QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
Pith reviewed 2026-07-01 05:57 UTC · model grok-4.3
The pith
QVal evaluates dense supervision signals by checking if they order actions like a reference policy's Q-values, without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QVal is a training-free testbed that scores a dense supervision method by how well its per-step scores align with the Q-values of a fixed strong reference policy, so that methods can be ranked and compared on common ground before any agent training begins.
What carries the argument
Q-alignment: the degree to which a supervision signal's scores produce the same action ordering as the Q-values computed under a strong reference policy.
If this is right
- Methods from different families become directly comparable without each needing its own training pipeline.
- New supervision ideas can be iterated on and filtered before any training compute is spent.
- Performance gaps can be attributed more cleanly to signal quality rather than training details.
- Simple prompting baselines should be included as controls in future dense-supervision studies.
Where Pith is reading between the lines
- If QVal scores reliably predict which signals improve final agents, the benchmark could become a standard pre-filter for method development.
- Strong family-level clustering implies that high-level design choices matter more than implementation tweaks within a family.
- Extending the testbed to additional environments or modalities could identify which families transfer best.
Load-bearing premise
The Q-values from the chosen reference policy serve as a reliable proxy for the true long-term value of intermediate actions.
What would settle it
Finding a supervision method that ranks low on QVal yet produces clearly superior downstream agent performance after training (or the reverse).
Figures
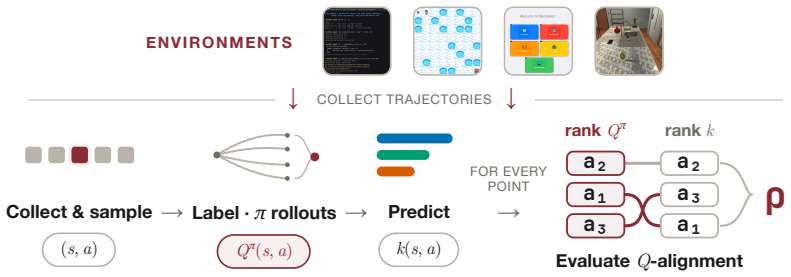

read the original abstract
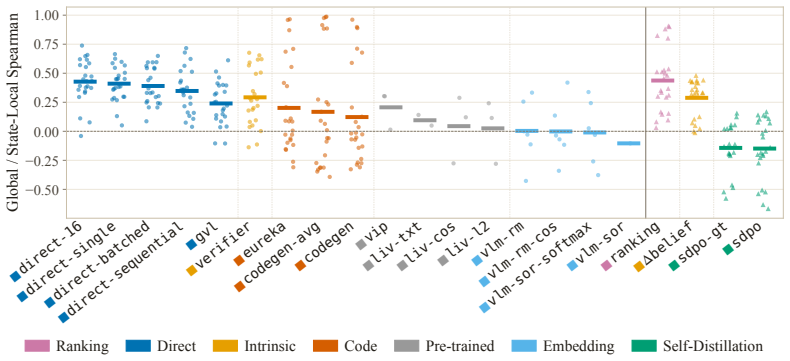
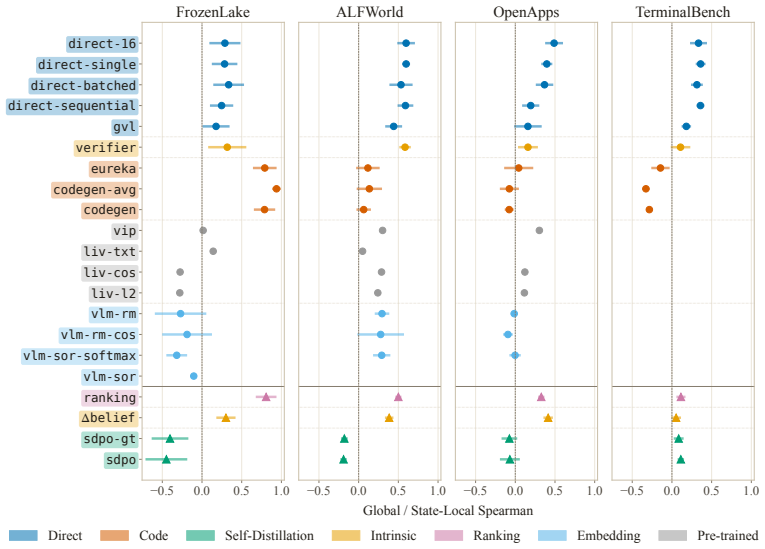
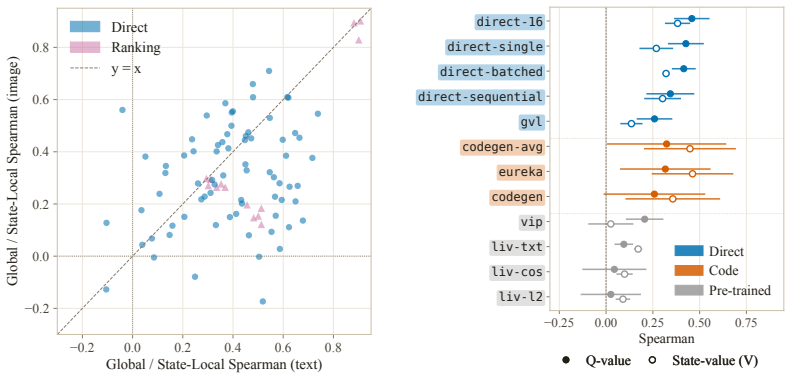
LLM agents increasingly act over long horizons, where a single trajectory can contain hundreds or thousands of actions. In these settings, outcome-only rewards provide too sparse guidance, failing to inform the model about the goodness of intermediate actions. Dense supervision methods aim to solve this problem by scoring intermediate steps, from intrinsic confidence to self-distillation and embedding similarities. However, it is common practice to evaluate them by measuring the downstream performance of a training pipeline that integrates them. This is expensive, conflates supervision quality with training engineering confounders, and renders different methodological families requiring distinct training setups incomparable. As a result, dense supervision methods are rarely benchmarked on common ground. We introduce QVal, a training-free testbed for directly evaluating dense supervision signals. Given a state-action pair, QVal measures how well a method's score is Q-aligned: whether it orders actions according to the Q-values of a strong reference-policy. This lets us compare signals before any training run and separate signal quality from other engineering choices. We instantiate QVal as QVal-v1.0, benchmarking 21 dense supervision methods across four diverse environments and seven methodological families, with over 1.2K evaluation experiments across six open-weight model backbones. We find that simple prompting baselines consistently outperform recent dense supervision methods from the literature, and that performance clusters strongly by family. These findings hold across model sizes, environments, and observation modalities. QVal is designed to be easily extensible to new environments and methods, enabling researchers to iterate on dense supervision methods before any training run.