Offline Reinforcement Learning for Fluid Controls: Data-based Multi-observational Policy Extraction
Pith reviewed 2026-07-01 06:22 UTC · model grok-4.3
The pith
A sensor position-conditioned architecture lets one offline RL policy adapt to multiple sensor placements in fluid flow control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
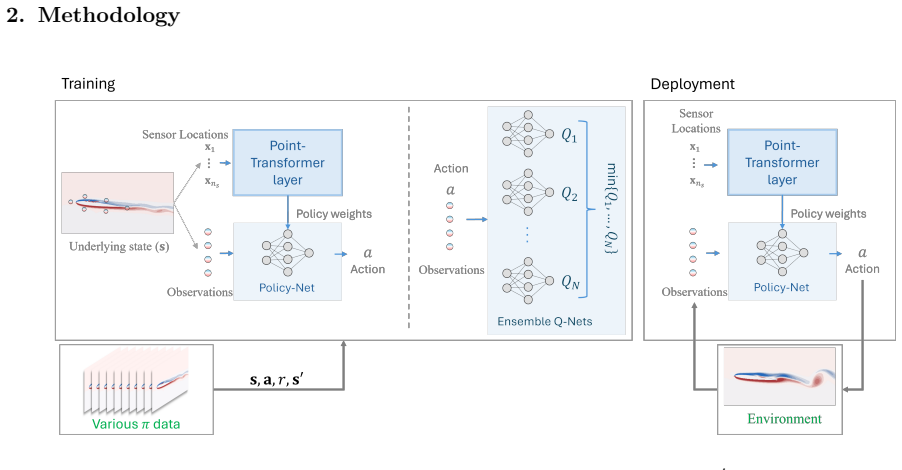
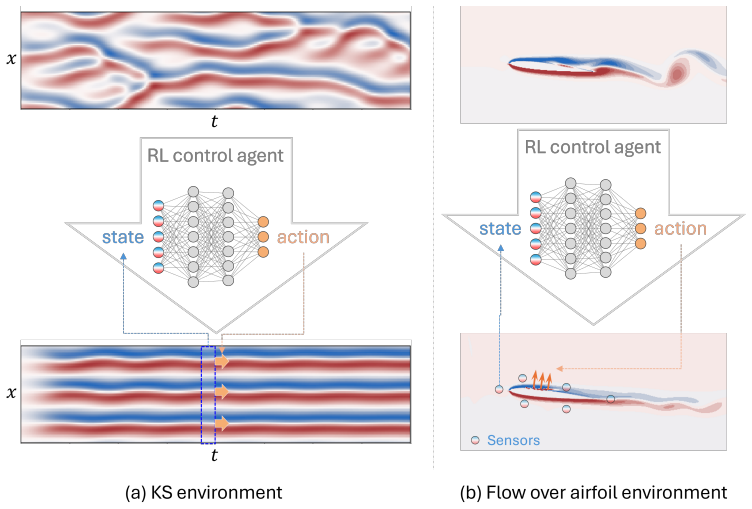
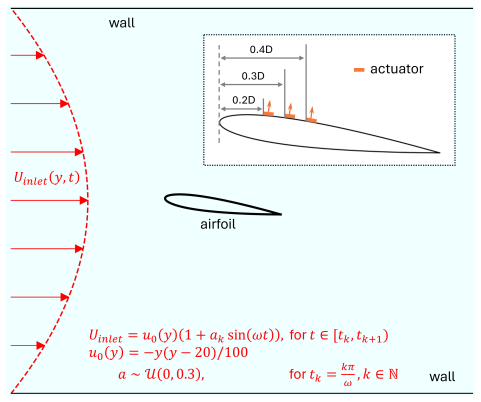
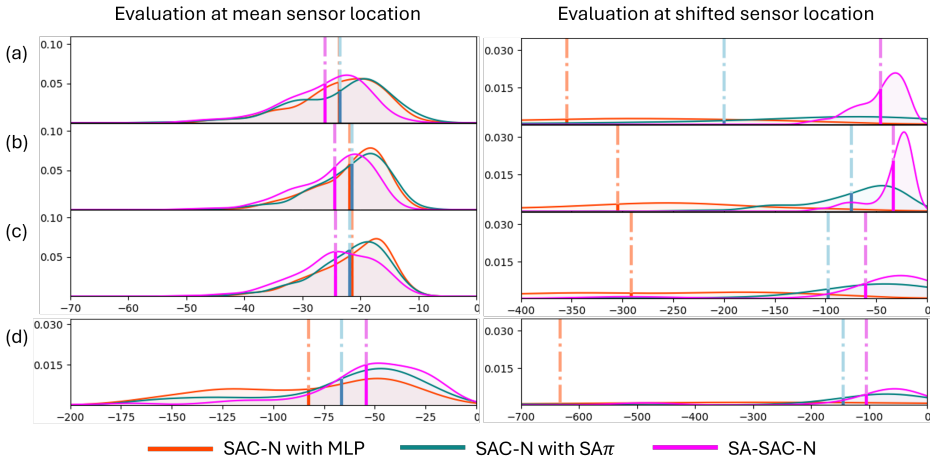
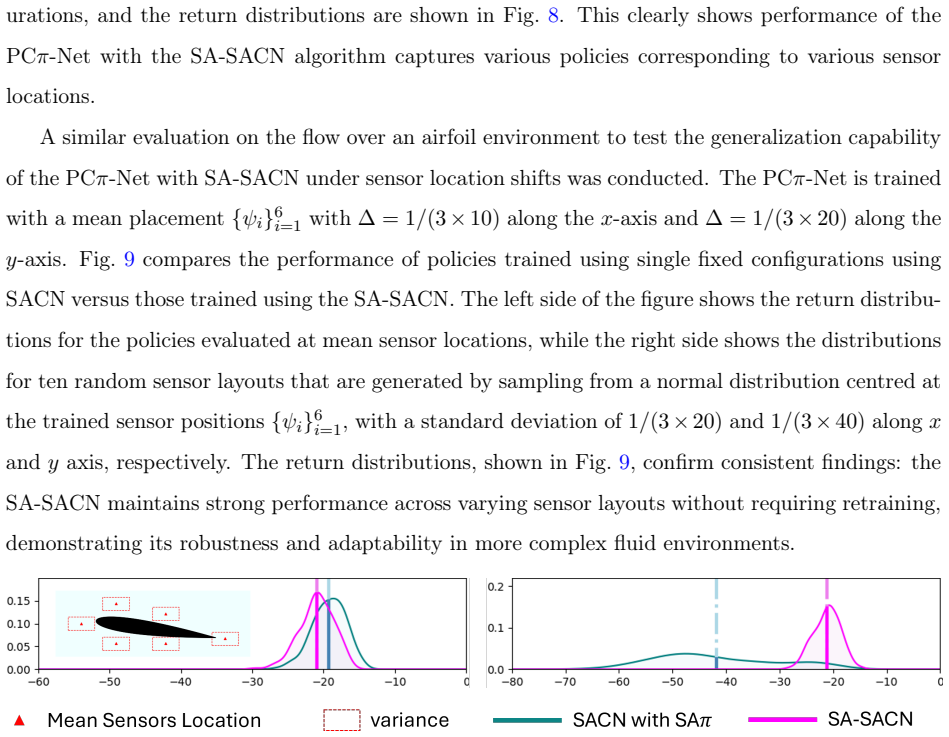
We propose a novel offline RL framework that addresses both challenges through data-driven policy extraction. We develop a sensor position-conditioned architecture that enables a single policy network to adapt seamlessly to multiple sensor arrangements. The position-conditioned approach incorporated spatial relationship modeling through Point Attention layers to ensure the generalizability to varying sensor placements. We demonstrate the framework on two representative problems, mitigating chaoticity in the Kuramoto-Sivashinsky equation and flow control over airfoils governed by the Navier-Stokes equation. The result demonstrates that the policy extraction from the dataset provides unprecede
What carries the argument
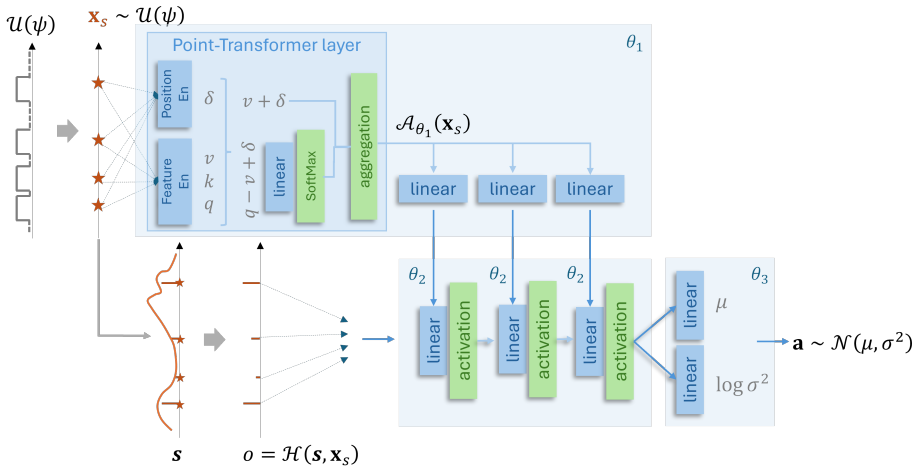
Sensor position-conditioned architecture with Point Attention layers that model spatial relationships to let one policy generalize across varying sensor placements.
If this is right
- A single trained policy network works for any sensor arrangement without retraining.
- Policies are obtained purely from offline datasets, eliminating the need for online interactions with the high-fidelity simulator.
