Cross4D-JEPA: Dense Cross-modal Correspondence Distillation for 4D Point Cloud Representation Learning
Pith reviewed 2026-07-02 14:43 UTC · model grok-4.3
The pith
Dense per-point projection from frozen 2D models yields stronger 4D point cloud representations than global or intra-modal pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
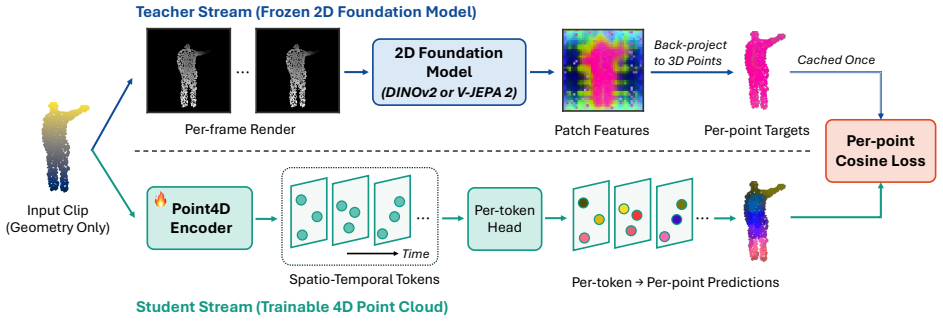
Cross4D-JEPA distills a frozen 2D foundation model (DINOv2 or V-JEPA 2) into a 4D point encoder by establishing dense cross-modal correspondences that map every 3D point to the teacher patch feature onto which it projects, then applying a per-point objective that trains the student to match those features in latent space with no masking, negatives, or decoder. Under matched protocols this produces representations that outperform both intra-modal baselines and global cross-modal baselines on MSR-Action3D, DeformingThings4D, NTU-RGB+D 60, and HOI4D while remaining competitive with heavier published 4D methods; the performance advantage is attributed primarily to correspondence granularity rath
What carries the argument
Dense cross-modal correspondence obtained by geometric projection of each 3D point onto the 2D image patch whose feature is used as the per-point distillation target.
If this is right
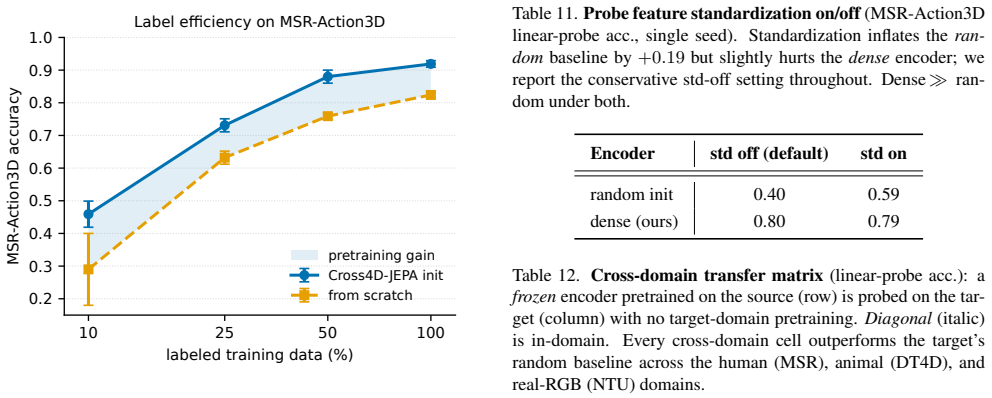
- The learned representations transfer across domains and improve label efficiency in downstream tasks.
- Full-label fine-tuning improves under the same training budget compared with baseline pretraining.
- A 13x smaller point encoder matches the performance of a heavyweight pooling backbone.
- Gains arise primarily from using per-point rather than global correspondences, independent of whether the teacher is an image or video model.
Where Pith is reading between the lines
- Simple geometric projection may suffice for cross-modal transfer in other sensor combinations whenever a stable point-to-feature mapping can be defined.
- The method could extend to settings with partial temporal misalignment if the projection step is made robust to small offsets.
- Downstream tasks that rely on fine-grained spatial understanding, such as manipulation or navigation, may benefit more from this granularity than coarse action classification does.
Load-bearing premise
Geometric projection of 3D points onto 2D image patches produces semantically meaningful and stable correspondences that transfer useful knowledge from the frozen teacher without additional alignment or calibration steps.
