CSO-LLM: Class Subspace Orthogonalization for Post-Training Backdoor Detection and Trigger Inversion in LLMs
Pith reviewed 2026-07-01 05:40 UTC · model grok-4.3
The pith
Class subspace orthogonalization in embedding space detects backdoors in LLMs and inverts triggers without needing a comprehensive blacklist.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Treating LLMs as classifiers, class subspace orthogonalization applied in embedding space enhances detector performance while implicitly blacklisting tokens that induce perturbations toward the putative target class, enabling both continuous and discrete search methods that achieve strong detection and accurate inversion of ground-truth triggers across several domains and architectures.
What carries the argument
Class Subspace Orthogonalization (CSO), a method that orthogonalizes class subspaces in token embedding space to penalize inclusion of tokens aligned with the target class of an attack.
If this is right
- The approach improves both sensitivity and specificity over a baseline detector for LLM backdoors.
- It supplies implicit blacklisting that reduces false signals from target-class tokens without requiring an exhaustive domain blacklist.
- It supports accurate inversion of ground-truth triggers via either continuous embedding optimization or discrete token accretion.
- Performance holds across multiple LLM classification domains and several different model architectures.
Where Pith is reading between the lines
- The same embedding-space orthogonalization idea could be tested on other discrete-input models such as certain sequence predictors outside language.
- If the method generalizes, it may lower the manual effort needed for blacklisting in security audits of deployed AI systems.
- Extensions to continuous or multimodal inputs might reveal whether the orthogonalization principle depends on the discrete token structure.
Load-bearing premise
That LLMs can be treated as classifiers so that class subspace orthogonalization in embedding space will reliably detect backdoors and invert triggers by supplying effective implicit blacklisting without a domain-specific comprehensive blacklist.
What would settle it
A controlled experiment planting a known trigger in one of the evaluated LLMs and finding that the method either misses the backdoor or recovers a substantially incorrect trigger would falsify the performance claims.
Figures
read the original abstract
While post-training backdoor detection and trigger inversion schemes have been developed for AIs used e.g. for images, there is a paucity of such methods for LLMs. First, the LLM input space is discrete, with up to 150,000^k k-tuples to consider with k the token-length of a putative trigger. Second, one must blacklist tokens typical of the putative target response (class) of an attack, as such tokens may give false detection signals. However, a comprehensive blacklist is not available, in general, for a given domain. We develop a highly effective detection and inversion framework for LLMs treated as classifiers. Central to our approach is class subspace orthogonalization (CSO), a novel plug-and-play paradigm for backdoor detection that serves two fundamental roles when applied to LLMs: i) it enhances both sensitivity and specificity of a baseline detector; ii) it provides a form of implicit blacklisting, as it penalizes against inclusion, in a candidate trigger, of tokens that induce signal perturbations "in the direction of" the putative target class of an attack. One version of our detector performs continuous optimization in token embedding space, while a companion trigger-inversion and detection method performs greedy accretion in discrete token space. Our methods give both strong detection performance and accurate inversion of ground-truth triggers on several LLM classification domains, and for several different LLM architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CSO-LLM, a post-training framework for backdoor detection and trigger inversion in LLMs treated as classifiers. It introduces class subspace orthogonalization (CSO) applied in embedding space to both enhance a baseline detector's sensitivity/specificity and provide implicit blacklisting by penalizing tokens aligned with the putative target class. Two variants are presented: continuous optimization over token embeddings and greedy discrete token accretion. The central claim is that these methods achieve strong detection performance and accurate recovery of ground-truth triggers across multiple LLM classification domains and architectures.
Significance. If the reported performance holds under the stated assumptions, the work is significant for LLM security because it directly tackles the discrete token space (up to 150k^k candidates) and the absence of domain-specific blacklists, two obstacles that prior image-domain methods do not face. The implicit-blacklisting effect via CSO is a genuine technical contribution that could extend beyond the evaluated settings. The paper supplies concrete algorithmic descriptions for both continuous and discrete variants, which supports reproducibility.
major comments (3)
- [§4.2] §4.2 (CSO projection definition): the claim that CSO supplies reliable implicit blacklisting rests on the assumption that class subspaces remain sufficiently orthogonal and stable across contexts; no quantitative analysis (e.g., cosine similarity of class directions under prompt variation or across architectures) is supplied to bound the failure probability when this assumption is violated.