- Sensor placement can be chosen or optimized after the policy has already been extracted.
- The same framework applies to both low-dimensional chaotic PDEs and high-dimensional Navier-Stokes flow control.
- Overall computational cost for deploying adaptive flow control drops because retraining is no longer required for each new sensor layout.
Where Pith is reading between the lines
- The conditioning trick could be reused in other control domains where the set of available observations changes between deployments.
- It is worth checking whether the attention mechanism continues to generalize when the number of sensors or their spatial distribution differs sharply from the training set.
- Similar position or configuration conditioning might reduce retraining costs in multi-task or continual reinforcement learning settings outside fluids.
- Physical experiments on real wind-tunnel or water-channel setups would be the next concrete test of whether the offline-extracted policies transfer beyond simulation.
Load-bearing premise
That offline datasets together with Point Attention layers are enough to produce policies that work on arbitrary unseen sensor placements.
What would settle it
Showing that the learned policy loses control performance on a sensor configuration whose positions were never present in the offline training data.
Figures





read the original abstract
Active flow control is a fundamental application in engineering. Recent advances in deep reinforcement learning have made progress in this field. However, the classical online RL approaches require extensive real-time interactions with the high fidelity environment, while each sensor configuration change necessitates whole policy retraining. All these factors result in prohibitive computational costs for real-world applications. In this work, we propose a novel offline RL framework that addresses both challenges through data-driven policy extraction. We develop a sensor position-conditioned architecture that enables a single policy network to adapt seamlessly to multiple sensor arrangements. The position-conditioned approach incorporated spatial relationship modeling through Point Attention layers to ensure the generalizability to varying sensor placements. We demonstrate the framework on two representative problems, mitigating chaoticity in the Kuramoto-Sivashinsky equation and flow control over airfoils governed by the Navier-Stokes equation. The result demonstrates that the policy extraction from the dataset provides unprecedented flexibility for sensor placement optimization. This approach represents a significant step towards adaptive, intelligent flow control systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an offline RL framework for active flow control that extracts policies from datasets using a single sensor position-conditioned policy network. The architecture incorporates Point Attention layers to model spatial relationships, enabling adaptation to multiple sensor arrangements without retraining. Demonstrations are provided on mitigating chaos in the Kuramoto-Sivashinsky equation and controlling flow over airfoils via the Navier-Stokes equations, with the claim that this yields unprecedented flexibility for sensor placement optimization.