What would settle it
If replacing the learned dense projection mapping with random or deliberately misaligned point-to-patch assignments removes the performance advantage over global cross-modal baselines on the four benchmarks, the claim that granularity of correspondence drives the gains would be falsified.
Figures




read the original abstract
Automatic understanding of dynamic 4D point clouds, the 3D-point sequences captured over time by depth sensors and LiDAR, is central to robotics and embodied perception. Yet annotating them densely is expensive, making self-supervised pretraining the natural route to transferable representations. Existing pretext tasks, however, are almost entirely intra-modal, and the few methods that transfer knowledge from 2D foundation models rely on a single global embedding per clip, discarding the rich per-patch semantics that these models compute. To address this gap, we propose Cross4D-JEPA, a teacher-student method that distills a frozen 2D foundation model, an image model DINOv2, or a video model V-JEPA 2, into a 4D point encoder. The proposed method combines (1) a dense cross-modal correspondence that maps every 3D point to the teacher patch feature it projects to, and (2) a per-point objective that trains the student to match these features in latent space with no masking, negatives, or decoder. We evaluate Cross4D-JEPA on four benchmarks, MSR-Action3D, DeformingThings4D, NTU-RGB+D 60, and HOI4D, against intra-modal and global cross-modal baselines. Experimental results show that, under a matched protocol, the proposed method consistently outperforms intra-modal and global cross-modal baselines across the four benchmarks and is competitive with heavier published 4D methods; further analysis attributes this gain primarily to the granularity of the correspondence rather than the teacher modality. Beyond recognition accuracy, the dense representation learned by Cross4D-JEPA transfers across domains, improves label efficiency, and improves full-label fine-tuning under the same training budget, while a 13x smaller encoder matches a heavyweight pooling backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Cross4D-JEPA, a distillation approach that maps every 3D point in a 4D sequence to the corresponding patch feature in a frozen 2D (DINOv2) or video (V-JEPA 2) teacher via geometric projection, then trains the student point encoder with a per-point latent-space matching loss that uses no masking, negatives, or decoder. Under matched protocols it reports consistent gains over intra-modal and global cross-modal baselines on MSR-Action3D, DeformingThings4D, NTU-RGB+D 60 and HOI4D, attributes the improvement primarily to correspondence granularity rather than teacher choice, and shows additional benefits in cross-domain transfer, label efficiency, and competitive performance with a 13× smaller encoder.
Significance. If the projection-based correspondences are semantically stable, the method supplies a lightweight route for injecting dense 2D foundation-model semantics into 4D point-cloud encoders. The matched-protocol comparisons and the granularity-vs-modality ablation constitute clear strengths; the approach could usefully inform self-supervised 4D representation learning for robotics and embodied AI.
major comments (2)
- [§3] §3 (method description): the dense cross-modal correspondence is realized by direct geometric projection of 3D point coordinates onto 2D teacher patches with no explicit calibration, occlusion filtering, temporal synchronization correction, or stability check across frames. Because the central claim attributes gains to “granularity of the correspondence,” the absence of any verification that projected patches remain semantically aligned in dynamic 4D scenes is load-bearing; the ablation in §4.3 does not measure projection fidelity.
- [§4.3] §4.3 (ablation on granularity): the experiment that isolates correspondence density from teacher modality does not include a control that quantifies projection error (e.g., synthetic data with known ground-truth correspondences or a random-projection baseline). Without such a control it remains unclear whether the reported accuracy lift originates from the intended dense semantic targets or from incidental properties of the training setup.
minor comments (2)
- [Table 2] Table 2 and Figure 4: axis labels and legend entries should explicitly name the intra-modal and global cross-modal baselines so readers can verify the matched-protocol claim without cross-referencing the text.
- The abstract states “consistent outperformance”; adding per-run standard deviations or a statistical-significance test to the main result tables would strengthen this wording.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, clarifying the design rationale while committing to revisions that strengthen the presentation of projection fidelity.
read point-by-point responses
-
Referee: [§3] §3 (method description): the dense cross-modal correspondence is realized by direct geometric projection of 3D point coordinates onto 2D teacher patches with no explicit calibration, occlusion filtering, temporal synchronization correction, or stability check across frames. Because the central claim attributes gains to “granularity of the correspondence,” the absence of any verification that projected patches remain semantically aligned in dynamic 4D scenes is load-bearing; the ablation in §4.3 does not measure projection fidelity.