- [Table 3, §5.1] Table 3 and §5.1: detection AUROC and trigger-inversion success rates are reported without ablation that isolates the contribution of the CSO term versus the baseline detector alone; without this control it is impossible to determine whether the performance gain is load-bearing or merely additive.
- [§5.3] §5.3 (greedy accretion algorithm): the discrete method's termination criterion and token-selection heuristic are described only at high level; the paper does not show that the greedy choice property holds under the same embedding geometry that justifies the continuous variant, leaving open the possibility that the two methods succeed for unrelated reasons.
minor comments (2)
- Notation for the orthogonalization operator is introduced without an explicit equation number; readers must infer the projection matrix from surrounding prose.
- Figure 2 caption does not state the number of random seeds or the exact prompt templates used to generate the embedding visualizations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§4.2] §4.2 (CSO projection definition): the claim that CSO supplies reliable implicit blacklisting rests on the assumption that class subspaces remain sufficiently orthogonal and stable across contexts; no quantitative analysis (e.g., cosine similarity of class directions under prompt variation or across architectures) is supplied to bound the failure probability when this assumption is violated.
Authors: We agree that quantitative validation of subspace orthogonality and stability would strengthen the implicit-blacklisting claim. In the revised manuscript we will add a new subsection with cosine-similarity measurements of class directions under prompt variation and across the evaluated architectures, together with a brief discussion of the observed failure probability. revision: yes
-
Referee: [Table 3, §5.1] Table 3 and §5.1: detection AUROC and trigger-inversion success rates are reported without ablation that isolates the contribution of the CSO term versus the baseline detector alone; without this control it is impossible to determine whether the performance gain is load-bearing or merely additive.
Authors: The referee is correct that an explicit ablation isolating the CSO term is missing. We will insert a new table (or expanded Table 3) that reports AUROC and inversion success for the baseline detector both with and without the CSO projection, thereby quantifying the incremental contribution of the orthogonalization step. revision: yes
-
Referee: [§5.3] §5.3 (greedy accretion algorithm): the discrete method's termination criterion and token-selection heuristic are described only at high level; the paper does not show that the greedy choice property holds under the same embedding geometry that justifies the continuous variant, leaving open the possibility that the two methods succeed for unrelated reasons.
Authors: We will expand §5.3 with a precise statement of the termination criterion and the token-selection rule. In addition we will add a short paragraph that links the greedy heuristic to the same embedding geometry used for the continuous variant and supply supporting empirical checks (e.g., monotonic improvement of the objective during accretion). revision: yes
Circularity Check
No circularity; CSO introduced as novel without equations or self-referential reductions
full rationale
The provided abstract and context contain no equations, derivations, or self-citations. CSO is presented as a 'novel plug-and-play paradigm' for implicit blacklisting and detection enhancement, with performance claims framed as empirical results on LLM classifiers. No load-bearing step reduces by construction to fitted inputs, prior self-work, or renamed known results. The method is self-contained against external benchmarks as described, with no evidence of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be treated as classifiers for the purpose of backdoor detection and trigger inversion.