Significance. If the generalization claims hold with adequate data coverage and validation, the work could meaningfully lower the barrier to deploying adaptive flow control by eliminating per-configuration retraining and online interaction costs. The combination of offline RL with position-conditioned attention for spatial invariance is a natural fit for sensor-placement problems and could influence related domains such as robotics or environmental sensing. However, the absence of reported dataset statistics, held-out placement tests, or quantitative transfer metrics makes the practical significance difficult to assess at present.
major comments (2)
- [Abstract] Abstract: The central claim that 'a single policy network [can] adapt seamlessly to multiple sensor arrangements' and provides 'unprecedented flexibility' rests on the unverified assumption that the offline datasets contain sufficient positional diversity and that Point Attention extrapolates the control mapping. No information is given on the number or distribution of sensor arrangements appearing in the Kuramoto-Sivashinsky or airfoil datasets, nor on whether any placements were held out for zero-shot evaluation.
- [Abstract] Abstract: No quantitative results, ablation studies, or baseline comparisons (e.g., retrained policies per configuration versus the conditioned network) are supplied to support the assertion of seamless adaptation or to quantify any performance gap. Without these, the load-bearing claim of generalizability cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit support of the generalizability claims. We will revise the manuscript to incorporate the requested dataset details, held-out evaluations, and quantitative comparisons.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'a single policy network [can] adapt seamlessly to multiple sensor arrangements' and provides 'unprecedented flexibility' rests on the unverified assumption that the offline datasets contain sufficient positional diversity and that Point Attention extrapolates the control mapping. No information is given on the number or distribution of sensor arrangements appearing in the Kuramoto-Sivashinsky or airfoil datasets, nor on whether any placements were held out for zero-shot evaluation.
Authors: We agree the abstract would benefit from concrete supporting details. The experimental sections describe data collection across multiple sensor positions for both the Kuramoto-Sivashinsky and airfoil cases. In revision we will update the abstract with explicit counts (number of arrangements per problem, distribution statistics, and confirmation of held-out placements used for zero-shot testing) and add a dedicated paragraph on dataset coverage to directly substantiate the positional diversity assumption. revision: yes
-
Referee: [Abstract] Abstract: No quantitative results, ablation studies, or baseline comparisons (e.g., retrained policies per configuration versus the conditioned network) are supplied to support the assertion of seamless adaptation or to quantify any performance gap. Without these, the load-bearing claim of generalizability cannot be evaluated.
Authors: The body of the manuscript reports performance metrics for the conditioned policy on the two control tasks. To strengthen the abstract claim, we will add an ablation study isolating the contribution of the Point Attention layers and a new table that directly compares the single position-conditioned network against separately trained policies for each sensor configuration. These additions will quantify adaptation performance and any gaps. revision: yes
Circularity Check
No circularity: method proposal with empirical demonstration, no derivations or self-referential predictions
full rationale
