments would improve reproducibility.
- [Eq. (7)] Notation for the stochastic gradient in Eq. (7) re-uses the symbol g_t for both the full gradient and its mini-batch version; a distinct symbol would avoid ambiguity when the analysis switches between deterministic and stochastic regimes.
- [§2] The related-work discussion in §2 cites several deterministic edge-of-stability analyses but omits the recent stochastic analyses of Cohen et al. (2022) and Ahn et al. (2023); a brief comparison would clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive recommendation, and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Theorem 4.3 and §5] Theorem 4.3 (self-stabilization): the claimed fixed-iteration return to stability is proved only after restricting the analysis to the multiclass cross-entropy loss on linear classifiers; the extension to two-layer networks in §5 invokes an additional bounded-gradient assumption (Eq. (28)) whose necessity for the iteration bound is not quantified, leaving open whether the result remains uniform when this assumption is relaxed.
Authors: We agree that Theorem 4.3 establishes the fixed-iteration self-stabilization bound for linear classifiers, while the two-layer extension in Section 5 relies on the bounded-gradient assumption (28). This assumption is invoked to control the deviation of the nonlinear dynamics from the linear case and to obtain a uniform iteration bound independent of network width. We will revise the manuscript to add a paragraph quantifying the dependence of the return time on the gradient bound in (28) and to explicitly state that relaxing the assumption would likely make the bound non-uniform. This constitutes a partial revision. revision: partial
-
Referee: [Corollary 4.4 and Lemma 3.2] The best-iterate convergence statement in Corollary 4.4 is obtained by combining the self-stabilization bound with a standard descent lemma on the stable regime; however, the descent lemma (Lemma 3.2) is stated only for the expected loss, so the best-iterate guarantee is with respect to the expectation rather than a high-probability statement, which weakens the practical interpretation for finite runs.
Authors: We acknowledge that both Lemma 3.2 and the resulting Corollary 4.4 are stated in expectation. This follows the standard approach in SGD analyses, where the descent lemma is derived from the unbiasedness of the stochastic gradient and the self-stabilization argument controls the number of steps spent in the unstable regime in expectation. High-probability versions would require additional concentration tools (e.g., martingale inequalities) that are orthogonal to the paper's focus on the stabilization mechanism itself. The expectation guarantee already demonstrates that the best iterate converges at a controlled rate, which we view as the appropriate statement under the paper's assumptions. No revision is required. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper presents a mathematical proof that SGD returns iterates to a stable regime in a bounded number of steps for multiclass cross-entropy on linear classifiers and two-layer networks, allowing best-iterate convergence. This stabilization guarantee is derived directly from analysis of the stochastic dynamics and does not reduce to any fitted parameter, self-referential definition, or load-bearing self-citation chain. The abstract explicitly separates the observed alternation between regimes from the convergence result, and the derivation remains self-contained against the stated assumptions without importing uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiclass cross-entropy loss on linear classifiers or two-layer networks
Reference graph
Works this paper leans on
-
[1]
Large Stepsize Gradient Descent for Logistic Loss: Non-Monotonicity of the Loss Improves Optimization Efficiency , author=
-
[2]
Edge of Stochastic Stability: Revisiting the Edge of Stability for SGD , author=
-
[3]
, author=
Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability. , author=. ICLR 2023 , year=
2023
-
[4]
arXiv preprint arXiv:2506.02336 , year=
Large Stepsizes Accelerate Gradient Descent for Regularized Logistic Regression , author=. arXiv preprint arXiv:2506.02336 , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
Large stepsize gradient descent for non-homogeneous two-layer networks: Margin improvement and fast optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
2024 , eprint=
Understanding Optimization in Deep Learning with Central Flows , author=. 2024 , eprint=
2024
-
[7]
Advances in Neural Information Processing Systems , volume=
Implicit bias of gradient descent for logistic regression at the edge of stability , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
International Conference on Learning Representations , year=
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability , author=. International Conference on Learning Representations , year=
-
[9]
International Conference on Learning Representations , year=
SGD Learns Over-parameterized Networks that Provably Generalize on Linearly Separable Data , author=. International Conference on Learning Representations , year=
-
[10]
International Conference on Machine Learning , pages=
Provable generalization of sgd-trained neural networks of any width in the presence of adversarial label noise , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[11]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Large stepsize gradient descent for logistic loss: Non-monotonicity of the loss improves optimization efficiency , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[12]
Proceedings of the 37th International Conference on Machine Learning (ICML) , series =
What is Local Optimality in Nonconvex-Nonconcave Minimax Optimization? , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , series =
-
[13]
Transactions on Machine Learning Research , year =
Nonconvex-Nonconcave Min-Max Optimization on Riemannian Manifolds , author =. Transactions on Machine Learning Research , year =
-
[14]
Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , series =
Semi-Implicit Hybrid Gradient Methods with Application to Adversarial Robustness , author =. Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , series =
-
[15]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Robust Multi-Agent Reinforcement Learning via Adversarial Regularization: Theoretical Foundation and Stable Algorithms , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[16]
The annals of mathematical statistics , pages=
A stochastic approximation method , author=. The annals of mathematical statistics , pages=. 1951 , publisher=
1951
-
[17]
The Annals of Mathematical Statistics , pages=
Stochastic estimation of the maximum of a regression function , author=. The Annals of Mathematical Statistics , pages=. 1952 , publisher=
1952
-
[18]
Seminaire de probabilites XXXIII , pages=
Dynamics of stochastic approximation algorithms , author=. Seminaire de probabilites XXXIII , pages=. 2006 , publisher=
2006
-
[19]
The Annals of Statistics , volume=
Strong convergence of a stochastic approximation algorithm , author=. The Annals of Statistics , volume=. 1978 , publisher=
1978
-
[20]
International Symposium on Algorithmic Game Theory , pages=
PPAD-complete pure approximate Nash equilibria in Lipschitz games , author=. International Symposium on Algorithmic Game Theory , pages=. 2022 , organization=
2022
-
[21]
arXiv preprint arXiv:2207.07557 , year=
The computational complexity of multi-player concave games and kakutani fixed points , author=. arXiv preprint arXiv:2207.07557 , year=
-
[22]
The Linear Complementarity Problem, Lemke Algorithm, Perturbation, and the Complexity Class PPAD , author=
-
[23]
Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages=
The complexity of constrained min-max optimization , author=. Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages=
-
[24]