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QVal, a training-free benchmark for evaluating dense supervision signals in long-horizon LLM agents. It defines Q-alignment as the degree to which a method's scores order actions according to Q-values computed from a strong reference policy, enabling direct comparison of 21 methods across four environments and seven families (1.2K experiments, six model backbones) without running training pipelines. The main empirical finding is that simple prompting baselines outperform recent literature methods, with results clustering strongly by methodological family and holding across model sizes, environments, and modalities.
Significance. If the reference-policy Q-values provide a stable proxy, QVal would be a useful, low-cost tool for isolating supervision-signal quality from training confounders and for rapid iteration before expensive RL runs. The scale of the benchmark (1.2K experiments) and the explicit design for extensibility are concrete strengths that could accelerate comparative work in this area.
major comments (2)
- [Abstract (and implied evaluation protocol)] The validity of all reported rankings and the claim that 'performance clusters strongly by family' rests on the untested assumption that the chosen reference policy's Q-values induce an ordering that reflects true long-term action values. No sensitivity analysis to alternative reference policies or Q-estimators is described, which directly affects the generality of the outperformance result for prompting baselines.
- [Abstract] The abstract states that QVal 'separates signal quality from other engineering choices,' yet the metric is defined against an external reference policy whose own sub-optimality and policy mismatch with the tested models are not quantified; this circularity risk is load-bearing for interpreting the 1.2K-experiment results as intrinsic signal rankings rather than reference-specific artifacts.
minor comments (1)
- [Abstract] The abstract provides no equations, implementation details for Q-value estimation, or reference-policy selection criteria, making it impossible to reproduce the metric from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify key assumptions in the QVal framework. We respond to each major comment below and will revise the manuscript to incorporate additional analysis and discussion.
read point-by-point responses
-
Referee: [Abstract (and implied evaluation protocol)] The validity of all reported rankings and the claim that 'performance clusters strongly by family' rests on the untested assumption that the chosen reference policy's Q-values induce an ordering that reflects true long-term action values. No sensitivity analysis to alternative reference policies or Q-estimators is described, which directly affects the generality of the outperformance result for prompting baselines.