The paper describes an offline RL framework and a sensor position-conditioned architecture using Point Attention layers for multi-observational policy extraction. It applies the method to Kuramoto-Sivashinsky and Navier-Stokes airfoil problems. No first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear. Claims of generalizability rest on the proposed architecture and dataset usage rather than any tautological reduction of outputs to inputs. This is a standard empirical ML methods paper; the derivation chain is absent and the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Glezer, M
A. Glezer, M. Amitay, Synthetic jets: A new paradigm for flow control, Philosophical Trans- actions of the Royal Society A 361 (1813) (2003) 1471–1487
2003
-
[2]
Z. Liu, M. Zhang, D. Sun, et al., A deep reinforcement learning optimization framework for supercritical airfoil aerodynamic shape design, Structural and Multidisciplinary Optimization 67 (2024) 34.doi:10.1007/s00158-024-03755-5
- [3]
-
[4]
Vinuesa, O
R. Vinuesa, O. Lehmkuhl, A. Lozano-Durán, J. Rabault, Flow control in wings and discovery of novel approaches via deep reinforcement learning, Fluids 7 (2) (2022) 62.doi:10.3390/ fluids7020062
2022
-
[5]
S. Zhao, F. Wang, Y. Tang, Y. Liu, Optimal sensor placement based on attention mechanism for minimizing lift fluctuations over an airfoil with deep reinforcement learning (2025).doi: 10.1007/978-981-97-9771-4_30
-
[6]
S. Aubrun, A. Leroy, P. Devinant, A review of wind turbine-oriented active flow control strate- gies, Experiments in Fluids 58 (2017) 134.doi:10.1007/s00348-017-2333-9
-
[7]
Simley, D
E. Simley, D. Millstein, S. Jeong, P. Fleming, The value of wake steering wind farm flow control in us energy markets, Wind Energy Science 9 (1) (2024) 219–234.doi:10.5194/ wes-9-219-2024. 24
2024
-
[8]
J. Xie, H. Dong, X. Zhao, Data-driven torque and pitch control of wind turbines via reinforce- ment learning, Renewable Energy 215 (2023) 118893.doi:10.1016/j.renene.2023.118893
-
[9]
Fernandez-Gauna, M
B. Fernandez-Gauna, M. Graña, J.-L. Osa-Amilibia, X. Larrucea, Actor-critic continuous state reinforcement learning for wind-turbine control robust optimization, Energy InformaticsCited in 2024 review (2022)
2024
-
[10]
H. Dong, J. Zhang, X. Zhao, Intelligent wind farm control via deep reinforcement learning and high-fidelity simulations, Applied Energy 292 (2021) 116928.doi:10.1016/j.apenergy.2021. 116928
-
[11]
S. Dallas, A. Stock, E. Hart, Control-oriented modelling of wind direction variability, Wind Energy Science 9 (2024) 841–867.doi:10.5194/wes-9-841-2024
-
[12]
García-Mayoral, J
R. García-Mayoral, J. Jiménez, A review of passive flow control techniques for boundary-layer control, Annual Review of Fluid Mechanics 43 (2011) 319–345
2011
-
[13]
Garcia, A
X. Garcia, A. Miró, P. Suárez, F. Alcántara-Ávila, J. Rabault, B. Font, O. Lehmkuhl, R. Vin- uesa, Deep-reinforcement-learning-based separation control in a two-dimensional airfoil, Inter- national Journal of Heat and Fluid Flow 116 (2025) 109913
2025
-
[14]
T. Sonoda, Z. Liu, T. Itoh, Y. Hasegawa, Reinforcement learning of control strategies for reduc- ing skin friction drag in a fully developed turbulent channel flow, Journal of Fluid Mechanics 960 (2023) A30.doi:10.1017/jfm.2023.180
-
[15]
C. Xia, J. Zhang, E. Kerrigan, G. Rigas, Active flow control for bluff body drag reduction using reinforcement learning with partial measurements, Journal of Fluid Mechanics 981 (2024) A17. doi:10.1017/jfm.2024.69
-
[16]
L. Guastoni, J. Rabault, P. Schlatter, H. Azizpour, R. Vinuesa, Deep reinforcement learning for turbulent drag reduction in channel flows, European Physical Journal E 46 (4) (2023) 27. doi:10.1140/epje/s10189-023-00285-8
- [17]
-
[18]
G. Maceda, E. Varon, F. Lusseyran, B. Noack, Stabilization of a multi-frequency open cavity flow with gradient-enriched machine learning control, Journal of Fluid Mechanics 955 (2023) A20.doi:10.1017/jfm.2022.1055
-
[19]
J. M. Ottino, Mixing, chaotic advection, and turbulence, Annual Review of Fluid Mechanics 22 (1) (1990) 207–254
1990
-
[20]