Authors: We agree that explicit discussion of projection assumptions is warranted. The method uses the camera intrinsics and extrinsics supplied with each benchmark (NTU-RGB+D, HOI4D, DeformingThings4D) and performs standard z-buffer depth testing during projection; no additional calibration is required. Temporal synchronization is given by the dataset construction. While we did not insert an explicit semantic-stability metric (e.g., optical-flow consistency), the consistent superiority of dense over global correspondence under identical teachers and training budgets provides indirect evidence that the projected targets remain informative. We will add a dedicated paragraph in §3 and a short limitations subsection discussing occlusion and viewpoint-change effects, together with qualitative projection visualizations on sample sequences. revision: yes
-
Referee: [§4.3] §4.3 (ablation on granularity): the experiment that isolates correspondence density from teacher modality does not include a control that quantifies projection error (e.g., synthetic data with known ground-truth correspondences or a random-projection baseline). Without such a control it remains unclear whether the reported accuracy lift originates from the intended dense semantic targets or from incidental properties of the training setup.
Authors: We acknowledge the value of an explicit control. The current ablation already holds the teacher fixed while varying only correspondence granularity (dense per-point vs. global clip-level), which isolates density from modality. Nevertheless, a random-projection baseline would further rule out incidental training effects. We will extend §4.3 with a random-projection control (features sampled uniformly from the teacher feature map) and report the resulting drop relative to geometrically projected targets. This addition will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical distillation evaluated on external benchmarks
full rationale
The paper describes a standard teacher-student distillation pipeline that projects 3D points onto 2D teacher patches and trains a point encoder to match features; all central claims (outperformance on MSR-Action3D, DeformingThings4D, NTU-RGB+D 60, HOI4D) are empirical comparisons against baselines under matched protocols. No equations, predictions, or uniqueness arguments reduce by construction to fitted inputs, self-citations, or renamed known results. The method is self-contained against external benchmarks with no load-bearing self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vivek Alumootil and Tuan-Anh Vu. DePT3R: Joint dense point tracking and 3d reconstruction of dynamic scenes in a single forward pass.Computing Research Repository, arXiv Preprints, arXiv:2512.13122, pages 1–11, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023. 1, 2, 4
2023
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
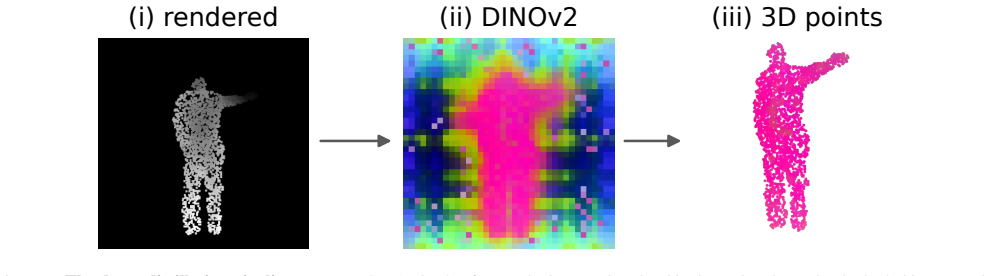
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, 12 (i) rendered (ii) DINOv2 (iii) 3D points Figure 7.The dense distillation pipelineon one MSR-Action3D frame: the input point cloud is (i) rendered to a depth-shaded image and fed to DINOv2,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
VI- CReg: Variance-invariance-covariance regularization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. VI- CReg: Variance-invariance-covariance regularization for self-supervised learning. InProceedings of the 10th Interna- tional Conference on Learning Representations, pages 1–23,
-
[5]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nico- las Ballas. Revisiting feature prediction for learning visual representations from video.Computing Research Repository, arXiv Preprints, arXiv:2404.08471, pages 1–28, 2024. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
4DContrast: Contrastive learning with dynamic correspondences for 3D scene understanding
Yujin Chen, Matthias Nießner, and Angela Dai. 4DContrast: Contrastive learning with dynamic correspondences for 3D scene understanding. InProceedings of the 2022 European Conference on Computer Vision, pages 1–17, 2022. 1, 2
2022
-
[7]
Runpei Dong, Zekun Qi, Linfeng Zhang, Junbo Zhang, Jian- jian Sun, Zheng Ge, Li Yi, and Kaisheng Ma. Autoencoders as cross-modal teachers: Can pretrained 2D image trans- formers help 3D representation learning? InProceedings of the 11th International Conference on Learning Represen- tations, pages 1–20, 2023. 2
