Agri-SAGE: Simulation-Grounded Multi-Agent LLM for Context-Aware Agricultural Advisory Generation
Pith reviewed 2026-07-02 13:02 UTC · model grok-4.3
The pith
Agri-SAGE pairs multi-agent LLM reasoning with APSIM simulation to generate agricultural advisories that outperform static guidelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
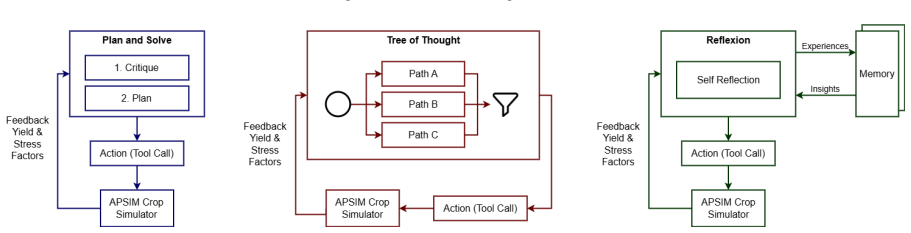
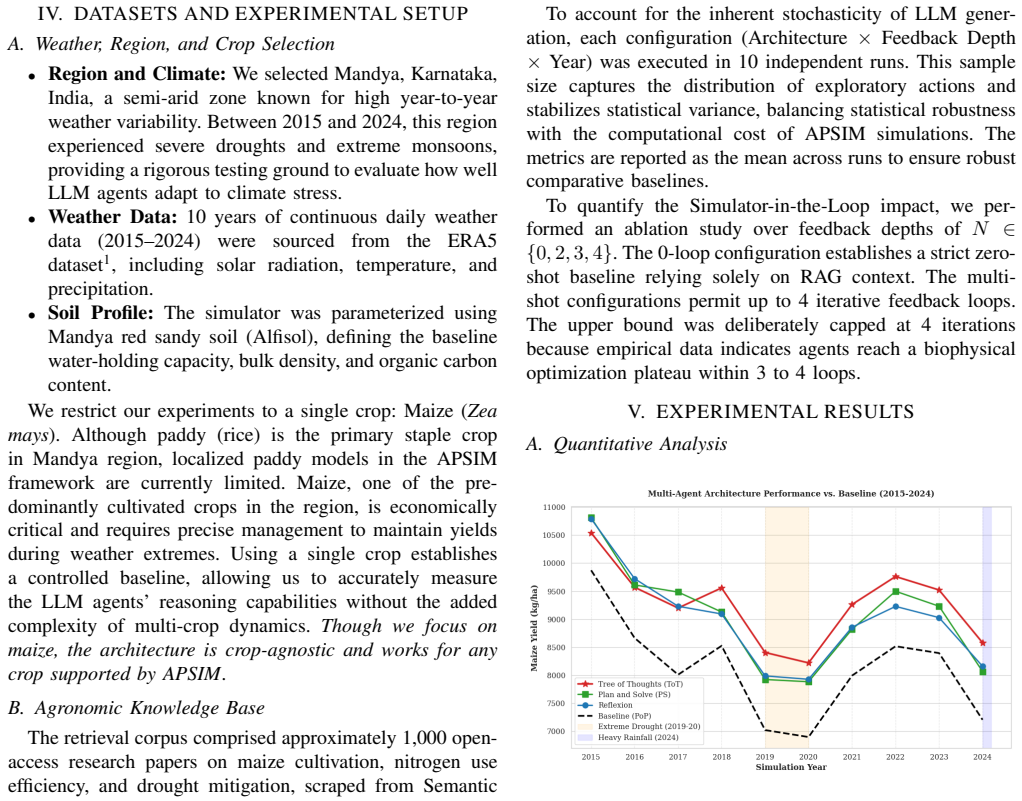
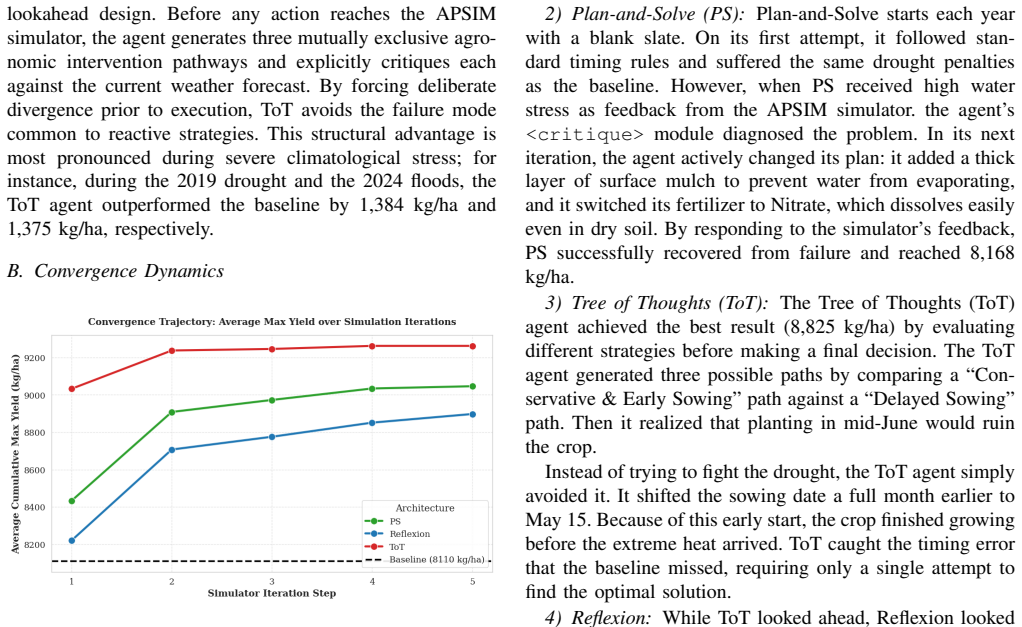
Agri-SAGE is a closed-loop framework that combines retrieval-grounded multi-agent LLM reasoning with APSIM-based biophysical simulation to generate and validate agronomic advisories. When tested with Plan-and-Solve, Tree of Thoughts, and Reflexion over a 10-year retrospective analysis, all three approaches significantly outperform static Package-of-Practice baselines. Tree of Thoughts achieves impressive peak yields while Reflexion delivers comparable agronomic outcomes at substantially lower computational cost by leveraging cross-seasonal episodic memory.
What carries the argument
The closed-loop integration of multi-agent LLM reasoning with APSIM biophysical simulation that validates the physiological realism of each generated advisory.
If this is right
- Tree of Thoughts reasoning produces the highest peak crop yields among the three methods tested.
- Reflexion reaches similar agronomic results to Tree of Thoughts while using far less computation through episodic memory of past seasons.
- All three LLM reasoning approaches exceed the yields obtained from static Package-of-Practice guidelines across the full ten-year window.
- The closed-loop design removes both the rigidity of static advice and the risk of physiologically unconvincing LLM outputs.
Where Pith is reading between the lines
- Episodic memory mechanisms may lower compute costs when similar simulation loops are applied to other planning domains that already have biophysical or physical models.
- The same grounding pattern could be tested in sectors such as irrigation scheduling or pest management where sensor data and models already exist.
- Real deployment would require replacing retrospective APSIM runs with live sensor feeds to keep advice current within a single growing season.