Lai, Zehua and Lim, Lek-Heng , journal =
-
[25]
Proceedings of the 25th Annual Conference on Learning Theory , title =
Recht, Benjamin and R\'. Proceedings of the 25th Annual Conference on Learning Theory , title =. 2012 , editor =
2012
-
[26]
2019 , journal =
Xiao Li and Zhihui Zhu and Anthony Man-Cho So and Jason D Lee , title =. 2019 , journal =
2019
-
[27]
SIAM Journal on Optimization , publisher=
Ghadimi, Saeed and Lan, Guanghui , year=. SIAM Journal on Optimization , publisher=. doi:10.1137/120880811 , number=
-
[28]
Ying, Bicheng and Yuan, Kun and Vlaski, Stefan and Sayed, Ali H. , booktitle =. doi:10.1109/TSP.2018.2878551 , eprint =
-
[29]
2019 , editor =
Haochen, Jeff and Sra, Suvrit , booktitle =. 2019 , editor =
2019
-
[30]
SIAM Journal on Optimization , volume =
G\". SIAM Journal on Optimization , volume =. 2019 , doi =
2019
-
[31]
2020 , journal=
Ahmed Khaled and Peter Richt\'. 2020 , journal=
2020
-
[32]
SIAM Review , number =
Bottou, L. SIAM Review , number =. 2018 , doi =
2018
-
[33]
Nguyen and Quoc Tran-Dinh and Dzung T
Lam M. Nguyen and Quoc Tran-Dinh and Dzung T. Phan and Phuong Ha Nguyen and Marten van Dijk , year=
-
[34]
2019 , editor =
Nagaraj, Dheeraj and Jain, Prateek and Netrapalli, Praneeth , booktitle =. 2019 , editor =
2019
-
[35]
Shashank Rajput and Anant Gupta and Dimitris Papailiopoulos , year=
-
[36]
arXiv preprint arXiv:1909.04715 , year =
Ahmed Khaled and Konstantin Mishchenko and Peter Richt. arXiv preprint arXiv:1909.04715 , year =
-
[37]
Scaffold: Stochastic controlled averaging for federated learning,
Sai Praneeth Karimireddy and Satyen Kale and Mehryar Mohri and Sashank J. Reddi and Sebastian U. Stich and Ananda Theertha Suresh , title =. arXiv preprint arXiv:1910.06378 , year =
-
[38]
Proceedings of the 36th International Conference on Machine Learning , year =
Gower, Robert Mansel and Loizou, Nicolas and Qian, Xun and Sailanbayev, Alibek and Shulgin, Egor and Richt\'. Proceedings of the 36th International Conference on Machine Learning , year =
-
[39]
Bertsekas , title =
Dimitri P. Bertsekas , title =. Optimization for Machine Learning , publisher =. 2011 , editor =
2011
-
[40]
Curiously fast convergence of some stochastic gradient descent algorithms , note =
Bottou, L\'. Curiously fast convergence of some stochastic gradient descent algorithms , note =. 2009 , url =
2009
-
[41]
Mathematical Programming , year =
G\". Mathematical Programming , year =. doi:10.1007/s10107-019-01440-w , publisher =
-
[42]
Proceedings of the 30th International Conference on Neural Information Processing Systems , year =
Shamir, Ohad , title =. Proceedings of the 30th International Conference on Neural Information Processing Systems , year =
-
[43]
Neurocomputing , year =
Qi Meng and Wei Chen and Yue Wang and Zhi-Ming Ma and Tie-Yan Liu , title =. Neurocomputing , year =
-
[44]
Raman, Parameswaran and Srinivasan, Sriram and Matsushima, Shin and Zhang, Xinhua and Yun, Hyokun and Vishwanathan, S.V.N. , title =. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , year =. doi:10.1145/3292500.3330837 , isbn =
-
[45]
Proceedings of the 25th Annual Conference on Learning Theory , year =
Benjamin Recht and Christopher R. Proceedings of the 25th Annual Conference on Learning Theory , year =
-
[46]
Convergence of Variance-Reduced Learning Under Random Reshuffling , booktitle =
B. Convergence of Variance-Reduced Learning Under Random Reshuffling , booktitle =. 2018 , pages =
2018
-
[47]
SIAM Journal on Optimization , year =
Mokhtari, Aryan and G\". SIAM Journal on Optimization , year =
-
[48]
SIAM Journal on Optimization , year =
G\". SIAM Journal on Optimization , year =. doi:10.1137/15m1049695 , publisher =
-
[49]
Mathematical Programming , year =
Ruoyu Sun and Yinyu Ye , title =. Mathematical Programming , year =. doi:10.1007/s10107-019-01437-5 , publisher =
-
[50]
Random permutations fix a worst case for cyclic coordinate descent , journal =. 2018 , volume =. doi:10.1093/imanum/dry040 , publisher =
-
[51]