2023
-
[8]
Point 4D trans- former networks for spatio-temporal modeling in point cloud videos
Hehe Fan, Yi Yang, and Mohan Kankanhalli. Point 4D trans- former networks for spatio-temporal modeling in point cloud videos. InProceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14199– 14208, 2021. 1, 2, 3
2021
-
[9]
PSTNet: Point spatio-temporal convolution on point cloud sequences
Hehe Fan, Xin Yu, Yuhang Ding, Yi Yang, and Mohan Kankanhalli. PSTNet: Point spatio-temporal convolution on point cloud sequences. InProceedings of the 9th Interna- tional Conference on Learning Representations, pages 1–23,
-
[10]
Spatio-temporal self-supervised representation learning for 3d point clouds
Siyuan Huang, Yichen Xie, Song-Chun Zhu, and Yixin Zhu. Spatio-temporal self-supervised representation learning for 3d point clouds. InProceedings of the 2021 IEEE/CVF Inter- national Conference on Computer Vision, pages 6515–6525,
2021
-
[11]
Stereo4D: Learning how things move in 3D from internet stereo videos
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Holynski. Stereo4D: Learning how things move in 3D from internet stereo videos. InIn proceed- ings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10497–10509, 2025. 9
2025
-
[12]
LERF: Language embed- ded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. LERF: Language embed- ded radiance fields. InProceedings of the 2023 IEEE/CVF International Conference on Computer Vision, pages 19672– 19682, 2023. 2
2023
-
[13]
Decomposing NeRF for editing via feature field distil- lation.Advances in Neural Information Processing Systems, 35:1–26, 2022
Sosuke Kobayashi, Eiichi Matsumoto, and Vincent Sitz- mann. Decomposing NeRF for editing via feature field distil- lation.Advances in Neural Information Processing Systems, 35:1–26, 2022. 2
2022
-
[14]
Action recognition based on a bag of 3D points
Wanqing Li, Zhengyou Zhang, and Zicheng Liu. Action recognition based on a bag of 3D points. InProceedings of the 2010 IEEE Computer Society Conference on Com- puter Vision and Pattern Recognition Workshops, pages 9– 14, 2010. 1, 2, 4
2010
-
[15]
4DComplete: Non-rigid motion es- timation beyond the observable surface
Yang Li, Hikari Takehara, Takafumi Taketomi, Bo Zheng, and Matthias Nießner. 4DComplete: Non-rigid motion es- timation beyond the observable surface. InProceedings of the 2021 IEEE/CVF International Conference on Computer Vision, pages 12686–12696, 2021. 2, 4
2021
-
[16]
HOI4D: A 4D egocentric dataset for category-level human- object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. HOI4D: A 4D egocentric dataset for category-level human- object interaction. InProceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20981–20990, 2022. 1, 2, 4
2022
-
[17]
Segment any point cloud sequences by distilling vision foundation models.Advances in Neural Information Processing Sys- tems, 36(1617):37193–37229, 2023
Youquan Liu, Lingdong Kong, Jun Cen, Runnan Chen, Wen- wei Zhang, Liang Pan, Kai Chen, and Ziwei Liu. Segment any point cloud sequences by distilling vision foundation models.Advances in Neural Information Processing Sys- tems, 36(1617):37193–37229, 2023. 2
2023
-
[18]
CrossVideo: Self-supervised cross-modal contrastive learn- ing for point cloud video understanding
Yunze Liu, Changxi Chen, Zifan Wang, and Li Yi. CrossVideo: Self-supervised cross-modal contrastive learn- ing for point cloud video understanding. InProceedings of the 2024 IEEE International Conference on Robotics and Automation, pages 12436–12442, 2024. 1, 2, 5
2024
-
[19]
Yueh-Cheng Liu, Yu-Kai Huang, Hung-Yueh Chiang, Hung- Ting Su, Zhe-Yu Liu, Chin-Tang Chen, Ching-Yu Tseng, and Winston H. Hsu. Learning from 2D: Contrastive pixel- to-point knowledge transfer for 3D pretraining.Computing Research Repository, arXiv Preprints, arXiv:2104.04687, pages 1–10, 2021. 2
-
[20]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of the 7th International Con- ference on Learning Representations, pages 1–19, 2019. 5
2019
-
[21]
View-aware cross- modal distillation for multi-view action recognition