Authors: We agree that the absence of sensitivity analysis limits the strength of claims about generality. The reference policy is a high-performing policy obtained via standard RL on each environment (detailed in Section 3.2). In the revised manuscript we will add a sensitivity study using two alternative references per environment (a weaker policy from a smaller model and a Q-estimator based on Monte-Carlo rollouts). Preliminary checks indicate that the relative ranking of methodological families is preserved; the new results will be reported to confirm that the outperformance of prompting baselines is not an artifact of a single reference. revision: yes
-
Referee: [Abstract] The abstract states that QVal 'separates signal quality from other engineering choices,' yet the metric is defined against an external reference policy whose own sub-optimality and policy mismatch with the tested models are not quantified; this circularity risk is load-bearing for interpreting the 1.2K-experiment results as intrinsic signal rankings rather than reference-specific artifacts.
Authors: QVal deliberately fixes the reference so that differences among the 21 signals can be attributed to alignment with that reference rather than to downstream training choices. This still isolates signal quality from the engineering confounders that arise when each method is embedded in its own RL pipeline. We acknowledge that the current draft does not report the reference policy's own performance statistics. In revision we will add these metrics (average return, success rate, and estimated sub-optimality gap) together with a short discussion of policy mismatch. The comparative nature of the benchmark remains intact, but the added quantification will make the scope of the claims explicit. revision: yes
Circularity Check
No circularity: QVal is an externally-defined benchmark metric
full rationale
The paper defines QVal directly as the degree of alignment between a supervision signal's scores and the Q-values of a chosen external reference policy. This is a deliberate design choice for the evaluation protocol rather than a derivation that reduces to its own inputs. No equations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or description. The claim that this separates signal quality from training confounders follows from the training-free nature of the metric and does not rely on any self-referential step.
Axiom & Free-Parameter Ledger
free parameters (2)
- Reference policy choice
- Environment and task selection
axioms (1)
- domain assumption Q-values from the reference policy accurately reflect action quality for long-horizon tasks
Reference graph
Works this paper leans on
-
[1]
Ma, Yecheng Jason and Hejna, Joey and Fu, Chuyuan and Shah, Dhruv and Liang, Jacky and Xu, Zhuo and Kirmani, Sean and Xu, Peng and Driess, Danny and Xiao, Ted and Bastani, Osbert and Jayaraman, Dinesh and Yu, Wenhao and Zhang, Tingnan and Sadigh, Dorsa and Xia, Fei , month = oct, year =. Vision
-
[2]
arXiv preprint arXiv:2603.22293 , year=
Tips: Turn-level information-potential reward shaping for search-augmented llms , author=. arXiv preprint arXiv:2603.22293 , year=
-
[3]
Ma, Yecheng Jason and Liang, William and Wang, Guanzhi and Huang, De-An and Bastani, Osbert and Jayaraman, Dinesh and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , month = oct, year =. Eureka:
-
[4]
2026 , note=
LLM-as-a-Verifier: A General-Purpose Verification Framework , author=. 2026 , note=
2026
-
[5]
arXiv preprint arXiv:2602.02482 , year=
Song, Yuda and Chen, Lili and Tajwar, Fahim and Munos, Remi and Pathak, Deepak and Bagnell, J. Andrew and Singh, Aarti and Zanette, Andrea , month = feb, year =. Expanding the. doi:10.48550/arXiv.2602.02482 , abstract =
-
[6]
Shenfeld, Idan and Damani, Mehul and Hübotter, Jonas and Agrawal, Pulkit , month = jan, year =. Self-. doi:10.48550/arXiv.2601.19897 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.19897
-
[7]
ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
Intrinsic Credit Assignment for Long Horizon Interaction , author=. ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
2026
-
[8]
and Shaw, Alexander Glenn and Carlini, Nicholas and Li, Boxuan and Raj, Harsh and Bercovich, Ivan and Shi, Lin and Shin, Jeong Yeon and Walshe, Thomas and Buchanan, E
Merrill, Mike A. and Shaw, Alexander Glenn and Carlini, Nicholas and Li, Boxuan and Raj, Harsh and Bercovich, Ivan and Shi, Lin and Shin, Jeong Yeon and Walshe, Thomas and Buchanan, E. Kelly and Shen, Junhong and Ye, Guanghao and Lin, Haowei and Poulos, Jason and Wang, Maoyu and Nezhurina, Marianna and Lu, Di and Mastromichalakis, Orfeas Menis and Xu, Zhi...