doi:10.1007/s12532-013-0053-8 , year =
Benjamin Recht and Christopher R. doi:10.1007/s12532-013-0053-8 , year =
-
[52]
Journal of the Operations Research Society of China , year=
Sun, Ruo-Yu , title=. Journal of the Operations Research Society of China , year=
-
[53]
arXiv preprint:1907.04232 , eprint =
Sebastian U. Stich , title =. arXiv preprint arXiv:1907.04232 , year =. 1907.04232v2 , eprintclass =
-
[54]
doi:10.1162/neco.1991.3.2.226 , year =
Zhi-Quan Luo , title =. doi:10.1162/neco.1991.3.2.226 , year =
-
[55]
doi:10.1080/10556789408805583 , year =
Luigi Grippo , title =. doi:10.1080/10556789408805583 , year =
-
[56]
Mangasarian and Mikhail V
Olvi L. Mangasarian and Mikhail V. Solodov , title =. Optimization Methods and Software , volume =. 1994 , publisher =
1994
-
[57]
Dimitri P. Bertsekas and John N. Tsitsiklis , title =. doi:10.1137/s1052623497331063 , year =
-
[58]
Angelia Nedi \' c and Dimitri P. Bertsekas. doi:10.1137/s1052623499362111 , year =
-
[59]
and Juditsky, A
Nemirovski, A. and Juditsky, A. and Lan, G. and Shapiro, A. , title =. SIAM Journal on Optimization , volume =. 2009 , doi =
2009
-
[60]
Practical Recommendations for Gradient-Based Training of Deep Architectures, pages 437--478
Bengio, Yoshua , year=. doi:10.1007/978-3-642-35289-8_26 , journal=
-
[61]
2018 , editor =
Nguyen, Lam and Nguyen, Phuong Ha and van Dijk, Marten and Richt. 2018 , editor =
2018
-
[62]
Yoel Drori and Ohad Shamir , year=
-
[63]
2019 , publisher =
Nguyen, Phuong Ha and Nguyen, Lam and van Dijk, Marten , booktitle =. 2019 , publisher =
2019
-
[64]
Nemirovsky, Arkadi and Yudin, David B. , year=
-
[65]
Proceedings of the 29th International Coference on International Conference on Machine Learning , year =
Rakhlin, Alexander and Shamir, Ohad and Sridharan, Karthik , title =. Proceedings of the 29th International Coference on International Conference on Machine Learning , year =
-
[66]
arXiv preprint arXiv:2004.08657 , archivePrefix=
Kwangjun Ahn and Suvrit Sra , year=. arXiv preprint arXiv:2004.08657 , archivePrefix=
-
[67]
2014 , publisher =
Needell, Deanna and Ward, Rachel and Srebro, Nati , booktitle =. 2014 , publisher =
2014
-
[68]
Advances in Neural Information Processing Systems 16 , editor =
Bottou, L\'. Advances in Neural Information Processing Systems 16 , editor =. 2004 , publisher =
2004
-
[69]
arXiv preprint arXiv:1910.09529 , year=
Adaptive gradient descent without descent , author=. arXiv preprint arXiv:1910.09529 , year=
-
[70]
SIAM Journal on Optimization , volume =
Chen, Gong and Teboulle, Marc , title =. SIAM Journal on Optimization , volume =. 1993 , doi =
1993
-
[71]
Kwangjun Ahn and Chulhee Yun and Suvrit Sra , year=
-
[72]
ICML , year=
Stochastic hamiltonian gradient methods for smooth games , author=. ICML , year=
-
[73]
SIAM Journal on Optimization , volume=
Convergence rates in forward--backward splitting , author=. SIAM Journal on Optimization , volume=. 1997 , publisher=
1997
-
[74]
AISTATS , year=
Fast Distributionally Robust Learning with Variance-Reduced Min-Max Optimization , author=. AISTATS , year=
-
[75]
AISTATS , year=
Revisiting stochastic extragradient , author=. AISTATS , year=
-
[76]
NeurIPS , year=
Stochastic gradient methods for distributionally robust optimization with f-divergences , author=. NeurIPS , year=
-
[77]
NeurIPS , year=
Combining deep reinforcement learning and search for imperfect-information games , author=. NeurIPS , year=
-
[78]
Zico Kolter and Nicolas Loizou and Marc Lanctot and Ioannis Mitliagkas and Noam Brown and Christian Kroer , title =
Samuel Sokota and Ryan D'Orazio and J. Zico Kolter and Nicolas Loizou and Marc Lanctot and Ioannis Mitliagkas and Noam Brown and Christian Kroer , title =. ICLR 2023 , year =
2023
-
[79]
NeurIPS , editor=
Adversarial Attack Generation Empowered by Min-Max Optimization , author=. NeurIPS , editor=
-
[80]
NeurIPS , year=
Generative Adversarial Networks , author=. NeurIPS , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.