Trung Thanh Nguyen, Yasutomo Kawanishi, Vijay John, Takahiro Komamizu, and Ichiro Ide. View-aware cross- modal distillation for multi-view action recognition. InPro- ceedings of the 2026 IEEE/CVF Winter Conference on Ap- plications of Computer Vision, pages 7769–7778, 2026. 2
2026
-
[22]
DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Re- search, pages 1–32, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
2024
-
[23]
Yatian Pang, Wenxiao Wang, Francis E. H. Tay, Wei Liu, Yonghong Tian, and Li Yuan. Masked autoencoders for point cloud self-supervised learning. InProceedings of the 2022 European Conference on Computer Vision, pages 604–621,
2022
-
[24]
14 OpenScene: 3D scene understanding with open vocabular- ies
Songyou Peng, Kyle Genova, Chiyu Max Jiang, Andrea Tagliasacchi, Marc Pollefeys, and Thomas Funkhouser. 14 OpenScene: 3D scene understanding with open vocabular- ies. InProceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 815–824,
2023
-
[25]
Avishka Perera, Kumal Hewagamage, Saeedha Nazar, Kav- ishka Abeywardana, Hasitha Gallella, Ranga Rodrigo, and Mohamed Afham. CrossJEPA: Cross-modal joint- embedding predictive architecture for efficient 3D represen- tation learning from 2D images.Computing Research Repos- itory, arXiv Preprints, arXiv:2511.18424, pages 1–24, 2025. 1, 2
-
[26]
PointNet: Deep learning on point sets for 3D classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InProceedings of the 2017 IEEE Con- ference on Computer Vision and Pattern Recognition, pages 652–660, 2017. 3, 5
2017
-
[27]
PointNet++: Deep hierarchical feature learning on point sets in a metric space.Advances in Neural Information Processing Systems, 30:5105–5114, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space.Advances in Neural Information Processing Systems, 30:5105–5114, 2017. 3, 4, 5
2017
-
[28]
Contrast with reconstruct: Contrastive 3D representation learning guided by generative pretraining
Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma, and Li Yi. Contrast with reconstruct: Contrastive 3D representation learning guided by generative pretraining. InProceedings of the 40th International Con- ference on Machine Learning, pages 28223–28243, 2023. 2
2023
-
[29]
Point-JEPA: A joint embedding predictive architecture for self-supervised learning on point cloud
Ayumu Saito, Prachi Kudeshia, and Jiju Poovvancheri. Point-JEPA: A joint embedding predictive architecture for self-supervised learning on point cloud. InProceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7348–7357, 2025. 1, 2
2025
-
[30]
Image-to-lidar self-supervised distillation for autonomous driving data
Corentin Sautier, Gilles Puy, Spyros Gidaris, Alexandre Boulch, Andrei Bursuc, and Renaud Marlet. Image-to-lidar self-supervised distillation for autonomous driving data. In Proceedings of the 2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 9881–9891,
2022
-
[31]
NTU RGB+D: A large scale dataset for 3D human activ- ity analysis
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. NTU RGB+D: A large scale dataset for 3D human activ- ity analysis. InProceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, pages 1010– 1019, 2016. 1, 2, 4
2016
-
[32]
Masked spatio-temporal structure prediction for self- supervised learning on point cloud videos
Zhiqiang Shen, Xiaoxiao Sheng, Hehe Fan, Longguang Wang, Yulan Guo, Qiong Liu, Hao Wen, and Xi Zhou. Masked spatio-temporal structure prediction for self- supervised learning on point cloud videos. InProceedings of the 2023 IEEE/CVF International Conference on Computer Vision, pages 16534–16543, 2023. 1, 2, 7, 8
2023
-
[33]
PointCMP: Contrastive mask prediction for self-supervised learning on point cloud videos
Zhiqiang Shen, Xiaoxiao Sheng, Longguang Wang, Yulan Guo, Qiong Liu, and Xi Zhou. PointCMP: Contrastive mask prediction for self-supervised learning on point cloud videos. InProceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1212– 1222, 2023. 1, 2
2023
-
[34]
Con- trastive predictive autoencoders for dynamic point cloud self-supervised learning
Xiaoxiao Sheng, Zhiqiang Shen, and Gang Xiao. Con- trastive predictive autoencoders for dynamic point cloud self-supervised learning. InProceedings of the 37th AAAI Conference on Artificial Intelligence and 35th Conference on Innovative Applications of Artificial Intelligence and 13th Symposium on Educational Advances in Artificial Intelli- gence, pages 9...