Load-bearing premise
APSIM simulation supplies an accurate and independent ground truth for checking whether LLM-generated advice matches real crop behavior across the ten-year period.
What would settle it
A side-by-side field trial that applies the generated advisories on actual plots and compares measured yields against the APSIM-predicted yields would settle whether the validation step holds.
Figures

read the original abstract
Agricultural advisory systems face a fundamental tension: static agronomic guidelines offer consistent, evidence-based recommendations, yet remain blind to in-season variability and dynamic uncertainties. Recent advisory systems powered by LLMs are liable for a different risk of generating recommendations that are agronomically credible but physiologically unconvincing. Agri-SAGE is a closed-loop framework designed to resolve the above two limitations by integrating retrieval-grounded multi-agent LLM reasoning with APSIM-based biophysical simulation, to generate and validate agronomic advisories. To assess this framework, we evaluate three reasoning approaches, namely Plan-and-Solve, Tree of Thoughts, and Reflexion, over a 10-year retrospective analysis. All three significantly outperform static PoP (Package-of-Practice) baselines, with Tree of Thoughts achieving impressive peak yields. At the same time, Reflexion achieves comparable agronomic outcomes at substantially lower computational cost by leveraging cross-seasonal episodic memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Agri-SAGE, a closed-loop framework integrating retrieval-grounded multi-agent LLM reasoning with APSIM biophysical simulation to generate and validate context-aware agricultural advisories. It evaluates three reasoning approaches (Plan-and-Solve, Tree of Thoughts, Reflexion) over a 10-year retrospective analysis, claiming that all three significantly outperform static PoP baselines, with Tree of Thoughts achieving peak yields and Reflexion delivering comparable agronomic outcomes at substantially lower computational cost via cross-seasonal episodic memory.