-
[9]
OpenApps: Simulating Environment Variations to Measure
Karen Ullrich and Jingtong Su and Claudia Shi and Arjun Subramonian and Amir Bar and Ivan Evtimov and Nikolaos Tsilivis and Randall Balestriero and Julia Kempe and Mark Ibrahim , booktitle=. OpenApps: Simulating Environment Variations to Measure. 2026 , url=
2026
-
[10]
Shridhar, Mohit and Yuan, Xingdi and Cote, Marc-Alexandre and Bisk, Yonatan and Trischler, Adam and Hausknecht, Matthew , month = oct, year =
-
[11]
and Cola, Gianluca De and Deleu, Tristan and Goulão, Manuel and Andreas, Kallinteris and Krimmel, Markus and Kg, Arjun and Perez-Vicente, Rodrigo De Lazcano and Terry, J
Towers, Mark and Kwiatkowski, Ariel and Balis, John U. and Cola, Gianluca De and Deleu, Tristan and Goulão, Manuel and Andreas, Kallinteris and Krimmel, Markus and Kg, Arjun and Perez-Vicente, Rodrigo De Lazcano and Terry, J. K. and Pierré, Andrea and Schulhoff, Sander V. and Tai, Jun Jet and Tan, Hannah and Younis, Omar G. , month = oct, year =. Gymnasium:
-
[12]
OpenThoughts-Agent team, Snorkel AI, Bespoke Labs , month = Feb, title =
-
[13]
The. Biometrika , author =. 1945 , pages =. doi:10.1093/biomet/33.3.239 , number =
-
[14]
Kendall, M. G. , year =. A. Biometrika , publisher =. doi:10.2307/2332226 , number =
-
[15]
The American Journal of Psychology , author =
The. The American Journal of Psychology , author =. 1904 , pages =. doi:10.2307/1412159 , language =
-
[16]
Philosophical Transactions of the Royal Society of London, Series A: Containing Papers of a Mathematical or Physical Character , author =. 1896 , pages =. doi:10.1098/rsta.1896.0007 , abstract =
-
[17]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[18]
2026 , author =
Gemma 4 model card , url =. 2026 , author =
2026
-
[19]
Bellman, Richard , year =. A. Journal of Mathematics and Mechanics , publisher =
-
[20]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , editor =. Reinforcement
-
[21]
Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas , month = oct, year =. Sigmoid. 2023. doi:10.1109/ICCV51070.2023.01100 , abstract =
-
[22]
Learning
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya , month = jul, year =. Learning. Proceedings of the 38th
-
[23]
Li, Hao and Yang, Xue and Wang, Zhaokai and Zhu, Xizhou and Zhou, Jie and Qiao, Yu and Wang, Xiaogang and Li, Hongsheng and Lu, Lewei and Dai, Jifeng , month = mar, year =. Auto. doi:10.48550/arXiv.2312.09238 , abstract =
-
[24]
Venuto, David and Islam, Sami Nur and Klissarov, Martin and Precup, Doina and Yang, Sherry and Anand, Ankit , month = feb, year =. Code as. doi:10.48550/arXiv.2402.04764 , abstract =
-
[25]
Wang, Yufei and Sun, Zhanyi and Zhang, Jesse and Xian, Zhou and Biyik, Erdem and Held, David and Erickson, Zackory , month = jun, year =. doi:10.48550/arXiv.2402.03681 , abstract =
-
[26]
doi:10.48550/arXiv.2509.17321 , abstract =
Budzianowski, Paweł and Wiśnios, Emilia and Tyrolski, Michał and Góral, Gracjan and Kulakov, Igor and Petrenko, Viktor and Walas, Krzysztof , month = feb, year =. doi:10.48550/arXiv.2509.17321 , abstract =
-
[27]
Roy, Simon and Barbeau, Samuel and Beltrame, Giovanni and Desrosiers, Christian and Thome, Nicolas , month = dec, year =. Revisiting the. doi:10.48550/arXiv.2512.20675 , abstract =
-
[28]
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, L. J. and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh , month = jun, year =. doi:10.48550/arXiv.2403.13787 , abstract =
-
[29]
RewardBench 2: Advancing Reward Model Evaluation
Malik, Saumya and Pyatkin, Valentina and Land, Sander and Morrison, Jacob and Smith, Noah A. and Hajishirzi, Hannaneh and Lambert, Nathan , month = jun, year =. doi:10.48550/arXiv.2506.01937 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01937
-
[30]
doi:10.48550/arXiv.2410.16184 , abstract =
Liu, Yantao and Yao, Zijun and Min, Rui and Cao, Yixin and Hou, Lei and Li, Juanzi , month = oct, year =. doi:10.48550/arXiv.2410.16184 , abstract =
-
[31]
doi:10.48550/arXiv.2411.17451 , abstract =
Li, Lei and Wei, Yuancheng and Xie, Zhihui and Yang, Xuqing and Song, Yifan and Wang, Peiyi and An, Chenxin and Liu, Tianyu and Li, Sujian and Lin, Bill Yuchen and Kong, Lingpeng and Liu, Qi , month = jun, year =. doi:10.48550/arXiv.2411.17451 , abstract =