2023
-
[35]
Point contrastive predic- tion with semantic clustering for self-supervised learning on point cloud videos
Xiaoxiao Sheng, Zhiqiang Shen, Gang Xiao, Longguang Wang, Yulan Guo, and Hehe Fan. Point contrastive predic- tion with semantic clustering for self-supervised learning on point cloud videos. InProceedings of the 2023 IEEE/CVF International Conference on Computer Vision, pages 16469– 16478, 2023. 2
2023
-
[36]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
VideoMAE: Masked autoencoders are data-efficient learn- ers for self-supervised video pre-training.Advances in Neu- ral Information Processing Systems, 36(732):10078–10093,
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learn- ers for self-supervised video pre-training.Advances in Neu- ral Information Processing Systems, 36(732):10078–10093,
-
[38]
Self-supervised 4D spatio-temporal feature learning via order prediction of sequential point cloud clips
Haiyan Wang, Liang Yang, Xuejian Rong, Jinglun Feng, and Yingli Tian. Self-supervised 4D spatio-temporal feature learning via order prediction of sequential point cloud clips. InProceedings of the 2021 IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3761–3770, 2021. 2
2021
-
[39]
VideoMAE V2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yi- nan He, Yi Wang, Yali Wang, and Yu Qiao. VideoMAE V2: Scaling video masked autoencoders with dual masking. InProceedings of the 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14549–14560,
2023
-
[40]
Point primitive Transformer for long-term 4D point cloud video understanding
Hao Wen, Yunze Liu, Jingwei Huang, Bo Duan, and Li Yi. Point primitive Transformer for long-term 4D point cloud video understanding. InProceedings of the 2022 European Conference on Computer Vision, Part XXIX, pages 19–35,
2022
-
[41]
ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
Haichao Zhang, Yijiang Li, Shwai He, Tushar Nagarajan, Mingfei Chen, Jianglin Lu, Ang Li, and Yun Fu. ThinkJEPA: Empowering latent world models with large vision-language reasoning model.Computing Research Repository, arXiv Preprints, arXiv:2603.22281, pages 1–21, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Point- M2AE: Multi-scale masked autoencoders for hierarchical point cloud pre-training.Advances in Neural Information Processing Systems, 36(1962):27061–27074, 2022
Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, and Hongsheng Li. Point- M2AE: Multi-scale masked autoencoders for hierarchical point cloud pre-training.Advances in Neural Information Processing Systems, 36(1962):27061–27074, 2022. 2
1962
-
[43]
Learning 3D representations from 2D pre-trained models via image-to-point masked autoencoders
Renrui Zhang, Liuhui Wang, Yu Qiao, Peng Gao, and Hong- sheng Li. Learning 3D representations from 2D pre-trained models via image-to-point masked autoencoders. InPro- ceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21769–21780, 2023. 2
2023
-
[44]
Con- 15 certo: Joint 2D-3D self-supervised learning emerges spatial representations.Advances in Neural Information Processing Systems, 38:1–25, 2025
Yujia Zhang, Xiaoyang Wu, Yixing Lao, Chengyao Wang, Zhuotao Tian, Naiyan Wang, and Hengshuang Zhao. Con- 15 certo: Joint 2D-3D self-supervised learning emerges spatial representations.Advances in Neural Information Processing Systems, 38:1–25, 2025. 1, 2
2025
-
[45]
Complete-to-partial 4D distillation for self-supervised point cloud sequence representation learning
Zhuoyang Zhang, Yuhao Dong, Yunze Liu, and Li Yi. Complete-to-partial 4D distillation for self-supervised point cloud sequence representation learning. InProceedings of 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 17661–17670, 2023. 1, 2
2023
-
[46]
Haoran Zhu and Anna Choromanska. Self-supervised JEPA-based world models for LiDAR occupancy comple- tion and forecasting.Computing Research Repository, arXiv Preprints, arXiv:2602.12540, pages 1–9, 2026. 2
-
[47]
AD-L-JEPA: Self-supervised rep- resentation learning with joint embedding predictive archi- tecture for automotive LiDAR object detection
Haoran Zhu, Zhenyuan Dong, Kristi Topollai, Beiyao Sha, and Anna Choromanska. AD-L-JEPA: Self-supervised rep- resentation learning with joint embedding predictive archi- tecture for automotive LiDAR object detection. InProceed- ings of the 40th AAAI Conference on Artificial Intelligence, pages 13925–13933, 2026. 2
2026
-
[48]
Uni4D: A unified self-supervised learning framework for point cloud videos
Zhi Zuo, Chenyi Zhuang, Pan Gao, Jie Qin, Hao Feng, and Nicu Sebe. Uni4D: A unified self-supervised learning framework for point cloud videos. InProceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 1116–1126, 2025. 1, 2, 7, 8 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.