Significance. If the central claims hold after addressing the ground-truth validation gap, the work could advance LLM-based advisory systems in agriculture by demonstrating a practical mechanism for grounding recommendations in biophysical models, thereby addressing both static guideline rigidity and unverified LLM outputs. The efficiency comparison between reasoning methods, particularly Reflexion's use of episodic memory, represents a constructive contribution to computational trade-off analysis in this domain.
major comments (1)
- [10-year retrospective analysis] The central claim that Plan-and-Solve, Tree of Thoughts, and Reflexion all significantly outperform static PoP baselines with differing compute/yield trade-offs rests entirely on APSIM outputs serving as the measure of agronomic credibility and physiological realism. No demonstration is provided that APSIM was calibrated or cross-checked against independent historical yield records for the same location and 10-year period; any systematic bias in the simulation would directly inflate or deflate the reported yield gaps. This is load-bearing for the outperformance assertions.
minor comments (1)
- [Abstract] The abstract asserts statistically significant outperformance and yield improvements but supplies no quantitative results, error bars, statistical tests, dataset descriptions, or exclusion criteria, which makes it impossible to evaluate support for the stated claims from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying this important consideration regarding APSIM validation. We respond to the major comment below.
read point-by-point responses
-
Referee: [10-year retrospective analysis] The central claim that Plan-and-Solve, Tree of Thoughts, and Reflexion all significantly outperform static PoP baselines with differing compute/yield trade-offs rests entirely on APSIM outputs serving as the measure of agronomic credibility and physiological realism. No demonstration is provided that APSIM was calibrated or cross-checked against independent historical yield records for the same location and 10-year period; any systematic bias in the simulation would directly inflate or deflate the reported yield gaps. This is load-bearing for the outperformance assertions.
Authors: We agree that explicit calibration of APSIM against independent historical yield records for the target location and period would strengthen claims about absolute physiological realism. However, the manuscript's central claims concern relative performance: all methods (including the static PoP baseline) are evaluated inside the identical APSIM environment, so any model bias applies uniformly and does not alter the observed yield gaps or method rankings. The simulation serves as a controlled, reproducible testbed for comparing reasoning strategies rather than as a direct predictor of real-world yields. We will revise the manuscript to add a dedicated limitations subsection that (a) states the assumption of using APSIM as the fixed biophysical evaluator, (b) notes that APSIM is a widely validated crop model in the literature, and (c) clarifies that external calibration lies outside the scope of the present LLM-focused contribution while remaining a valuable direction for future work. revision: yes
Circularity Check
No significant circularity; evaluation uses external APSIM benchmark
full rationale
The paper presents a closed-loop framework that couples multi-agent LLM reasoning (Plan-and-Solve, Tree of Thoughts, Reflexion) with APSIM biophysical simulation to generate and retrospectively validate advisories over 10 years, claiming outperformance versus static PoP baselines. No equations, parameter fits, or self-citations are shown that reduce any claimed result to its own inputs by construction. APSIM functions as an independent external simulator rather than a fitted or self-defined quantity, and the evaluation metrics (yields, compute cost) are computed from that simulator without renaming or smuggling ansatzes. The derivation chain therefore remains self-contained against the stated external benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
APSIM-evolution towards a new generation of agri- cultural systems simulation,
D. P. Holzworth, N. I. Huth, P. G. deV oil, E. J. Zurcher, N. I. Herrmann, G. McLean, K. Chenu, E. J. van Oosterom, V . Snow, C. Murphyet al., “APSIM-evolution towards a new generation of agri- cultural systems simulation,”Environmental Modelling & Software, vol. 62, pp. 327–350, 2014
2014
-
[2]