invented entities (1)
-
Class Subspace Orthogonalization (CSO)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Unmasking backdoors: An explainable defense via gradient-attention anomaly scoring for pre-trained language models
Anindya Sundar Das, Kangjie Chen, and Monowar Bhuyan. Unmasking backdoors: An explainable defense via gradient-attention anomaly scoring for pre-trained language models. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[2]
T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks.IEEE Access, 7:47230–47244, 2019
2019
-
[3]
Gradient-based adversarial attacks against text transformers
Chuan Guo, Alexandre Sablayrolles, Hervé Jégou, and Douwe Kiela. Gradient-based adversarial attacks against text transformers. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5747–5757, 2021
2021
-
[4]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR. OpenReview.net, 2022
2022
-
[5]
FLAN-T5-small
Hugging Face. FLAN-T5-small. https://huggingface.co/google/flan-t5-small, 2022
2022
-
[6]
Purifying generative LLMs from backdoors without prior knowledge or clean reference
Jianwei Li and Jung-Eun Kim. Purifying generative LLMs from backdoors without prior knowledge or clean reference. InThe Fourteenth International Conference on Learning Repre- sentations, 2026
2026
-
[7]
Piccolo: Exposing Complex Backdoors in NLP Transformer Models
Yingqi Liu, Guangyu Shen, Guanhong Tao, Shengwei An, Shiqing Ma, and Xiangyu Zhang. Piccolo: Exposing Complex Backdoors in NLP Transformer Models. InProc. IEEE Symp. Security & Privacy, 2022
2022
-
[8]
W. Lyu and al. Task-Agnostic Detector for Insertion-Based Backdoor Attacks. arXiv:2403.17155v1, 25 Mar 2024
-
[9]
Pham, Yige Li, and Jun Sun
Nay Myat Min, Long H. Pham, Yige Li, and Jun Sun. CROW: Eliminating backdoors from large language models via internal consistency regularization. InForty-second International Conference on Machine Learning, 2025
2025
- [10]
-
[11]
Constrained optimization with dynamic bound-scaling for effective NLP backdoor defense
Guangyu Shen, Yingqi Liu, Guanhong Tao, Qiuling Xu, Zhuo Zhang, Shengwei An, Shiqing Ma, and Xiangyu Zhang. Constrained optimization with dynamic bound-scaling for effective NLP backdoor defense. InProc. ICML, 2022
2022
-
[12]
Manning, Andrew Y
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Y . Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 conference on empirical methods in natural language processing (EMNLP), pages 1631–1642, 2013
2013
-
[13]
Universal adversarial triggers for attacking and analyzing NLP
Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. Universal adversarial triggers for attacking and analyzing NLP. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162, 2019
2019
-
[14]
B. Wang, Y . Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, and B.Y . Zhao. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. InProc. IEEE Symposium on Security and Privacy, 2019