C. Vignon, J. Rabault, J. Vasanth, F. Alcántara-Ávila, M. Mortensen, R. Vinuesa, Effective control of two-dimensional Rayleigh–Bénard convection: Invariant multi-agent reinforcement learning is all you need, Physics of Fluids 35 (6) (2023) 065146.doi:10.1063/5.0153181
-
[21]
M. P. Paidoussis, Fluid–Structure Interactions: Slender Structures and Axial Flow, Elsevier, 2010
2010
-
[22]
W. Chen, Q. Wang, L. Yan, G. Hu, B. Noack, Deep reinforcement learning-based active flow control of vortex-induced vibration of a square cylinder, Physics of Fluids 35 (5) (2023) 053610. doi:10.1063/5.0152777
-
[23]
Y. Yao, et al., Deep reinforcement learning-based active mass driver decoupled control frame- workconsideringcontrol–structureinteractioneffects, Computer-AidedCivilandInfrastructure Engineering (2024).doi:10.1111/mice.13159
-
[24]
D. Rus, M. T. Tolley, Design, fabrication and control of soft robots, Nature 521 (2015) 467–475
2015
-
[25]
S. Verma, G. Novati, P. Koumoutsakos, Efficient collective swimming by harnessing vortices through deep reinforcement learning, Proceedings of the National Academy of Sciences 115 (23) (2018) 5849–5854.doi:10.1073/pnas.1800923115
-
[26]
Liepmann, G
H. Liepmann, G. Brown, D. Nosenchuck, Control of laminar-instability waves using a new technique, Journal of Fluid Mechanics 118 (1982) 187–200
1982
-
[27]
D. M. Bushnell, C. B. McGinley, Turbulence control in wall flows, Annual Review of Fluid Mechanics 21 (1989) 1–20
1989
-
[28]
S. S. Joshi, J. L. Speyer, J. Kim, A systems theory approach to the feedback stabilization of infinitesimal and finite-amplitude disturbances in plane poiseuille flow, Journal of Fluid Mechanics 332 (1997) 157–184.doi:10.1017/S0022112096004314. 26
-
[29]
T.R. Bewley, S.-C. Liu, Optimal and robustcontrol andestimation oflinearpaths totransition, Journal of Fluid Mechanics 365 (1998) 305–349.doi:10.1017/S0022112098001320
-
[30]
Paris, S
R. Paris, S. Beneddine, J. Dandois, Robust flow control and optimal sensor placement using deep reinforcement learning, Journal of Fluid Mechanics 913 (2021) A25
2021
-
[31]
WATANABE, N
A. WATANABE, N. TAKADA, S. SHIMOMURA, S. SEKIMOTO, S.¯OTOMO, A. OYAMA, H. NISHIDA, Effect of pressure sensor arrangement on deep reinforcement learning-based feed- back control of separated flow around aerofoils, Aerospace Science and Technology (2025) 110347
2025
-
[32]
Gazzola, A
M. Gazzola, A. A. Tchieu, D. Alexeev, A. De Brauer, P. Koumoutsakos, Learning to school in the presence of hydrodynamic interactions, Journal of Fluid Mechanics 789 (2016) 726–749
2016
-
[33]
Novati, S
G. Novati, S. Verma, D. Alexeev, D. Rossinelli, W. M. Van Rees, P. Koumoutsakos, Synchroni- sation through learning for two self-propelled swimmers, Bioinspiration & biomimetics 12 (3) (2017) 036001
2017
-
[34]
Gustavsson, L
K. Gustavsson, L. Biferale, A. Celani, S. Colabrese, Finding efficient swimming strategies in a three-dimensional chaotic flow by reinforcement learning, The European Physical Journal E 40 (2017) 1–6
2017
-
[35]
Colabrese, K
S. Colabrese, K. Gustavsson, A. Celani, L. Biferale, Flow navigation by smart microswimmers via reinforcement learning, Physical review letters 118 (15) (2017) 158004
2017
-
[36]
Liu, J.-X
X.-Y. Liu, J.-X. Wang, Physics-informed dyna-style model-based deep reinforcement learning for dynamic control, Proceedings of the Royal Society A 477 (2255) (2021) 20210618
2021
-
[37]
Shankar, V
V. Shankar, V. Puri, R. Balakrishnan, R. Maulik, V. Viswanathan, Differentiable physics- enabled closure modeling for burgers’ turbulence, Machine Learning: Science and Technology 4 (1) (2023) 015017
2023
-
[38]
X.-Y. Liu, M. Zhu, L. Lu, H. Sun, J.-X. Wang, Multi-resolution partial differential equations preserved learning framework for spatiotemporal dynamics, Communications Physics 7 (1) (2024) 31. 27
2024
- [39]
- [40]
-
[41]
H. J. Bae, P. Koumoutsakos, Scientific multi-agent reinforcement learning for wall-models of turbulent flows, Nature Communications 13 (1) (2022) 1443