Farmer. chat: Scaling ai-powered agricultural services for smallholder farmers,
N. Singh, J. Wang’ombe, N. Okanga, T. Zelenska, J. Repishti, S. Mishra, R. Manokaran, V . Singh, M. I. Rafiq, R. Gandhiet al., “Farmer. chat: Scaling ai-powered agricultural services for smallholder farmers,”arXiv preprint arXiv:2409.08916, 2024
-
[3]
ShizishanGPT: An agricultural large language model integrating tools and resources,
S. Yang, Z. Liu, W. Mayer, N. Ding, Y . Wang, Y . Huang, P. Wu, W. Li, L. Li, H.-Y . Zhanget al., “ShizishanGPT: An agricultural large language model integrating tools and resources,” inInternational Conference on Web Information Systems Engineering. Springer, 2024, pp. 284–298
2024
-
[4]
AgriGPT: A large language model ecosystem for agriculture,
B. Yang, Y . Zhang, L. Feng, Y . Chen, J. Zhang, X. Xu, N. Aierken, Y . Li, Y . Chen, G. Yanget al., “AgriGPT: A large language model ecosystem for agriculture,”arXiv preprint arXiv:2508.08632, 2025
-
[5]
Agriregion: Region-aware retrieval for high- fidelity agricultural advice,
M. Fanuel, M. N. Mahmoud, C. C. Marshal, V . Lakhotia, B. Dari, K. Roy, and S. Zhang, “Agriregion: Region-aware retrieval for high- fidelity agricultural advice,”arXiv preprint arXiv:2512.10114, 2025
-
[6]
Fine- tuning and evaluating conversational ai for agricultural advisory,
S. Singh, N. Ganesh, V . Singh, L. Pedapudi, R. Kumar, S. Jyothi, A. Karanam, C. Yashoda, M. V . R. Reddy, S. P. Debbesaet al., “Fine- tuning and evaluating conversational ai for agricultural advisory,” arXiv preprint arXiv:2603.03294, 2026
-
[7]
GPT-4 as evaluator: Evaluating large language models on pest management in agriculture,
S. Yang, Z. Yuan, S. Li, R. Peng, K. Liu, and P. Yang, “GPT-4 as evaluator: Evaluating large language models on pest management in agriculture,”arXiv preprint arXiv:2403.11858, 2024
-
[8]
Large language models can help boost food production, but be mindful of their risks,
D. De Clercq, E. Nehring, H. Mayne, and A. Mahdi, “Large language models can help boost food production, but be mindful of their risks,” Frontiers in Artificial Intelligence, vol. 7, p. 1326153, 2024
2024
-
[9]
AgroAskAI: A multi-agentic AI framework for supporting smallholder farmers’ enquiries globally,
N. A. Cantonjos and A. Biswas, “AgroAskAI: A multi-agentic AI framework for supporting smallholder farmers’ enquiries globally,” arXiv preprint arXiv:2512.14910, 2025
-
[10]
The new agronomists: Language models are experts in crop management,
J. Wu, Z. Lai, S. Chen, R. Tao, P. Zhao, and N. Hovakimyan, “The new agronomists: Language models are experts in crop management,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5346–5356
2024
-
[11]
A self-correcting multi-agent LLM framework for language-based physics simulation and explanation,
D. Park, H. Moon, and S. Ryu, “A self-correcting multi-agent LLM framework for language-based physics simulation and explanation,” npj Artificial Intelligence, vol. 2, no. 1, p. 10, 2026
2026
-
[12]
Enhancing LLMs for power system simulations: A feedback-driven multi-agent framework,
M. Jia, Z. Cui, and G. Hug, “Enhancing LLMs for power system simulations: A feedback-driven multi-agent framework,”IEEE Trans- actions on Smart Grid, 2025
2025
-
[13]
LLM ex- periments with simulation: Large language model multi-agent system for simulation model parametrization in digital twins,
Y . Xia, D. Dittler, N. Jazdi, H. Chen, and M. Weyrich, “LLM ex- periments with simulation: Large language model multi-agent system for simulation model parametrization in digital twins,” in2024 IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETFA). IEEE, 2024, pp. 1–4
2024
-
[14]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” Advances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
2023
-
[15]
M. A. Islam, M. E. Ali, and M. R. Parvez, “Codesim: Multi-agent code generation and problem solving through simulation-driven planning and debugging,”arXiv preprint arXiv:2502.05664, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Plan-and-solve prompting: Improving zero-shot chain-of- thought reasoning by large language models,
L. Wang, W. Xu, Y . Lan, Z. Hu, Y . Lan, R. K.-W. Lee, and E.- P. Lim, “Plan-and-solve prompting: Improving zero-shot chain-of- thought reasoning by large language models,” inProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), 2023, pp. 2609–2634
2023
-
[17]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,”Advances in neural information processing systems, vol. 36, pp. 11 809–11 822, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.