2019
-
[15]
Miller, and George Kesidis
Hang Wang, Zhen Xiang, David J. Miller, and George Kesidis. MM-BD: Post-Training Detection of Backdoor Attacks with Arbitrary Backdoor Pattern Types Using a Maximum Margin Statistic. InIEEE S&P, 2024
2024
-
[16]
Rethinking the Reverse- engineering of Trojan Triggers
Zhenting Wang, Kai Mei, Hailun Ding, Juan Zhai, and Shiqing Ma. Rethinking the Reverse- engineering of Trojan Triggers. InNeurIPS, 2022
2022
-
[17]
UNICORN: A Unified Backdoor Trigger Inversion Framework
Zhenting Wang, Kai Mei, Juan Zhai, and Shiqing Ma. UNICORN: A Unified Backdoor Trigger Inversion Framework. InICLR, 2023. 11
2023
-
[18]
Miller, and George Kesidis
Zhen Xiang, David J. Miller, and George Kesidis. Detection of backdoors in trained classifiers without access to the training set.IEEE TNNLS, 2022
2022
-
[19]
Towards reliable and efficient backdoor trigger inversion via decoupling benign features
Xiong Xu, Kunzhe Huang, Yiming Li, Zhan Qin, and Kui Ren. Towards reliable and efficient backdoor trigger inversion via decoupling benign features. InICLR, 2024
2024
-
[20]
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Yang, D.J
G. Yang, D.J. Miller, and G. Kesidis. Improving the Sensitivity of Backdoor Detectors via Class Subspace Orthogonalization. InProc. ICML, Seoul, Korea, July 2026
2026
-
[22]
R. Zeng, X. Chen, Y . Pu, X. Zhang, T. Du, and S. Ji. CLIBE: Detecting Dynamic Backdoors in Transformer-based NLP Models. InProc. NDSS, 2025
2025
-
[23]
Y . Zeng and al. BEEAR: Embedding-based Adversarial Removal of Safety Backdoors in Instruction-tuned Language Models.arXiv:2406.17092v1, 24 Jun 2021
-
[24]
Y . Zeng, S. Chen, W. Park, Z. Mao, M. Jin, and R. Jia. Adversarial unlearning of backdoors via implicit hypergradient. InProc. ICLR, 2022
2022
-
[25]
Character-level convolutional networks for text classification
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. InAdvances in Neural Information Processing Systems, volume 28, 2015
2015
-
[26]
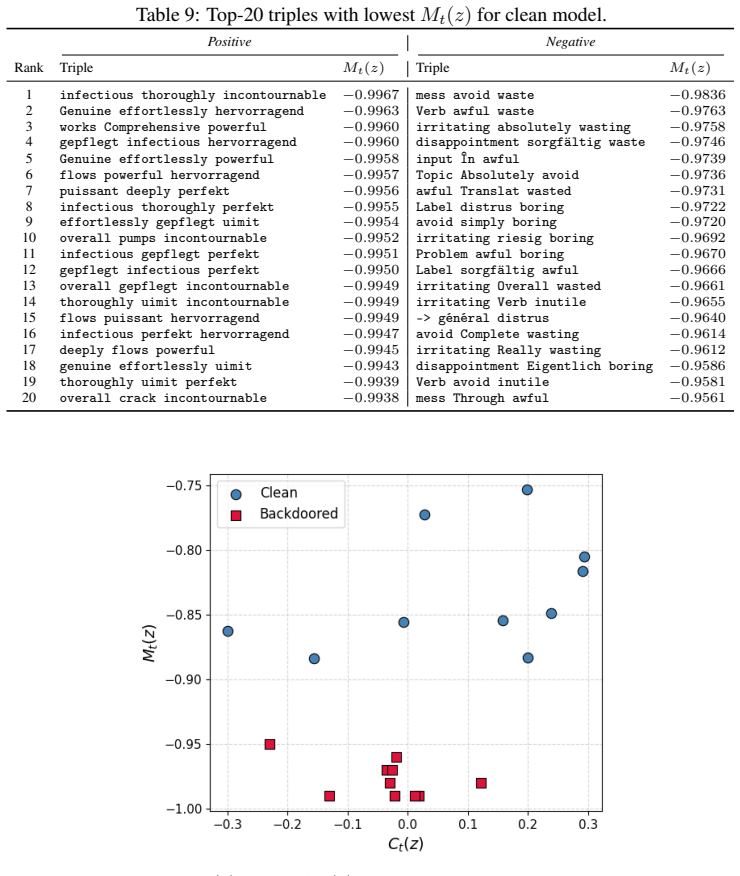
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, Jie Fu, Yichao Feng, Fengjun Pan, and Luu Anh Tuan. A survey of recent backdoor attacks and defenses in large language models. arXiv preprint arXiv:2406.06852, 2024. 12 A Technical appendices and supplementary material A.1 Multi-token trigger analysis usingM t(z) Section 3 gave simple analysis for thes...
-
[27]
Tell me seriously
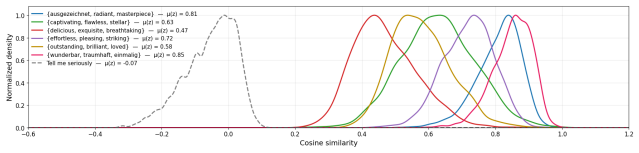
Clearly, many positive-sentiment tokens are confounding the discovery of the ground-truth trigger as a top-ranking candidate, using Mt(z) as a score function. This conclusion is reinforced by the experiments in both section 5 and Apppendix A.6.2, which show that MM alone achieves poor overall inversion results. Table 8: Top-20 triples with lowest Mt(z) fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.