2022
-
[42]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, J. Fu, Offline reinforcement learning: Tutorial, review, and perspectives on open problems, arXiv preprint arXiv:2005.01643 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[43]
R. F. Prudencio, M. R. Maximo, E. L. Colombini, A survey on offline reinforcement learning: Taxonomy, review, and open problems, IEEE Transactions on Neural Networks and Learning Systems 34 (8) (2023) 4179–4198
2023
-
[44]
Kumar, A
A. Kumar, A. Zhou, G. Tucker, S. Levine, Conservative q-learning for offline reinforcement learning, Advances in Neural Information Processing Systems 33 (2020) 1179–1191
2020
-
[45]
Kumar, J
A. Kumar, J. Fu, M. Soh, G. Tucker, S. Levine, Stabilizing off-policy q-learning via bootstrap- ping error reduction, Advances in Neural Information Processing Systems 32 (2019)
2019
-
[46]
Y. Wu, G. Tucker, O. Nachum, Behavior regularized offline reinforcement learning, arXiv preprint arXiv:1911.11361 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[47]
Fujimoto, D
S. Fujimoto, D. Meger, D. Precup, Off-policy deep reinforcement learning without exploration, in: International Conference on Machine Learning, PMLR, 2019, pp. 2052–2062
2019
-
[48]
G. An, S. Moon, J.-H. Kim, H. O. Song, Uncertainty-based offline reinforcement learning with diversified q-ensemble, Advances in neural information processing systems 34 (2021) 7436–7447
2021
-
[49]
Singh, L
A. Singh, L. Yang, K. Hartikainen, C. Finn, S. Levine, End-to-end robotic reinforcement learn- ing without reward engineering, in: Robotics: Science and Systems, 2020
2020
-
[50]
Mandlekar, D
A. Mandlekar, D. Xu, R. Martín-Martín, Y. Zhu, L. Fei-Fei, S. Savarese, Learning to generalize across long-horizon tasks from human demonstrations, in: Robotics: Science and Systems, 2021. 28
2021
-
[51]
Gottesman, F
O. Gottesman, F. Johansson, M. Komorowski, A. Faisal, D. Sontag, F. Doshi-Velez, L. A. Celi, Guidelines for reinforcement learning in healthcare, Nature Medicine 25 (1) (2019) 16–18
2019
-
[52]
B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, P. Pérez, Deep reinforcement learning for autonomous driving: Datasets, methods, and challenges, IEEE Transactions on Intelligent Transportation Systems 23 (6) (2021) 4909–4926
2021
-
[53]
I. Char, J. Abbate, L. Bardóczi, M. D. Boyer, Y. Chung, R. Conlin, K. Erickson, V. Mehta, N. Richner, E. Kolemen, J. Schneider, Offline model-based reinforcement learning for tokamak control, in: Proceedings of Machine Learning Research, Vol. 211, 5th Annual Conference on Learning for Dynamics and Control, 2023, pp. 1–16
2023
-
[54]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., Human-level control through deep rein- forcement learning, nature 518 (7540) (2015) 529–533
2015
-
[55]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in: International conference on machine learning, Pmlr, 2018, pp. 1861–1870
2018
-
[56]
Fujimoto, H
S. Fujimoto, H. Hoof, D. Meger, Addressing function approximation error in actor-critic meth- ods, in: International conference on machine learning, PMLR, 2018, pp. 1587–1596
2018
-
[57]
H. Zhao, L. Jiang, J. Jia, P. H. Torr, V. Koltun, Point transformer, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16259–16268
2021
-
[58]
Cvitanović, R
P. Cvitanović, R. L. Davidchack, E. Siminos, On the state space geometry of the kuramoto– sivashinsky flow in a periodic domain, SIAM Journal on Applied Dynamical Systems 9 (1) (2010) 1–33
2010
-
[59]
Wang, Y.-F
Y.-Z. Wang, Y.-F. Mei, N. Aubry, Z. Chen, P. Wu, W.-T. Wu, Deep reinforcement learning based synthetic jet control on disturbed flow over airfoil, Physics of Fluids 34 (3) (2022). 29 Appendix A. Various models Figure A.12: SACN algorithm with MLP as actor Figure A.13: SACN algorithm with PCπ-net as actor 30 Figure A.14: Sensor aware SACN (PC-SACN) algorit...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.