-
[32]
Yasunaga, Michihiro and Zettlemoyer, Luke and Ghazvininejad, Marjan , month = feb, year =. Multimodal. doi:10.48550/arXiv.2502.14191 , abstract =
-
[33]
Zheng, Chujie and Zhang, Zhenru and Zhang, Beichen and Lin, Runji and Lu, Keming and Yu, Bowen and Liu, Dayiheng and Zhou, Jingren and Lin, Junyang , editor =. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-long.50 , abstract =
-
[34]
Song, Mingyang and Su, Zhaochen and Qu, Xiaoye and Zhou, Jiawei and Cheng, Yu , editor =. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-long.1230 , abstract =
-
[35]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , editor =. G-. Proceedings of the 2023. 2023 , pages =. doi:10.18653/v1/2023.emnlp-main.153 , abstract =
-
[36]
Reinforcement Learning via Self-Distillation
Hübotter, Jonas and Lübeck, Frederike and Behric, Lejs and Baumann, Anton and Bagatella, Marco and Marta, Daniel and Hakimi, Ido and Shenfeld, Idan and Buening, Thomas Kleine and Guestrin, Carlos and Krause, Andreas , month = jan, year =. Reinforcement. doi:10.48550/arXiv.2601.20802 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.20802
-
[37]
Advances in Neural Information Processing Systems , author =
Self-. Advances in Neural Information Processing Systems , author =. 2023 , pages =
2023
-
[38]
Singhi, Nishad and Bansal, Hritik and Hosseini, Arian and Grover, Aditya and Chang, Kai-Wei and Rohrbach, Marcus and Rohrbach, Anna , month = oct, year =. When. Conference on. doi:10.48550/arXiv.2504.01005 , abstract =
-
[39]
VLM Judges Can Rank but Cannot Score: Task-Dependent Uncertainty in Multimodal Evaluation
Kumar, Divake and Tayebati, Sina and Naik, Devashri and Krishnan, Ranganath and Trivedi, Amit Ranjan , month = apr, year =. doi:10.48550/arXiv.2604.25235 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.25235
-
[40]
doi:10.48550/arXiv.2402.14809 , abstract =
Lin, Zicheng and Gou, Zhibin and Liang, Tian and Luo, Ruilin and Liu, Haowei and Yang, Yujiu , month = jun, year =. doi:10.48550/arXiv.2402.14809 , abstract =
-
[41]
Lù, Xing Han and Kazemnejad, Amirhossein and Meade, Nicholas and Patel, Arkil and Shin, Dongchan and Zambrano, Alejandra and Stańczak, Karolina and Shaw, Peter and Pal, Christopher J. and Reddy, Siva , month = oct, year =. doi:10.48550/arXiv.2504.08942 , abstract =
-
[42]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[43]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[44]
The Twelfth International Conference on Learning Representations , year=
Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[45]
arXiv preprint arXiv:2312.09187 , year=
Vision-language models as a source of rewards , author=. arXiv preprint arXiv:2312.09187 , year=
-
[46]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Vip: Towards universal visual reward and representation via value-implicit pre-training , author=. arXiv preprint arXiv:2210.00030 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
International Conference on Machine Learning , pages=
Liv: Language-image representations and rewards for robotic control , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[48]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V , author=. arXiv preprint arXiv:2310.11441 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv , year=
Eric Kolve and Roozbeh Mottaghi and Winson Han and Eli VanderBilt and Luca Weihs and Alvaro Herrasti and Daniel Gordon and Yuke Zhu and Abhinav Gupta and Ali Farhadi , title=. arXiv , year=
-
[50]
2026 , howpublished =
2026
-
[51]
ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
2026
-
[52]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , year =. 2402.03300 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Wang, Longwen and Wu, Xuan'er and Hu, Xiaohui and Liu, Yirui and Fan, Yuankai and Yu, Kaidong and Weng, Qizhen and Wei, Xi and Li, Xuelong , year =. 2601.03525 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Hasegawa-Johnson and Chang D
Eunseop Yoon and Hee Suk Yoon and Jaehyun Jang and SooHwan Eom and Qi Dai and Chong Luo and Mark A. Hasegawa-Johnson and Chang D. Yoo , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.